






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转载自:我爱计算机视觉论文信息:

论文链接:https://arxiv.org/abs/2412.19412
代码链接:https://github.com/LSXI7/MINIMA
在线demo:https://huggingface.co/spaces/lsxi77777/MINIMA
摘要:
跨视图、跨模态图像匹配是多模态融合感知中的核心问题之一,具有重要实际意义。然而,由于不同成像系统或风格所引发的模态差异,该任务面临严峻挑战。现有方法通常专注于提取特定模态的不变特征,并依赖有限规模的数据集进行训练,其泛化能力十分有限。
为解决上述难题,本文提出一种统一的多模态图像匹配框架——MINIMA。该方法摒弃了复杂模块设计的传统思路,转而从数据扩增的角度出发,旨在全面提升模型的通用性能。
为此,我们设计了一种简洁高效的数据引擎,能够生成包含多种模态、丰富场景以及精确匹配标签的大规模数据集。具体而言,通过引入生成模型,我们将廉价且易于获取的RGB匹配数据扩展至其他模态类型,从而有效继承原始RGB数据集中丰富的匹配标签和多样性。基于此,我们构建了大规模合成数据集MD-syn,填补了当前多模态图像匹配领域的数据空白。
实验结果表明,借助MD-syn数据集,现有的匹配模型能够轻松获得强大的跨模态匹配能力。我们在涵盖视觉、遥感、医学等多个领域的19种跨模态匹配任务中进行了全面测试,结果显示MINIMA框架可显著提升基准方法的综合性能及零样本泛化能力,最高提升幅度可达98%。此外,在某些模态任务上,我们的方法甚至超越了特定模态的专有方法。
文章亮点:
首个跨模态统一匹配框架MINIMA:一次训练即可适配视觉、遥感、医学等多领域的19种跨模态场景。
首个大规模多模态匹配数据集MD-syn:对标Megadepth,利用生成模型构建数据引擎,自动生成4.8亿对高质量跨模态图像对,同时涵盖稠密匹配标签,为多模态图像匹配研究填补了数据空白。
行业应用新突破:MINIMA在真实多模态场景中可显著提升基准方法的性能,为多模态感知任务提供了全新的技术基础,可用于多源多模态图像配准、融合感知、多模态定位导航、3D生成等任务。
整体结果展示:
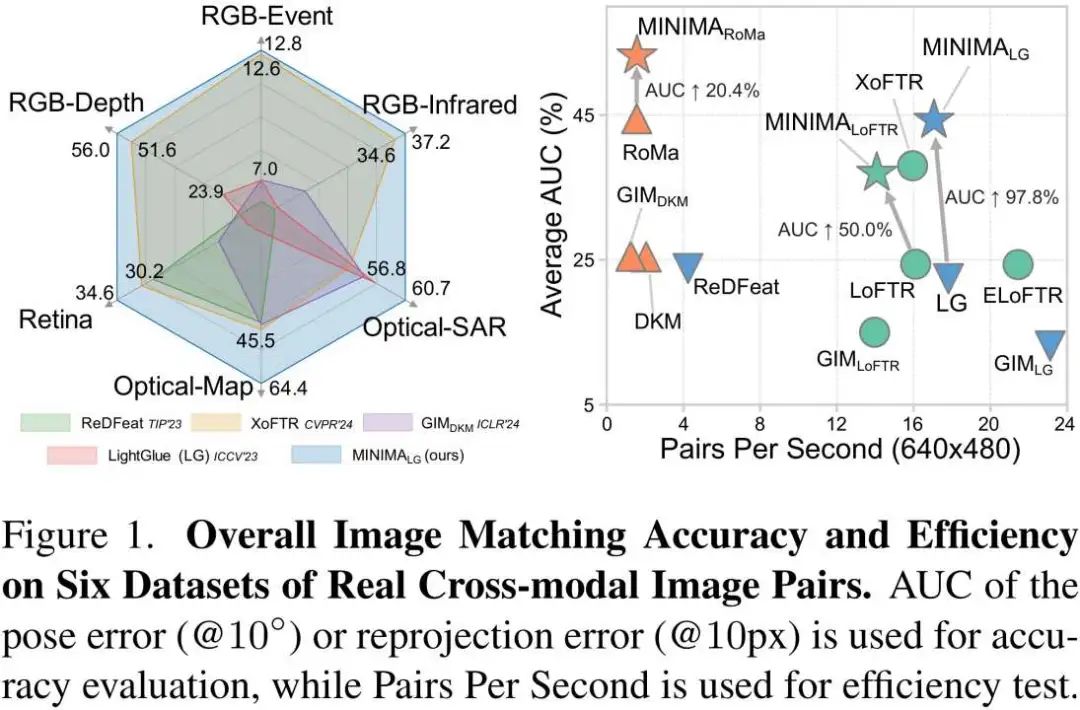
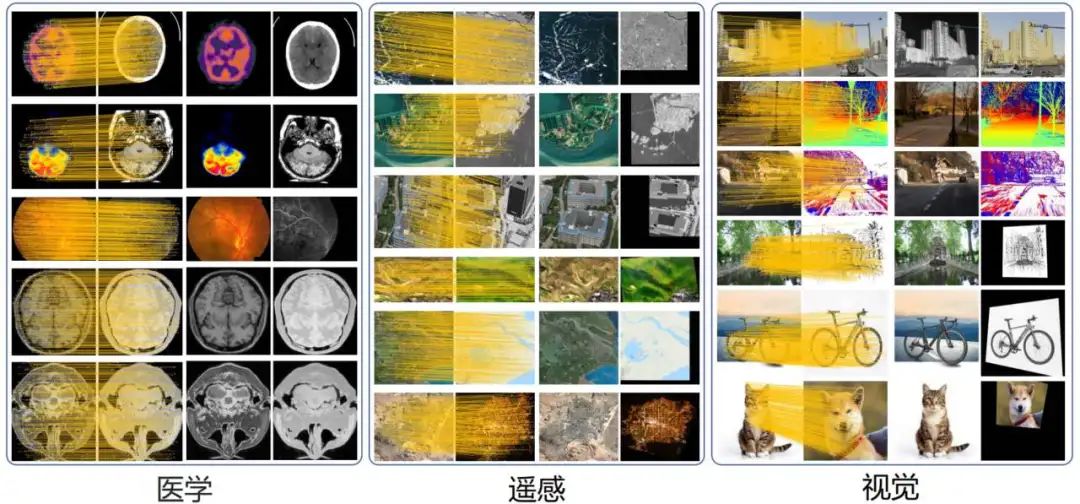
MINIMA实现细节
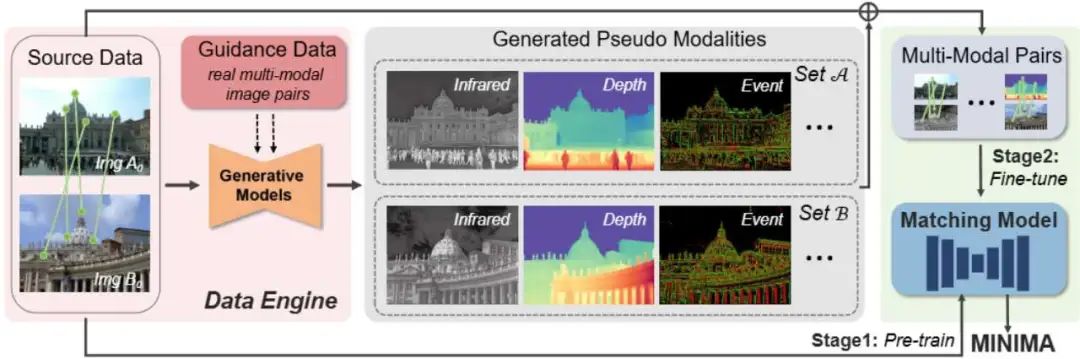
MINIMA 框架分为两大核心模块,如图所示:
1.数据生成引擎:以 MegaDepth 数据集为基础,利用数据引擎生成包括红外(Infrared)、深度(Depth)、事件(Event)等在内的多种模态数据。生成的数据在模态多样性和场景覆盖性上均优于现有数据集。
2.匹配模型训练:采用“预训练 + 微调”的两阶段策略。第一阶段在多视角 RGB 数据上进行预训练;第二阶段在生成的跨模态数据上进行微调,快速适应多模态任务。
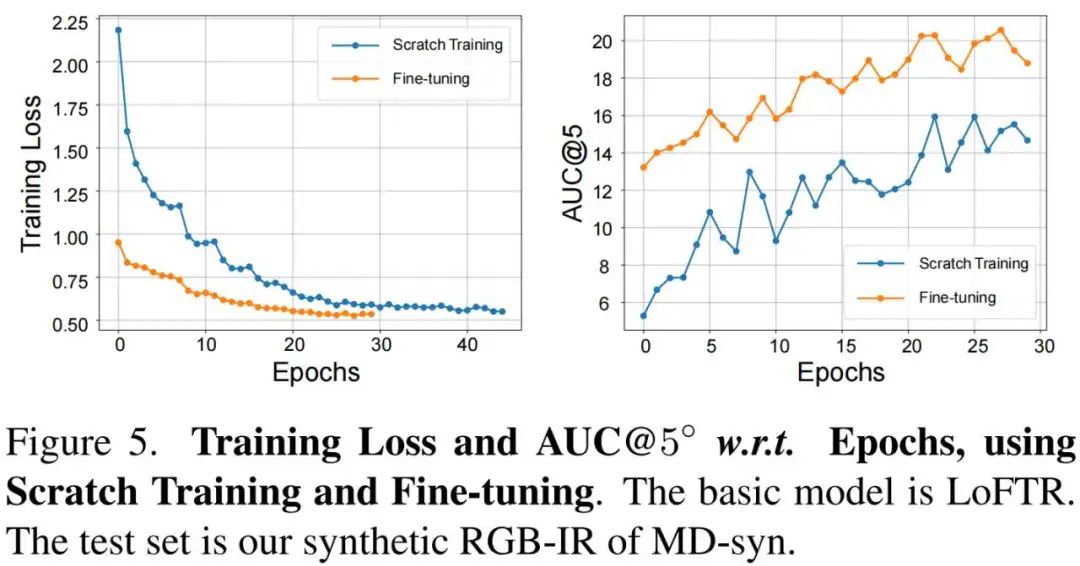
如下图所示。由于不同模态之间的差异性,直接在MD-syn上重新开始训练需要较大代价,而从单一可见光数据训练的模型可以提供良好的匹配先验,从而使多模态微调过程快速收敛。
论文其他图表结果

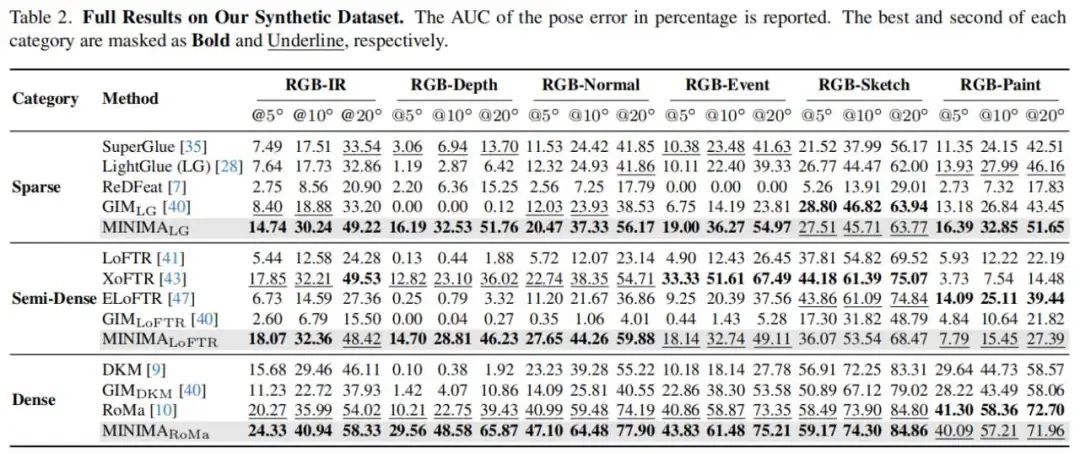
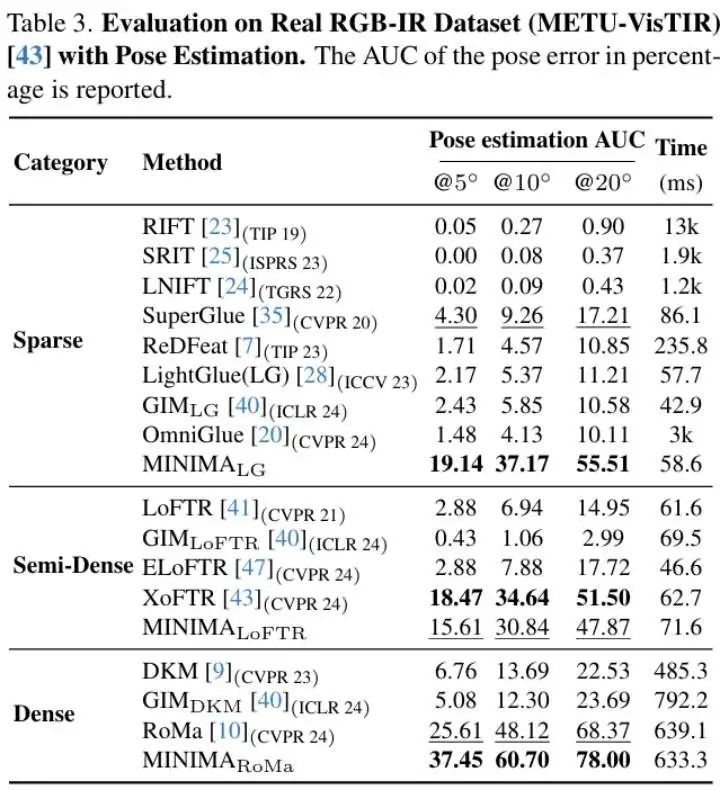
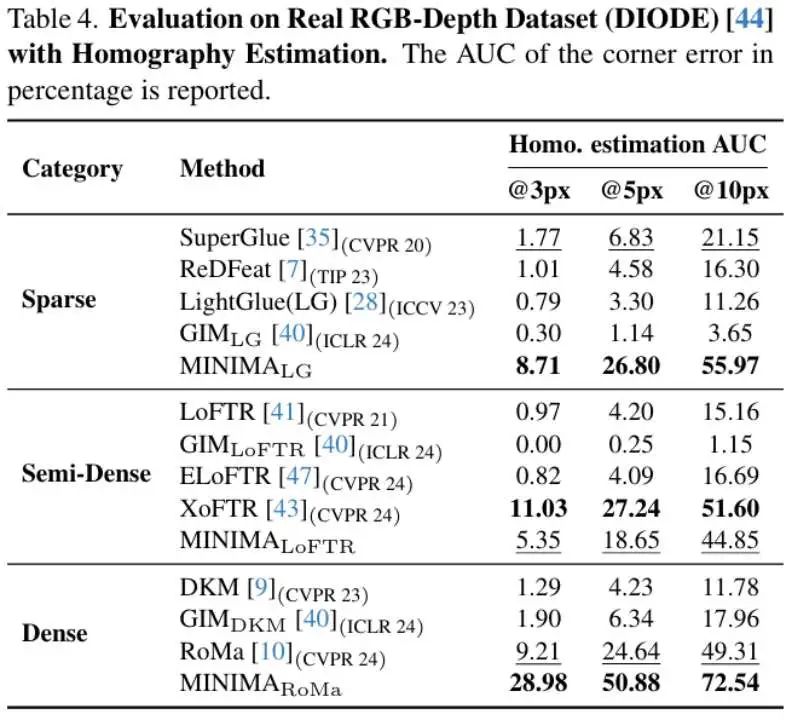
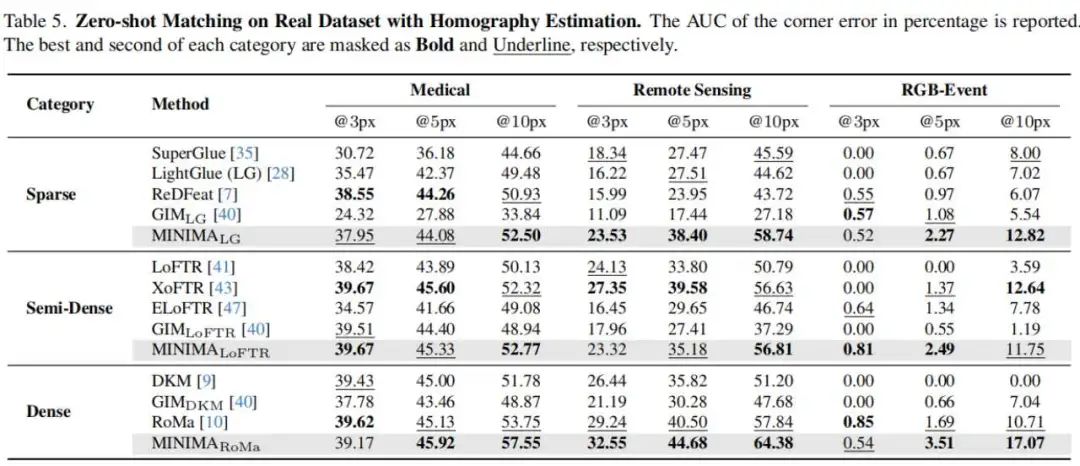
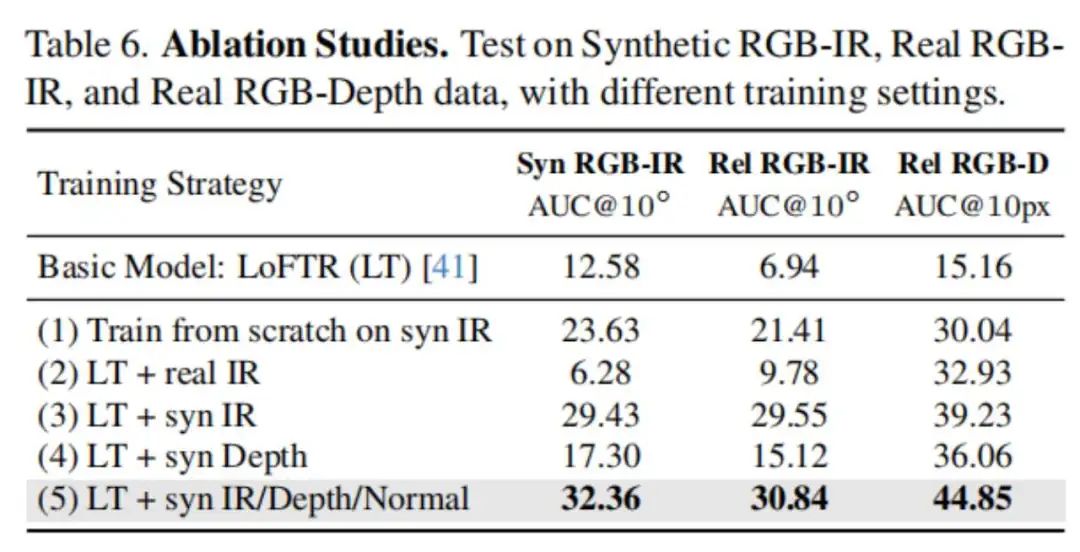
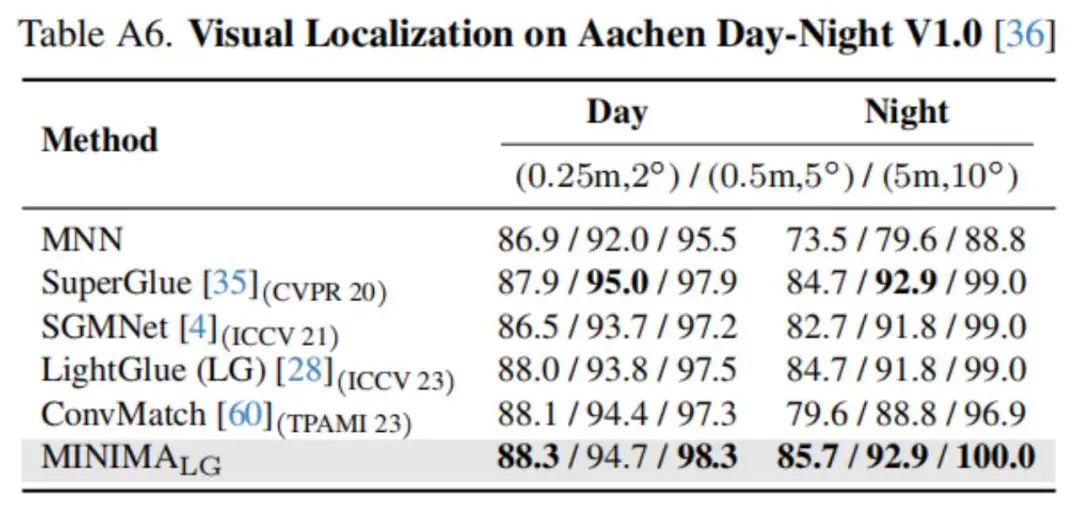
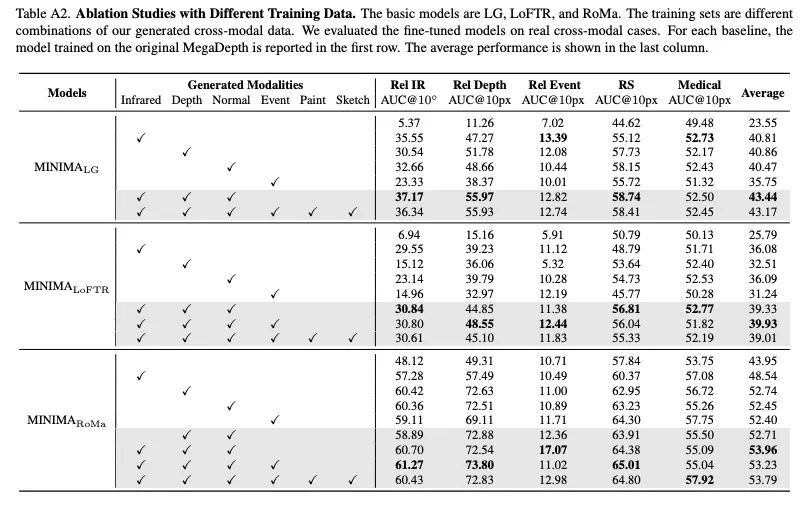
消融实验和视觉定位应用实验结果
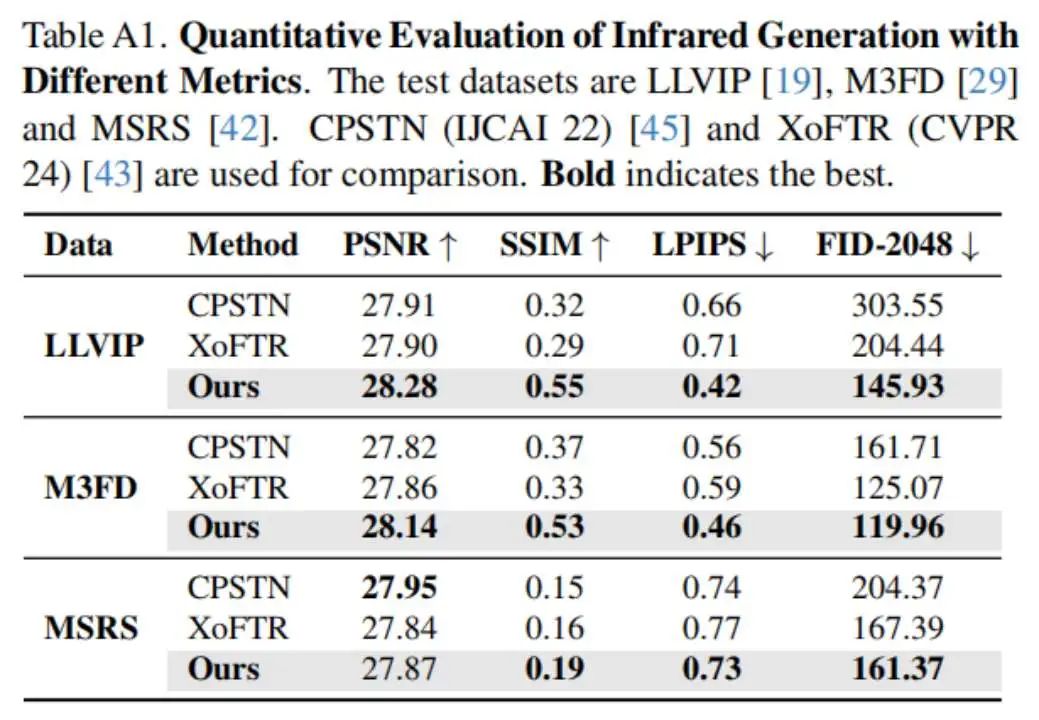
红外图像生成结果

总结
MINIMA框架通过数据生成技术和高效的模型优化策略,成功填补了通用跨模态图像匹配领域的数据与模型空白。所构建的MD-syn数据集和统一匹配框架不仅显著提升了匹配性能,还大幅降低了研究成本。MINIMA为多模态感知相关应用提供了强有力的支持,具有广阔的研究与应用前景。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









