







前言
本文介绍BEVPoolv2,从工程优化的角度出发,改善BEV模型的视图转换。
通过省略视锥特征的计算、存储和预处理来实现,使其在计算和存储方面不再受到巨大的负担。
输入使用640 ×1600的分辨率,它可以在 0.82 毫秒内处理,这是先前最快实现的 15.1 倍。
一、分析BEVPool问题
Lift-Splat-Shoot(LSS)视图转换,可以将常规2D图像转为BEV图,其中会用到BEVPool。
BEVPool的思路流程如下图所示:
1、输入:图像特征、对应的深度得分。
2、生成视锥特征:每个像素有深度信息后,可以结合相机内外参投影到三维空间中。
3、预处理和累计求和:三维体素索引和视锥特征需要进行预处理,然后对同一个方柱区域内,可能存在多个点进行累计求和,压缩形成BEV特征。
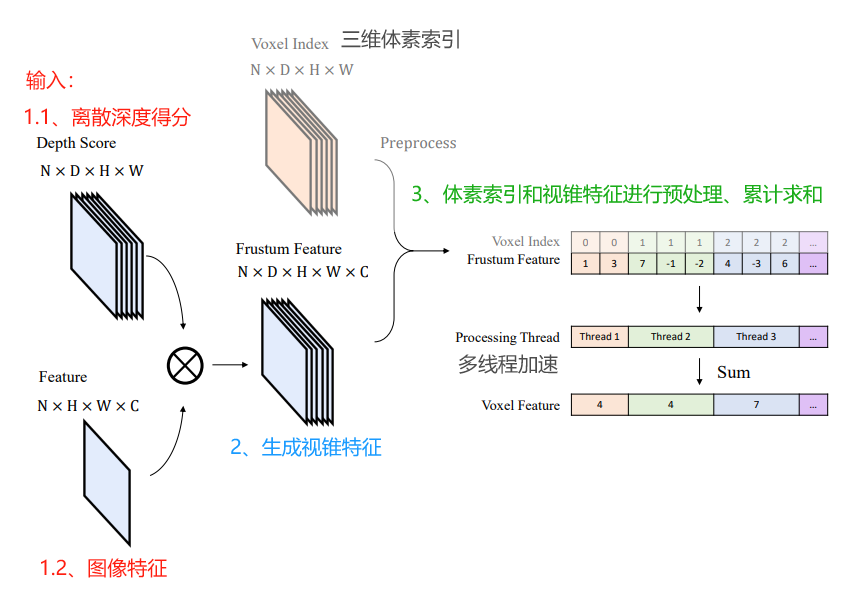
如上图所示,N是视图数,D是深度类别数,H是特征图的高度,W是特征图的宽度、C是特征通道数。
- 离散深度分数尺寸为(N,D,H,W),图像特征尺寸为(N,H,W,C),通过两者生成视锥体特征。
- LSS视图转换的主要缺点之一是它必须计算、存储和预处理具有大尺寸(N,D,H,W,C)的视锥体特征。
- 然后,视锥体特与体素索引一起进行预处理,该索引指示视锥体点所属的体素,并根据相机的内部和外部计算得出。
- 预处理包括过滤超出所有体素范围的视锥体点,并根据它们的体素索引对视锥体点进行排序。
- 最后,相同体素内的视锥体点通过累积求和进行聚合。
一些优化方案:
- Lift-Splat-Shoot 视角转换的BEVPool,在部署时最大的问题是推理速度慢和显存占用多。
- 与累积求和不同,BEVFusion中的BEVPool使用多个处理线程加速此过程。然而,它仍然需要计算、存储和预处理视锥体特征,这既消耗内存又消耗计算资源。
- BEVDepth和BEVStereo使用VoxelPool时也存在类似的情况。当增加输入分辨率时,它们的效率明显降低,内存需求急剧增加。
- 例如,在深度维度为118且输入分辨率为640×1760的情况下,以前最快的实现仅能以81 FPS进行处理,并占用高达2964 MB的缓存内存。这在边缘设备上显然是不可行的。
- 于是提出了BEVPoolv2。
二、BEVPoolv2原理
BEVPoolv2通过体素索引和视锥体索引可以在离线进行预计算和预处理,然后推理时根据这个视锥特征的索引去获取计算该视锥特征的图像特征和深度得分。
如下图所示,它的思路流程:
- 离线进行预计算和预处理:体素索引和视锥体索引
- 输入深度分数、图像特征
- 通过视锥体索引,找到对应深度分数和特征
- 相同体素内的视锥体点通过累积求和进行聚合
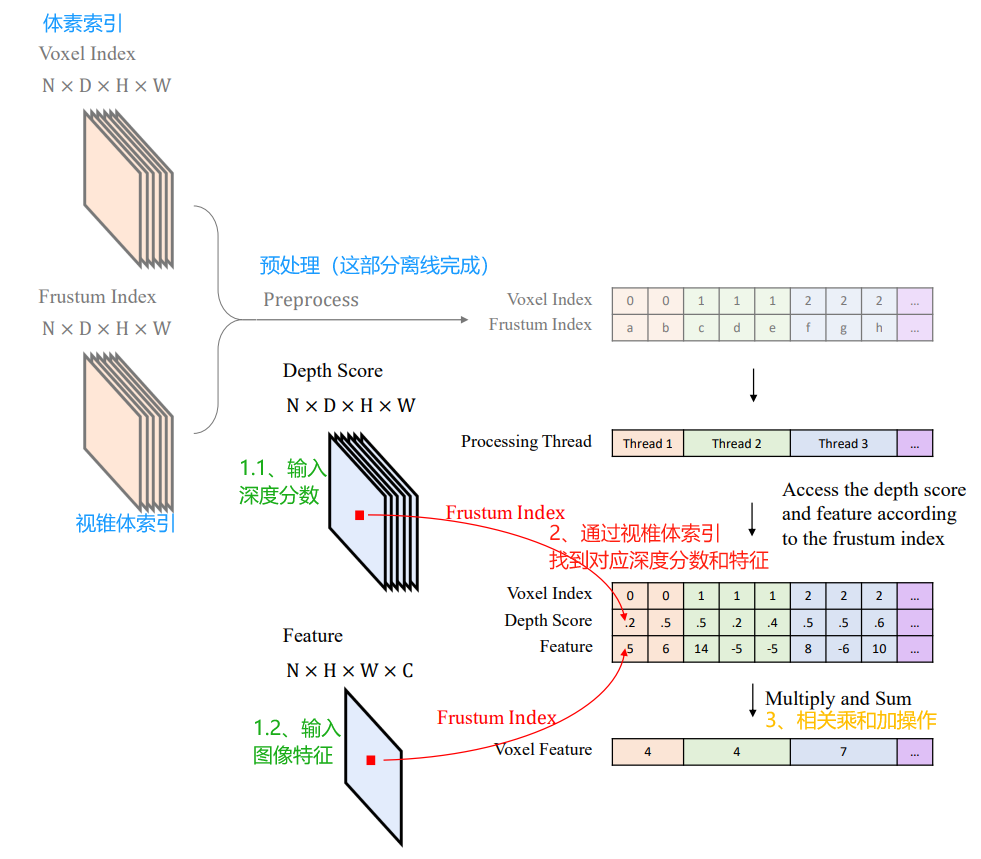
- 体素索引和视锥体索引计算这部分,在推理过程中,它们只是充当固定参数。
- 通过这种方式,避免了显式计算、存储和预处理视锥体特征。因此,可以节省内存和计算,并进一步加速推理。
- 通过预计算加速,BEVPoolv2在低分辨率256×704的情况下推理速度高达4,863 PFS,仍然在高分辨率640×1760的情况下保持1,509 FPS。
- 在低分辨率256×704下,它比先前最快的实现快3.1倍,在高分辨率640×1760下快8.2倍。
- BEVPoolv2如此之快,使得视图变换不再成为整个管道的瓶颈。最后但同样重要的是,通过避免存储视锥体特征而节省的内存也是令人满意的。
- 这使得Lift-Splat-Shoot视图变换器可以在边缘设备上部署。
详细实验测试参考原论文:BEVPoolv2: A Cutting-edge Implementation of BEVDet Toward Deployment
三、BEVPoolv2 CUDA代码实现
BEVPoolv2助力于LSS方案能在边缘设备上部署,推BEV方案部署落地。
这里写了一个pyhon的函数来调用bev_pool_v2,这里只给了前向推理的代码,反向传播的没给出。
def bev_pool_v2(depth, feat, ranks_depth, ranks_feat, ranks_bev,
bev_feat_shape, interval_starts, interval_lengths):
"""
Args:
depth: (B, N, D, fH, fW)
feat: (B, N, fH, fW, C)
ranks_depth: (N_points, ),
ranks_feat: (N_points, ),
ranks_bev: (N_points, ),
bev_feat_shape: (B, D_Z, D_Y, D_X, C)
interval_starts: (N_pillar, )
interval_lengths: (N_pillar, )
Returns:
x: bev feature in shape (B, C, Dz, Dy, Dx)
"""
x = QuickCumsumCuda.apply(depth, feat, ranks_depth, ranks_feat, ranks_bev,
bev_feat_shape, interval_starts,
interval_lengths) # (B, Dz, Dy, Dx, C)
x = x.permute(0, 4, 1, 2, 3).contiguous() # (B, C, Dz, Dy, Dx)
return x
class QuickCumsumCuda(torch.autograd.Function):
r"""BEVPoolv2 implementation for Lift-Splat-Shoot view transformation.
Please refer to the `paper <https://arxiv.org/abs/2211.17111>`_
"""
@staticmethod
def forward(ctx, depth, feat, ranks_depth, ranks_feat, ranks_bev,
bev_feat_shape, interval_starts, interval_lengths):
ranks_bev = ranks_bev.int() # (N_points, ),
depth = depth.contiguous().float() # (B, N, D, fH, fW)
feat = feat.contiguous().float() # (B, N, fH, fW, C)
ranks_depth = ranks_depth.contiguous().int() # (N_points, ),
ranks_feat = ranks_feat.contiguous().int() # (N_points, ),
interval_lengths = interval_lengths.contiguous().int() # (N_pillar, )
interval_starts = interval_starts.contiguous().int() # (N_pillar, )
out = feat.new_zeros(bev_feat_shape) # (B, D_Z, D_Y, D_X, C)
bev_pool_v2_ext.bev_pool_v2_forward(
depth,
feat,
out,
ranks_depth,
ranks_feat,
ranks_bev,
interval_lengths,
interval_starts,
)
ctx.save_for_backward(ranks_bev, depth, feat, ranks_feat, ranks_depth)
return out
对应的测试函数:
def test_bev_pool_v2():
depth = np.array([0.3, 0.4, 0.2, 0.1, 0.7, 0.6, 0.8, 0.9])
depth = torch.from_numpy(depth).float().cuda()
depth = depth.view(1, 1, 2, 2, 2).requires_grad_()
feat = torch.ones(
size=[1, 1, 2, 2, 2], dtype=torch.float,
device='cuda').requires_grad_()
ranks_depth = torch.from_numpy(np.array([0, 4, 1, 6])).int().cuda()
ranks_feat = torch.from_numpy(np.array([0, 0, 1, 2])).int().cuda()
ranks_bev = torch.from_numpy(np.array([0, 0, 1, 1])).int().cuda()
kept = torch.ones(
ranks_bev.shape[0], device=ranks_bev.device, dtype=torch.bool)
kept[1:] = ranks_bev[1:] != ranks_bev[:-1]
interval_starts = torch.where(kept)[0].int()
if len(interval_starts) == 0:
return None, None, None, None, None
interval_lengths = torch.zeros_like(interval_starts)
interval_lengths[:-1] = interval_starts[1:] - interval_starts[:-1]
interval_lengths[-1] = ranks_bev.shape[0] - interval_starts[-1]
bev_feat = bev_pool_v2(depth, feat, ranks_depth, ranks_feat, ranks_bev,
(1, 1, 2, 2, 2), interval_starts, interval_lengths)
loss = torch.sum(bev_feat)
loss.backward()
assert loss == 4.4
grad_depth = np.array([2., 2., 0., 0., 2., 0., 2., 0.])
grad_depth = torch.from_numpy(grad_depth).float()
grad_depth = grad_depth.cuda().view(1, 1, 2, 2, 2)
assert depth.grad.allclose(grad_depth)
grad_feat = np.array([1.0, 1.0, 0.4, 0.4, 0.8, 0.8, 0., 0.])
grad_feat = torch.from_numpy(grad_feat).float().cuda().view(1, 1, 2, 2, 2)
assert feat.grad.allclose(grad_feat)
bev_pool_v2()函数主要是调用了QuickCumsumCuda()类,使用其前向推理的方法。
QuickCumsumCuda()类的前向推理中,主要调用了bev_pool_v2_ext.bev_pool_v2_forward()。
其中,bev_pool_v2_ext是用cpp实现的,名称为括bev_pool.cpp,调用封装成库的bev_pool_cuda.cu。
bev_pool.cpp代码如下所示:
// Copyright (c) Phigent Robotics. All rights reserved.
// Reference https://arxiv.org/abs/2211.17111
#include <torch/torch.h>
#include <c10/cuda/CUDAGuard.h>
// CUDA function declarations
void bev_pool_v2(int c, int n_intervals, const float* depth, const float* feat,
const int* ranks_depth, const int* ranks_feat, const int* ranks_bev,
const int* interval_starts, const int* interval_lengths, float* out);
/*
Function: pillar pooling (forward, cuda)
Args:
depth : input depth, FloatTensor[n, d, h, w]
feat : input features, FloatTensor[n, h, w, c]
out : output features, FloatTensor[b, c, h_out, w_out]
ranks_depth : depth index of points, IntTensor[n_points]
ranks_feat : feat index of points, IntTensor[n_points]
ranks_bev : output index of points, IntTensor[n_points]
interval_lengths : starting position for pooled point, IntTensor[n_intervals]
interval_starts : how many points in each pooled point, IntTensor[n_intervals]
Return:
*/
void bev_pool_v2_forward(
const at::Tensor _depth, // (B, N, D, fH, fW)
const at::Tensor _feat, // (B, N, fH, fW, C)
at::Tensor _out, // (B, D_Z, D_Y, D_X, C)
const at::Tensor _ranks_depth, // (N_points, ),
const at::Tensor _ranks_feat, // (N_points, ),
const at::Tensor _ranks_bev, // (N_points, ),
const at::Tensor _interval_lengths, // (N_pillar, )
const at::Tensor _interval_starts // (N_pillar, )
) {
int c = _feat.size(4);
int n_intervals = _interval_lengths.size(0);
const at::cuda::OptionalCUDAGuard device_guard(device_of(_depth));
const float* depth = _depth.data_ptr<float>();
const float* feat = _feat.data_ptr<float>();
const int* ranks_depth = _ranks_depth.data_ptr<int>();
const int* ranks_feat = _ranks_feat.data_ptr<int>();
const int* ranks_bev = _ranks_bev.data_ptr<int>();
const int* interval_lengths = _interval_lengths.data_ptr<int>();
const int* interval_starts = _interval_starts.data_ptr<int>();
float* out = _out.data_ptr<float>();
bev_pool_v2(
c, n_intervals, depth, feat, ranks_depth, ranks_feat,
ranks_bev, interval_starts, interval_lengths, out
);
}
bev_pool_cuda.cu代码如下所示:
// Copyright (c) Phigent Robotics. All rights reserved.
// Reference https://arxiv.org/abs/2211.17111
#include <stdio.h>
#include <stdlib.h>
// CUDA内核函数,用于处理3D点云数据的特征聚合
__global__ void bev_pool_v2_kernel(int c, int n_intervals,
const float *__restrict__ depth,
const float *__restrict__ feat,
const int *__restrict__ ranks_depth,
const int *__restrict__ ranks_feat,
const int *__restrict__ ranks_bev,
const int *__restrict__ interval_starts,
const int *__restrict__ interval_lengths,
float* __restrict__ out) {
// 计算当前线程的全局索引,确定处理的数据位置
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 计算当前pillar的索引
int index = idx / c;
// 计算当前处理的特征通道的索引
int cur_c = idx % c;
// 如果当前pillar索引超出范围,则线程直接返回
if (index >= n_intervals) return;
// 获取当前pillar的起始点索引
int interval_start = interval_starts[index];
// 获取当前pillar包含的点的数量
int interval_length = interval_lengths[index];
// 初始化累加器,用于累计特征值
float psum = 0;
// 指向当前深度值和特征值的指针
const float* cur_depth;
const float* cur_feat;
// 遍历当前pillar的所有点
for(int i = 0; i < interval_length; i++) {
// 获取当前点的深度值
cur_depth = depth + ranks_depth[interval_start + i];
// 获取当前通道对应的特征值
cur_feat = feat + ranks_feat[interval_start + i] * c + cur_c;
// 累加当前点的特征值与深度值的乘积
psum += *cur_feat * *cur_depth;
}
// 获取当前pillar在BEV(鸟瞰图)网格中的索引
const int* cur_rank = ranks_bev + interval_start;
// 定位输出数组中的相应位置
float* cur_out = out + *cur_rank * c + cur_c;
// 将累加的特征值写入输出数组
*cur_out = psum;
}
// 定义 bev_pool_v2 函数,用于并行处理3D点云数据
void bev_pool_v2(int c, int n_intervals, const float* depth, const float* feat,
const int* ranks_depth, const int* ranks_feat, const int* ranks_bev,
const int* interval_starts, const int* interval_lengths, float* out) {
// 调用CUDA内核函数bev_pool_v2_kernel
// 使用n_intervals * c计算所需的线程总数,然后除以256确定需要多少个线程块
// 每个线程块使用256个线程
bev_pool_v2_kernel<<<(int)ceil(((double)n_intervals * c / 256)), 256>>>(
c, n_intervals, depth, feat, ranks_depth, ranks_feat,
ranks_bev, interval_starts, interval_lengths, out
);
}
其实这里只是给了CUDA的示例,对于NVIDIA的芯片没什么问题,能部署。
但是对于其他芯片,比如国产的黑芝麻、地平线等,需要转为普通C代码;
然后利用芯片多线程接口,实现并行BEV池化即可。
本文先介绍到这里,后面会分享其它“BEV工程优化”的方法、原理、代码。



















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











