







MLMs之Kimi:《Kimi k1.5: Scaling Reinforcement Learning with LLMs》翻译与解读
导读:论文介绍了Kimi K1.5,一个利用RL训练的多模态大型语言模型 (MLLM)。论文的核心在于探索通过强化学习来扩展大型语言模型能力的新途径,并取得了显著成果。总而言之,这篇论文通过Kimi K1.5模型及其训练方法,证明了利用强化学习来扩展大型语言模型能力的可行性和有效性,为未来人工智能的发展提供了新的思路和方向。 论文中提出的长上下文缩放、改进的策略优化算法以及高效的训练基础设施都是重要的贡献。
>> 背景痛点:传统的语言模型预训练主要依赖于下一个token预测,其效果受限于可获得的训练数据量。虽然扩大模型参数和数据规模能提升性能(符合缩放法则),但高质量训练数据的获取存在瓶颈,限制了模型能力的进一步提升。因此,论文指出,扩展RL为持续改进人工智能提供了一个新的方向,即让大型语言模型通过奖励学习来探索,从而突破静态数据集的限制。然而,之前的研究并未取得具有竞争力的结果。
>> 具体的解决方案:论文提出的解决方案是Kimi K1.5模型,其训练过程包含以下几个关键步骤:
● 高质量RL提示集的构建:这部分强调了提示集的多样性、难度平衡和可评估性。为了保证提示集的质量,论文采用了多种方法,包括自动过滤、难度评估(基于SFT模型的通过率)、以及防止奖励作弊(排除容易作弊的题型,例如选择题)。
● 长上下文 (long-CoT) 有监督微调:在强化学习之前,先用精心设计的长上下文有监督微调数据集对模型进行预训练,这个数据集包含了准确验证的推理路径(文本和图像输入)。这帮助模型内化了规划、评估、反思和探索等关键认知过程。
● 强化学习训练:论文的核心在于其强化学习策略。它采用了一种在线镜像下降算法的变体,并结合了部分 rollout、长度惩罚和采样策略优化等技术来提高训练效率。 值得注意的是,该方法避免了使用蒙特卡洛树搜索、价值函数和过程奖励模型等更复杂的技术。
● 长到短 (long2short) 方法:论文提出了一种将长上下文 (long-CoT) 模型的推理能力迁移到短上下文 (short-CoT) 模型的方法,包括模型合并、最短拒绝采样、DPO和长到短RL等。
● 多模态训练:Kimi K1.5模型在文本和视觉数据上联合训练,具备跨模态推理能力。
● 高效的训练基础设施:论文详细介绍了其大规模强化学习训练系统,包括 rollout workers、master、reward models、replay buffer 和 trainer workers 等组件,以及部分 rollout 技术来提高长上下文RL训练的效率。 还介绍了代码沙盒用于安全执行用户提交的代码,并优化了代码执行和基准评估。
>> 核心思路步骤:
● 数据准备:收集并清洗高质量的多模态数据(文本、图像、视频),构建多样化、难度平衡的RL提示集。
● 模型预训练:使用大规模多模态数据进行预训练,建立强大的语言和视觉基础模型。
● 长上下文有监督微调:使用长上下文推理路径数据进行微调,提升模型的推理能力。
● 强化学习训练:使用改进的在线镜像下降算法和部分 rollout 等技术进行强化学习训练,优化模型的推理策略。
● 长到短迁移:将长上下文模型的知识迁移到短上下文模型,提高短上下文模型的效率和性能。
>> 优势:
● 在多个基准测试和模态上取得了最先进的推理性能:在AIME、MATH 500、Codeforces和MathVista等基准测试中取得了与OpenAI的o1模型相当,甚至更好的结果。
● 在短上下文推理方面也取得了最先进的结果:显著优于GPT-4o和Claude Sonnet 3.5等现有模型。
● 提出了一种简单有效的强化学习框架:避免了使用更复杂的技术,提高了训练效率。
● 有效地扩展了上下文长度:将RL的上下文窗口扩展到128k,并观察到性能随着上下文长度的增加而持续提高。
● 提出了有效的长到短方法:将长上下文的推理能力迁移到短上下文模型,提高了token效率。
● 设计了高效的训练基础设施:包括部分 rollout 和混合部署策略,提高了训练效率和可扩展性。
>> 结论和观点:
● 上下文长度的扩展对于改进LLM至关重要。
● 通过长上下文缩放和改进的策略优化,即使不依赖于更复杂的技术,也能实现强大的性能。
● 部分 rollout 技术有效地解决了长上下文RL训练中的挑战。
● 长到短方法可以显著提高短上下文模型的性能和token效率。
● 高质量的数据和有效的训练策略是提升LLM推理能力的关键。
目录
《Kimi k1.5: Scaling Reinforcement Learning with LLMs》翻译与解读
《Kimi k1.5: Scaling Reinforcement Learning with LLMs》翻译与解读
| 地址 | 论文地址:[2501.12599v1] Kimi k1.5: Scaling Reinforcement Learning with LLMs |
| 时间 | 2025年1月22日 |
| 作者 | Kimi团队 |
Abstract
| Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data. Scaling reinforcement learning (RL) unlocks a new axis for the continued improvement of artificial intelligence, with the promise that large language models (LLMs) can scale their training data by learning to explore with rewards. However, prior published work has not produced competitive results. In light of this, we report on the training practice of Kimi k1.5, our latest multi-modal LLM trained with RL, including its RL training techniques, multi-modal data recipes, and infrastructure optimization. Long context scaling and improved policy optimization methods are key ingredients of our approach, which establishes a simplistic, effective RL framework without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models. Notably, our system achieves state-of-the-art reasoning performance across multiple benchmarks and modalities -- e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista -- matching OpenAI's o1. Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models, yielding state-of-the-art short-CoT reasoning results -- e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench -- outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%). | 使用下一个标记预测进行语言模型预训练已被证明在扩大计算规模方面是有效的,但受可用训练数据量的限制。扩大强化学习(RL)为人工智能的持续改进开辟了新的途径,其承诺在于大型语言模型(LLM)可以通过学习利用奖励进行探索来扩大其训练数据。然而,此前已发表的工作尚未取得有竞争力的结果。鉴于此,我们报告了我们最新多模态 LLM——Kimi k1.5 的训练实践,包括其 RL 训练技术、多模态数据配方和基础设施优化。长上下文扩展和改进的策略优化方法是我们方法的关键要素,它建立了一个简单有效的 RL 框架,无需依赖蒙特卡罗树搜索、价值函数和过程奖励模型等更复杂的技巧。值得注意的是,我们的系统在多个基准和模态上实现了最先进的推理性能——例如,在 AIME 上达到 77.5,在 MATH 500 上达到 96.2,在 Codeforces 上达到第 94 百分位,在 MathVista 上达到 74.9——与 OpenAI 的 o1 相当。此外,我们提出了有效的长链思维(CoT)到短链思维(CoT)的方法,利用长链思维技术来改进短链思维模型,从而在短链思维推理方面取得了最先进的成果——例如,在 AIME 上达到 60.8,在 MATH500 上达到 94.6,在 LiveCodeBench 上达到 47.3,大幅超越了现有的短链思维模型,如 GPT-4o 和 Claude Sonnet 3.5(最高提升幅度达 550%)。 |
Figure 1: Kimi k1.5 long-CoT results.
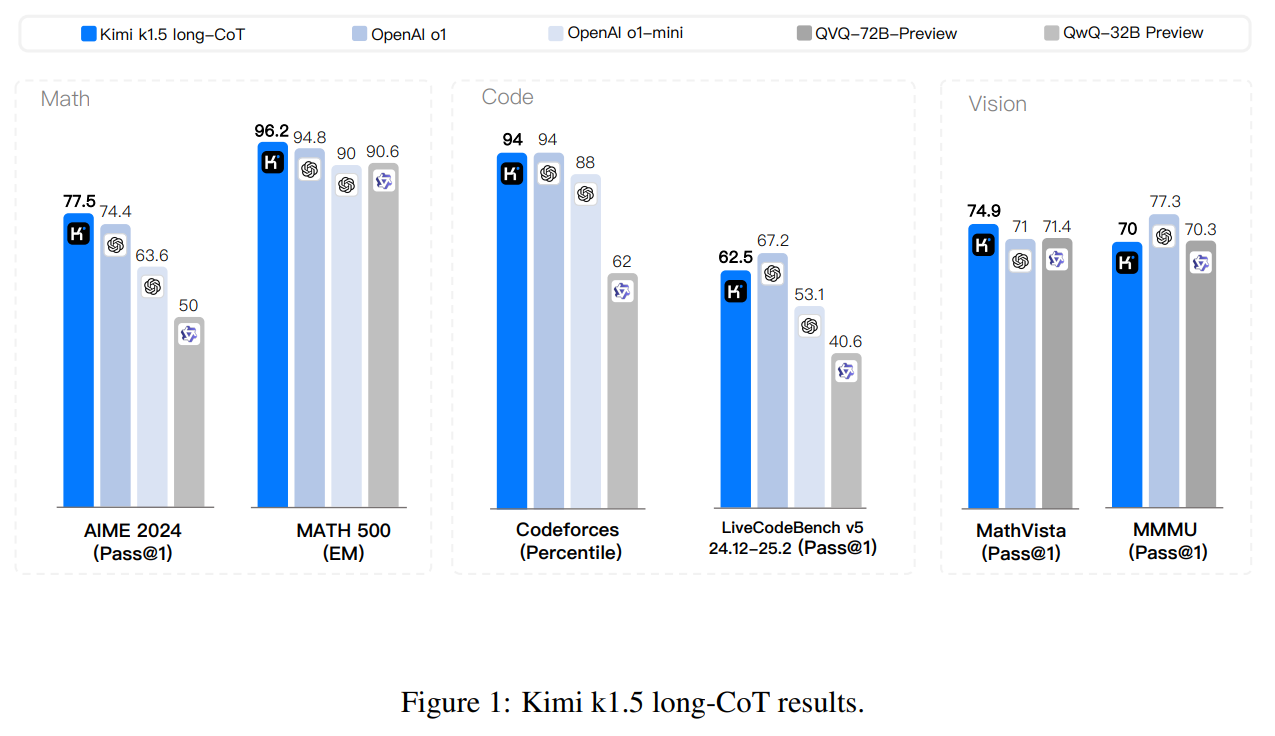
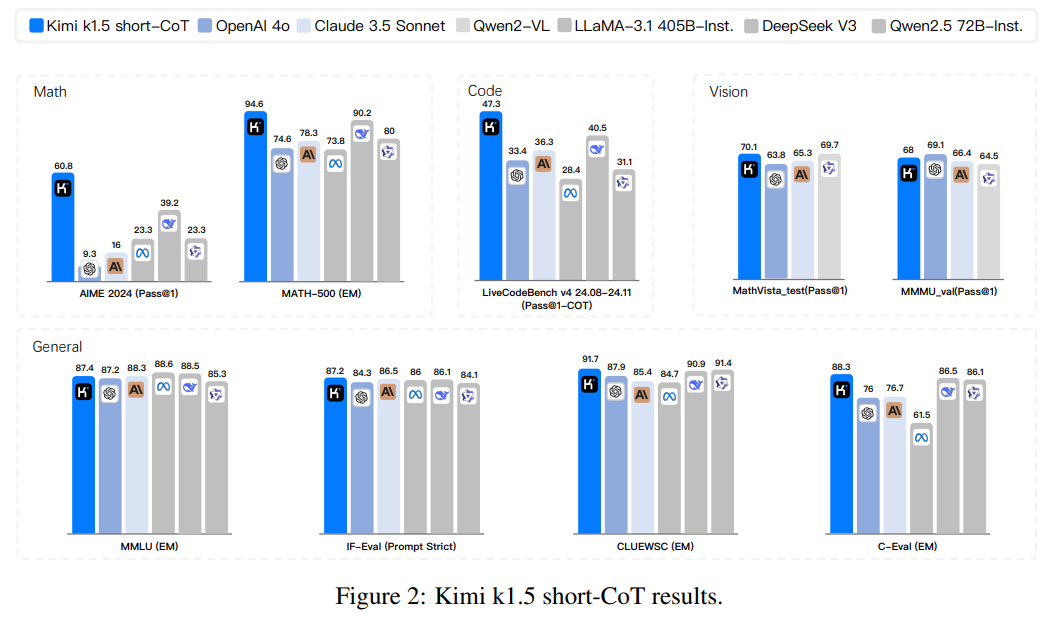
Figure 2: Kimi k1.5 short-CoT results.
1、Introduction
| Language model pretraining with next token prediction has been studied under the context of the scaling law, where proportionally scaling model parameters and data sizes leads to the continued improvement of intelligence. (Kaplan et al. 2020; Hoffmann et al. 2022) However, this approach is limited to the amount of available high-quality training data. (Villalobos et al. 2024; Muennighoff et al. 2023).In this report, we present the training recipe of Kimi k1.5, our latest multi-modal LLM trained with reinforcement learning (RL). The goal is to explore a possible new axis for continued scaling. Using RL with LLMs, the models learns to explore with rewards and thus is not limited to a pre-existing static dataset. | 在缩放定律的背景下,对语言模型进行下个标记预测的预训练已得到研究,其中按比例缩放模型参数和数据规模会导致智能的持续提升。(Kaplan 等人,2020 年;Hoffmann 等人,2022 年)然而,这种方法受限于可用的高质量训练数据量。(Villalobos 等人,2024 年;Muennighoff 等人,2023 年)。在本报告中,我们介绍了 Kimi k1.5 的训练配方,这是我们的最新多模态大语言模型,通过强化学习(RL)进行训练。其目标是探索可能的新轴以实现持续缩放。通过将 RL 应用于 LLM,模型能够通过奖励进行探索,从而不受预先存在的静态数据集的限制。 |
| There are a few key ingredients about the design and training of k1.5. • Long context scaling. We scale the context window of RL to 128k and observe continued improvement of performance with an increased context length. A key idea behind our approach is to use partial rollouts to improve training efficiency—i.e., sampling new trajectories by reusing a large chunk of previous trajectories, avoiding the cost to re-generate the new trajectories from scratch. Our observation identifies the context length as a key dimension of the continued scaling of RL with LLMs. • Improved policy optimization. We derive a formulation of RL with long-CoT and employ a variant of online mirror descent for robust policy optimization. This algorithm is further improved by our effective sampling strategy, length penalty, and optimization of the data recipe. • Simplistic Framework. Long context scaling, combined with the improved policy optimization methods, establishes a simplistic RL framework for learning with LLMs. Since we are able to scale the context length, the learned CoTs exhibit the properties of planning, reflection, and correction. An increased context length has an effect of increasing the number of search steps. As a result, we show that strong performance can be achieved without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models. • Multimodalities. Our model is jointly trained on text and vision data, which has the capabilities of jointly reasoning over the two modalities. Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models. Specifically, our approaches include applying length penalty with long-CoT activations and model merging. | 关于 k1.5 的设计和训练,有几个关键要素。 • 长上下文缩放。我们将 RL 的上下文窗口扩展到 128k,并观察到随着上下文长度的增加,性能持续提升。我们方法背后的一个关键理念是使用部分回放来提高训练效率,即通过复用先前轨迹中的大段内容来采样新的轨迹,避免了从头生成新轨迹的成本。我们的观察表明,上下文长度是强化学习与大语言模型持续扩展的关键维度。 • 改进的策略优化。我们推导出长 CoT 强化学习的公式,并采用在线镜像下降的一种变体来进行稳健的策略优化。我们的有效采样策略、长度惩罚以及数据配方的优化进一步改进了该算法。 • 简单框架。长上下文扩展与改进的策略优化方法相结合,为使用大语言模型的学习建立了一个简单的强化学习框架。由于我们能够扩展上下文长度,所学的 CoT 展现出规划、反思和修正的特性。上下文长度的增加相当于增加了搜索步骤的数量。因此,我们表明无需依赖蒙特卡罗树搜索、价值函数和过程奖励模型等更复杂的技巧,也能取得出色的表现。 • 多模态。我们的模型是在文本和视觉数据上联合训练的,具备对这两种模态进行联合推理的能力。此外,我们还提出了有效的长到短方法,利用长链式思维(CoT)技术来改进短链式思维模型。具体而言,我们的方法包括应用长链式思维激活的长度惩罚以及模型合并。 |
| Our long-CoT version achieves state-of-the-art reasoning performance across multiple benchmarks and modalities—e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista—matching OpenAI’s o1. Our model also achieves state-of-the-art short-CoT reasoning results—e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench—outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%). Results are shown in Figures 1 and 2. | 我们的长链式思维版本在多个基准和模态上实现了最先进的推理性能,例如在 AIME 上达到 77.5,在 MATH 500 上达到 96.2,在 Codeforces 上达到第 94 百分位,在 MathVista 上达到 74.9,与 OpenAI 的 o1 相当。我们的模型还在短链式思维推理方面取得了最先进的结果,例如在 AIME 上达到 60.8,在 MATH500 上达到 94.6,在 LiveCodeBench 上达到 47.3,大幅超越了现有的短链式思维模型,如 GPT-4o 和 Claude Sonnet 3.5(最高提升达 550%)。结果如图 1 和图 2 所示。 |
Conclusion
| We present the training recipe and system design of k1.5, our latest multi-modal LLM trained with RL. One of the key insights we extract from our practice is that the scaling of context length is crucial to the continued improvement of LLMs. We employ optimized learning algorithms and infrastructure optimization such as partial rollouts to achieve efficient long-context RL training. How to further improve the efficiency and scalability of long-context RL training remains an important question moving forward. Another contribution we made is a combination of techniques that enable improved policy optimization. Specifically, we formulate long-CoT RL with LLMs and derive a variant of online mirror descent for robust optimization. We also experiment with sampling strategies, length penalty, and optimizing the data recipe to achieve strong RL performance. | 我们介绍了 k1.5 的训练配方和系统设计,这是我们的最新多模态 LLM,通过强化学习进行训练。从实践中我们得出的一个关键见解是,上下文长度的扩展对于 LLM 的持续改进至关重要。我们采用优化的学习算法和基础设施优化(如部分回放)来实现高效的长上下文强化学习训练。如何进一步提高长上下文强化学习训练的效率和可扩展性,仍是未来的一个重要问题。 我们做出的另一项贡献是结合多种技术以实现更优的策略优化。具体而言,我们用 LLM 构建了长链式思维强化学习,并推导出一种在线镜像下降的变体以实现稳健优化。我们还试验了采样策略、长度惩罚以及优化数据配方,以实现强大的强化学习性能。 |
| We show that strong performance can be achieved by long context scaling and improved policy optimization, even without using more complex techniques such as Monte Carlo tree search, value functions, and process reward models. In the future, it will also be intriguing to study improving credit assignments and reducing overthinking without hurting the model’s exploration abilities. We have also observed the potential of long2short methods. These methods largely improve performance of short CoT models. Moreover, it is possible to combine long2short methods with long-CoT RL in an iterative way to further increase token efficiency and extract the best performance out of a given context length budget. | 我们表明,通过长上下文扩展和改进策略优化,即使不使用蒙特卡罗树搜索、价值函数和过程奖励模型等更复杂的技术,也能取得出色的表现。未来,研究如何改进信用分配以及减少过度思考而不损害模型的探索能力也将十分有趣。 我们还观察到了长到短方法的潜力。这些方法极大地提高了短 CoT 模型的性能。此外,有可能以迭代的方式将长到短方法与长 CoT 强化学习相结合,以进一步提高标记效率,并在给定的上下文长度预算内提取最佳性能。 |



















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











