




《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
这篇文章主要介绍一下关于YOLOv8的网络结构配置文件yolov8.yaml的详细解读与说明。帮助各位小伙更好的理解YOLOv8网络结构的配置文件写法,也便于后期自己对于网络结构进行改进,然后修改配置文件。
网络结构

YOLOv8网络主要包含3个部分【Backbone,Neck, Head】,主要作用如下:
-
Backbone主干网络是模型的基础,负责从输入图像中提取特征。这些特征是后续网络层进行目标检测的基础。 在YOLOv8中,主干网络采用了类似于CSPDarknet的结构。
-
Neck颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。
-
Head头部网络是目标检测模型的决策部分,负责产生最终的检测结果。
yolov8.yaml配置文件的作用就是根据文件内容,构建出上述整个网络。下面对yolov8.yaml配置文件进行详细讲解。
配置文件
关于YOLOv8网络的配置文件yolov8.yaml的详细内容如下:
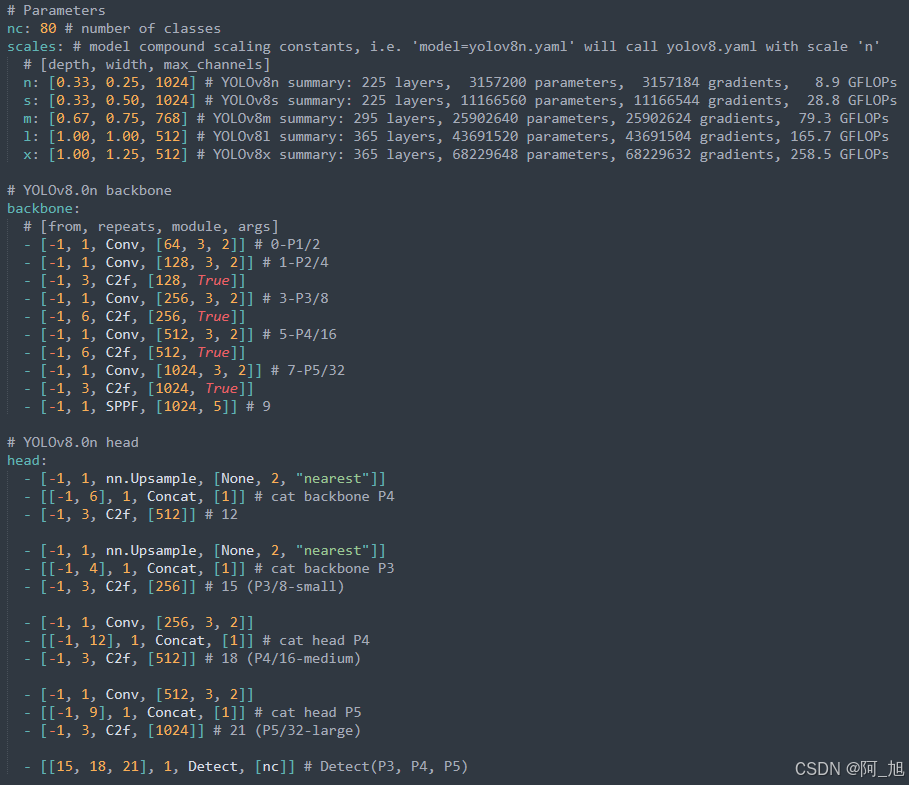
配置文件主要分为三个部分: 参数部分【Parameters】,主干部分【backone】,头部部分【head】。下面分别对这几个部分进行详细说明。
参数部分【Parameters】
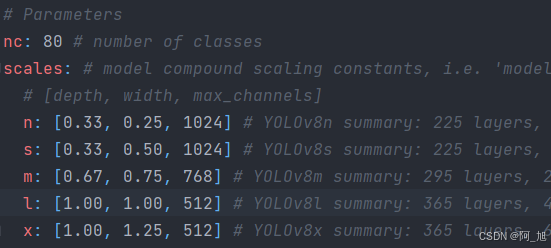
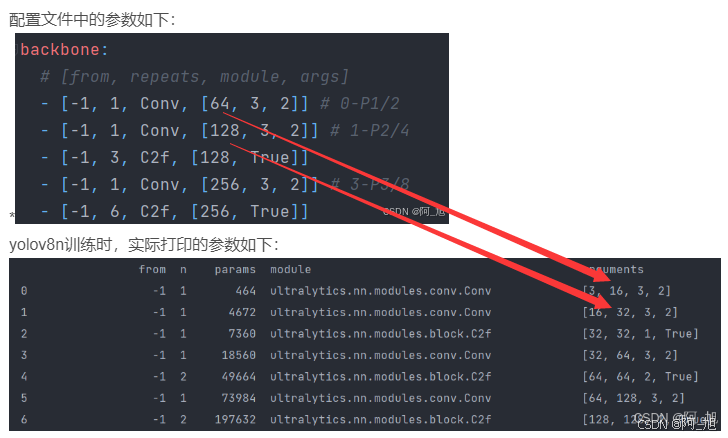
nc: 80指的是数据集中的类别数量。scales代表模型尺寸,分了n,s,m,l,x这5个不同大小的尺寸,参数量依次从小到大。[depth, width, max_channels]分别表示网络模型的深度因子、网络模型的宽度因子、最大通道数。depth深度因子的作用:表示模型中重复模块的数量或层数的缩放比例。这里主要用来调整C2f模块中的子模块Bottelneck重复次数。比如主干中第一个C2f模块的number系数是3,我们使用0.33x3并且向上取整就等于1了,这就代表第一个C2f模块中Bottelneck只重复一次;width宽度因子的作用:表示模型中通道数(即特征图的深度)的缩放比例,如果某个层原本有64个通道,而width设置为0.5,则该层的通道数变为32。比如使用yolov8n.yaml文件,参数为[0.33, 0.25, 1024]。第一个Conv模块的输出通道数写的是64,但是实际上这个通道数并不是64,而是使用宽度因子0.25x64得到的最终结果16;同理,C2f模块的输出通道虽然在yaml文件上写的是128,但是在实际使用时依然要乘上宽度因子0.25,那么第一个C2f模块最终的到实际通道数就是0.25x128 = 32。如下图所示,其他的依次类推。max-channels表示每层最大通道数。每层的通道数会与这个参数进行一个对比,如果特征图通道数大于这个数,那就取max_channels的值。
主干部分【backbone】
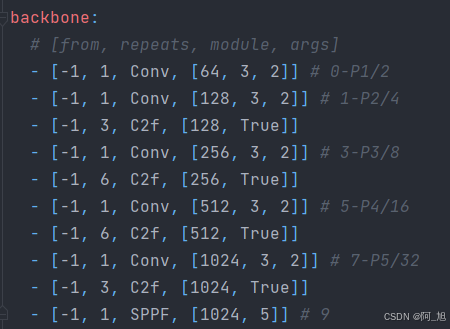
主干部分有四个参数[from, number, module, args] ,解释如下:
from,这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。number,这个参数表示模块重复的次数,如果为3则表示该模块重复3次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于C2f模块来说,这个number就代表C2f中Bottelneck模块重复的次数。module,这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第二层使用了C2f模块。args,表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层conv参数【64,3,2】:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。
每一层解释如下,见注释:
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 第0层,-1代表将上层的输入作为本层的输入。第0层的输入是640*640*3的图像。Conv代表卷积层,相应的参数:64代表输出通道数,3代表卷积核大小k,2代表stride步长。
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 第1层,本层和上一层是一样的操作(128代表输出通道数,3代表卷积核大小k,2代表stride步长)
- [-1, 3, C2f, [128, True]] # 第2层,本层是C2f模块,3代表本层重复3次。128代表输出通道数,True表示Bottleneck有shortcut。
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 第3层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为80*80*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/8。
- [-1, 6, C2f, [256, True]] # 第4层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。256代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是80*80*256。
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 第5层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/16。
- [-1, 6, C2f, [512, True]] # 第6层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。512代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是40*40*512。
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 第7层,进行卷积操作(1024代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*1024(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/32。
- [-1, 3, C2f, [1024, True]] #第8层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是20*20*1024。
- [-1, 1, SPPF, [1024, 5]] # 9 第9层,本层是快速空间金字塔池化层(SPPF)。1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4),经过一次Conv得到20*20*1024。
其他说明:
各层注释中的P1/2表示该层特征图缩放为输入图像尺寸的1/2,是第1特征层;P2/4表示该层特征图缩放为输入图像尺寸的1/4,是第2特征层;其他的依次类推。
头部
head部分的写法与backbone部分相同,也是按照[from, number, module, args] 这4个参数进行编写。
每一层的详细说明见注释:
# YOLOv8.0n head 头部层
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 第10层,本层是上采样层。-1代表将上层的输出作为本层的输入。None代表上采样的size=None(输出尺寸)不指定。2代表scale_factor=2,表示输出的尺寸是输入尺寸的2倍。mode=nearest代表使用的上采样算法为最近邻插值算法。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为40*40*1024。
- [[-1, 6], 1, Concat, [1]] # cat backbone P4 第11层,本层是concat层,[-1, 6]代表将上层和第6层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*1024,第6层的输出是40*40*512,最终本层的输出尺寸为40*40*1536。
- [-1, 3, C2f, [512]] # 12 第12层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。与Backbone中C2f不同的是,此处的C2f的bottleneck模块的shortcut=False。
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 第13层,本层也是上采样层(参考第10层)。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为80*80*512。
- [[-1, 4], 1, Concat, [1]] # cat backbone P3 第14层,本层是concat层,[-1, 4]代表将上层和第4层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是80*80*512,第6层的输出是80*80*256,最终本层的输出尺寸为80*80*768。
- [-1, 3, C2f, [256]] # 15 (P3/8-small) 第15层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。256代表输出通道数。经过这层之后,特征图尺寸变为80*80*256,特征图的长宽已经变成输入图像的1/8。
- [-1, 1, Conv, [256, 3, 2]] # 第16层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。
- [[-1, 12], 1, Concat, [1]] # cat head P4 第17层,本层是concat层,[-1, 12]代表将上层和第12层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*256,第12层的输出是40*40*512,最终本层的输出尺寸为40*40*768。
- [-1, 3, C2f, [512]] # 18 (P4/16-medium) 第18层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。经过这层之后,特征图尺寸变为40*40*512,特征图的长宽已经变成输入图像的1/16。
- [-1, 1, Conv, [512, 3, 2]] # 第19层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。
- [[-1, 9], 1, Concat, [1]] # cat head P5 第20层,本层是concat层,[-1, 9]代表将上层和第9层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是20*20*512,第9层的输出是20*20*1024,最终本层的输出尺寸为20*20*1536。
- [-1, 3, C2f, [1024]] # 21 (P5/32-large) 第21层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数。经过这层之后,特征图尺寸变为20*20*1024,特征图的长宽已经变成输入图像的1/32。
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5) 第20层,本层是Detect层,[15, 18, 21]代表将第15、18、21层的输出(分别是80*80*256、40*40*512、20*20*1024)作为本层的输入。nc是数据集的类别数。
这部分主要多出3个操作nn.Upsample、Concat、Detect,解释如下:
nn.Upsample:表示上采样,将特征图大小进行翻倍操作。比如将大小为20X20的特征图,变为40X40的特征图大小。
Concat:代表拼接操作,将相同大小的特征图,通道进行拼接,要求是特征图大小一致,通道数可以不相同。例如[-1, 6]:-1代表上一层,6代表第六层(从第0层开始数),将上一层与第6层进行concat拼接操作。
Detect的from有三个数,15,18,21,这三个就是最终网络的输出特征图,分别对应P3,P4,P5。
模型训练时打印出的结构参数如下,【下图为yolov8n.yaml打印信息】:
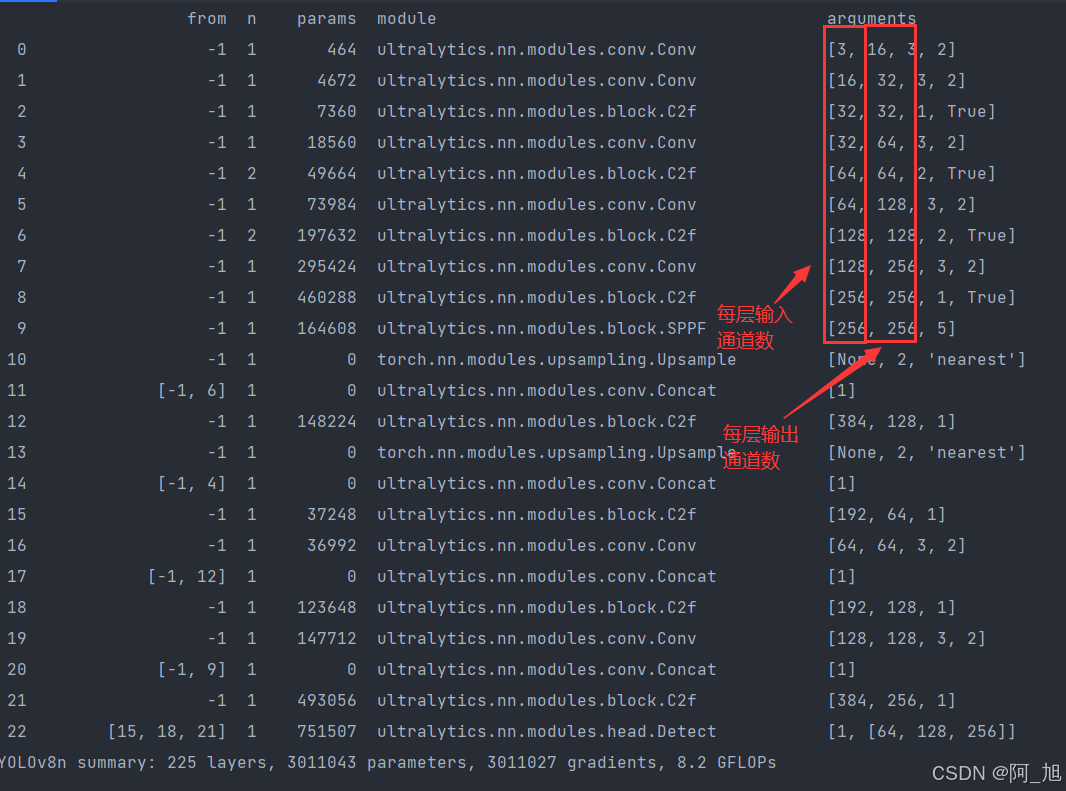
好了,这篇文章就介绍到这里,如果对你有帮助,感谢点赞关注!

关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











