







这里的总结一下:
- 1.解决什么总体问题:解决三维空间中的目标识别,最终结果是用一个小盒子也就是bounding box把这个东西框起来。
- 2.解决什么痛点 :1.原有的方案中忽略了三维最原始的特性。2.在大的空间当中,小的常常被忽略。3.遮挡的问题。 4.点稀疏的问题。
- 3.怎么解决:1.直接使用点云数据,减少手工处理的影响,2.不是严格的使用3D或是2D的方案,是在3D的框架下,结合2D的出色经验。
1.研究提出的背景和原因
- 1.在二维空间分类问题和语义分割问题都取得了很好的进展,与此同时,在三维空间的信息的处理却并不理想。虽然不理想,但是三维信息的处理却自动驾驶等众多领域的重要需求。
- 2.另外,我们本身就是生活在一个三维的空间当中,所以三维的应用更加贴近我们的生活以后的应用还将逐渐变多,再加上,三维空间可以保留物体最原始的拓扑结构,这个是我们需要的,就算是之前已经研究的非常到位的二维信息处理,也是从三维空间采集得来,采集的结果肯定是不如原有的数据的,所以三维数据的处理十分重要,作者准备自己研究一下,三维空间的处理问题。
- 3.在二维空间中相互距离很近的物体,可能恰恰是整个图片中相互距离最远的两个物体,可以看到三维数据可以更加有效的利用信息。
- 4.参考了之前的研究内容,觉得传统的处理方法会丢失很多信息(这里是直接引用PointNet的论断)。之后发现PointNet只是研究了分类和语义识别,对象识别还没有研究,至此研究方向就确定了。
至此研究方向就确定了–研究三维空间的目标分割问题。
分析问题:
三维空间的内容大家研究的很少,所以需要参考二维空间的成功经验,看了一下,如果使用二维空间的类似方案滑动窗口或3D区域建议网络是比较简单,但是会引起很大的问题。那就是计算量会很大,导致不能效果很好地完成计算。
理解一下,我之前的研究方向有点偏向语义分割,所以对对象检测的了解有限,这两种方法其实不收所以这里可能理解错误。我理解这里两种方式都有点偏向遍历的方式,你在二维空间的计算量为x的平方的话,你迁移到三维空间就会变成x的立方,这个计算量的扩张是十分恐怖的,所以本文作者没有选择这种方式。
在三维到二维转化的问题中的考量:
1.三维卷积的计算代价太大,所以要转化为二维的进行处理,但是之前也说过了,如果是转化为二维空间处理会丢失一些特征,所以,不能真正的转化到二维空间处理。而是要从二维获得一定信息再回到三维。
2.所以本文采用用二维图像缩小范围,之后去三维空间做精细化处理。
2.实际的实现
这个任务其实可以分成两个任务:一个是region proposals、一个是classification。
region proposals
其实关键难点其实是搞清楚下面的四张图的内容:
1.对应a的获得
2.对应从a到b
3.对应从b到c
4.对应从c到d
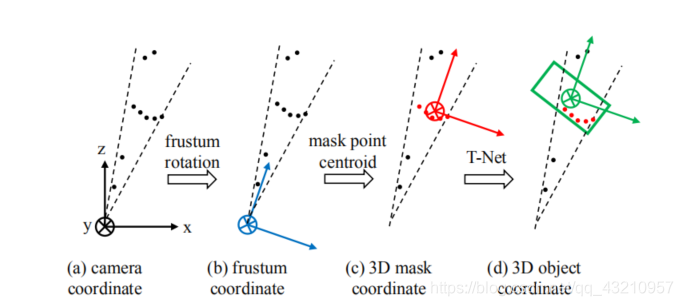
1.取出来这个锥体
概述:最早是使用二维的物体和点云相结合的问题,就是在二维找出来,之后去三维切下来,之后PointNet识别就好做了。有了二维的位置,之后去三维割下来继续识别。之后去3D extruded 下来。之后,要切成一个锥,因为我们这个视角是逐渐扩大的,所以实际上切下来是个锥形。
详细过程
- 1.想要进行目标检测和识别,最关键的问题就是先缩小范围,既然是一个缩小范围的过程,其实没必要做的特别准确,只要效率够好就行,所以本文作者选择在二维图像当中先检测到这个东西。
(这里的主要考量因素是:二维图像的分辨率较好、二维图像的分割算法较成熟) - 2.我们在二维图像当中取出来这个东西之后,最关键的是我们怎么在三维点云当中选择出对应的那部分点,只需要依据视角,将选取出来的那个图片部分进行扩大就行了,所以就产生了文章中反复提的 frustum point clouds。
- 3.这时候就产生了一个新的问题:二维的目标检测一定要准确(毕竟之后的推算的基于二维的目标检测)
为了提升二维空间的目标检测的准确度作者首先使用通用的目标检测数据集进行预训练(ImageNet classification COCO object detection datasets),之后再用和领域结合的数据集(a KITTI 2D object detection dataset)进行微调。
2.锥体进行标准化的问题
接下来就是标准化的问题。这个锥体的方向是五花八门的,所以需要对其进行归一化。我觉得理解标准化,需要从两个角度开始理解:
1.能不能提升计算的性能
2.能不能提升识别的效果
2.1提升计算的效率的角度
计算的快慢,显然是大家的形式越相似,计算速度更快。所以从计算速度来看,我们需要将形式转化为完全一样的情况。考虑到这里是个锥体,也就是方向都是标准方向,大小都是一样大的。
2.2提升识别准确性的
上面确定了只有两个需要考虑的角度,下面我们就直接评估这两个角度就行了:
1.都转化成标准角度这很好,因为这样可以增加平移不变形,因为平移最后改变的其实就仅仅是一个视角的问题。
2.转化成固定的大小这就并不好,因为我们最后要用到这个大小的,如果这里进行仿射,虽然最后也能恢复。但是这个过程在点云当中节省的计算量有限,却还需要变回来评估大小(需要知道盒子的大小)
2.3到底怎么做?
文章提出来的锥体既然已经成为了一个独立的点的集合,那么我们对其进行适当地坐标系变换不就可以了吗,所以就使用了坐标系变化,使得每个锥体都朝向一个相同的方向。(这里旋转不需要使用网络,直接变换成正的就可以了,因为这个东西有明确的方向性,也就是视角固定)
3.在这个锥体里面缩小范围
这里已经确定了这个东西就在这个范围当中,接下来要做的就是怎么在这个范围当中继续缩小范围的问题。
3.1继续利用二维空间中得到的分类信息
我们在二维空间完成的是一个object detect,这个其实是包括两个结果一个是分割的结果、一个是识别的结果。我们上面利用的信息只有一个也就是分割的结果,所以思考怎么利用分类结果接成为了一个需要考虑的因素。
所以本文作者就将分类信息做成一个one-hot-vector输入到到缩小范围的过程中,这样可以更好地辅助识别。
这个其实很好理解,本身是一个mutil_class object detection,经过这么一处理,直接就变成了一个单独类别的目标检测了。找某种确定的东西显然比找东西要有容易一些,显然这样也能让网络更加有针对性。
或者描述成:我们输入是一个圆锥区域,就算我们进行适当地缩小,也可能在我们最终的范围中还有两个物体,所以输入一个类别就很容易解决这个问题了。能够将这个东西分出来。
3.2那么这又对缩小范围有什么作用
- 1.因为我们想要真正的完成画bounding box,其实需要我们完成对原有视图的语义分割,如果有好多类别显然有挑战,但是我们这里输入这里物体的类别之后,就变成只有只有两类标签的语义分割。
- 2.我们接下来对其进行语义分割就顺利了很多。
3.3总结
总结起来,这里其实是使用PointNet的语义分割缩小原来的大范围,生成一个更小的范围,以及一个中心,因为已经产生了物体的中心了,这里就需要进行新的坐标系转化。 也就变出来了图c。
4.T-net修正
研究做到第三步其实以及差不多,但是还是有一定的偏差,
为什么还有偏差?因为我们获得的点云来自于雷达,所以我们获得的点都是在迎面的表层,获得的中心也是表层的中心,但是我们需要的是内部的中心,所以还有一定的偏差。
所以使用这个训练了一个T-Net进行修正。
这里一定要理解一个问题这个T-Net和之前的空间旋转不同,这里是为了完成中心点的修正。
classification
直接使用的是图像识别过程中的结果。
Multi-task Losses
提出的原因
和传统的网络比起来这个网络同样也是一个流程走下来的,也是最终得到一个结果。但是不同的在于标签的情况,传统的网络只有最后的一个标签,而这里中间有很多步骤的结果是有标签的。所以这个和我们传统的监督学习不一样了。需要一个新的损失函数。
具体是什么
我理解文章中的这个函数实际上就是给各个损失一个权重,并且训练过程中应当权重可以调整。
















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











