






F C O S FCOS FCOS
预测中心度越接近1,就是预测框的中心越接近目标框的中心
1.视频教程:
B站、网易云课堂、腾讯课堂
2.代码地址:
Gitee
Github
3.存储地址:
Google云
百度云:
提取码:
《FCOS: Fully Convolutional One-Stage Object Detection》
—一种全卷积单阶段目标检测方法
作者:Zhi Tian 、 Chunhua Shen etc
单位:The University of Adelaide, Australia
发表会议及时间:ICCV 2019
Submission history
From: Chunhua Shen [view email]
[v1] Tue, 2 Apr 2019 11:56:36 UTC (4,255 KB)
[v2] Fri, 5 Apr 2019 04:13:34 UTC (4,248 KB)
[v3] Sun, 14 Apr 2019 01:42:12 UTC (4,255 KB)
[v4] Fri, 2 Aug 2019 00:45:02 UTC (4,258 KB)
[v5] Tue, 20 Aug 2019 11:26:21 UTC (4,267 KB)
- Abstract
一 论文导读
Paper:https://arxiv.org/abs/1904.01355
官方代码: this https URL
We propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to semantic segmentation.
Almost all state-of-the-art object detectors such as RetinaNet, SSD, YOLOv3, and Faster R-CNN rely on pre-defined anchor boxes. In contrast, our proposed detector FCOS is anchor box free, as well as proposal free.
By eliminating the predefined set of anchor boxes, FCOS completely avoids the complicated computation related to anchor boxes such as calculating overlapping during training.
More importantly, we also avoid all hyper-parameters related to anchor boxes, which are often very sensitive to the final detection performance.
With the only post-processing non-maximum suppression (NMS), FCOS with ResNeXt-64x4d-101 achieves 44.7% in AP with single-model and single-scale testing, surpassing previous one-stage detectors with the advantage of being much simpler.
For the first time, we demonstrate a much simpler and flexible detection framework achieving improved detection accuracy.
We hope that the proposed FCOS framework can serve as a simple and strong alternative for many other instance-level tasks. Code is available at:Code is available at: this https URL
创新点(优点):逐像素计算,和中心度的预测,来进行检测(同时Anchor Free)
单阶段,像素级预测的思想解决目标检测问题
anchor free的,加速处理速度,降低内存
实例性质检测任务
一定程度上均衡了正负样本(就是提升了正样本的数量),可以利用更多的前景样本来训练,bbox的位置回归更准确
可以检测重叠(不同类别物体之间)、遮挡(不同类别物体之间),极小和极大的物体。
Anchor base的缺点
1.检测性能对于anchor的大小,数量,长宽比都非常敏感,通过改变这些超参数Retinanet在Coco benchmark上面提升了4%的AP。
2.固定的anchor降低了检测器的普适性,导致对于不同任务,其anchor需要重新设置大小和长宽比。
3.为了去匹配真实框,需要生成大量的anchor,但是大部分的anchor在训练时标记为negative,所以就造成了样本间的不平衡(没有充分利用fore-ground)
4.在训练时,需要计算所有anchor与真实框的IOU,会消耗大量内存和时间
二 论文精读
Center-ness:中心度
两个分支
一个分支:预测类别和中心度
另一个分支:预测上下左右的离中心的距离
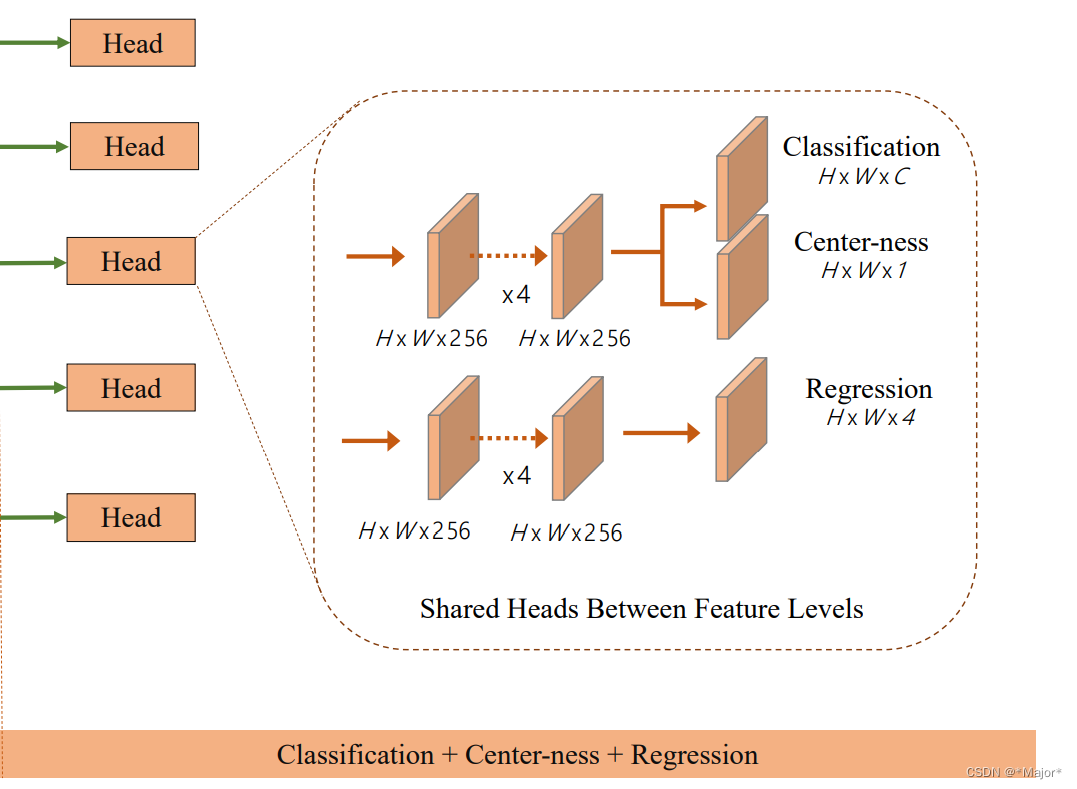
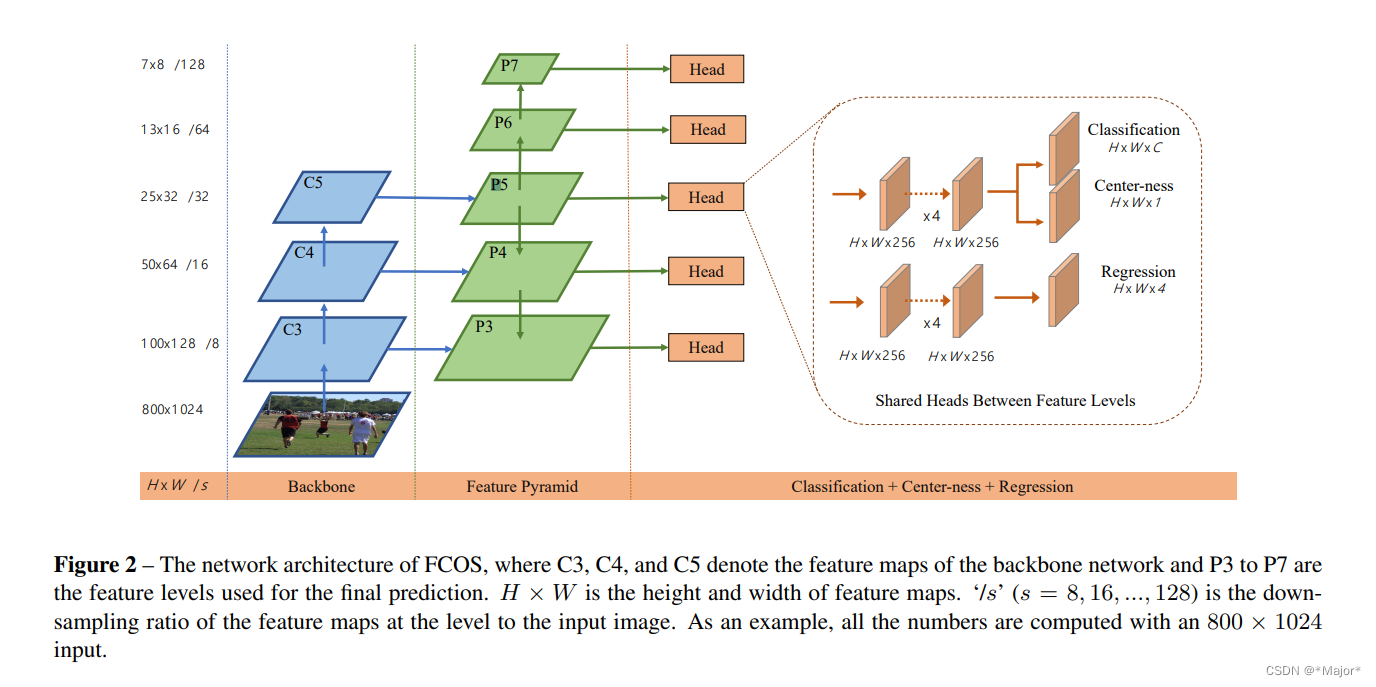
backbone使用FPN
C5之上并没有继续下采样,再下采样意义已经不大,信息会过分丢失
P5之后继续特征下采样,是为看增加尺度的多样性
三 代码实现
import torch.nn as nn
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import math
import torch.nn.functional as F
'''
参数配置
'''
class DefaultConfig():
# backbone
backbone = "darknet19"
# backbone="resnet50"
pretrained = False # 不加载预训练模型
freeze_stage_1 = True
freeze_bn = True
# fpn
fpn_out_channels = 256
use_p5 = True
# head
class_num = 80
use_GN_head = True
prior = 0.01
add_centerness = True
cnt_on_reg = False
# training
strides = [8, 16, 32, 64, 128]
limit_range = [[-1, 64], [64, 128], [128, 256], [256, 512], [512, 999999]]
# inference
score_threshold = 0.3
nms_iou_threshold = 0.2
max_detection_boxes_num = 150
'''
损失设计
'''
def coords_fmap2orig(feature, stride):
'''
transfor one fmap coords to orig coords
Args
featurn [batch_size,h,w,c]
stride int
Returns
coords [n,2]
'''
h, w = feature.shape[1:3] # 得到该层输出结果的h和w
shifts_x = torch.arange(0, w * stride, stride, dtype=torch.float32) # 得到该层点对应左上角的x和y的坐标
shifts_y = torch.arange(0, h * stride, stride, dtype=torch.float32)
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
shift_x = torch.reshape(shift_x, [-1])
shift_y = torch.reshape(shift_y, [-1]) # 通过meshgrid的方式把所有框左上角的坐标找出来
coords = torch.stack([shift_x, shift_y], -1) + stride // 2 # 最后都位移到框的中心去
return coords
class GenTargets(nn.Module):
def __init__(self, strides, limit_range):
super().__init__()
self.strides = strides # 在config file中定义了每一个特征层对应的stride为多少
self.limit_range = limit_range # 在config file中定义了每一个特征层对应的框的范围为多少
assert len(strides) == len(limit_range)
def forward(self, inputs):
"""
inputs
[0]list [cls_logits,cnt_logits,reg_preds]
cls_logits list contains five [batch_size,class_num,h,w]
cnt_logits list contains five [batch_size,1,h,w]
reg_preds list contains five [batch_size,4,h,w]
[1]gt_boxes [batch_size,m,4] FloatTensor
[2]classes [batch_size,m] LongTensor
Returns
cls_targets:[batch_size,sum(_h*_w),1]
cnt_targets:[batch_size,sum(_h*_w),1]
reg_targets:[batch_size,sum(_h*_w),4]
"""
cls_logits, cnt_logits, reg_preds = inputs[0] # input[0]为FCOS网络的预测结果,现在分解为这三项
gt_boxes = inputs[1] # 第二项代表实际的gt boxes
classes = inputs[2] # 第三项代表实际的gt boxes的类别
cls_targets_all_level = []
cnt_targets_all_level = []
reg_targets_all_level = []
assert len(self.strides) == len(cls_logits)
for level in range(len(cls_logits)): # 界限来分层来进行目标的一个转换
level_out = [cls_logits[level], cnt_logits[level], reg_preds[level]] # 将一层的目标打包成一个list
level_targets = self._gen_level_targets(level_out, gt_boxes, classes, self.strides[level],
self.limit_range[level]) # 根据输入的gt boxes找出每一个坐标点对应的回归目标为多少
cls_targets_all_level.append(level_targets[0]) # 将这几个目标存起来
cnt_targets_all_level.append(level_targets[1])
reg_targets_all_level.append(level_targets[2])
return torch.cat(cls_targets_all_level, dim=1), torch.cat(cnt_targets_all_level, dim=1), torch.cat(
reg_targets_all_level, dim=1) # 将不同层的目标合并起来
def _gen_level_targets(self, out, gt_boxes, classes, stride, limit_range, sample_radiu_ratio=1.5):
'''
Args
out list contains [[batch_size,class_num,h,w],[batch_size,1,h,w],[batch_size,4,h,w]]
gt_boxes [batch_size,m,4]
classes [batch_size,m]
stride int
limit_range list [min,max]
Returns
cls_targets,cnt_targets,reg_targets
'''
cls_logits, cnt_logits, reg_preds = out # 将该层中FCOS的预测结果分解成三项
batch_size = cls_logits.shape[0]
class_num = cls_logits.shape[1]
m = gt_boxes.shape[1] # 得到此时gt boxes的数量
cls_logits = cls_logits.permute(0, 2, 3, 1) # [batch_size,h,w,class_num]
coords = coords_fmap2orig(cls_logits, stride).to(device=gt_boxes.device) # [h*w,2] 找到特征图上的点对应实际图片中的位置
cls_logits = cls_logits.reshape((batch_size, -1, class_num)) # [batch_size,h*w,class_num]
cnt_logits = cnt_logits.permute(0, 2, 3, 1) # 全部把代表预测结果的维度移动到最后一维,并平h和w的维度
cnt_logits = cnt_logits.reshape((batch_size, -1, 1))
reg_preds = reg_preds.permute(0, 2, 3, 1)
reg_preds = reg_preds.reshape((batch_size, -1, 4))
h_mul_w = cls_logits.shape[1]
x = coords[:, 0]
y = coords[:, 1]
l_off = x[None, :, None] - gt_boxes[..., 0][:, None, :] # [1,h*w,1]-[batch_size,1,m]-->[batch_size,h*w,m] # 计算中心点和gt box四条边的距离
t_off = y[None, :, None] - gt_boxes[..., 1][:, None, :]
r_off = gt_boxes[..., 2][:, None, :] - x[None, :, None]
b_off = gt_boxes[..., 3][:, None, :] - y[None, :, None]
ltrb_off = torch.stack([l_off, t_off, r_off, b_off], dim=-1) # [batch_size,h*w,m,4] 把这四个距离记录下来,顺序为left,top,right,bottom
areas = (ltrb_off[..., 0] + ltrb_off[..., 2]) * (ltrb_off[..., 1] + ltrb_off[..., 3]) # [batch_size,h*w,m]
off_min = torch.min(ltrb_off, dim=-1)[0] # [batch_size,h*w,m] 找到每一个坐标对应的框的最大值和最小值
off_max = torch.max(ltrb_off, dim=-1)[0] # [batch_size,h*w,m]
mask_in_gtboxes = off_min > 0 # 统计那些坐标在gt boxes内的
mask_in_level = (off_max > limit_range[0]) & (off_max <= limit_range[1]) # 通过limit_range来计算那些属于该level的坐标点
radiu = stride * sample_radiu_ratio # 控制对应的坐标点应在gt boxes中心的附近
gt_center_x = (gt_boxes[..., 0] + gt_boxes[..., 2]) / 2 # 找到gt boxes的中心
gt_center_y = (gt_boxes[..., 1] + gt_boxes[..., 3]) / 2
c_l_off = x[None, :, None] - gt_center_x[:, None, :] # [1,h*w,1]-[batch_size,1,m]-->[batch_size,h*w,m]
c_t_off = y[None, :, None] - gt_center_y[:, None, :]
c_r_off = gt_center_x[:, None, :] - x[None, :, None] # 计算gt boxes的中心与中心点在原图位置之间的距离
c_b_off = gt_center_y[:, None, :] - y[None, :, None]
c_ltrb_off = torch.stack([c_l_off, c_t_off, c_r_off, c_b_off], dim=-1) # [batch_size,h*w,m,4]
c_off_max = torch.max(c_ltrb_off, dim=-1)[0] # 计算上下左右最选的距离为多少
mask_center = c_off_max < radiu # 只选择小于1.5倍stride的点
mask_pos = mask_in_gtboxes & mask_in_level & mask_center # [batch_size,h*w,m] # 最后将上述三个标准合并下,就得到了每一个gt boxes可能对应的点是哪些
areas[~mask_pos] = 99999999 # 非目标点的面积被设定为无穷大
areas_min_ind = torch.min(areas, dim=-1)[1] # [batch_size,h*w] 找到每一个gt boxes对应的中心点预测结果面积与那个gt boxes更接近
reg_targets = ltrb_off[torch.zeros_like(areas, dtype=torch.uint8).scatter_(-1, areas_min_ind.unsqueeze(dim=-1),
1)] # [batch_size*h*w,4]
reg_targets = torch.reshape(reg_targets, (batch_size, -1, 4)) # [batch_size,h*w,4] # 输出每一个坐标点最后应该实现的目标为多少
classes = torch.broadcast_tensors(classes[:, None, :], areas.long())[0] # [batch_size,h*w,m]
cls_targets = classes[
torch.zeros_like(areas, dtype=torch.uint8).scatter_(-1, areas_min_ind.unsqueeze(dim=-1), 1)]
cls_targets = torch.reshape(cls_targets, (batch_size, -1, 1)) # [batch_size,h*w,1] 同理找到对应的应有的target为多少
left_right_min = torch.min(reg_targets[..., 0], reg_targets[..., 2]) # [batch_size,h*w]
left_right_max = torch.max(reg_targets[..., 0], reg_targets[..., 2])
top_bottom_min = torch.min(reg_targets[..., 1], reg_targets[..., 3])
top_bottom_max = torch.max(reg_targets[..., 1], reg_targets[..., 3])
cnt_targets = ((left_right_min * top_bottom_min) / (left_right_max * top_bottom_max + 1e-10)).sqrt().unsqueeze(
dim=-1) # [batch_size,h*w,1] # 根据公式计算此时的centerness目标
assert reg_targets.shape == (batch_size, h_mul_w, 4)
assert cls_targets.shape == (batch_size, h_mul_w, 1)
assert cnt_targets.shape == (batch_size, h_mul_w, 1)
# process neg coords
mask_pos_2 = mask_pos.long().sum(dim=-1) # [batch_size,h*w]
# num_pos=mask_pos_2.sum(dim=-1)
# assert num_pos.shape==(batch_size,)
mask_pos_2 = mask_pos_2 >= 1 # 找到那些不属于任何一个gt boxes的坐标
assert mask_pos_2.shape == (batch_size, h_mul_w)
cls_targets[~mask_pos_2] = 0 # [batch_size,h*w,1] 将他们的类别分为0
cnt_targets[~mask_pos_2] = -1 # cnt和reg都为-1,不用计算
reg_targets[~mask_pos_2] = -1
return cls_targets, cnt_targets, reg_targets
def compute_cls_loss(preds, targets, mask):
'''
Args
preds: list contains five level pred [batch_size,class_num,_h,_w]
targets: [batch_size,sum(_h*_w),1]
mask: [batch_size,sum(_h*_w)]
'''
batch_size = targets.shape[0]
preds_reshape = []
class_num = preds[0].shape[1]
mask = mask.unsqueeze(dim=-1)
# mask=targets>-1#[batch_size,sum(_h*_w),1]
num_pos = torch.sum(mask, dim=[1, 2]).clamp_(min=1).float() # [batch_size,]
for pred in preds:
pred = pred.permute(0, 2, 3, 1)
pred = torch.reshape(pred, [batch_size, -1, class_num])
preds_reshape.append(pred)
preds = torch.cat(preds_reshape, dim=1) # [batch_size,sum(_h*_w),class_num] 将pred按照target的构成方式调整为一样的大小
assert preds.shape[:2] == targets.shape[:2]
loss = []
for batch_index in range(batch_size): # 分不同的图片分别计算loss
pred_pos = preds[batch_index] # [sum(_h*_w),class_num]
target_pos = targets[batch_index] # [sum(_h*_w),1]
target_pos = (torch.arange(1, class_num + 1, device=target_pos.device)[None,
:] == target_pos).float() # sparse-->onehot 将原有的目标转换为onehot的形式
loss.append(focal_loss_from_logits(pred_pos, target_pos).view(1)) # 在cls的loss计算中,用了focal loss
return torch.cat(loss, dim=0) / num_pos # [batch_size,]
def compute_cnt_loss(preds, targets, mask):
'''
Args
preds: list contains five level pred [batch_size,1,_h,_w]
targets: [batch_size,sum(_h*_w),1]
mask: [batch_size,sum(_h*_w)]
'''
batch_size = targets.shape[0]
c = targets.shape[-1]
preds_reshape = []
mask = mask.unsqueeze(dim=-1)
# mask=targets>-1#[batch_size,sum(_h*_w),1]
num_pos = torch.sum(mask, dim=[1, 2]).clamp_(min=1).float() # [batch_size,]
for pred in preds:
pred = pred.permute(0, 2, 3, 1)
pred = torch.reshape(pred, [batch_size, -1, c])
preds_reshape.append(pred)
preds = torch.cat(preds_reshape, dim=1)
assert preds.shape == targets.shape # [batch_size,sum(_h*_w),1]
loss = []
for batch_index in range(batch_size):
pred_pos = preds[batch_index][mask[batch_index]] # [num_pos_b,]
target_pos = targets[batch_index][mask[batch_index]] # [num_pos_b,]
assert len(pred_pos.shape) == 1
loss.append(
nn.functional.binary_cross_entropy_with_logits(input=pred_pos, target=target_pos, reduction='sum').view(1)) # 在cnt的loss计算在仅用了交叉熵
return torch.cat(loss, dim=0) / num_pos # [batch_size,]
def compute_reg_loss(preds, targets, mask, mode='giou'):
'''
Args
preds: list contains five level pred [batch_size,4,_h,_w]
targets: [batch_size,sum(_h*_w),4]
mask: [batch_size,sum(_h*_w)]
'''
batch_size = targets.shape[0]
c = targets.shape[-1]
preds_reshape = []
# mask=targets>-1#[batch_size,sum(_h*_w),4]
num_pos = torch.sum(mask, dim=1).clamp_(min=1).float() # [batch_size,]
for pred in preds:
pred = pred.permute(0, 2, 3, 1)
pred = torch.reshape(pred, [batch_size, -1, c])
preds_reshape.append(pred)
preds = torch.cat(preds_reshape, dim=1)
assert preds.shape == targets.shape # [batch_size,sum(_h*_w),4]
loss = []
for batch_index in range(batch_size):
pred_pos = preds[batch_index][mask[batch_index]] # [num_pos_b,4]
target_pos = targets[batch_index][mask[batch_index]] # [num_pos_b,4]
assert len(pred_pos.shape) == 2
if mode == 'iou':
loss.append(iou_loss(pred_pos, target_pos).view(1)) # 在reg的loss计算中运用了两种不同的iou
elif mode == 'giou':
loss.append(giou_loss(pred_pos, target_pos).view(1))
else:
raise NotImplementedError("reg loss only implemented ['iou','giou']")
return torch.cat(loss, dim=0) / num_pos # [batch_size,]
def iou_loss(preds, targets):
'''
Args:
preds: [n,4] ltrb
targets: [n,4]
'''
lt = torch.min(preds[:, :2], targets[:, :2])
rb = torch.min(preds[:, 2:], targets[:, 2:])
wh = (rb + lt).clamp(min=0)
overlap = wh[:, 0] * wh[:, 1] # [n]
area1 = (preds[:, 2] + preds[:, 0]) * (preds[:, 3] + preds[:, 1])
area2 = (targets[:, 2] + targets[:, 0]) * (targets[:, 3] + targets[:, 1])
iou = overlap / (area1 + area2 - overlap)
loss = -iou.clamp(min=1e-6).log()
return loss.sum()
def giou_loss(preds, targets):
'''
Args:
preds: [n,4] ltrb
targets: [n,4]
'''
lt_min = torch.min(preds[:, :2], targets[:, :2])
rb_min = torch.min(preds[:, 2:], targets[:, 2:])
wh_min = (rb_min + lt_min).clamp(min=0)
overlap = wh_min[:, 0] * wh_min[:, 1] # [n]
area1 = (preds[:, 2] + preds[:, 0]) * (preds[:, 3] + preds[:, 1])
area2 = (targets[:, 2] + targets[:, 0]) * (targets[:, 3] + targets[:, 1])
union = (area1 + area2 - overlap)
iou = overlap / union
lt_max = torch.max(preds[:, :2], targets[:, :2])
rb_max = torch.max(preds[:, 2:], targets[:, 2:])
wh_max = (rb_max + lt_max).clamp(0)
G_area = wh_max[:, 0] * wh_max[:, 1] # [n]
giou = iou - (G_area - union) / G_area.clamp(1e-10)
loss = 1. - giou
return loss.sum()
def focal_loss_from_logits(preds, targets, gamma=2.0, alpha=0.25):
'''
Args:
preds: [n,class_num]
targets: [n,class_num]
'''
preds = preds.sigmoid()
pt = preds * targets + (1.0 - preds) * (1.0 - targets)
w = alpha * targets + (1.0 - alpha) * (1.0 - targets)
loss = -w * torch.pow((1.0 - pt), gamma) * pt.log()
return loss.sum()
class LOSS(nn.Module):
def __init__(self, config=None):
super().__init__()
if config is None:
self.config = DefaultConfig
else:
self.config = config
def forward(self, inputs):
"""
inputs list
[0]preds: ....
[1]targets : list contains three elements [[batch_size,sum(_h*_w),1],[batch_size,sum(_h*_w),1],[batch_size,sum(_h*_w),4]]
"""
preds, targets = inputs
cls_logits, cnt_logits, reg_preds = preds
cls_targets, cnt_targets, reg_targets = targets
mask_pos = (cnt_targets > -1).squeeze(dim=-1) # [batch_size,sum(_h*_w)]
cls_loss = compute_cls_loss(cls_logits, cls_targets, mask_pos).mean() # [] # 分别计算三种loss
cnt_loss = compute_cnt_loss(cnt_logits, cnt_targets, mask_pos).mean()
reg_loss = compute_reg_loss(reg_preds, reg_targets, mask_pos).mean()
if self.config.add_centerness: # 返回单个loss和相加后的loss
total_loss = cls_loss + cnt_loss + reg_loss
return cls_loss, cnt_loss, reg_loss, total_loss
else:
total_loss = cls_loss + reg_loss + cnt_loss * 0.0
return cls_loss, cnt_loss, reg_loss, total_loss
'''
BackBone
'''
cfg1 = [32, 'M', 64, 'M', 128, 64, 128, 'M', 256, 128, 256]
cfg2 = ['M', 512, 256, 512, 256, 512]
cfg3 = ['M', 1024, 512, 1024, 512, 1024]
def make_layers(cfg, in_channels=3, batch_norm=True, flag=True):
"""
从配置参数中构建网络
:param cfg: 参数配置
:param in_channels: 输入通道数,RGB彩图为3, 灰度图为1
:param batch_norm: 是否使用批正则化
:return:
"""
layers = []
# flag = True # 用于变换卷积核大小,(True选后面的,False选前面的)
in_channels = in_channels
for v in cfg:
if v == 'M':
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
else:
layers.append(nn.Conv2d(in_channels=in_channels,
out_channels=v,
kernel_size=(1, 3)[flag],
stride=1,
padding=(0, 1)[flag],
bias=False))
if batch_norm:
layers.append(nn.BatchNorm2d(v))
in_channels = v
layers.append(nn.LeakyReLU(negative_slope=0.1, inplace=True))
flag = not flag
return nn.Sequential(*layers)
class Darknet19(nn.Module):
"""
Darknet19 模型
"""
def __init__(self, in_channels=3, batch_norm=True, pretrained=False):
"""
模型结构初始化
:param in_channels: 输入数据的通道数 (input pic`s channel.)
:param batch_norm: 是否使用正则化 (use batch_norm, True or False;True by default.)
:param pretrained: 是否导入预训练参数 (use the pretrained weight)
"""
super(Darknet19, self).__init__()
# 调用make_layers 方法搭建网络
# (build the network)
self.block1 = make_layers(cfg1, in_channels=in_channels, batch_norm=batch_norm, flag=True)
self.block2 = make_layers(cfg2, in_channels=cfg1[-1], batch_norm=batch_norm, flag=False)
self.block3 = make_layers(cfg3, in_channels=cfg2[-1], batch_norm=batch_norm, flag=False)
# 导入预训练模型或初始化
if pretrained:
self.load_weight()
else:
self._initialize_weights()
def forward(self, x):
# 前向传播
feature1 = self.block1(x)
feature2 = self.block2(feature1)
feature3 = self.block3(feature2)
return [feature1, feature2, feature3]
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def load_weight(self):
weight_file = '../weight/darknet19-deepBakSu-e1b3ec1e.pth'
dic = {}
for now_keys, values in zip(self.state_dict().keys(), torch.load(weight_file).values()):
dic[now_keys] = values
self.load_state_dict(dic)
__all__ = ['resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# ResNet-B
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, if_include_top=False):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
if if_include_top:
self.fc = nn.Linear(512 * block.expansion, num_classes)
self.if_include_top = if_include_top
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
out3 = self.layer2(x)
out4 = self.layer3(out3)
out5 = self.layer4(out4)
return out3, out4, out5
# 使用demo.py时
# if self.if_include_top:
# x = self.avgpool(out5)
# x = x.view(x.size(0), -1)
# x = self.fc(x)
# return x
# else:
# return out3, out4, out5
def freeze_bn(self):
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()
def freeze_stages(self, stage):
if stage >= 0:
self.bn1.eval()
for m in [self.conv1, self.bn1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, stage + 1):
layer = getattr(self, 'layer{}'.format(i))
layer.eval()
for param in layer.parameters():
param.requires_grad = False
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
'''
FPN
'''
class FPN_(nn.Module):
"""only for resnet50,101,152"""
def __init__(self, features=256, use_p5=True):
super(FPN, self).__init__()
self.prj_5 = nn.Conv2d(2048, features, kernel_size=1)
self.prj_4 = nn.Conv2d(1024, features, kernel_size=1)
self.prj_3 = nn.Conv2d(512, features, kernel_size=1)
self.conv_5 = nn.Conv2d(features, features, kernel_size=3, padding=1)
self.conv_4 = nn.Conv2d(features, features, kernel_size=3, padding=1)
self.conv_3 = nn.Conv2d(features, features, kernel_size=3, padding=1)
if use_p5:
self.conv_out6 = nn.Conv2d(features, features, kernel_size=3, padding=1, stride=2)
else:
self.conv_out6 = nn.Conv2d(2048, features, kernel_size=3, padding=1, stride=2)
self.conv_out7 = nn.Conv2d(features, features, kernel_size=3, padding=1, stride=2)
self.use_p5 = use_p5
self.apply(self.init_conv_kaiming) # 对FPN结构使用凯明初始化
def upsamplelike(self, inputs):
src, target = inputs
return F.interpolate(src, size=(target.shape[2], target.shape[3]),
mode='nearest')
def init_conv_kaiming(self, module):
if isinstance(module, nn.Conv2d):
nn.init.kaiming_uniform_(module.weight, a=1)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def forward(self, x):
C3, C4, C5 = x
P5 = self.prj_5(C5)
P4 = self.prj_4(C4)
P3 = self.prj_3(C3)
P4 = P4 + self.upsamplelike([P5, C4])
P3 = P3 + self.upsamplelike([P4, C3])
P3 = self.conv_3(P3)
P4 = self.conv_4(P4)
P5 = self.conv_5(P5)
P5 = P5 if self.use_p5 else C5
P6 = self.conv_out6(P5)
P7 = self.conv_out7(F.relu(P6))
return [P3, P4, P5, P6, P7]
class FPN(nn.Module):
"""only for resnet50,101,152"""
def __init__(self, features=256, use_p5=True, backbone="resnet50"):
super(FPN, self).__init__()
if backbone == "resnet50":
print("resnet50 backbone")
self.prj_5 = nn.Conv2d(2048, features, kernel_size=1) # 不改变特征图的尺寸
self.prj_4 = nn.Conv2d(1024, features, kernel_size=1)
self.prj_3 = nn.Conv2d(512, features, kernel_size=1)
elif backbone == "darknet19":
print("darnet19 backbone")
self.prj_5 = nn.Conv2d(1024, features, kernel_size=1) # 不改变特征图的尺寸
self.prj_4 = nn.Conv2d(512, features, kernel_size=1)
self.prj_3 = nn.Conv2d(256, features, kernel_size=1)
else:
raise ValueError("arg 'backbone' only support 'resnet50' or 'darknet19'")
self.conv_5 = nn.Conv2d(features, features, kernel_size=3, padding=1) # 不改变特征图的尺寸
self.conv_4 = nn.Conv2d(features, features, kernel_size=3, padding=1)
self.conv_3 = nn.Conv2d(features, features, kernel_size=3, padding=1)
if use_p5:
self.conv_out6 = nn.Conv2d(features, features, kernel_size=3, padding=1, stride=2) # 将特征图尺寸缩小一半
else:
self.conv_out6 = nn.Conv2d(2048, features, kernel_size=3, padding=1, stride=2) # 将特征图尺寸缩小一半
self.conv_out7 = nn.Conv2d(features, features, kernel_size=3, padding=1, stride=2) # 将特征图尺寸缩小一半
self.use_p5 = use_p5
self.apply(self.init_conv_kaiming) # 对FPN结构使用凯明初始化
def upsamplelike(self, inputs): # 将src的尺寸大小,上采样到 target的尺寸
src, target = inputs
return F.interpolate(src, size=(target.shape[2], target.shape[3]),mode='nearest')
def init_conv_kaiming(self, module):
if isinstance(module, nn.Conv2d): # 判断变量module是不是nn.Conv2d类
nn.init.kaiming_uniform_(module.weight, a=1)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def forward(self, x):
C3, C4, C5 = x
# print(C3.shape, C4.shape, C5.shape)
P5 = self.prj_5(C5)
P4 = self.prj_4(C4)
P3 = self.prj_3(C3)
P4 = P4 + self.upsamplelike([P5, C4]) # 先将P5上采样到C4大小,再用元素相加的方式进行融合
P3 = P3 + self.upsamplelike([P4, C3]) # 先将P4上采样到C3大小,再用元素相加的方式进行融合
P3 = self.conv_3(P3) # 融合后再卷积的目的:用卷积操作平滑一下特征图的数值
P4 = self.conv_4(P4)
P5 = self.conv_5(P5)
P5 = P5 if self.use_p5 else C5
P6 = self.conv_out6(P5)
P7 = self.conv_out7(F.relu(P6))
return [P3, P4, P5, P6, P7] # 返回融合后的特征图
'''
HEAD
'''
class ScaleExp(nn.Module):
def __init__(self, init_value=1.0):
super(ScaleExp, self).__init__()
self.scale = nn.Parameter(torch.tensor([init_value], dtype=torch.float32))
def forward(self, x):
return torch.exp(x * self.scale)
class ClsCntRegHead(nn.Module):
def __init__(self, in_channel, class_num, GN=True, cnt_on_reg=True, prior=0.01):
"""
Args
in_channel
class_num
GN
prior
"""
super(ClsCntRegHead, self).__init__()
self.prior = prior
self.class_num = class_num
self.cnt_on_reg = cnt_on_reg
cls_branch = []
reg_branch = []
for i in range(4):
# conv--gn--relu
cls_branch.append(nn.Conv2d(in_channel, in_channel, kernel_size=3, padding=1, bias=True))
if GN:
cls_branch.append(nn.GroupNorm(32, in_channel))
cls_branch.append(nn.ReLU(True))
reg_branch.append(nn.Conv2d(in_channel, in_channel, kernel_size=3, padding=1, bias=True))
if GN:
reg_branch.append(nn.GroupNorm(32, in_channel))
reg_branch.append(nn.ReLU(True))
self.cls_conv = nn.Sequential(*cls_branch)
self.reg_conv = nn.Sequential(*reg_branch)
self.cls_logits = nn.Conv2d(in_channel, class_num, kernel_size=3, padding=1)
self.cnt_logits = nn.Conv2d(in_channel, 1, kernel_size=3, padding=1)
self.reg_pred = nn.Conv2d(in_channel, 4, kernel_size=3, padding=1)
self.apply(self.init_conv_RandomNormal)
nn.init.constant_(self.cls_logits.bias, -math.log((1 - prior) / prior))
self.scale_exp = nn.ModuleList([ScaleExp(1.0) for _ in range(5)])
def init_conv_RandomNormal(self, module, std=0.01):
if isinstance(module, nn.Conv2d):
nn.init.normal_(module.weight, std=std)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def forward(self, inputs):
"""inputs:[P3~P7]"""
cls_logits = []
cnt_logits = []
reg_preds = []
for index, P in enumerate(inputs):
cls_conv_out = self.cls_conv(P)
reg_conv_out = self.reg_conv(P)
cls_logits.append(self.cls_logits(cls_conv_out))
if not self.cnt_on_reg:
cnt_logits.append(self.cnt_logits(cls_conv_out))
else:
cnt_logits.append(self.cnt_logits(reg_conv_out))
reg_preds.append(self.scale_exp[index](self.reg_pred(reg_conv_out)))
return cls_logits, cnt_logits, reg_preds
'''
网络架构
'''
class FCOS(nn.Module):
def __init__(self, config=None):
super().__init__()
if config is None:
config = DefaultConfig
if config.backbone == "resnet50":
self.backbone = resnet50(pretrained=config.pretrained,
if_include_top=True)
elif config.backbone == "darknet19":
self.backbone = Darknet19()
self.fpn = FPN(config.fpn_out_channels,
use_p5=config.use_p5,
backbone=config.backbone)
self.head = ClsCntRegHead(config.fpn_out_channels,
config.class_num,
config.use_GN_head,
config.cnt_on_reg,
config.prior)
self.config = config
def train(self, mode=True):
"""
set module training mode, and frozen bn
"""
super().train(mode=True)
def freeze_bn(module):
if isinstance(module, nn.BatchNorm2d):
module.eval()
classname = module.__class__.__name__
if classname.find('BatchNorm') != -1:
for p in module.parameters(): p.requires_grad = False
if self.config.freeze_bn:
self.apply(freeze_bn)
print("INFO===>success frozen BN")
if self.config.freeze_stage_1:
self.backbone.freeze_stages(1)
print("INFO===>success frozen backbone stage1")
def forward(self, x):
"""
Returns
list [cls_logits,cnt_logits,reg_preds]
cls_logits list contains five [batch_size,class_num,h,w]
cnt_logits list contains five [batch_size,1,h,w]
reg_preds list contains five [batch_size,4,h,w]
"""
C3, C4, C5 = self.backbone(x)
all_P = self.fpn([C3, C4, C5])
cls_logits, cnt_logits, reg_preds = self.head(all_P)
return [cls_logits, cnt_logits, reg_preds]
class FCOS_(nn.Module):
def __init__(self, config=None):
super().__init__()
if config is None:
config = DefaultConfig
self.backbone = resnet50(pretrained=config.pretrained, if_include_top=True) # train
# self.backbone = resnet50(pretrained=config.pretrained, if_include_top=False)
self.fpn = FPN(config.fpn_out_channels, use_p5=config.use_p5)
self.head = ClsCntRegHead(config.fpn_out_channels, config.class_num,
config.use_GN_head, config.cnt_on_reg, config.prior)
self.config = config
def train(self, mode=True):
"""
set module training mode, and frozen bn
"""
super().train(mode=True)
def freeze_bn(module):
if isinstance(module, nn.BatchNorm2d):
module.eval()
classname = module.__class__.__name__
if classname.find('BatchNorm') != -1:
for p in module.parameters(): p.requires_grad = False
if self.config.freeze_bn:
self.apply(freeze_bn)
print("INFO===>success frozen BN")
if self.config.freeze_stage_1:
self.backbone.freeze_stages(1)
print("INFO===>success frozen backbone stage1")
def forward(self, x):
"""
Returns
list [cls_logits,cnt_logits,reg_preds]
cls_logits list contains five [batch_size,class_num,h,w]
cnt_logits list contains five [batch_size,1,h,w]
reg_preds list contains five [batch_size,4,h,w]
"""
C3, C4, C5 = self.backbone(x)
all_P = self.fpn([C3, C4, C5])
cls_logits, cnt_logits, reg_preds = self.head(all_P)
return [cls_logits, cnt_logits, reg_preds]
class DetectHead(nn.Module):
def __init__(self, score_threshold, nms_iou_threshold, max_detection_boxes_num, strides, config=None):
super().__init__()
self.score_threshold = score_threshold
self.nms_iou_threshold = nms_iou_threshold
self.max_detection_boxes_num = max_detection_boxes_num
self.strides = strides
if config is None:
self.config = DefaultConfig
else:
self.config = config
def forward(self, inputs):
"""
inputs list [cls_logits,cnt_logits,reg_preds]
cls_logits list contains five [batch_size,class_num,h,w]
cnt_logits list contains five [batch_size,1,h,w]
reg_preds list contains five [batch_size,4,h,w]
"""
cls_logits, coords = self._reshape_cat_out(inputs[0], self.strides) # [batch_size,sum(_h*_w),class_num]
cnt_logits, _ = self._reshape_cat_out(inputs[1], self.strides) # [batch_size,sum(_h*_w),1]
reg_preds, _ = self._reshape_cat_out(inputs[2], self.strides) # [batch_size,sum(_h*_w),4]
cls_preds = cls_logits.sigmoid_()
cnt_preds = cnt_logits.sigmoid_()
cls_scores, cls_classes = torch.max(cls_preds, dim=-1) # [batch_size,sum(_h*_w)]
if self.config.add_centerness:
cls_scores = cls_scores * (cnt_preds.squeeze(dim=-1)) # [batch_size,sum(_h*_w)]
cls_classes = cls_classes + 1 # [batch_size,sum(_h*_w)]
boxes = self._coords2boxes(coords, reg_preds) # [batch_size,sum(_h*_w),4]
# select topk
max_num = min(self.max_detection_boxes_num, cls_scores.shape[-1])
topk_ind = torch.topk(cls_scores, max_num, dim=-1, largest=True, sorted=True)[1] # [batch_size,max_num]
_cls_scores = []
_cls_classes = []
_boxes = []
for batch in range(cls_scores.shape[0]):
_cls_scores.append(cls_scores[batch][topk_ind[batch]]) # [max_num]
_cls_classes.append(cls_classes[batch][topk_ind[batch]]) # [max_num]
_boxes.append(boxes[batch][topk_ind[batch]]) # [max_num,4]
cls_scores_topk = torch.stack(_cls_scores, dim=0) # [batch_size,max_num]
cls_classes_topk = torch.stack(_cls_classes, dim=0) # [batch_size,max_num]
boxes_topk = torch.stack(_boxes, dim=0) # [batch_size,max_num,4]
assert boxes_topk.shape[-1] == 4
return self._post_process([cls_scores_topk, cls_classes_topk, boxes_topk])
def _post_process(self, preds_topk):
"""
cls_scores_topk [batch_size,max_num]
cls_classes_topk [batch_size,max_num]
boxes_topk [batch_size,max_num,4]
"""
_cls_scores_post = []
_cls_classes_post = []
_boxes_post = []
cls_scores_topk, cls_classes_topk, boxes_topk = preds_topk
for batch in range(cls_classes_topk.shape[0]):
mask = cls_scores_topk[batch] >= self.score_threshold
_cls_scores_b = cls_scores_topk[batch][mask] # [?]
_cls_classes_b = cls_classes_topk[batch][mask] # [?]
_boxes_b = boxes_topk[batch][mask] # [?,4]
nms_ind = self.batched_nms(_boxes_b, _cls_scores_b, _cls_classes_b, self.nms_iou_threshold)
_cls_scores_post.append(_cls_scores_b[nms_ind])
_cls_classes_post.append(_cls_classes_b[nms_ind])
_boxes_post.append(_boxes_b[nms_ind])
scores, classes, boxes = torch.stack(_cls_scores_post, dim=0), torch.stack(_cls_classes_post,
dim=0), torch.stack(_boxes_post,
dim=0)
return scores, classes, boxes
@staticmethod
def box_nms(boxes, scores, thr):
"""
boxes: [?,4]
scores: [?]
"""
if boxes.shape[0] == 0:
return torch.zeros(0, device=boxes.device).long()
assert boxes.shape[-1] == 4
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.sort(0, descending=True)[1]
keep = []
while order.numel() > 0:
if order.numel() == 1:
i = order.item()
keep.append(i)
break
else:
i = order[0].item()
keep.append(i)
xmin = x1[order[1:]].clamp(min=float(x1[i]))
ymin = y1[order[1:]].clamp(min=float(y1[i]))
xmax = x2[order[1:]].clamp(max=float(x2[i]))
ymax = y2[order[1:]].clamp(max=float(y2[i]))
inter = (xmax - xmin).clamp(min=0) * (ymax - ymin).clamp(min=0)
iou = inter / (areas[i] + areas[order[1:]] - inter)
idx = (iou <= thr).nonzero().squeeze()
if idx.numel() == 0:
break
order = order[idx + 1]
return torch.LongTensor(keep)
def batched_nms(self, boxes, scores, idxs, iou_threshold):
if boxes.numel() == 0:
return torch.empty((0,), dtype=torch.int64, device=boxes.device)
# strategy: in order to perform NMS independently per class.
# we add an offset to all the boxes. The offset is dependent
# only on the class idx, and is large enough so that boxes
# from different classes do not overlap
max_coordinate = boxes.max()
offsets = idxs.to(boxes) * (max_coordinate + 1)
boxes_for_nms = boxes + offsets[:, None]
keep = self.box_nms(boxes_for_nms, scores, iou_threshold)
return keep
def _coords2boxes(self, coords, offsets):
"""
Args
coords [sum(_h*_w),2]
offsets [batch_size,sum(_h*_w),4] ltrb
"""
x1y1 = coords[None, :, :] - offsets[..., :2]
x2y2 = coords[None, :, :] + offsets[..., 2:] # [batch_size,sum(_h*_w),2]
boxes = torch.cat([x1y1, x2y2], dim=-1) # [batch_size,sum(_h*_w),4]
return boxes
def _reshape_cat_out(self, inputs, strides):
"""
Args
inputs: list contains five [batch_size,c,_h,_w]
Returns
out [batch_size,sum(_h*_w),c]
coords [sum(_h*_w),2]
"""
batch_size = inputs[0].shape[0]
c = inputs[0].shape[1]
out = []
coords = []
for pred, stride in zip(inputs, strides):
pred = pred.permute(0, 2, 3, 1)
coord = coords_fmap2orig(pred, stride).to(device=pred.device)
pred = torch.reshape(pred, [batch_size, -1, c])
out.append(pred)
coords.append(coord)
return torch.cat(out, dim=1), torch.cat(coords, dim=0)
class ClipBoxes(nn.Module):
def __init__(self):
super().__init__()
def forward(self, batch_imgs, batch_boxes):
batch_boxes = batch_boxes.clamp_(min=0)
h, w = batch_imgs.shape[2:]
batch_boxes[..., [0, 2]] = batch_boxes[..., [0, 2]].clamp_(max=w - 1)
batch_boxes[..., [1, 3]] = batch_boxes[..., [1, 3]].clamp_(max=h - 1)
return batch_boxes
class FCOSDetector(nn.Module):
def __init__(self, mode="training", config=None):
super().__init__()
if config is None:
config = DefaultConfig
self.mode = mode
self.fcos_body = FCOS(config=config)
if mode == "training":
self.target_layer = GenTargets(strides=config.strides, limit_range=config.limit_range)
self.loss_layer = LOSS()
elif mode == "inference":
self.detection_head = DetectHead(config.score_threshold,
config.nms_iou_threshold,
config.max_detection_boxes_num,
config.strides, config)
self.clip_boxes = ClipBoxes()
def forward(self, inputs):
"""
inputs
[training] list batch_imgs,batch_boxes,batch_classes
[inference] img
"""
if self.mode == "training":
batch_imgs, batch_boxes, batch_classes = inputs # 代表这一个step中输入模型的数据
out = self.fcos_body(batch_imgs) # 通过图片计算出此时FCOS网络预测的cls,centerness和reg分别为多少
targets = self.target_layer([out, batch_boxes, batch_classes])
losses = self.loss_layer([out, targets])
return losses
elif self.mode == "inference":
# raise NotImplementedError("no implement inference model")
'''
for inference mode, img should preprocessed before feeding in net
'''
batch_imgs = inputs
out = self.fcos_body(batch_imgs)
scores, classes, boxes = self.detection_head(out)
boxes = self.clip_boxes(batch_imgs, boxes)
return scores, classes, boxes
if __name__ == "__main__":
model = FCOSDetector(mode="inference")
x = torch.randn(2, 3, 320, 480)
y = model(x)
for i in y:
print(i)
四 问题思索
五 实验参数设置
六 额外补充
FCOS如何解决重叠问题,就是一个像素既可以预测这个类别框,也可以预测另一个类别框,该问题如何解决?
FCOS解决奇异样本的方案就是利用FPN(特征金字塔网络)
原因是:奇异样本一般发生在目标框不同大小、不同类别上
操作:将不同大小的bounding box分配到对应大小的featuremap上
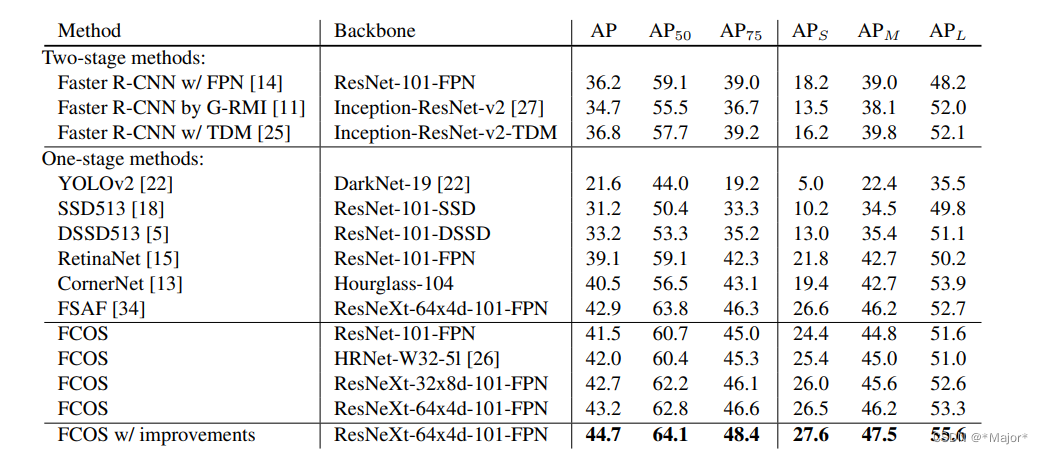
与其他一些网络比较:

















 3464
3464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









