









目录
1.主函数解析(car_dector.py)
测试一张图像,具体代码之前已经讲过了,这里都是重用,不再赘述。
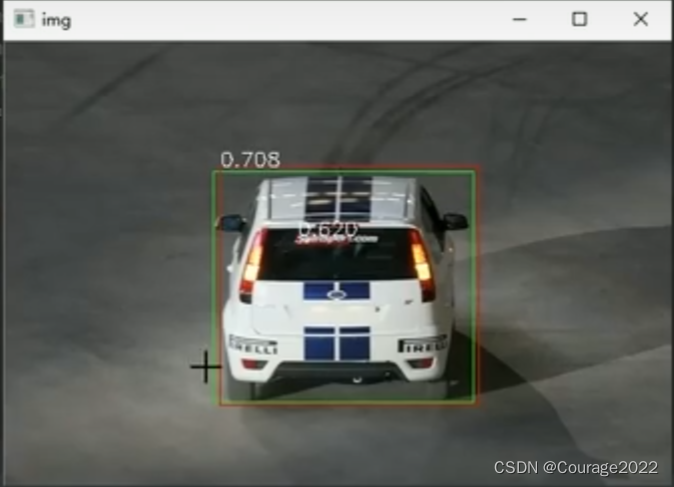
if __name__ == '__main__': device = get_device() transform = get_transform() model = get_model(device=device) #创建selectivesearch对象 gs = selectivesearch.get_selective_search() # test_img_path = '../imgs/000007.jpg' # test_xml_path = '../imgs/000007.xml' test_img_path = '../imgs/000012.jpg' test_xml_path = '../imgs/000012.xml' img = cv2.imread(test_img_path) dst = copy.deepcopy(img) bndboxs = util.parse_xml(test_xml_path) for bndbox in bndboxs: xmin, ynin,xmax, ymax = bndbox ##画一个框框 cv2.rectangle(dst,(xmin,ymin),(xmax,ymax),color=(0,255,0),thickness=1) ##候选区域建议 selectivesearch.config(gs,img,strategy='f') rects = selectivesearch.get_rects(gs) print('候选区域建议数目:%d' % len(rects)) ##svm阈值 svm_thresh = 0.60 ##保存正样本边界框 score_list = list() positive_list = list() start = time.time() ##对取出来的框体 for rect in rects: xmin,ymin,xmax,ymax = rect rect_img = img[ymin:ymax,xmin:xmax] #处理图像并放入GPU rect_transform = transform(rect_img).to(device) #走二分类模型 output = model(rect_transform.unsqueeze(0))[0] if torch.argmax(output).item() == 1: """ 预测为汽车 """ #softmax将概率归一化,输出的是(不是车概率,是车概率) probs = torch.softmax(output,dim=0).cpu().numpy() #tmp_score_list.append(pnobs[1]) #tmp_positive_list.append(rect) #probs[1]是是车的概率,如果大于svm阈值 #记录得分以及框体 if probs[1] >= svm_thresh: score_list.append(probs[1]) positive_list.append(rect) end = time.time() print('detect time: %d s'%(end - start)) nms_rects,nms_scores = nms(positive_list,score_list) print(nms_rects) print(nms_scores) draw_box_with_text(dst,nns_rects,nms_scores) cv2.imshow('img', dst) cv2.waitKey(0)测试一下:
probs是经过softmax处理后的打分值,即这个框体是正向框体的可能性是0.58,是负向框体的概率是0.42...。
候选区域建议数目:1799 probs [0.41098363 0.58909637] probs[1] 0.58909637 probs [0.438327280.56167275] probs[1]0.56167275 probs [0.3801731 0.6198269] probs[1] 0.6198269 [219 145 257 151] tensor([0.1703,0.6591],device=' cuda:0')[0.380173100.6198269] 统计正例的数量和分值的数量 8 8 [array([160,101,350,269],dtype=int32),array([219,145,257,151],dtype=int32)][0.7514985,0.6198269]分类器结果:
2.载入函数
def get_device(): return torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') def get_transform(): #数据转换 transform=transforms.Compose([ transforms.ToPILImage(), transforms.Resize((227,227)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5,0.5,,0.5),(0.5,0.5,0.5)) ]) return transform def get_model(device=None): #加载CNN模型 model = alexnet() num_classes = 2 num_features = model.classifier[6].in_features model.classifier[6] = nn.Linear(nun_features,num_classes) model.load_state_dict(torch.load('./models/best_linear_svm_alexnet_car.pth)) model.eval() #取消梯度追踪 for param in model.parameters(): param.requires_grad = False if device: model = model.to(device) return model
3. 非极大值抑制:
def nms(rect_list,score_list): """ 非极大值抑制 @param rect_list: list,大小为[N,4] @param scorelist: list,大小为[N] """ nms.rects = list() nms.scores = list() rect_array = np.array(rect_list) score_array = np.array(score_list) #一次排序后即可 #按分类概率从高到低排序,然后将框体分值从大到小对应排序 idxs = np.argsort(score_array)[::-1] rect_array = rect_array[idxs] score_array = score_array[idxs] thresh = 0.3 while len(score_array) > 0: #添加分类概率最大的边界框 nms_rects.append(rect_array[0]) nms_scores.append(score_array[0]) #将剩余的(除了最大的)放在一起 rect_array = rect_array[1:] score_array = score_array[1:] length = len(score_array) if length <= 0: break #计算IoU:将nms_rects的最后一个框体和其余的框体做IoU运算 iou_scores = util.iou(np.array(nms_rects[len(nms_rects) -1]),rect_array) print(iou_scores) #去除重叠率大于等于thresh = 0.3的边界框,即去除过多重叠框 idxs = np.where(iou_scores < thresh)[0] #更新rect_array rect_array 进入下一个循环 rect_array = rect_array[idxs] rect_array = score_array[idxs] return nms_rects,nms_scores
4.RCNN缺点
RCNN缺点
1、区域选取采用cpu算法。
2、模型三步走的训练方式。
3、svm、岭回归的等方式,训练方式不够先进,而且每次只能训练一个svm。
















 2209
2209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











