










LLMs之Tool:screenpipe(OCR+RAG)的简介、安装和使用方法、案例应用
目录
Screenpipe 简介

2024年7月,Screenpipe 是一个由 rewind.ai 和 cursor.com 联合开发的 AI 助理,它能够进行 24/7 的屏幕和语音录制,旨在为超级智能时代做好数据准备。其目标是让用户拥有所有上下文信息的 AI 助手。项目标语为“recording reality, one pixel at a time”。 Screenpipe 在 GitHub 上非常活跃,曾多次荣登趋势榜首,并获得了 Founders, Inc 的支持。 它还拥有一个插件系统,允许用户创建和分享自定义插件(pipes)。
Screenpipe 提供了一个全面的数据采集和 AI 辅助工具,其应用范围广泛,有待于用户进一步探索和开发。 项目本身积极响应社区反馈,鼓励用户贡献代码和反馈问题。
Screenpipe 通过本地运行、全方位数据捕获、强大的AI处理能力和可扩展的插件系统,为用户提供了一个高效、私密且功能强大的个人AI助手。 其目标是帮助用户提高生产力,并更好地管理和利用自己的数字生活数据。
官网:screenpipe
1、特点
Screenpipe是一个跨平台的开源开发工具,它在用户设备本地运行,能够捕获所有桌面活动,包括音频、屏幕和UI交互。其核心特点可以概括为以下几点:
>> 全方位记录:记录所有桌面活动,包括屏幕录制、音频录制以及用户交互。
>> 强大的搜索和聊天功能:能够对记录的全部数字生活进行毫秒级的搜索,并支持与搜索结果进行聊天互动。 提供一个playground,允许用户使用演示视频中的样本数据进行搜索和聊天。
>> 转录和总结:能够完美地记录和总结所有通话和会议内容,并且可以在离线状态下工作。
自动化功能:可以将会议内容转化为行动项,并自动更新Notion、Slack和CRM等应用。
>> 数据私有性:100% 保护用户数据隐私,所有数据在本地处理,并采用军用级安全措施。
>> 可扩展性:通过名为“pipes”的插件系统,用户可以添加自定义AI插件,扩展Screenpipe的功能,实现个性化需求。
>> 多平台支持:支持跨平台使用。
2、核心原理:OCR+RAG
Screenpipe 的核心原理是基于用户设备本地运行的程序,实时捕获音频、屏幕和UI交互等数据。这些数据被存储在本地,并通过内置的AI模型进行处理,实现转录、总结、搜索和自动化等功能。 其插件系统(pipes)允许用户扩展其功能,通过自定义代码来处理捕获的数据,从而实现更个性化的应用。 Screenpipe 的一个关键优势在于其数据私密性,所有处理都在本地完成,避免了数据上传到云端带来的隐私风险。
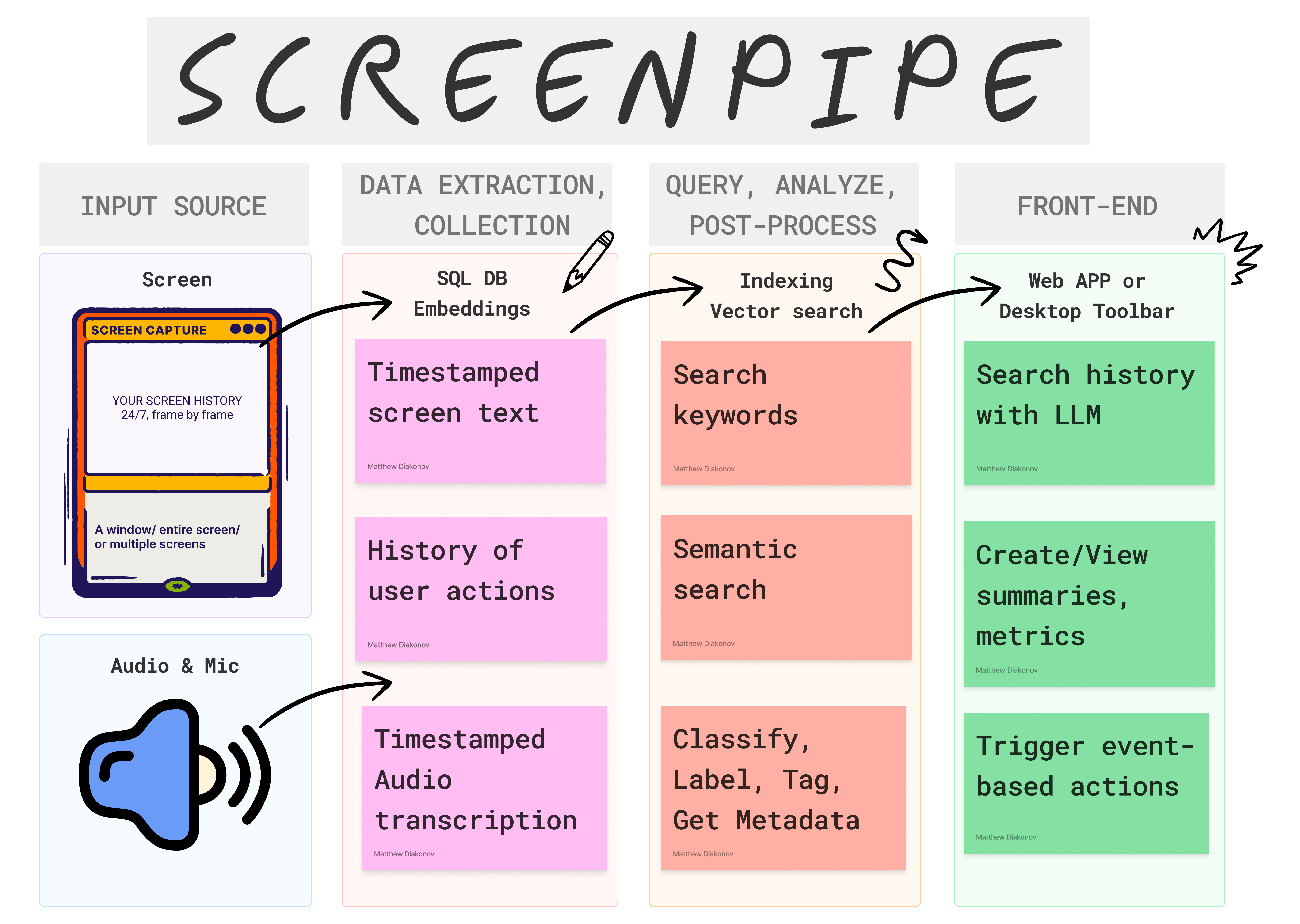
这张图描述了Screenpipe 系统的架构和工作流程,它可以被分解成四个主要阶段:
1. 输入源 (INPUT SOURCE):
- 屏幕 (Screen): Screenpipe 能够捕获整个屏幕、单个窗口或多个屏幕的活动,以帧为单位记录屏幕历史。
- 音频和麦克风 (Audio & Mic): 系统同时记录音频信息,用于后续的转录和分析。
2. 数据提取和收集 (DATA EXTRACTION, COLLECTION):
- SQL 数据库和嵌入 (SQL DB Embeddings): 捕获的屏幕和音频数据会被存储到 SQL 数据库中,并生成相应的嵌入向量 (Embeddings),用于后续的向量搜索。
- 带时间戳的屏幕文本 (Timestamped screen text): 从屏幕截图中提取文本信息,并记录其出现的时间戳。
- 用户行为历史 (History of user actions): 记录用户与屏幕交互的所有操作,例如鼠标点击、键盘输入等,并记录时间戳。
- 带时间戳的音频转录 (Timestamped Audio transcription): 对录制的音频进行转录,并记录时间戳。
3. 查询、分析和后处理 (QUERY, ANALYZE, POST-PROCESS):
- 索引和向量搜索 (Indexing Vector search): 利用嵌入向量进行高效的向量搜索,快速检索相关信息。
- 关键词搜索 (Search keywords): 支持基于关键词的文本搜索。
- 语义搜索 (Semantic search): 能够理解查询的语义,返回更准确的结果,不仅仅局限于关键词匹配。
- 分类、标记、标签和元数据获取 (Classify, Label, Tag, Get Metadata): 对数据进行分类、标记和添加元数据,方便后续的分析和使用。
4. 前端 (FRONT-END):
- Web 应用或桌面工具栏 (Web APP or Desktop Toolbar): 用户可以通过 Web 应用或桌面工具栏与系统进行交互,进行搜索、查看总结和指标等操作。
- 使用 LLM 搜索历史 (Search history with LLM): 利用大型语言模型 (LLM) 对历史记录进行更智能的搜索。
- 创建/查看摘要和指标 (Create/View summaries, metrics): 系统能够生成摘要和各种指标,方便用户理解和分析数据。
- 触发基于事件的动作 (Trigger event-based actions): 可以根据特定事件触发预定义的动作,实现自动化操作。
总而言之,Screenpipe 通过整合屏幕录制、音频录制、数据库管理、向量搜索和大型语言模型等技术,构建了一个强大的数据记录、分析和检索系统,能够帮助用户记录、理解和利用其数字生活中的信息。 其核心在于将不同类型的数据整合起来,并通过多种搜索方式进行检索,最终以易于理解的方式呈现给用户。
3、更新
- [2024/10] screenpipe 获得 Founders, Inc 的支持
- [2024/10] screenpipe 现在可以在中国使用,无需 VPN,并支持中文 OCR
- [2024/09] screenpipe 是 GitHub 趋势榜第一的项目,并在 Hacker News 上流行!
- [2024/09] 150 名用户全天候使用 screenpipe!
- [2024/09] 发布了我们的文档
- [2024/08] 现在任何人都可以从应用界面创建、分享、安装 pipes(插件),基于 GitHub 仓库/目录
- [2024/08] 我们正在进行悬赏活动!为 screenpipe 贡献并赚钱,查看问题
- [2024/08] 我们发布了适用于 Apple 和 Windows 的原生 OCR
- [2024/07] 🎁 screenpipe 在 AGI House 的 Friends(AI 项链)黑客马拉松中获胜(即将整合)
- [2024/07] 我们刚刚发布了桌面应用!立即下载!
Screenpipe 安装和使用方法
Screenpipe 提供多种安装方式,以满足不同用户的需求:
T1、命令行界面 (CLI)
适用于技术用户,提供直接的命令行操作方式。
T2、付费桌面应用
提供一年更新、优先支持和优先功能。可以通过提交 PR(示例已提供)或在线分享 Screenpipe 来获得一年的桌面应用许可证。
T3、免费桌面应用 (自建)
Screenpipe 完全开源,用户可以自行构建免费的桌面应用,但需要自行编译。
T4、Rust 或 WASM 库
可作为 Rust 或 WASM 库使用,通过 websocket 流式传输帧和 OCR 数据到用户的应用程序。
Screenpipe 案例应用
提供的文本中没有具体列举 Screenpipe 的案例应用,但可以从其功能推断出一些潜在的应用场景:
AI 训练数据收集:Screenpipe 可以收集大量的屏幕和语音数据,用于训练各种 AI 模型,例如对话模型、图像识别模型等。
软件开发辅助:通过记录屏幕操作和语音指令,Screenpipe 可以帮助开发者记录开发过程,辅助调试和代码审查。
用户行为分析:Screenpipe 收集的数据可以用于分析用户行为,改进软件设计和用户体验。
远程协助和培训:Screenpipe 可以记录远程协助或培训过程,方便后续回顾和改进。



















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











