







NLP之Prompt:《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing预训练、提示和预测:自然语言处理中提示方法的系统综述》翻译与解读
目录
1 Two Sea Changes in NLP自然语言处理的两次巨变
完全监督学习:以机器学习为中心,早期的NLP模型严重依赖特征工程
预训练-提示-预测范式(2021年起):给定一套适当的提示,以完全无监督的方式训练的单个LM可用于解决大量任务
Fig.1: A typology of important concepts for prompt-based learning提示式学习的重要概念类型
2 A Formal Description of Prompting提示的正式描述
2.1 Supervised Learning in NLP监督学习
2.3 Design Considerations for Prompting提示的设计注意事项
Figure 1: Typology of prompting methods.提示方法的类型。
3 Pre-trained Language Models预训练语言模型
两种提示:完形填空提示(更适合Mask任务)、前缀提示(更适合标准自回归生成任务)
4.2 Manual Template Engineering手动模板工程
4.3 Automated Template Learning模板自动学习
4.3.1 Discrete Prompts离散提示/硬提示:
4.3.2 Continuous Prompts连续提示/软提示:直接在模型的嵌入空间中进行提示
C1: Prefix Tunin前缀调优:在输入之前添加一系列连续的任务特定向量的方法+保持LM参数冻结
C2: Tuning Initialized with Discrete Prompts使用离散提示初始化调优
C3: Hard-Soft Prompt Hybrid Tuning硬-软提示混合调优:如P-tuning
《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》翻译与解读
| 地址 | |
| 时间 | 2021年7月28日 |
| 作者 | Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig 卡耐基梅隆大学 |
| 总结 | 论文总结了一种新的自然语言处理范式,即提示式学习。 背景痛点:传统监督学习模式需要对模型输入x和输出y进行训练,但这需要大量标注数据,而且难以应对新场景。但是标注数据往往难以获取。预训练语言模型掌握了丰富的语言知识,但仅通过监督训练难以利用这些知识进行下游任务。 解决方案: >> 提示式学习模式基于预训练好的语言模型,将原始输入x转换为包含槽位的提示性文本x',语言模型根据提示填充槽位信息得到最终文本,从中获得输出y。 >> 将原始输入通过模板修改成指导性文本提示,将预训练语言模型应用于概率填空得到预测结果。通过定义新的提示函数,语言模型可以基于很少或没有标注数据进行少量样本学习或零样本学习,适应新场景。 核心特点: >> 允许语言模型在大量原始文字上进行预训练,通过定义新提示函数实现少量示例学习或零示例学习,适应新的场景需要少量或无标注数据。 >> 提供了统一的数学表示法来概括广泛工作,并根据预训练模型、提示选择和调优策略等多个维度对现有工作进行分类梳理。 >> 可以利用预训练模型学习到的丰富语言知识。 >> 通过定义提示不需要额外标注数据就可以进行下游任务迁移,实现少样本或零样本学习。 >> 提示学习框架更加通用,可以统一许多现有工作。 优势:相比传统监督学习,提示式学习需要的标注数据更少,能更好地应对新任务和情景。同时研究提出了相关概念和资源,有利于推进该领域的发展。 >> 可以有效利用预训练模型带来的知识优势。 >> 可以基于少量或无数据进行任务迁移,实现更广泛的应用。 >> 通过定义不同提示函数可以实现不同下游任务,提高模型可复用性。 |
Abstract
| This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website this http URL including constantly-updated survey, and paperlist. | 本文调查和组织了自然语言处理中的一个新范式的研究工作,我们将其称为“基于提示的学习”。与传统的监督学习不同,传统监督学习训练模型以输入x并预测输出y为P(y|x)为基础,基于提示的学习基于直接建模文本概率的语言模型。为了使用这些模型执行预测任务,原始输入x使用模板修改为一个具有一些未填槽的文本字符串提示x',然后使用语言模型概率地填充未填信息以获得最终字符串x,从中可以得出最终输出y。 这个框架由于多种原因而强大而有吸引力:它允许语言模型在大量原始文本上进行预训练,并通过定义新的提示函数,模型能够执行少量或甚至零量标记数据的学习,适应新场景。在本文中,我们介绍了这个有前途的范式的基础知识,描述了一套统一的数学符号,涵盖了各种现有工作,并沿着几个维度组织了现有工作,例如预训练模型、提示和调整策略的选择。 为了让有兴趣的初学者更容易进入这个领域,我们不仅对现有的作品进行了系统的回顾,并对基于提示的概念进行了高度结构化的分类,而且还发布了其他资源,例如,一个网站这个http URL包含不断更新的调查和论文列表。 |
1 Two Sea Changes in NLP自然语言处理的两次巨变
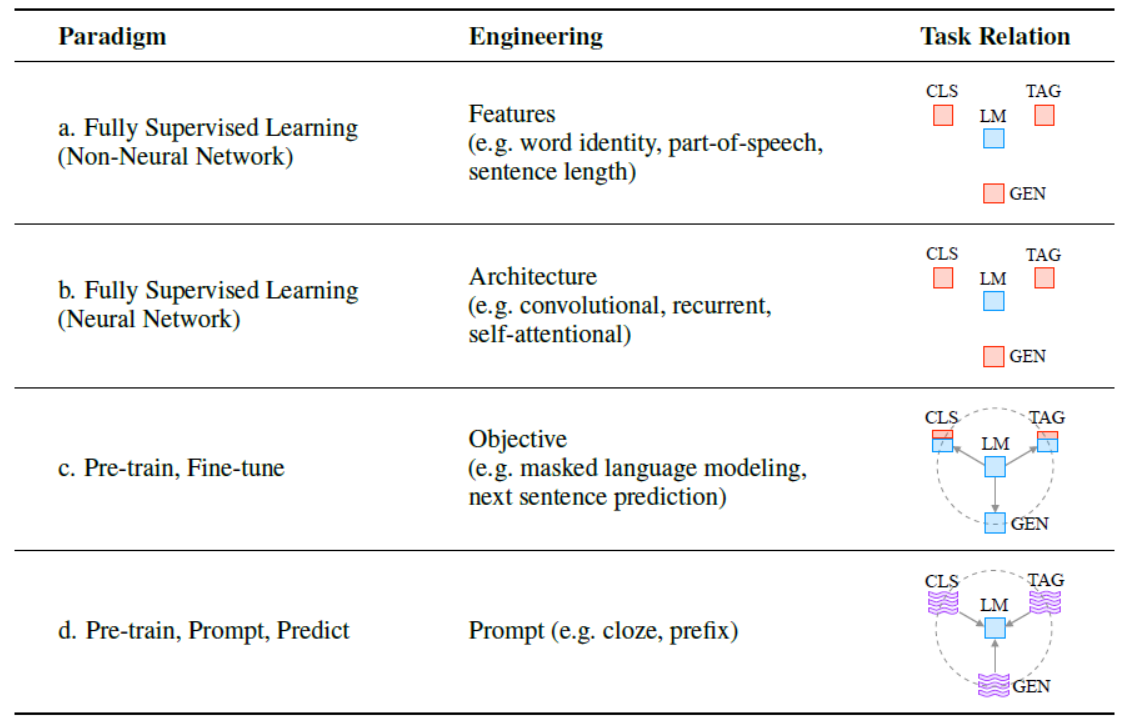
完全监督学习:以机器学习为中心,早期的NLP模型严重依赖特征工程
| Fully supervised learning, where a task-specific model is trained solely on a dataset of input-output examples for the target task, has long played a central role in many machine learning tasks (Kotsiantis et al., 2007), and natural language processing (NLP) was no exception. Because such fully supervised datasets are ever-insufficient for learning high-quality models, early NLP models relied heavily on feature engineering (Tab. 1 a.; e.g. Lafferty et al.(2001); Guyon et al. (2002); Och et al. (2004); Zhang and Nivre (2011)), where NLP researchers or engineers used their domain knowledge to define and extract salient features from raw data and provide models with the appropriate inductive bias to learn from this limited data. With the advent of neural network models for NLP, salient features were learned jointly with the training of the model itself (Collobert et al., 2011; Bengio et al., 2013), and hence focus shifted to architecture engineering, where inductive bias was rather provided through the design of a suitable network architecture conducive to learning such features (Tab. 1 b.; e.g. Hochreiter and Schmidhuber (1997); Kalchbrenner et al. (2014); Chung et al. (2014); Kim (2014); Bahdanau et al. (2014); Vaswani et al. (2017)).1 | 完全监督学习,在这种学习中,一个任务特定的模型仅在目标任务的输入输出示例数据集上进行训练,长期以来在许多机器学习任务(Kotsiantis等,2007)中一直扮演着核心角色,自然语言处理(NLP)也不例外。由于这种完全监督的数据集始终不足以学习高质量的模型,早期的NLP模型严重依赖特征工程(表1a;例如Lafferty等人(2001);Guyon等人(2002);Och等人(2004);Zhang和Nivre(2011)),其中NLP研究人员或工程师利用他们的领域知识从原始数据中定义和提取显著特征,并为模型提供适当的归纳偏差以从有限数据中学习。随着NLP的神经网络模型的出现,显著特征与模型本身的训练一起学习(Collobert等人,2011;Bengio等人,2013),因此焦点转向了架构工程,归纳偏差通过设计适用于学习这些特征的适当网络架构来提供(表1b;例如Hochreiter和Schmidhuber(1997);Kalchbrenner等人(2014);Chung等人(2014);Kim(2014);Bahdanau等人(2014);Vaswani等人(2017))。1 |
预训练-微调范式(2017年起):通用特征
| However, from 2017-2019 there was a sea change in the learning of NLP models, and this fully supervised paradigm is now playing an ever-shrinking role. Specifically, the standard shifted to the pre-train and fine-tune paradigm (Tab. 1 c.; e.g. Radford and Narasimhan (2018); Peters et al. (2018); Dong et al. (2019); Yang et al. (2019); Lewis et al. (2020a)). In this paradigm, a model with a fixed2 architecture is pre-trained as a language model (LM), predicting the probability of observed textual data. Because the raw textual data necessary to train LMs is available in abundance, these LMs can be trained on large datasets, in the process learning robust general-purpose features of the language it is modeling. The above pre-trained LM will be then adapted to different downstream tasks by introducing additional parameters and fine-tuning them using task-specific objective functions. Within this paradigm, the focus turned mainly to objective engineering, designing the training objectives used at both the pre-training and fine-tuning stages. For example, Zhang et al. (2020a) show that introducing a loss function of predicting salient sentences from a document will lead to a better pre-trained model for text summarization. Notably, the main body of the pre-trained LM is generally (but not always; Peters et al. (2019)) fine-tuned as well to make it more suitable for solving the downstream task. | 然而,从2017年到2019年,NLP模型学习发生了翻天覆地的变化,完全监督的范式现在扮演着一个不断缩小的角色。具体而言,标准转向了预训练和微调范式(表1c;例如Radford和Narasimhan(2018);Peters等人(2018);Dong等人(2019);Yang等人(2019);Lewis等人(2020a))。在这个范式中,一个具有固定架构的模型被预训练为语言模型(LM),预测观察到的文本数据的概率。 由于用于训练LM的原始文本数据丰富充裕,这些LM可以在大型数据集上进行训练,从而学习模拟语言的健壮通用特征。然后,上述预训练的LM将通过引入附加参数并使用特定任务的目标函数进行微调,以适应不同的下游任务。 在这个范式中,焦点主要转向了目标工程,设计用于预训练和微调阶段的训练目标。例如,Zhang等人(2020a)表明,引入从文档中预测显著句子的损失函数将导致更好的用于文本摘要的预训练模型。值得注意的是,通常(但并非总是;Peters等人(2019))还对预训练的LM的主体进行微调,以使其更适合解决下游任务。 |
预训练-提示-预测范式(2021年起):给定一套适当的提示,以完全无监督的方式训练的单个LM可用于解决大量任务
| Now, as of this writing in 2021, we are in the middle of a second sea change, in which the “pre-train, fine-tune” procedure is replaced by one in which we dub “pre-train, prompt, and predict”. In this paradigm, instead of adapting pre-trained LMs to downstream tasks via objective engineering, downstream tasks are reformulated to look more like those solved during the original LM training with the help of a textual prompt. For example, when recognizing the emotion of a social media post, “I missed the bus today.”, we may continue with a prompt “I felt so ”, and ask the LM to fill the blank with an emotion-bearing word. Or if we choose the prompt “English: I missed the bus today. French: ”), an LM may be able to fill in the blank with a French translation. In this way, by selecting the appropriate prompts we can manipulate the model behavior so that the pre-trained LM itself can be used to predict the desired output, sometimes even without any additional task-specific training (Tab. 1 d.; e.g. Radford et al. (2019); Petroni et al. (2019); Brown et al. (2020); Raffel et al. (2020); Schick and Sch¨utze (2021b); Gao et al. (2021)). The advantage of this method is that, given a suite of appropriate prompts, a single LM trained in an entirely unsupervised fashion can be used to solve a great number of tasks (Brown et al., 2020; Sun et al., 2021). However, as with most conceptually enticing prospects, there is a catch – this method introduces the necessity for prompt engineering, finding the most appropriate prompt to allow a LM to solve the task at hand. | 截至2021年写作时,我们正处于第二次巨变的中间阶段,其中“预训练、微调”的程序被我们称之为“预训练、提示和预测”的程序所取代。在这个范例中,下游任务不是通过目标工程使预训练的LM适应下游任务,而是在文本提示的帮助下,重新制定下游任务,使其看起来更像原始LM训练期间解决的那些任务。 例如,在识别社交媒体帖子的情感时,“我今天错过了公交车。”,我们可以继续使用提示“I felt so”,并要求LM用一个带有情感的词填空。或者,如果我们选择提示“English: I missed the bus today. French:”),LM可能能够用法语翻译填空。通过选择适当的提示,我们可以操纵模型行为,以便预训练的LM本身可以用于预测所需的输出,有时甚至无需任何额外的任务特定训练(表1d;例如Radford等人(2019);Petroni等人(2019);Brown等人(2020);Raffel等人(2020);Schick和Sch¨utze(2021b);Gao等人(2021))。 这种方法的优势在于,给定一套适当的提示,以完全无监督的方式训练的单个LM可用于解决大量任务(Brown等人,2020;Sun等人,2021)。然而,与大多数概念上引人入胜的前景一样,这种方法也有一个问题 - 这种方法引入了对提示工程的必要性,需要找到最合适的提示以使LM解决手头的任务。 |
本调查:正式定义提示方法
| This survey attempts to organize the current state of knowledge in this rapidly developing field by providing an overview and formal definition of prompting methods (§2), and an overview of the pre-trained language models that use these prompts (§3). This is followed by in-depth discussion of prompting methods, from basics such as prompt engineering (§4) and answer engineering (§5) to more advanced concepts such as multi-prompt learning methods (§6) and prompt-aware training methods (§7). We then organize the various applications to which prompt-based learning methods have been applied, and discuss how they interact with the choice of prompting method (§8). Finally, we attempt to situate the current state of prompting methods in the research ecosystem, making connections to other research fields (§9), suggesting some current challenging problems that may be ripe for further research (§10), and performing a meta-analysis of current research trends (§11). | 本调查试图试图通过提供提示方法(§2)的概述和正式定义以及使用这些提示的预训练语言模型(§3)的概述,来组织这一快速发展领域的当前知识状态。然后,我们深入讨论提示方法,从基础的提示工程(§4)和答案工程(§5)到更高级的概念,如多提示学习方法(§6)和提示感知训练方法(§7)。然后,我们组织了提示学习方法已应用的各种应用,并讨论它们与提示方法选择的互动(§8)。最后,我们尝试将提示方法的当前状态置于研究生态系统中,与其他研究领域建立联系(§9),提出一些可能值得进一步研究的当前具有挑战性的问题(§10),并对当前研究趋势进行元分析(§11)。 |
| Finally, in order to help beginners who are interested in this field learn more effectively, we highlight some systematic resources about prompt learning (as well as pre-training) provided both within this survey and on companion websites: | 最后,为了帮助对这一领域感兴趣的初学者更有效地学习,我们强调了关于提示学习(以及预训练)的一些系统资源,这些资源不仅在本调查中提供,还在相关网站上提供。 |
| A website of prompt-based learning that contains: frequent updates to this survey, related slides, etc. | 一个基于即时学习的网站,包含:调查的频繁更新,相关幻灯片等。 |
Fig.1: A typology of important concepts for prompt-based learning提示式学习的重要概念类型
Table 1: NLP中的四种范式
| Table 1: Four paradigms in NLP. The “engineering” column represents the type of engineering to be done to build strong systems. The “task relation” column, shows the relationship between language models (LM) and other NLP tasks (CLS: classification, TAG: sequence tagging, GEN: text generation).fully unsupervised training. fully supervised training.Supervised training combined with unsupervised training. indicates a textual prompt. Dashed lines suggest that different tasks can be connected by sharing parameters of pre-trained models. “LM!Task”represents adapting LMs (objectives) to downstream tasks while “Task!LM” denotes adapting downstream tasks (formulations) to LMs. | 表格1:自然语言处理中的四种范式。 “工程”列代表构建强大系统所需进行的工程类型。 “任务关系”列显示语言模型(LM)与其他自然语言处理任务( CLS:分类, TAG:序列标注, GEN:文本生成)之间的关系。完全无监督训练。完全监督训练。监督训练结合无监督训练。表示文本提示。虚线表示可以通过共享预训练模型的参数连接不同任务。 “LM!Task”表示将LM(目标)调整到下游任务,而“Task!LM”表示将下游任务(表述)调整到LM。 |
| • Tab.7: A systematic and comprehensive comparison among different prompting methods. • Tab.10: An organization of commonly-used prompts. • Tab.12: A timeline of prompt-based research works. • Tab.13: A systematic and comprehensive comparison among different pre-trained LMs. | • 表7:对不同提示方法进行系统和全面的比较。 • 表10:常用提示的组织形式。 • 表12:基于提示的研究工作的时间表。 • 表13:对不同预训练LM进行系统和全面的比较。 |
2 A Formal Description of Prompting提示的正式描述
2.1 Supervised Learning in NLP监督学习
| In a traditional supervised learning system for NLP, we take an input x, usually text, and predict an output y based on a model P(yjx; _x0012_). y could be a label, text, or other variety of output. In order to learn the parameters _x0012_ of this model, we use a dataset containing pairs of inputs and outputs, and train a model to predict this conditional probability. We will illustrate this with two stereotypical examples. First, text classification takes an input text x and predicts a label y from a fixed label set Y. To give an example, sentiment analysis (Pang et al., 2002; Socher et al., 2013) may take an input x =“I love this movie.” and predict a label y = ++, out of a label set Y = f++; +; ~; -; --g. Second, conditional text generation takes an input x and generates another text y. One example is machine translation (Koehn, 2009), where the input is text in one language such as the Finnish x = “Hyv¨a¨a huomenta.” and the output is the English y = “Good morning”.. | 在传统的自然语言处理监督学习系统中,我们以输入x(通常是文本)为基础,根据模型P(y|x; _x0012_)预测输出y。这里y可以是标签、文本或其他各种输出形式。为了学习这个模型的参数_x0012_,我们使用包含输入和输出配对的数据集,并训练一个模型来预测这个条件概率。我们将通过两个典型的例子来说明这一点。 首先,文本分类接受一个输入文本x并从固定的标签集Y中预测标签y。以情感分析(Pang等,2002;Socher等,2013)为例,可能输入x=“我喜欢这部电影。”并预测一个标签y=++,其中标签集Y={++,+,-,--}。 其次,条件文本生成接受一个输入x并生成另一个文本y。一个例子是机器翻译(Koehn,2009),其中输入是一种语言的文本,如芬兰文x=“Hyv¨a¨a huomenta。”,输出是英文y=“Good morning”。 |
2.2 Prompting Basics提示基础
监督学习的痛点:必须针对任务拥有大量的监督数据
| The main issue with supervised learning is that in order to train a model P (y|x; θ), it is necessary to have supervised data for the task, which for many tasks cannot be found in large amounts. Prompt-based learning methods for NLP attempt to circumvent this issue by instead learning an LM that models the probability P (x; θ) of text x itself (details in §3) and using this probability to predict y, reducing or obviating the need for large supervised datasets. In this section we lay out a mathematical description of the most fundamental form of prompting, which encompasses many works on prompting and can be expanded to cover others as well. Specifically, basic prompting predicts the highest-scoring yˆ in three steps. | 监督学习的主要问题在于,为了训练模型P(y|x; θ),必须针对任务拥有大量的监督数据,而对于许多任务来说,这样的数据是难以找到的。用于自然语言处理的基于提示的学习方法试图通过学习一个LM,该LM对文本x本身的概率P(x; θ)建模(详见第3节),并使用这个概率来预测y,从而减少或消除对大量监督数据的需求。在本节中,我们提供了提示的最基本形式的数学描述,该形式包含了许多提示的工作,并且可以扩展到涵盖其他形式。具体而言,基本提示通过三个步骤预测得分最高的yˆ。 |
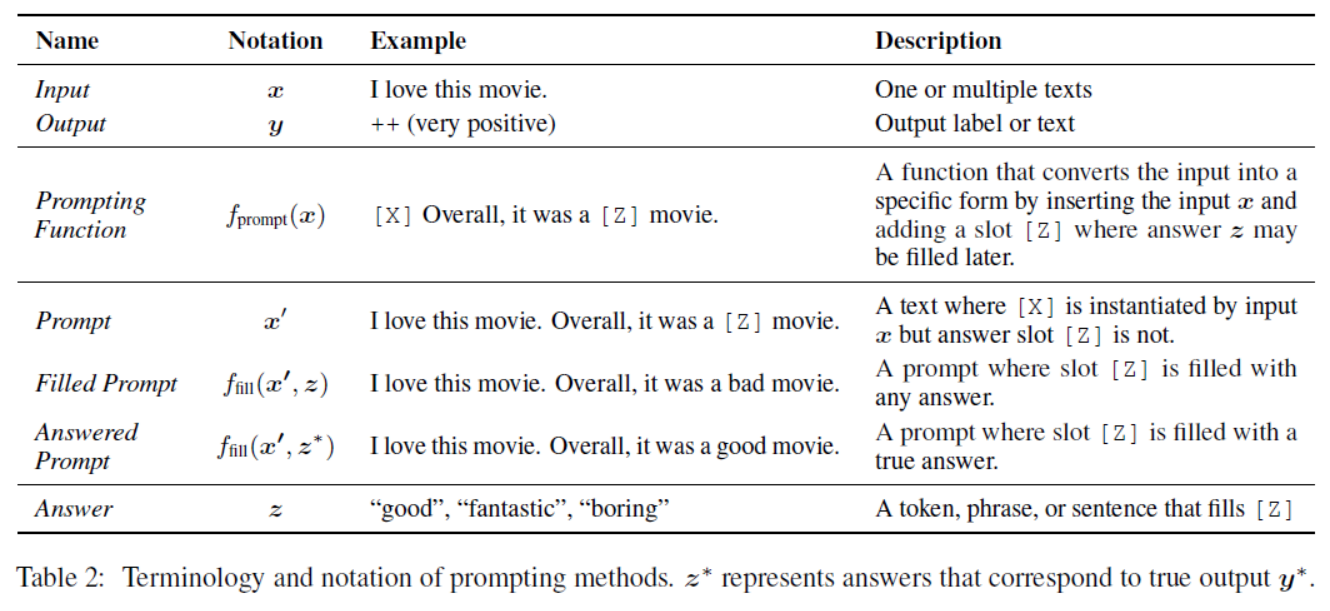
Table 2: Terminology and notation of prompting methods. z∗ represents answers that correspond to true output y∗.提示方法的术语和符号。Z *表示对应于真实输出y *的答案。
2.2.1 Prompt Addition提示添加
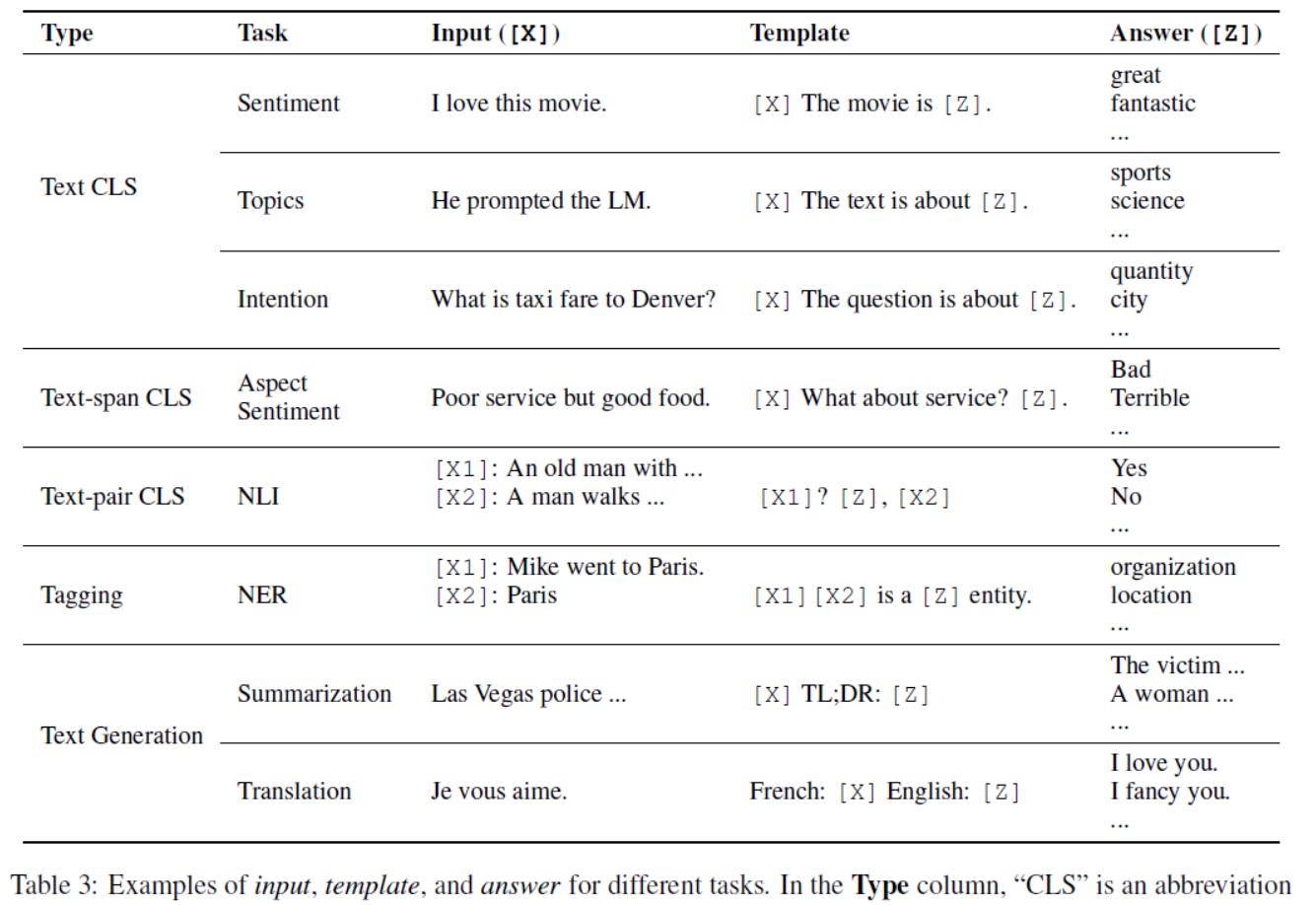
| In this step a prompting function fprompt(·) is applied to modify the input text x into a prompt x = fprompt(x). In the majority of previous work (Kumar et al., 2016; McCann et al., 2018; Radford et al., 2019; Schick and Sch¨utze, 2021a), this function consists of a two step process: >> Apply a template, which is a textual string that has two slots: an input slot [X] for input x and an answer slot [Z] for an intermediate generated answer text z that will later be mapped into y. >> Fill slot [X] with the input text x. In the case of sentiment analysis where x =“I love this movie.”, the template may take a form such as “[X] Overall, it was a [Z] movie.”. Then, x would become “I love this movie. Overall it was a [Z] movie.” given the previous example. In the case of machine translation, the template may take a form such as “Finnish: [X] English:[Z]”, where the text of the input and answer are connected together with headers indicating the language. We show more examples in Tab. 3 | 在此步骤中,使用提示函数fprompt(·)将输入文本x修改为提示符x <s:1> = fprompt(x)。在之前的大部分工作中(Kumar et al., 2016;McCann et al., 2018;Radford等人,2019;Schick and Sch¨utze, 2021a),该函数由两个步骤组成: >>应用一个模板,它是一个文本字符串,有两个槽:一个输入槽[X]用于输入X,一个答案槽[Z]用于中间生成的答案文本Z,稍后将被映射到y。 >>用输入文本X填充槽[X]。 在情感分析中,x =“我喜欢这部电影。,模板可能会采取这样的形式:“总的来说,这是一部[Z]电影。”然后,x <s:1>会变成“我喜欢这部电影。总的来说,这是一部[Z]电影。的问题。在机器翻译的情况下,模板可以采用“芬兰语:[X]英语:[Z]”这样的形式,其中输入和回答的文本与指示语言的标题连接在一起。我们在表3中展示了更多示例 |
| Notably, (1) the prompts above will have an empty slot to fill in for z, either in the middle of the prompt or at the end. In the following text, we will refer to the first variety of prompt with a slot to fill in the middle of the text as a cloze prompt, and the second variety of prompt where the input text comes entirely before z as a prefix prompt. (2) In many cases these template words are not necessarily composed of natural language tokens; they could be virtual words (e.g. represented by numeric ids) which would be embedded in a continuous space later, and some prompting methods even generate continuous vectors directly (more in §4.3.2). (3) The number of [X] slots and the number of [Z] slots can be flexibly changed for the need of tasks at hand. | 值得注意的是, (1)上面的提示符将有一个空槽来填充z,要么在提示符的中间,要么在提示符的末尾。在下面的文本中,我们将把第一种类型的提示符称为完形提示符,这种提示符在文本中间有一个要填充的槽,而第二种类型的提示符(输入文本完全位于z之前)称为前缀提示符。 (2)在许多情况下,这些模板词不一定由自然语言标记组成;它们可以是虚拟词(例如,由数字id表示),稍后将嵌入到连续空间中,一些提示方法甚至直接生成连续向量(详见§4.3.2)。 (3) [X]槽数和[Z]槽数可根据手头任务的需要灵活调整。 |
2.2.2 Answer Search搜索答案
| Next, we search for the highest-scoring text zˆ that maximizes the score of the LM. We first define Z as a set of permissible values for z. Z could range from the entirety of the language in the case of generative tasks, or could be a small subset of the words in the language in the case of classification, such as defining Z = {“excellent”, “good”, f“OK”(,x,“bad”z) , “horrible”} to represent each of the xclasses in Y = {++, +, ~, -, --}. We then define a function fill that fills in the location [Z] in prompt with the potential answer z. We will call any prompt that has gone through this process as a filled prompt. Particularly, if the prompt is filled with a true answer, we will refer to it as an answered prompt (Tab. 2 shows an example). Finally, we search over the set of potential answers z by calculating the probability of their corresponding filled prompts using a pre-trained LM P (·; θ) | 接下来,我们搜索得分最高的文本z *,使LM的得分最大化。我们首先将Z定义为Z的允许值的集合。在生成任务的情况下,Z可以是整个语言,或者在分类的情况下,Z可以是语言中单词的一个小子集,例如定义Z = {" excellent ", " good ", f " OK " (,x <s:1>, " bad " Z), " terrible "}来表示每个xclasses Y ={++, +, ~, -, -}。 然后,我们定义一个函数fill,用可能的答案Z填充prompt中的位置[Z]。我们将调用任何经过此过程的prompt作为已填充的prompt。特别是,如果提示符中填满了真实答案,我们将把它称为已回答的提示符(表2显示了一个示例)。最后,我们通过使用预训练的LM P(·;θ) |
| This search function could be an argmax search that searches for the highest-scoring output, or sampling that randomly generates outputs following the probability distribution of the LM. | 这个搜索函数可以是搜索得分最高的输出的argmax搜索,也可以是根据LM的概率分布随机生成输出的抽样。 |
2.2.3 Answer Mapping答案映射
| Finally, we would like to go from the highest-scoring answer zˆ to the highest-scoring output yˆ. This is trivial in some cases, where the answer itself is the output (as in language generation tasks such as translation), but there are also other cases where multiple answers could result in the same output. For example, one may use multiple different sentiment-bearing words (e.g. “excellent”, “fabulous”, “wonderful”) to represent a single class (e.g. “++”), in which case it is necessary to have a mapping between the searched answer and the output value. | 最后,我们想从得分最高的答案z→到得分最高的输出y→。在某些情况下,这是微不足道的,因为答案本身就是输出(如翻译等语言生成任务),但在其他情况下,多个答案可能会导致相同的输出。例如,可以使用多个不同的带有情感的单词(例如“excellent”,“fabulous”,“wonderful”)来表示单个类(例如“++”),在这种情况下,有必要在搜索的答案和输出值之间有一个映射。 |
Table 3: Examples of input, template, and answer for different tasks. In the Type column, “CLS” is an abbreviation for “classification”. In the Task column, “NLI” and “NER” are abbreviations for “natural language inference” (Bow-man et al., 2015) and “named entity recognition” (Tjong Kim Sang and De Meulder, 2003) respectively.表3:不同任务的输入、模板和答案示例。在“类型”一栏中,“CLS”是“分类”的缩写。在任务栏中,“NLI”和“NER”分别是“自然语言推理”(Bow-man et al., 2015)和“命名实体识别”(Tjong Kim Sang and De Meulder, 2003)的缩写。
2.3 Design Considerations for Prompting提示的设计注意事项
| Now that we have our basic mathematical formulation, we elaborate a few of the basic design considerations that go into a prompting method, which we will elaborate in the following sections: >> Pre-trained Model Choice: There are a wide variety of pre-trained LMs that could be used to calculate P (x; θ). In §3 we give a primer on pre-trained LMs, specifically from the dimensions that are important for interpreting their utility in prompting methods. >> Prompt Engineering: Given that the prompt specifies the task, choosing a proper prompt has a large effect not only on the accuracy, but also on which task the model performs in the first place. In §4 we discuss methods to choose which prompt we should use as fprompt(x). >> Answer Engineering: Depending on the task, we may want to design Z differently, possibly along with the mapping function. In §5 we discuss different ways to do so. >> Expanding the Paradigm: As stated above, the above equations represent only the simplest of the various underlying frameworks that have been proposed to do this variety of prompting. In §6 we discuss ways to expand this underlying paradigm to further improve results or applicability. >> Prompt-based Training Strategies: There are also methods to train parameters, either of the prompt, the LM, or both. In §7, we summarize different strategies and detail their relative advantages. | 现在我们有了基本的数学公式,我们将详细说明提示方法的一些基本设计注意事项,我们将在以下部分详细说明: >>预训练模型选择:有各种各样的预训练LM可用于计算P(x; θ)。在第3节中,我们提供了有关预训练LM的入门知识,特别是从解释其在提示方法中的效用的重要维度。 >>提示工程:考虑到提示指定了任务,选择合适的提示不仅对准确性有很大影响,而且对模型首先执行的任务也有很大影响。在第4节中,我们讨论选择哪个提示作为fprompt(x)的方法。 >>回答工程:根据任务的不同,我们可能希望以不同的方式设计Z,可能还包括映射函数。在第5节中,我们讨论不同的方法来实现这一点。 >>扩展范式:正如前面所述,上述方程只代表了为完成各种提示而提出的各种基础框架中的最简单的一种。在第6节中,我们讨论扩展这个基础范式的方法,以进一步改进结果或适用性。 >>基于提示的训练策略:还有一些方法可以训练参数,无论是提示的参数、LM的参数还是两者兼而有之。在第7节中,我们总结不同的策略并详细说明它们的相对优势。 |
Figure 1: Typology of prompting methods.提示方法的类型。

3 Pre-trained Language Models预训练语言模型
| Given the large impact that pre-trained LMs have had on NLP in the pre-train and fine-tune paradigm, there are already a number of high-quality surveys that interested readers where interested readers can learn more (Raffel et al., 2020; Qiu et al., 2020; Xu et al., 2021; Doddapaneni et al., 2021). Nonetheless, in this chapter we present a systematic view of various pre-trained LMs which (i) organizes them along various axes in a more systematic way, (ii) particularly focuses on aspects salient to prompting methods. Below, we will detail them through the lens of main training objective, type of text noising, auxiliary training objective, attention mask, typical architecture, and preferred application scenarios. We describe each of these objectives below, and also summarize a number of pre-trained LMs along each of these axes in Tab. 13 in the appendix. | 考虑到预训练的LMs在预训练和微调范式中对NLP产生的巨大影响,已经有许多高质量的调查,感兴趣的读者可以在其中了解更多(rafael等人,2020;邱等,2020;Xu et al., 2021;Doddapaneni et al., 2021)。尽管如此,在本章中,我们对各种预训练的LMs提出了一个系统的观点,即(i)以更系统的方式沿着不同的轴组织它们,(ii)特别关注提示方法的突出方面。下面,我们将从主要训练目标、文本降噪类型、辅助训练目标、注意掩模、典型架构、首选应用场景等方面进行详细介绍。我们在下面描述了这些目标,并在附录的表13中总结了沿着这些轴的一些预训练的lm。 |
3.1 Training Objectives目标
4 Prompt Engineering提示工程
| Prompt engineering is the process of creating a prompting function fprompt(x) that results in the most effective performance on the downstream task. In many previous works, this has involved prompt template engineering, where a human engineer or algorithm searches for the best template for each task the model is expected to perform. As shown in the “Prompt Engineering” section of Fig.1, one must first consider the prompt shape, and then decide whether to take a manual or automated approach to create prompts of the desired shape, as detailed below. | 提示工程是创建一个提示函数fprompt(x)的过程,该函数在下游任务上产生最有效的性能。在许多先前的工作中,这涉及到提示模板工程,其中人类工程师或算法搜索每个模型预计执行的任务的最佳模板。必须首先考虑提示形状,然后决定是采用手动方法还是自动方法来创建所需形状的提示。 |
4.1 Prompt Shape提示形状
两种提示:完形填空提示(更适合Mask任务)、前缀提示(更适合标准自回归生成任务)
| As noted above, there are two main varieties of prompts: cloze prompts (Petroni et al., 2019; Cui et al., 2021), which fill in the blanks of a textual string, and prefix prompts (Li and Liang, 2021; Lester et al., 2021), which continue a string prefix. Which one is chosen will depend both on the task and the model that is being used to solve the task. In general, for tasks regarding generation, or tasks being solved using a standard auto-regressive LM, prefix prompts tend to be more conducive, as they mesh well with the left-to-right nature of the model. For tasks that are solved using masked LMs, cloze prompts are a good fit, as they very closely match the form of the pre-training task. Full text reconstruction models are more versatile, and can be used with either cloze or prefix prompts. Finally, for some tasks regarding multiple inputs such as text pair classification, prompt templates must contain space for two inputs,[X1] and [X2], or more. | 如上所述,提示有两种主要变体: 完形填空提示(Petroni等,2019; Cui等,2021),用于填充文本字符串的空白,和 前缀提示(Li和Liang,2021; Lester等,2021),用于延续字符串前缀。 选择哪一种将取决于任务和用于解决任务的模型。 一般来说,对于涉及生成的任务或使用标准自回归LM解决的任务,前缀提示往往更有助益,因为它们与模型的从左到右的性质很好地契合。 对于使用蒙版LM解决的任务,完形填空提示是一个很好的选择,因为它们与预训练任务的形式非常相似。完整的文本重建模型更加灵活,可以与cloze或前缀提示一起使用。 最后,对于涉及多个输入的一些任务,如文本对分类,提示模板必须包含两个或更多输入的空间,[X1]和[X2],或更多。 |
4.2 Manual Template Engineering手动模板工程
| Perhaps the most natural way to create prompts is to manually create intuitive templates based on human introspec-tion. For example, the seminal LAMA dataset (Petroni et al., 2019) provides manually created cloze templates to probe knowledge in LMs. Brown et al. (2020) create manually crafted prefix prompts to handle a wide variety of tasks, including question answering, translation, and probing tasks for common sense reasoning. Schick and Sch¨utze (2020, 2021a,b) use pre-defined templates in a few-shot learning setting on text classification and conditional text generation tasks. | 创建提示的最自然的方式可能是根据人的直觉手动创建直观的模板。例如,具有开创性的LAMA数据集(Petroni等,2019)提供了手动创建的cloze完形模板,用于探索LM中的知识。 Brown等人(2020)通过手动制作的前缀提示来处理各种任务,包括问答、翻译和常识推理的探测任务。 Schick和Sch¨utze(2020, 2021a,b)在文本分类和条件文本生成任务的few-shot学习环境中使用预定义的模板。 |
4.3 Automated Template Learning模板自动学习
手动模板的痛点:需要时间和经验、无法手动发现最佳提示
| While the strategy of manually crafting templates is intuitive and does allow solving various tasks with some degree of accuracy, there are also several issues with this approach: (1) creating and experimenting with these prompts is an art that takes time and experience, particularly for some complicated tasks such as semantic parsing (Shin et al., 2021); (2) even experienced prompt designers may fail to manually discover optimal prompts (Jiang et al., 2020c). To address these problems, a number of methods have been proposed to automate the template design process. In particular, the automatically induced prompts can be further separated into discrete prompts, where the prompt is an actual text string, and continuous prompts, where the prompt is instead described directly in the embedding space of the underlying LM. One other orthogonal design consideration is whether the prompting function fprompt(x) is static, using essentially the same prompt template for each input, or dynamic, generating a custom template for each input. Both static and dynamic strategies have been used for different varieties of discrete and continuous prompts, as we will mention below. | 虽然手工制作模板的策略是直观的,并且允许以一定程度的准确性解决各种任务,但这种方法也存在几个问题: (1)创建和试验这些提示是一门需要时间和经验的艺术,特别是对于一些复杂的任务,如语义解析(Shin等人,2021); (2)即使经验丰富的提示设计师也可能无法手动发现最佳提示(Jiang et al., 2020c)。 为了解决这些问题,已经提出了许多方法来自动化模板设计过程。特别是,自动诱导提示可以进一步分为离散提示和连续提示,前者的提示是一个实际的文本字符串,后者的提示直接在底层LM的嵌入空间中描述。 另一个正交设计考虑因素是提示函数fprompt(x)是静态的(对每个输入使用相同的提示模板)还是动态的(为每个输入生成自定义模板)。静态和动态策略都用于不同种类的离散和连续提示,我们将在下面提到。 |
4.3.1 Discrete Prompts离散提示/硬提示:
| Works on discovering discrete prompts (a.k.a hard prompts) automatically search for templates described in a discrete space, usually corresponding to natural language phrases. We detail several methods that have been proposed for this below: | 用于发现离散提示(又名硬提示),自动搜索在离散空间中描述的模板,通常对应于自然语言短语。我们详细介绍了为此提出的几种方法: |
D1: 提示挖掘:频繁出现的中间词或依赖路径
| D1: Prompt Mining Jiang et al. (2020c)’s MINE approach is a mining-based method to automatically find templates given a set of training inputs x and outputs y. This method scrapes a large text corpus (e.g. Wikipedia) for strings containing x and y, and finds either the middle words or dependency paths between the inputs and outputs. Frequent middle words or dependency paths can serve as a template as in “[X] middle words [Z]”. | D1: Jiang等人(2020c)的MINE方法是一种基于挖掘的方法,可以在给定一组训练输入x和输出y的情况下自动找到模板。该方法为包含x和y的字符串抓取大型文本语料库(例如Wikipedia),并找到中间单词或输入和输出之间的依赖路径。频繁出现的中间词或依赖路径可以作为模板,如“[X]中间词[Z]”。 |
D2: 提示重述
| D2: Prompt Paraphrasing Paraphrasing-based approaches take in an existing seed prompt (e.g. manually constructed or mined), and paraphrases it into a set of other candidate prompts, then selects the one that achieves the highest training accuracy on the target task. This paraphrasing can be done in a number of ways, including using round-trip translation of the prompt into another language then back (Jiang et al., 2020c), using replacement of phrases from a thesaurus (Yuan et al., 2021b), or using a neural prompt rewriter specifically optimized to improve accuracy of systems using the prompt (Haviv et al., 2021). Notably, Haviv et al. (2021) perform paraphrasing after the input x is input into the prompt template, allowing a different paraphrase to be generated for each individual input. | D2: 基于释义的方法采用现有的种子提示(例如手动构建或挖掘),并将其释义为一组其他候选提示,然后选择在目标任务上达到最高训练精度的提示。这种释义可以通过多种方式完成,包括将提示语往返翻译成另一种语言,然后再返回(Jiang等人,2020c),使用替换词库中的短语(Yuan等人,2021b),或者使用专门优化的神经提示重写器来提高使用提示的系统的准确性(Haviv等人,2021)。值得注意的是,Haviv等人(2021)在输入x输入到提示模板后执行释义,允许为每个单独的输入生成不同的释义。 |
D3: 基于梯度的搜索
| D3: Gradient-based Search Wallace et al. (2019a) applied a gradient-based search over actual tokens to find short sequences that can trigger the underlying pre-trained LM to generate the desired target prediction. This search is done in an iterative fashion, stepping through tokens in the prompt . Built upon this method, Shin et al. (2020) automatically search for template tokens using downstream application training samples and demonstrates strong performance in prompting scenarios. | D3: Wallace等人(2019a)对实际令牌应用了基于梯度的搜索,以找到可以触发底层预训练LM以生成所需目标预测的短序列。此搜索以迭代的方式完成,逐步遍历提示中的令牌。在此方法的基础上,Shin等人(2020)使用下游应用程序训练样本自动搜索模板令牌,并在提示场景中展示了强大的性能。 |
D4: 提示生成
| D4: Prompt Generation Other works treat the generation of prompts as a text generation task and use standard natural language generation models to perform this task. For example, Gao et al. (2021) introduce the seq2seq pre-trained model T5 into the template search process. Since T5 has been pre-trained on a task of filling in missing spans, they use T5 to generate template tokens by (1) specifying the position to insert template tokens within a template4 (2) provide training samples for T5 to decode template tokens. Ben-David et al. (2021) propose a domain adaptation algorithm that trains T5 to generate unique domain relevant features (DRFs; a set of keywords that characterize domain information) for each input. Then those DRFs can be concatenated with the input to form a template and be further used by downstream tasks. | D4:提示符生成 其他作品将提示符的生成视为文本生成任务,并使用标准的自然语言生成模型来执行该任务。例如, Gao等人(2021)将seq2seq预训练模型T5引入模板搜索过程。由于T5已经在填充缺失的跨度的任务上进行了预训练,他们使用T5通过(1)指定在模板中插入模板令牌的位置(2)为T5解码模板令牌提供训练样本来生成模板令牌。 Ben-David等人(2021)提出了一种领域自适应算法,该算法训练T5生成唯一的领域相关特征(DRF;表征领域信息的关键词集)。然后,这些DRF可以与输入连接以形成模板,并进一步由下游任务使用。 |
D5: 提示评分
| D5: Prompt Scoring Davison et al. (2019) investigate the task of knowledge base completion and design a template for an input (head-relation-tail triple) using LMs. They first hand-craft a set of templates as potential candidates, and fill the input and answer slots to form a filled prompt. They then use a unidirectional LM to score those filled prompts, selecting the one with the highest LM probability. This will result in custom template for each individual input. | Davison等人(2019)研究知识库完成任务,并使用LM设计了一个输入(头-关系-尾三元组)的模板。他们首先手工制作一组模板作为潜在候选项,并填充输入和答案插槽以形成填充的提示。然后,他们使用单向LM对这些填充的提示进行评分,选择具有最高LM概率的提示。这将导致每个单独输入的定制模板。 |
4.3.2 Continuous Prompts连续提示/软提示:直接在模型的嵌入空间中进行提示
| Because the purpose of prompt construction is to find a method that allows an LM to effectively perform a task, rather than being for human consumption, it is not necessary to limit the prompt to human-interpretable natural language. Because of this, there are also methods that examine continuous prompts (a.k.a. soft prompts) that perform prompting directly in the embedding space of the model. Specifically, continuous prompts remove two constraints:(1) relax the constraint that the embeddings of template words be the embeddings of natural language (e.g., English) words. (2) Remove the restriction that the template is parameterized by the pre-trained LM’s parameters. Instead, templates have their own parameters that can be tuned based on training data from the downstream task. We highlight several representative methods below. | 因为提示构建的目的是找到一种方法,使LM能够有效地执行任务,而不是为了人类理解,所以没有必要将提示限制为可解释的自然语言。 正因为如此,还有一些方法研究连续提示(又称软提示),直接在模型的嵌入空间中进行提示。具体来说,连续提示消除了两个约束: (1)放宽了模板词的嵌入必须是自然语言(如英语)词的嵌入的约束。 (2)去掉模板被预训练LM的参数化的限制。相反,模板有自己的参数,这些参数可以根据来自下游任务的训练数据进行调优。 我们在下面重点介绍几个有代表性的方法。 |
C1: Prefix Tunin前缀调优:在输入之前添加一系列连续的任务特定向量的方法+保持LM参数冻结
| C1: Prefix Tuning Prefix Tuning (Li and Liang, 2021) is a method that prepends a sequence of continuous task-specific vectors to the input, while keeping the LM parameters frozen. Mathematically, this consists of optimizing over the following log-likelihood objective given a trainable prefix matrix Mφ and a fixed pre-trained LM parameterized by θ. In Eq. 2, h<i = [h(1); · · · ; h(<in)] is the concatenation of all neural network layers at time step i. It is copied from <i Mφ directly if the corresponding time step is within the prefix (hi is Mφ[i]), otherwise it is computed using the pre-trained LM. | 前缀调优(Li and Liang, 2021)是一种在输入之前添加一系列连续的任务特定向量的方法,同时保持LM参数冻结。 在数学上,这包括对以下对数似然目标进行优化,给定一个可训练的前缀矩阵Mφ和一个由θ参数化的固定预训练LM。 式2中,h<i = [h(1)];···;h(<in)]是所有神经网络层在时间步长i处的连接。如果对应的时间步长在前缀内(hi为Mφ[i]),则直接从<i Mφ复制,否则使用预训练的LM计算。 |
| Experimentally, Li and Liang (2021) observe that such continuous prefix-based learning is more sensitive to different initialization in low-data settings than the use of discrete prompts with real words. Similarly, Lester et al.(2021) prepend the input sequence with special tokens to form a template and tune the embeddings of these tokens directly. Compared to Li and Liang (2021)’s method, this adds fewer parameters as it doesn’t introduce additional tunable parameters within each network layer. Tsimpoukelli et al. (2021) train a vision encoder that encodes an image into a sequence of embeddings that can be used to prompt a frozen auto-regressive LM to generate the appropriate caption. They show that the resulting model can perform few-shot learning for vision-language tasks such as visual question answering etc. Different from the above two works, the prefix used in (Tsimpoukelli et al., 2021) is sample-dependent, namely a representation of input images, instead of a task embedding. | 通过实验, Li和Liang(2021)观察到,在低数据设置下,这种基于前缀的连续学习比使用真实单词的离散提示对不同初始化更敏感。 同样,Lester等人(2021)在输入序列前加上特殊的标记以形成模板,并直接调整这些标记的嵌入。 与Li和Liang(2021)的方法相比,这种方法添加的参数更少,因为它没有在每个网络层中引入额外的可调参数。 Tsimpoukelli等人(2021)训练了一个视觉编码器,该编码器将图像编码为一系列嵌入,可用于提示冻结的自回归LM生成适当的标题。 结果表明,该模型可以在视觉问答等视觉语言任务中进行少样本学习。与上述两部作品不同的是,(Tsimpoukelli et al., 2021)中使用的前缀是样本相关的,即输入图像的表示,而不是任务嵌入。 |
C2: Tuning Initialized with Discrete Prompts使用离散提示初始化调优
| C2: Tuning Initialized with Discrete Prompts There are also methods that initialize the search for a continuous prompt using a prompt that has already been created or discovered using discrete prompt search methods. For example, Zhong et al. (2021b) first define a template using a discrete search method such as AUTOPROMPT (Shin et al., 2020)’s, initialize virtual tokens based on this discovered prompt, then fine-tune the embeddings to increase task accuracy. This work found that initializing with manual templates can provide a better starting point for the search process. Qin and Eisner (2021) propose to learn a mixture of soft templates for each input where the weights and parameters for each template are jointly learned using training samples. The initial set of templates they use are either manually crafted ones or those obtained using the “prompt mining” method. Similarly, Hambardzumyan et al.(2021) introduce the use of a continuous template whose shape follows a manual prompt template. | C2:使用离散提示初始化的调优 还有一些方法,它们使用已经使用离散提示搜索方法创建或发现的提示初始化对连续提示的搜索。例如, Zhong等人(2021b)首先使用AUTOPROMPT (Shin等人,2020)等离散搜索方法定义模板,根据发现的提示初始化虚拟令牌,然后对嵌入进行微调以提高任务准确性。这项工作发现,使用手动模板进行初始化可以为搜索过程提供更好的起点。 Qin和Eisner(2021)提出为每个输入学习软模板的混合,其中每个模板的权重和参数使用训练样本共同学习。他们使用的初始模板要么是手工制作的,要么是使用“提示挖掘”方法获得的模板。 类似地,Hambardzumyan等人(2021)介绍了连续模板的使用,其形状遵循手动提示模板。 |
C3: Hard-Soft Prompt Hybrid Tuning硬-软提示混合调优:如P-tuning
| C3: Hard-Soft Prompt Hybrid Tuning Instead of using a purely learnable prompt template, these methods insert some tunable embeddings into a hard prompt template. Liu et al. (2021b) propose “P-tuning”, where continuous prompts are learned by inserting trainable variables into the embedded input. To account for interaction between prompt tokens, they represent prompt embeddings as the output of a BiLSTM (Graves et al., 2013). P-tuning also introduces the use of task-related anchor tokens (such as “capital” in relation extraction) within the template for further improvement. These anchor tokens are not tuned during training. Han et al. (2021) propose prompt tuning with rules (PTR), which uses manually crafted sub-templates to compose a complete template using logic rules. To enhance the representation ability of the resulting template, they also insert several virtual tokens whose embeddings can be tuned together with the pre-trained LMs parameters using training samples. The template tokens in PTR contain both actual tokens and virtual tokens. Experiment results demonstrate the effectiveness of this prompt design method in relation classification tasks. | 硬-软提示混合调优 这些方法不是使用纯粹可学习的提示模板,而是在硬提示模板中插入一些可调的嵌入。 Liu等人(2021b)提出了“P-tuning”,通过在嵌入的输入中插入可训练的变量来学习连续提示。为了考虑提示标记之间的相互作用,他们将提示嵌入表示为BiLSTM的输出(Graves等人,2013)。P-tuning还在模板中引入了与任务相关的锚标记(例如关系提取中的“大写”)的使用,以便进一步改进。这些锚标记在训练期间没有进行调优。 Han等人(2021)提出使用规则(PTR)进行提示调优,它使用手动制作的子模板来使用逻辑规则组成完整的模板。为了增强结果模板的表示能力,他们还插入了几个虚拟标记,这些标记的嵌入可以使用训练样本与预训练的LMs参数一起进行调优。PTR中的模板令牌包含实际令牌和虚拟令牌。实验结果证明了该提示设计方法在关系分类任务中的有效性。 |
6、Multi-Prompt Learning多提示学习
| The prompt engineering methods we discussed so far focused mainly on constructing a single prompt for an input. However, a significant body of research has demonstrated that the[useX]of multiple oglprompts can furtherMASK]improve the efficacy of prompting methods, and we willubcall thesePmethods multi-prompt learning methods. In practice, there are several ways to extend the single prompt learning to the use multiple prompts, which have a variety of motivations. We summarize representative methods in the “Multi-prompt Learning” section of Fig.1 as well as Fig.4. | 到目前为止,我们讨论的提示工程方法主要集中于为输入构造单个提示。然而,大量的研究表明,使用多个提示可以进一步改善提示方法的效果,,我们将这些方法称为多提示学习方法。在实践中,有几种方法可以将单提示学习扩展到使用多个提示,这些提示有各种各样的动机。我们在图1和图4的“Multi-prompt Learning”部分总结了具有代表性的方法。 |
6.1 Prompt Ensembling提示合成器
| Prompt ensembling is the process of using multiple unanswered prompts for an input at inference time to make predictions. An example is shown in Fig. 4-(a). The multiple prompts can either be discrete prompts or continuous prompts.5 This sort ofX]prompt eensembling can (1) leverage the ogllcomplementary advantages of different prompts, (2)MASK]MASK] alleviate the cost of prompt engineering, since choosing one best-performing prompt is challenging, (3) stabilize performance on downstream tasks. Prompt ensembling is connected to ensembling methods that are used to combine together multiple systems, which have a long history in machine learning (Ting and Witten, 1997; Zhou et al., 2002; Duh et al., 2011). Current research also borrows ideas from these works to derive effective ways for prompt ensembling, as described below. | 提示集成是在推理时对输入使用多个未回答的提示进行预测的过程。图4-(a)是一个例子。多个提示可以是离散提示,也可以是连续提示这种类型的提示集成可以 (1)利用不同提示的互补优势, (2)降低提示工程的成本,因为选择一个性能最佳的提示是具有挑战性的, (3)稳定下游任务的性能。 提示集成与用于将多个系统组合在一起的集成方法有关,这在机器学习中具有悠久的历史(Ting和Witten, 1997;Zhou et al., 2002;Duh et al., 2011)。当前的研究还从这些工作中借鉴思想,以得出用于提示合奏的有效方法,如下所述。 |
12 Conclusion
| In this paper, we have summarized and analyzed several paradigms in the development of statistical natural language processing techniques, and have argued that prompt-based learning is a promising new paradigm that may represent another major change in the way we look at NLP. First and foremost, we hope this survey will help researchers more effectively and comprehensively understand the paradigm of prompt-based learning, and grasp its core challenges so that more scientifically meaningful advances can be made in this field. In addition, looking all the way back to the summary of the four paradigms of NLP research presented in §1, we hope to highlight the commonalities and differences between them, making research on any of these paradigms more full-fledged, and potentially providing a catalyst to inspire work towards the next paradigm shift as well. | 在本文中,我们总结并分析了统计自然语言处理技术发展中的几个范式,并认为基于提示的学习是一种有前途的新范式,可能代表了我们看待NLP的另一次重大变革。首先,我们希望这份调查能够帮助研究人员更有效、更全面地了解基于提示的学习范式,并掌握其核心挑战,以便在这一领域取得更具科学意义的进展。此外,回顾在第1节中呈现的NLP研究的四个范式的总结,我们希望突显它们之间的共同点和差异,使对其中任何一个范式的研究更加全面,并激发对下一次范式转变的工作的启示。 |

















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











