









 本文介绍了SQLCoder,一款强大的LLM,专门用于将自然语言问题转译成SQL查询。文章详细讲解了SQLCoder的介绍、安装过程、硬件需求,以及在Colab中使用的步骤。模型性能优于其他大模型,如GPT-3.5-turbo和Text-Davinci-003。
本文介绍了SQLCoder,一款强大的LLM,专门用于将自然语言问题转译成SQL查询。文章详细讲解了SQLCoder的介绍、安装过程、硬件需求,以及在Colab中使用的步骤。模型性能优于其他大模型,如GPT-3.5-turbo和Text-Davinci-003。
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
目录
SQLCoder的简介
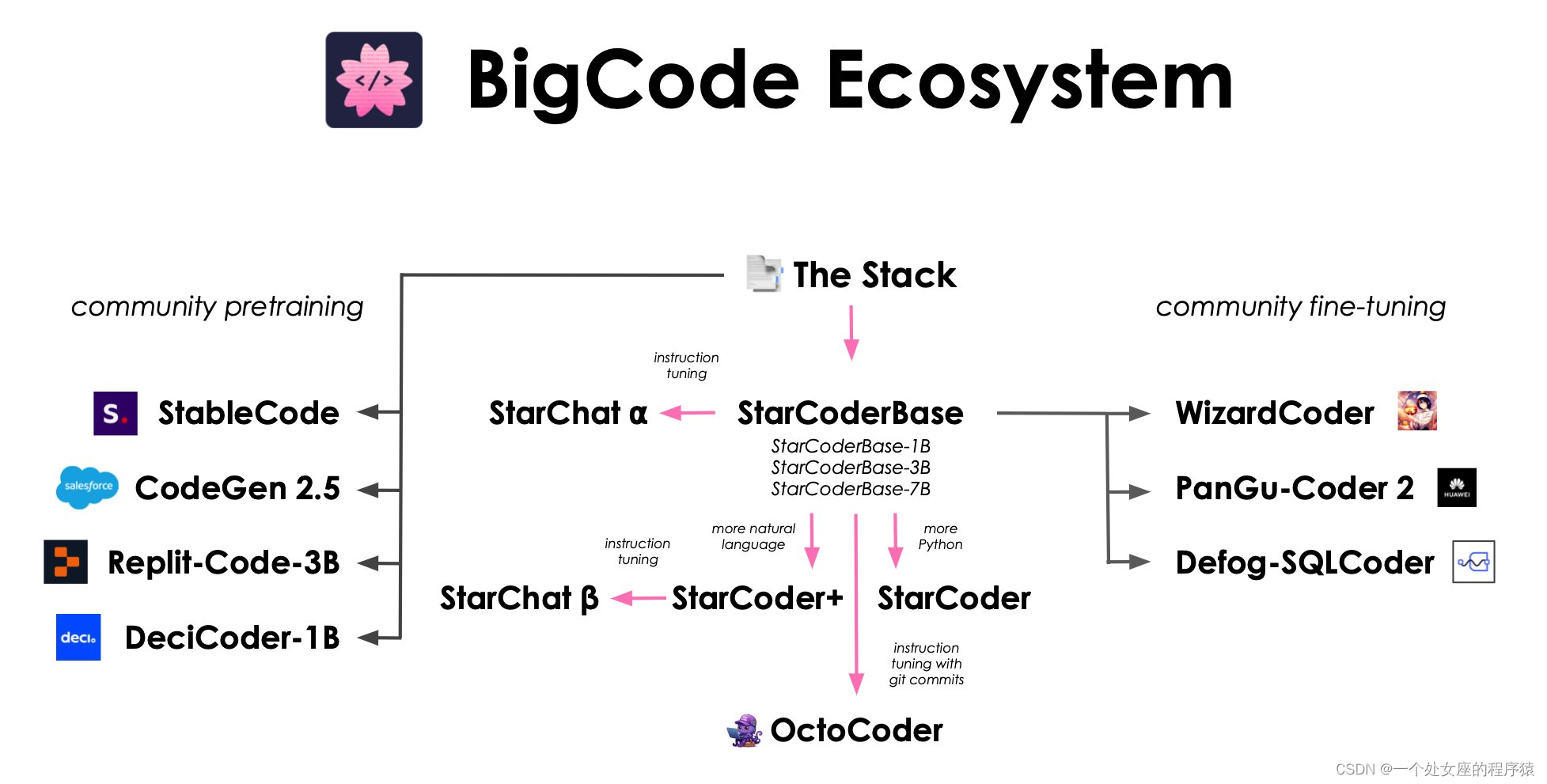
2023年8月,发布了SQLCoder,这是一个先进的LLM,用于将自然语言问题转换为SQL查询。SQLCoder在基础的StarCoder模型上进行了微调。SQLCoder是一个拥有150亿参数的模型,在我们的sql-eval框架上,它在自然语言到SQL生成任务上胜过了gpt-3.5-turbo,并且在所有流行的开源模型中表现显著。它还明显优于大小超过10倍的text-davinci-003模型。
Defog在2个时期内对10537个经过人工筛选的问题进行了训练。这些问题基于10个不同的模式。在训练数据中,没有包括评估框架中的任何模式。
训练分为2个阶段。第一阶段是关于被分类为“容易”或“中等”难度的问题,第二阶段是关于被分类为“困难”或“超级困难”难度的问题。
在easy+medium数据上的训练结果存储在一个名为defog-easy的模型中。我们发现在hard+extra-hard数据上的额外训练导致性能增加了7个百分点。
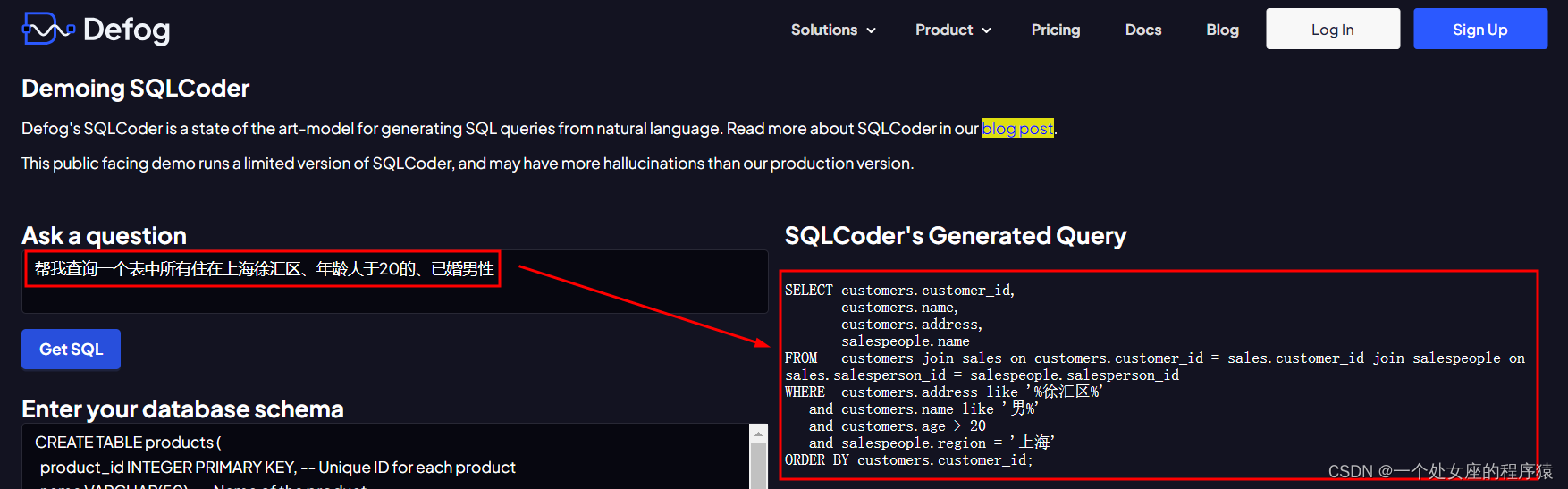
官网在线测试:https://defog.ai/sqlcoder-demo/
GitHub官网:GitHub - defog-ai/sqlcoder: SoTA LLM for converting natural language questions to SQL queries
1、结果
| model | perc_correct |
| gpt-4 | 74.3 |
| defog-sqlcoder | 64.6 |
| gpt-3.5-turbo | 60.6 |
| defog-easysql | 57.1 |
| text-davinci-003 | 54.3 |
| wizardcoder | 52.0 |
| starcoder | 45.1 |
2、按问题类别的结果
我们将每个生成的问题分类为5个类别之一。该表显示了每个模型按类别细分的正确回答问题的百分比。
| query_category | gpt-4 | defog-sqlcoder | gpt-3.5-turbo | defog-easy | text-davinci-003 | wizard-coder | star-coder |
| group_by | 82.9 | 77.1 | 71.4 | 62.9 | 62.9 | 68.6 | 54.3 |
| order_by | 71.4 | 65.7 | 60.0 | 68.6 | 60.0 | 54.3 | 57.1 |
| ratio | 62.9 | 57.1 | 48.6 | 40.0 | 37.1 | 22.9 | 17.1 |
| table_join | 74.3 | 57.1 | 60.0 | 54.3 | 51.4 | 54.3 | 51.4 |
| where | 80.0 | 65.7 | 62.9 | 60.0 | 60.0 | 60.0 | 45.7 |
SQLCoder的安装
1、硬件要求
SQLCoder已在A100 40GB GPU上进行了测试,使用bfloat16权重。您还可以在具有20GB或更多内存的消费者GPU上加载8位和4位量化版本的模型。例如RTX 4090、RTX 3090以及具有20GB或更多内存的Apple M2 Pro、M2 Max或M2 Ultra芯片。
2、下载模型权重
地址:defog/sqlcoder · Hugging Face
3、使用SQLCoder
您可以通过transformers库使用SQLCoder,方法是从Hugging Face存储库中下载我们的模型权重。我们已添加了有关在示例数据库架构上进行推断的示例代码。
python inference.py -q "Question about the sample database goes here"示例问题:我们与纽约的客户相比,从旧金山的客户那里获得更多收入吗?为我提供每个城市的总收入以及两者之间的差异。您还可以在我们的网站上使用演示,或在Colab中运行SQLCoder。
4、Colab中运行SQLCoder
第一步,配置环境
!pip install torch transformers bitsandbytes accelerate第二步,测试
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
torch.cuda.is_available()第三步,下载模型
使用Colab Pro上的A100(或具有> 30GB VRAM的任何系统)在bf16中加载它。如果不可用,请使用至少具有20GB VRAM的GPU在8位中加载它,或者至少具有12GB VRAM在4位中加载它。在Colab上,它适用于V100,但在T4上崩溃。
首次下载模型然后将其加载到内存中的步骤大约需要10分钟。所以请耐心等待 :)
model_name = "defog/sqlcoder"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
# torch_dtype=torch.bfloat16,
# load_in_8bit=True,
load_in_4bit=True,
device_map="auto",
use_cache=True,
)第四步,设置问题和提示并进行标记化
随意更改以下问题。如果您想要尝试自己的数据库架构,请在提示中编辑模式。
question = "What product has the biggest fall in sales in 2022 compared to 2021? Give me the product name, the sales amount in both years, and the difference."
prompt = """### Instructions:
Your task is to convert a question into a SQL query, given a Postgres database schema.
Adhere to these rules:
- **Deliberately go through the question and database schema word by word** to appropriately answer the question
- **Use Table Aliases** to prevent ambiguity. For example, `SELECT table1.col1, table2.col1 FROM table1 JOIN table2 ON table1.id = table2.id`.
- When creating a ratio, always cast the numerator as float
### Input:
Generate a SQL query that answers the question `{question}`.
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (
product_id INTEGER PRIMARY KEY, -- Unique ID for each product
name VARCHAR(50), -- Name of the product
price DECIMAL(10,2), -- Price of each unit of the product
quantity INTEGER -- Current quantity in stock
);
CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY, -- Unique ID for each customer
name VARCHAR(50), -- Name of the customer
address VARCHAR(100) -- Mailing address of the customer
);
CREATE TABLE salespeople (
salesperson_id INTEGER PRIMARY KEY, -- Unique ID for each salesperson
name VARCHAR(50), -- Name of the salesperson
region VARCHAR(50) -- Geographic sales region
);
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale
product_id INTEGER, -- ID of product sold
customer_id INTEGER, -- ID of customer who made purchase
salesperson_id INTEGER, -- ID of salesperson who made the sale
sale_date DATE, -- Date the sale occurred
quantity INTEGER -- Quantity of product sold
);
CREATE TABLE product_suppliers (
supplier_id INTEGER PRIMARY KEY, -- Unique ID for each supplier
product_id INTEGER, -- Product ID supplied
supply_price DECIMAL(10,2) -- Unit price charged by supplier
);
-- sales.product_id can be joined with products.product_id
-- sales.customer_id can be joined with customers.customer_id
-- sales.salesperson_id can be joined with salespeople.salesperson_id
-- product_suppliers.product_id can be joined with products.product_id
### Response:
Based on your instructions, here is the SQL query I have generated to answer the question `{question}`:
```sql
""".format(question=question)
eos_token_id = tokenizer.convert_tokens_to_ids(["```"])[0]第五步,生成SQL
在具有4位量化的V100上可能非常缓慢。每个查询可能需要大约1-2分钟。在单个A100 40GB上,需要大约10-20秒。
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=eos_token_id,
pad_token_id=eos_token_id,
max_new_tokens=400,
do_sample=False,
num_beams=5
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
torch.cuda.empty_cache()
torch.cuda.synchronize()
# 清空缓存,以便在内存崩溃时可以生成更多结果
# 在Colab上特别重要 - 内存管理要简单得多
# 在运行推断服务时
# 嗯!生成的SQL在这里:
print(outputs[0].split("```sql")[-1].split("```")[0].split(";")[0].strip() + ";")
SQLCoder的使用方法
更新中……



















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











