







《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
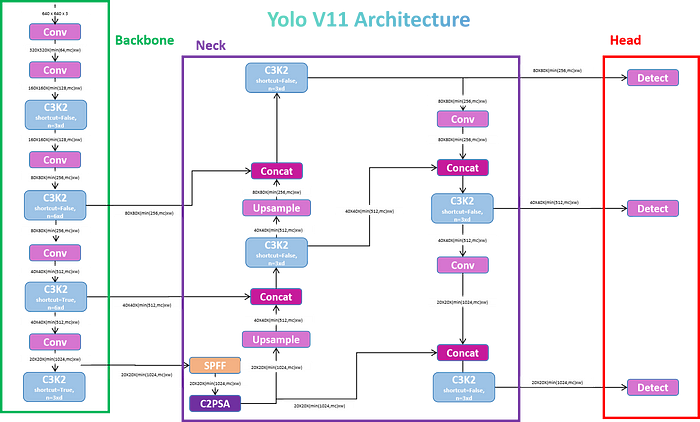
YOLOv11模型架构
在不断发展的人工智能和计算机视觉领域,目标检测已成为最关键的任务之一。无论是使自动驾驶汽车能够识别障碍物,还是帮助监控系统实时跟踪运动,物体检测模型已经彻底改变了无数行业。YOLO(You Only Look Once)系列模型不断突破极限,平衡实时速度和精确度。通过YOLOv 11,我们看到了多年创新的顶峰-带来比以往任何时候都更快,更准确,更高效的目标检测。本文将带您了解YOLOv 11的架构之旅,与以前版本的比较以及在项目中实现它的实用指南。
YOLO模型概述
目标检测是计算机视觉中最具挑战性的任务之一,涉及图像中目标的准确识别和定位。像R-CNN这样的传统对象检测方法通常需要花费大量时间来处理图像,生成所有响应,然后对它们进行分类,这对于实时应用来说效率低下。
YOLO的诞生:You Only Look Once
Joseph雷德蒙、Santosh Divvala、Ross Girshick、Ali Farhad在CVPR上发表了一篇名为“You Only Look Once:Unified,Real-Time Object Detection“的论文,介绍了一种名为YOLO的革命性模型。主要目的是创建一个更快的单次检测算法,而不影响准确性。这是一个回归问题,其中图像一旦通过FNN就可以获得多个对象的边界框坐标和相应的类。
它的创新之处在于它的单镜头检测方法,将图像划分为网格,直接为每个网格单元预测边界框和类概率。这使得YOLO更快,更高效,比Faster R-CNN等两阶段模型实现了显着的速度提升。
YOLO发展历程(V1到V11)
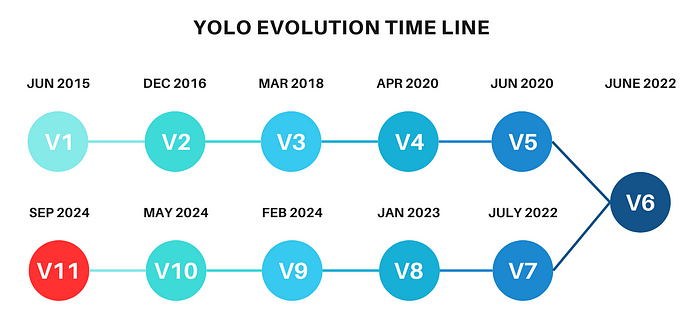
自引入YOLOv1以来,该模型经历了多次迭代,每次迭代都在准确性,速度和效率方面有所改进。以下是不同YOLO版本的主要里程碑:
- YOLOv1(2016):最初的YOLO模型是为速度而设计的,实现了实时性能,但由于其粗网格系统,在小物体检测方面遇到了困难
- YOLOv2(2017):引入了批量归一化、锚框和更高分辨率的输入,从而实现更准确的预测和更好的本地化
- YOLOv3(2018):使用特征金字塔进行多尺度预测,改进了对不同大小和尺度的物体的检测
- YOLOv4(2020):专注于数据增强的改进,包括马赛克增强和自对抗训练,同时还优化了骨干网络以实现更快的推理
- YOLOv5(2020):虽然由于缺乏正式的研究论文而引起争议,但YOLOv5由于在PyTorch中实现而被广泛采用,并且针对实际部署进行了优化
- YOLOv6、YOLOv7(2022年):改进了模型缩放和准确性,引入了更高效的模型版本(如YOLOv7 Tiny),在边缘设备上表现出色
- YOLOv8:YOLOv8引入了CSPDarkNet骨干网和路径聚合等架构更改,与以前的版本相比,提高了速度和准确性
- YOLOv11(2024):最新的YOLO版本YOLOv11引入了更高效的架构,包括C3K2块、SPFF(空间金字塔快速池化)和C2PSA等高级注意力机制。YOLOv11旨在增强小物体检测并提高准确性,同时保持YOLO以实时推理速度而闻名。
YOLOv11架构详解
YOLOv11的架构旨在优化速度和准确性,并建立在YOLOv8,YOLOv9和YOLOv10等早期YOLO版本中引入的改进之上。YOLOv11的主要架构创新围绕着C3K2块、SPFF模块和C2PSA块,所有这些都增强了它处理空间信息的能力,同时保持高速推理。
1.骨干
a.卷积块
该块被命名为Conv块,其处理给定的c,h,w通过2D卷积层,然后是2D批归一化层,最后是SiLU激活函数
B.瓶颈层
这是一个带有快捷参数的卷积块序列,参数True或者False将决定您是否要获取残差部分。它类似于ResNet Block,如果快捷方式设置为False,则不会考虑任何残留。
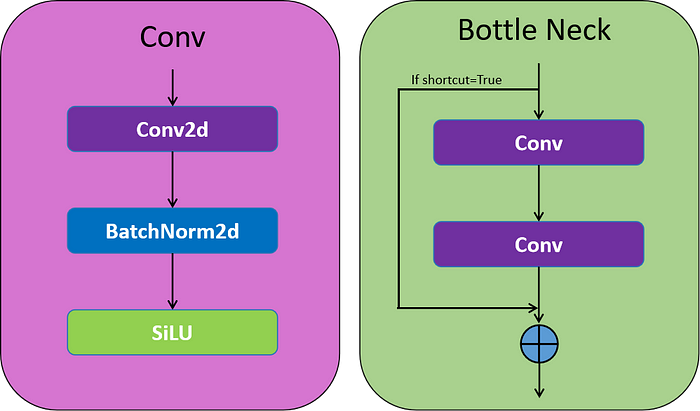
卷积块和瓶颈层
C. C2F(YOLOv8)
C2F块(跨阶段部分聚焦,CSP-Focus)源自CSP网络,特别关注效率和特征图保存。这个块包含一个Conv块,然后将输出分成两半(其中通道被划分),它们通过一系列’n’瓶颈层进行处理,最后将每个层输出与最后的Conv块相连。这有助于增强特征图连接,而无需冗余信息。
d. C3K2
YOLOv 11使用C3 K2块来处理主干不同阶段的特征提取。较小的3x3内核允许更有效的计算,同时保留模型捕获图像中基本特征的能力。YOLOv11主干的核心是C3K2块,它是早期版本中引入的CSP(跨阶段部分)瓶颈的演变。C3K2模块通过分割特征图并应用一系列较小的内核卷积(3x3)来优化网络中的信息流,这比较大的内核卷积更快,计算成本更低。通过处理较小的独立特征图并在几次卷积后合并它们,C3K2模块与YOLOv8的C2f模块相比,使用更少的参数来改进特征表示。
C3K块包含与C2F块类似的结构,但这里不会进行拆分,输入通过Conv块,然后是一系列具有连接的’n’个瓶颈层,并以最终Conv块结束。
C3 K2使用C3 K块来处理信息。它在开始和结束时有2个Conv块,随后是一系列C3K块,最后是Conv块输出和最后一个C3K块输出,并以最后一个Conv块结束。该块侧重于保持速度和精度之间的平衡,利用CSP结构。
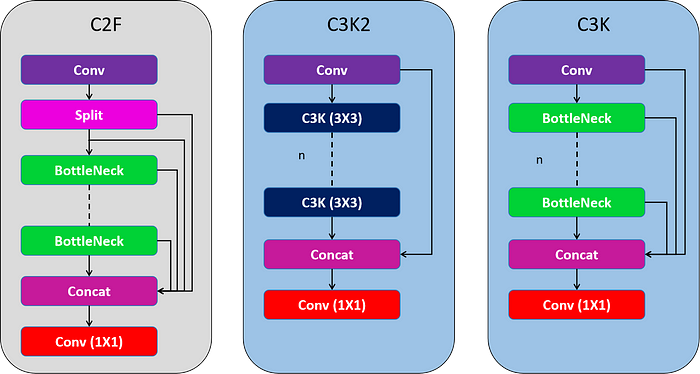
C2F和C3K2块的比较
2.颈部:空间金字塔池化快速(SPFF)和上采样
YOLOv11保留了SPFF模块(Spatial Pyramid Pooling Fast),该模块旨在以不同的尺度汇集图像不同区域的特征。这提高了网络捕获不同大小物体的能力,特别是小物体,这对早期的YOLO版本来说是一个挑战。
SPFF使用多个最大池化操作(具有不同的内核大小)来聚合多尺度上下文信息。该模块可确保即使是很小的物体也能被模型识别,因为它有效地结合了不同分辨率的信息。SPFF的加入确保了YOLOv11可以保持实时速度,同时增强了其在多个尺度上检测物体的能力。
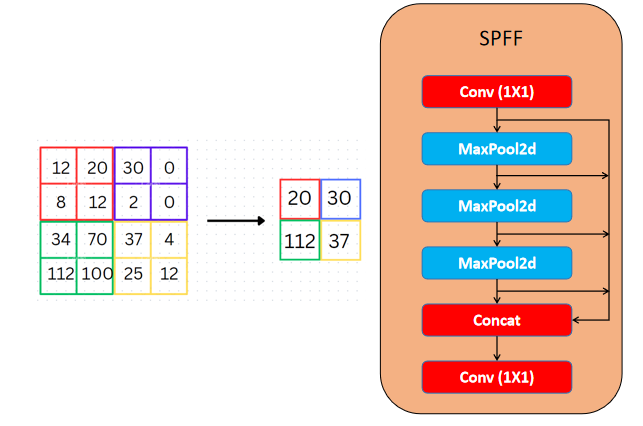
空间金字塔池化快速
3.注意机制:C2PSA模块
YOLOv11的一个重要创新是增加了C2PSA模块(跨阶段部分空间注意力)。这个模块引入了注意力机制,通过强调特征图中的空间相关性,提高了模型对图像中重要区域的关注度,例如较小或部分遮挡的对象。
a.位置敏感注意力
该类封装了将位置敏感注意力和前馈网络应用于输入张量的功能,增强了特征提取和处理功能。该层包括用Attention层处理输入层,并将输入和Attention层输出连接,然后通过前馈神经网络,然后是Conv Block,然后是Conv Block,没有激活,然后将Conv Block输出和第一个接触层输出连接。
b. C2PSA
C2PSA块使用两个PSA(部分空间注意力)模块,它们在特征图的不同分支上操作,然后连接起来,类似于C2F块结构。这种设置确保模型专注于空间信息,同时保持计算成本和检测精度之间的平衡。C2PSA模块通过在提取的特征上应用空间注意力来细化模型选择性地关注感兴趣区域的能力。这使得YOLOv11在精确检测需要精细对象细节的场景中优于YOLOv8等以前的版本。
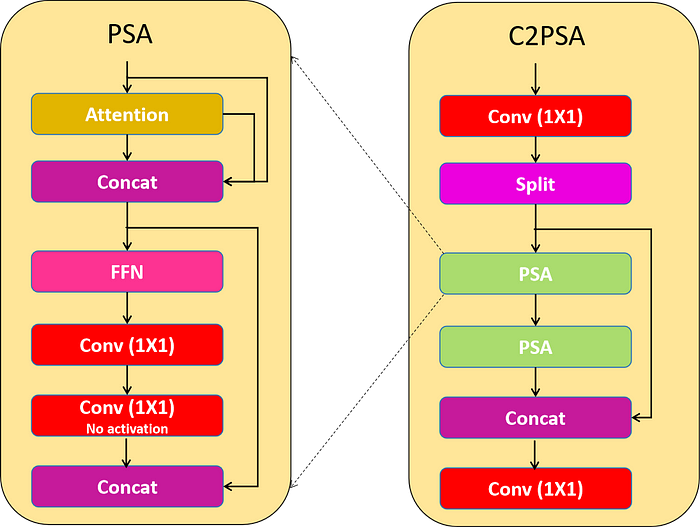
4. Head:检测和多尺度预测
与早期的YOLO版本类似,YOLOv11使用多尺度预测头来检测不同大小的物体。头部使用由脊柱和颈部生成的特征图输出三种不同尺度(低、中、高)的检测框。
检测头从三个特征图(通常来自P3、P4和P5)输出预测,对应于图像中的不同粒度级别。这种方法确保了小物体被更精细地检测到(P3),而较大的物体被更高级别的特征捕获(P5)。
YOLOv11代码实现
这里是一个使用PyTorch的YOLOv11的最小而简洁的实现步骤。这将为您测试图像上的对象检测提供一个明确的起点。
步骤1:安装库
首先,确保您安装了必要的依赖项:
pip install torch torchvision ultralytics
步骤2:加载YOLOv11模型
以下代码片段演示了如何加载YOLOv11模型并对输入图像运行推理:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO11n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
# Inference on a video
results = model('video.mp4', save=True)
这个最小的代码涵盖了使用YOLOv11模型加载、运行和显示结果。
YOLOv11的性能说明
在本节中,我们将讨论如何使用常见的对象检测指标来评估YOLOv11模型的性能。这些指标有助于量化准确性和速度,这对实时应用至关重要。
1.平均精度(mAP)
- mAP是跨多个类和IoU阈值计算的平均精度。它是对象检测任务中最常见的指标,可以深入了解模型在精确度和召回率之间的平衡程度。
- 更高的mAP值表示更好的对象定位和分类,特别是对于小的和被遮挡的对象。由于C3K2和C2PSA块的改善
2.并交比(IoU)
- IoU测量预测的边界框和地面实况框之间的重叠。IoU阈值(通常设置在0.5和0.95之间)用于确定预测是否被视为真阳性。
3.每秒帧数(FPS)
- FPS测量模型的速度,表示模型每秒可以处理多少帧。更高的FPS意味着更快的推理,这对于实时应用至关重要。
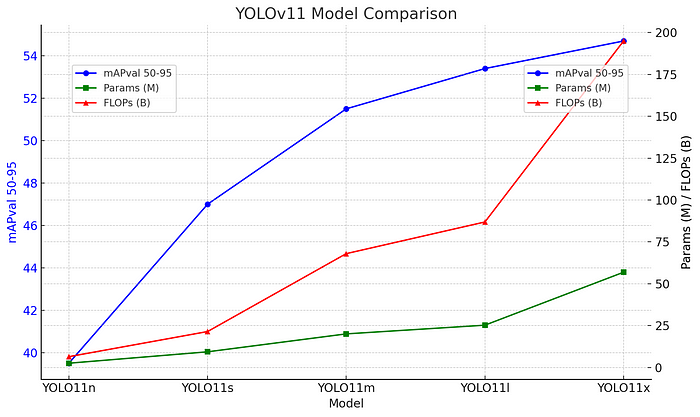
不同版本YOLOv11模型在检测任务中的比较
YOLOv11与以前版本的性能比较
在本节中,我们将重点比较YOLOv11与YOLOv8、YOLOv9和YOLOv10等早期型号的性能。性能比较将涵盖诸如平均精度(mAP)、推理速度(FPS)和对象检测和分割等各种任务的参数效率等指标。
用于比较的关键参数
- mAP(Mean Average Precision):mAP是对象检测最常用的指标,它可以跨多个交并比(IoU)阈值测量精度和召回率。
- FPS(每秒帧数):表示模型处理图像或视频帧的速度,这是实时应用程序的关键因素。
- 参数计数和FLOPs:这些指标有助于确定模型的计算成本,特别是在边缘设备上部署时。
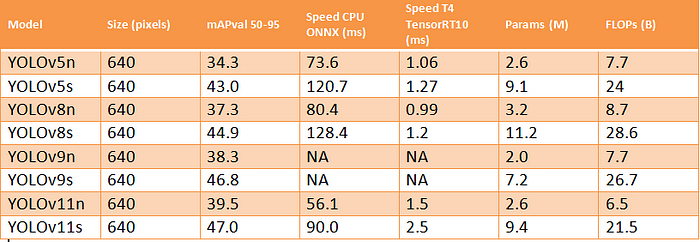
YOLO v5,v8,v9和v11的nano和small版本的指标对比表。
结论
总之,YOLOv11标志着物体检测领域的一个重要里程碑,它提供了速度、准确性和效率的更优组合。它的架构改进,例如用于有效特征提取的C3K2块和用于增强对关键图像区域的关注的C2PSA注意机制,使其性能优于YOLOv8和YOLOv10等以前的版本。随着mAP分数和FPS速率的提高,YOLOv11继续推动实时对象检测的边界。
该模型的灵活性使其成为各种现实应用的主要候选者,从自动驾驶到医学成像,精确和快速推理都至关重要。YOLOv11在多尺度检测和空间注意力方面的进步使其能够在具有复杂对象结构的环境中表现出色,同时保持其标志性的快速推理能力。
总体而言,YOLOv11不仅是一次迭代,而且是一次飞跃,使其成为当今最有效、最通用的目标检测模型之一。对于那些从事实时检测任务的人来说,YOLOv11提供了一个实用的解决方案,可以平衡速度和准确性之间的权衡。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











