







目录
3.1 Continuous disparity network (CDN)
3.2 Learning with Wasserstein distances【https://zhuanlan.zhihu.com/p/58506295】
3.3 Extension: learning with multi-modal ground truths
摘要:
问题:
现有的深度或视差估计方法输出一个在一组预定义的离散值上的分布。当真正的深度或视差与任何这些值都不匹配时,这会导致不准确的结果。这种分布通常是通过回归损失间接学习的,这在对象边界周围的模糊区域造成了进一步的问题。
1.介绍
现有的方法主要通过回归损失来学习分布:最小化平均值和地面真值[12,51]之间的距离。换句话说,没有直接的监督来教模型围绕真相深度分配更高的概率。
提出:
1.一种新的立体视差估计神经网络架构,它能够输出任意视差值上的分布,从中我们可以直接获取模式并绕过均值。与现有的工作一样,我们的模型预测了一个预定义的离散集中的每个离差值的概率。此外,它还预测了每个离散值的实值偏移量。这种简单的预测偏移量加法使我们能够在推理过程中使用该模式作为预测,而不是平均值,从而保证所预测的深度具有较高的估计概率。图2说明了我们的模型,连续视差网络(CDN)。
2.一种新的损失函数,它在训练过程中提供了一个更有信息性的目标。具体地说,我们允许单模态或多模态的地面真实深度分布(从附近的像素获得),并表示它们为Dirac delta functions的(混合)。然后,学习的目标是最小化预测的真实分布和地面真实分布之间的散度。注意到这两个分布可能没有共同的支持,我们应用Wasserstein distance[39]来测量散度。

我们提出的方法在数学上都有充分的基础,实际上也非常简单。它与大多数现有的立体深度或视差估计方法兼容——我们只需要添加一个额外的偏移分支,用Wasserstein distance取代常用的回归损失。我们使用多个现有的立体网络[4,51,54]在三个任务验证了我们的方法:立体视差估计[25]、立体深度估计[9]和三维目标检测[9]。最后一个是使用立体深度作为输入来检测三维对象的下游任务。我们进行了全面的实验,并表明我们的算法在这三个任务中都有了显著的改进。
2.背景
立体声深度估计技术通常首先估计像素单位的视差,然后利用倒数关系来近似深度。基本方法是将左图像Il中的像素(u、v)与右图像Ir中的像素(u、vd)进行比较,并找到最佳匹配。由于像素坐标被约束为整数,因此d也被约束为一个整数。因此,估计的视差是一个整数,迫使估计的深度是少数几个离散值之一。
3.视差估计
我们指出了取平均估计的两个缺点:
1.首先,当预测的分布为多模态时,平均值可能会偏离模式,并可能错误地预测低概率值(见图3)。这种多模态分布经常出现在对象边界周围的像素上。虽然它们总共只占图像像素的一小部分,但最近的研究表明了它们在三维对象检测[18,19,31]等下游任务中的特别重要性。
2.其次,平均值的物理意义绝不是与真正的差距:不确定性对应可能产生40%的机会差距为10像素和60%的机会差距为20像素,但这并不意味着差距应该是16像素。

3.1 Continuous disparity network (CDN)
我们的网络的输出仍然将是一组具有相应概率的离散值,但离散值将不限于整数。关键的想法是从integral disparity values开始,除了概率之外还预测偏移。
用D表示integral disparity values的集合。如上所述,视差估计技术会为每个d∈D产生一个成本Sdisp(u、v、d)。softmax可将此成本转换为概率分布:
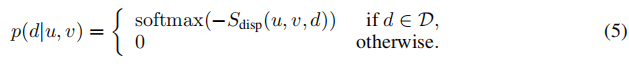
我们建议添加一个子网络b(u、v、d),它可以预测每个像素(u、v)处的每个d∈D的一个偏移视差值。
我们使用它来将d∈D处的概率质量移为d'=db(u,v,d)。由此导致了以下概率分布:
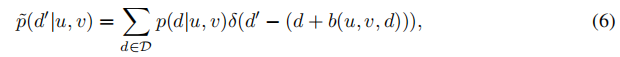
这是在任意视差值d'上的Dirac delta functions的混合物。
在我们的实现中,子网络b(u、v、d)与Sdisp(u、v、d)共享其特征和计算,除了完全连接或卷积层的最后一个块。
3.2 Learning with Wasserstein distances【https://zhuanlan.zhihu.com/p/58506295】
分布之间有许多流行的散度测量方法,如KL散度、JS散度, total Variation, the Wasserstein distance等。在本文中,我们选择the Wasserstein distance是出于一个特殊的原因:p˜(d'|u,v)和p*(d'|u,v)可能没有任何共同的支持。![]()
在一个度量空间(X、d)上的两个分布µ、ν之间的Wasserstein-p distance被定义为:
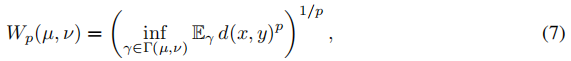
其中,Γ(µ,ν)表示所有联合分布γ(x,y)的集合,其边际分布γ(x)和γ(y)分别恰好为µ和ν。直观上,γ(x,y)表示为了将分布µ转换为ν,需要从x到y传输多少“质量”。估计瓦瑟斯坦的距离通常是非常平凡的,需要解决一个线性规划问题。一个特殊的例外是,当µ和ν都是一维变量的分布时,这就是我们在视差值上的分布的情况。具体来说,当ν是一个Dirac delta functions时,其支持点位于y*,Wasserstein-p distance可以简化为:

3.3 Extension: learning with multi-modal ground truths
学习匹配分布的一个特殊优点是,允许在单个像素位置使用多个地面真值(即多模态地面真值分布)。D*为一个像素(u、v)处的地面真值视差值集时,地面真值分布变为:
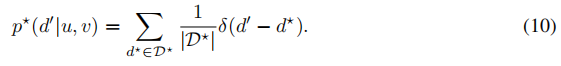
从p*(d'|u,v)不是一个Dirac delta functions,我们不能再应用方程8,而是应用下面的方程来比较两个一维分布[27,32,42]:
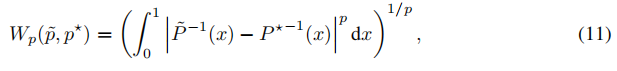
P˜和P*分别为p˜和p*的累积分布函数(CDFs)。对于案例p=1,我们可以将方程式11重写为[38]:
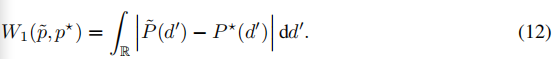
我们注意到,方程11和方程12都可以计算出系数。
虽然现有的数据集并没有直接提供多模态的地面真理,但我们研究了以下过程来构造它们。对于每个像素,我们考虑一个k×k邻域,并通过将中心像素视差设置权重α,其余的分别为(1−α)/(k×k−1)来创建一个多模态分布。我们在实验中设置了k=3和α=0.8。我们的实证研究表明,使用多模态的地面真值可以导致更快的模型收敛速度。
4. 实验

4.2 实施的详细信息
我们主要使用W1损失来训练我们的CDN模型。
Stereo disparity.
我们将我们的连续视差网络(CDN)体系结构应用于PSMNet[4]和GANet[54],即CDN-PSMNET和CDN-GANET。
The offset sub-network.
我们使用Conv3D-Relu-Conv3D块实现b(u、v、d)。它以Sdisp(u、v、d)的最后一个全连接或卷积块之前的4D成本体积作为输入。
Multi-modal ground truths.
略~















 3533
3533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









