








一、论文信息
论文题目:MedMamba: Vision Mamba for Medical Image Classification
中文题目:MedMamba: 用于医学图像分类的视觉Mamba
论文链接:https://arxiv.org/pdf/2403.03849
官方github:https://github.com/YubiaoYue/MedMamba
所属机构:广州医科大学生物医学工程学院,广东技术师范大学数学与系统科学学院
核心速览:本文介绍了一种名为MedMamba的新型医学图像分类模型,该模型结合了经典卷积层和状态空间模型(SSM)来有效提取医学图像的局部和全局特征,旨在解决传统卷积神经网络(CNN)和视觉变换器(ViT)在处理医学图像时的局限性。
二、论文概要

图3:具有不同成像方式的16种不同数据集的典型样本。
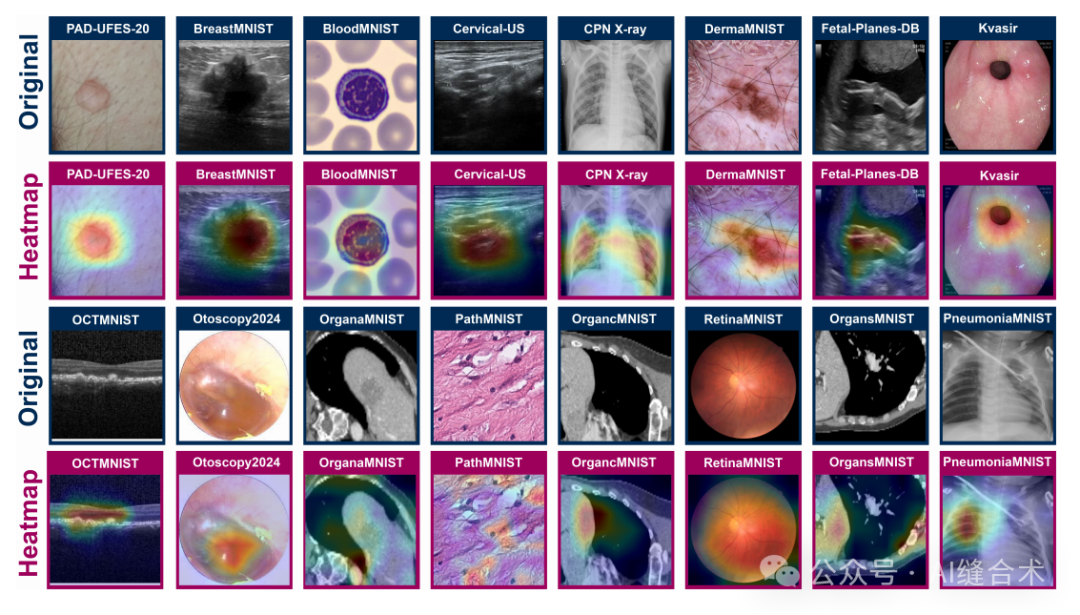
图5:使用Grad-CAM在16个数据集上对MedMamba-S进行视觉热图分析。
1. 研究背景:
-
研究问题:医学图像分类是医疗图像分析的基础步骤,对于计算机辅助诊断(CAD)至关重要。然而,随着医学影像技术的发展,大量不同成像模态的医学图像涌现,手动分类和解释变得非常耗时和劳动密集。此外,不同临床医生在分析和解释医学图像时的方法和结论存在显著差异,这依赖于他们的专业知识和经验。因此,如何利用人工智能技术提高医学图像分类的准确性和效率,成为CAD和计算机视觉领域的一个基本且重要的任务。
-
研究难点:尽管CNN和ViT在视觉表征学习领域占据主导地位,但CNN在捕捉全局上下文和长距离依赖方面存在局限性,而ViT虽然能有效捕捉长距离依赖,但其自注意力机制的二次计算复杂度导致在实际应用中难以部署,特别是在计算资源有限的临床环境中。此外,现有的CNN、ViT和CNN-ViT混合架构在处理高分辨率医学图像时仍面临计算负担重的问题。
-
文献综述:近年来,随着深度学习技术的发展,CNN和ViT在医学图像分类任务中得到了广泛研究和应用。然而,CNN在建模长距离依赖方面存在局限性,而ViT的自注意力机制计算复杂度高,限制了其在实际应用中的部署。最近的研究表明,状态空间模型(SSM)能够有效建模长距离依赖,同时保持线性计算复杂度。受此启发,本文提出了MedMamba,这是第一个用于通用医学图像分类的Vision Mamba。
2. 本文贡献:
-
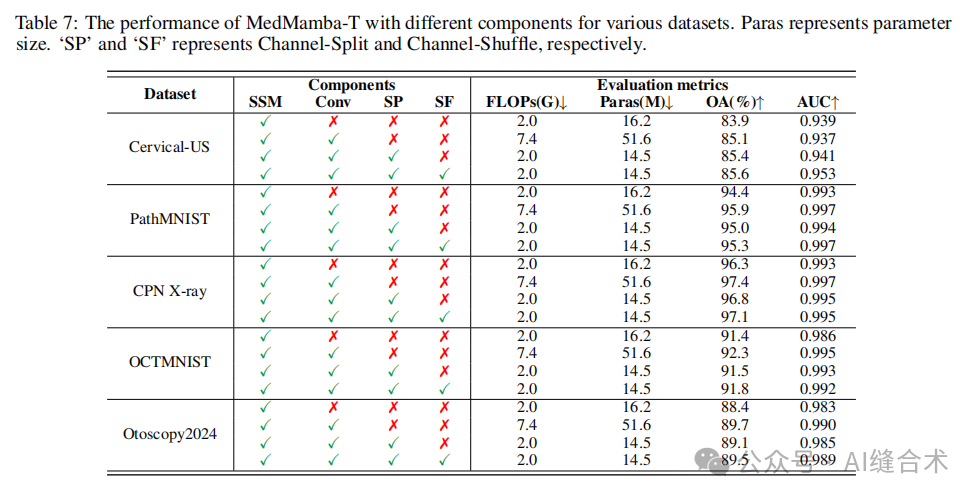
提出MedMamba架构:MedMamba是一种结合了经典卷积层和状态空间模型(SSM)的新型混合基础块SS-Conv-SSM,旨在有效提取医疗图像的局部和全局特征。该架构通过引入分组卷积策略和通道洗牌操作,实现了在保持高准确率的同时减少模型参数和计算负担。
-
2D-选择性扫描机制(SS2D):SS2D是MedMamba的核心元素之一,它通过引入交叉扫描模块(CSM)来解决视觉数据中的“方向敏感”问题,确保每个像素点能够整合来自不同方向的信息,从而获得全局感受野。
-
SS-Conv-SSM:SS-Conv-SSM块是一个轻量级的双分支卷积块,它将特征图分割成两组,分别通过Conv-Branch和SSM-Branch提取全局和局部信息。最后,通过通道连接和通道洗牌恢复通道维度的大小,避免了分组卷积操作导致的信息丢失。(本文介绍重点)
三、创新方法
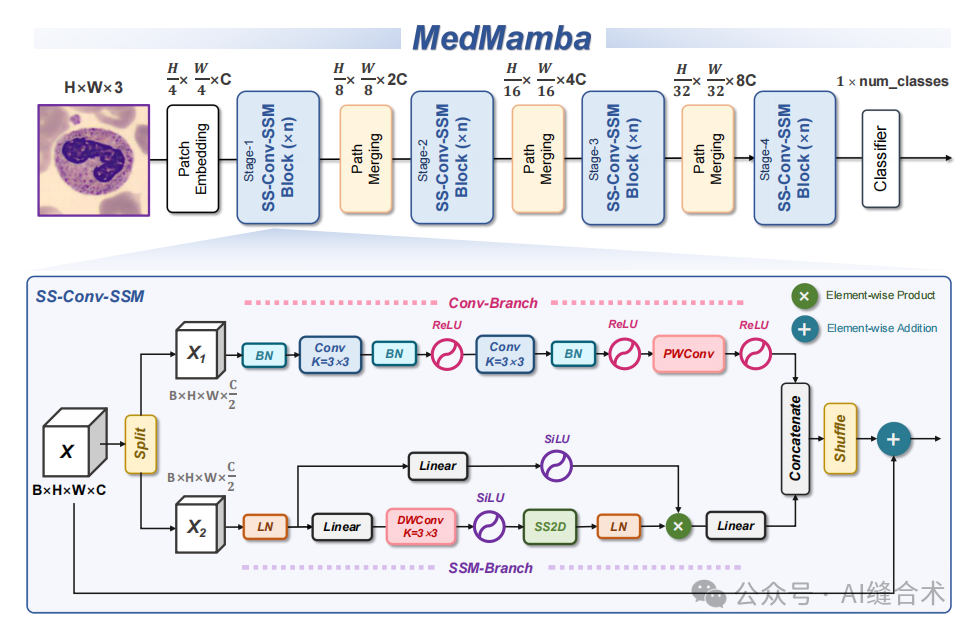
图1:MedMamba的整体架构。BN、LN、Linear、PWConv和DWConv分别代表批量归一化、层归一化、线性层、点卷积和深度可分离卷积。
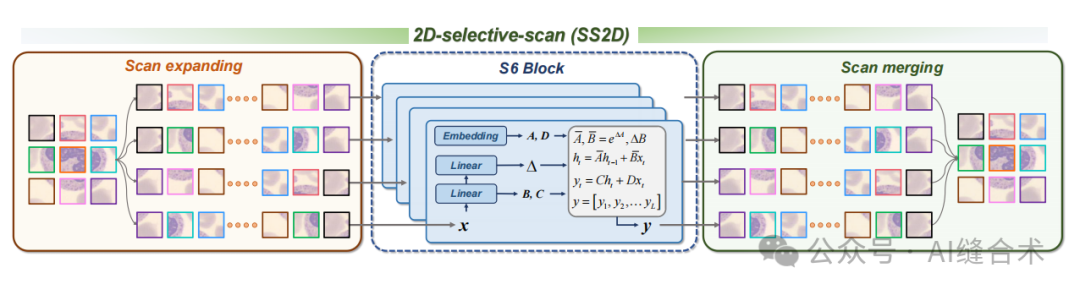
图2:SS2D内部建模过程的视觉展示。
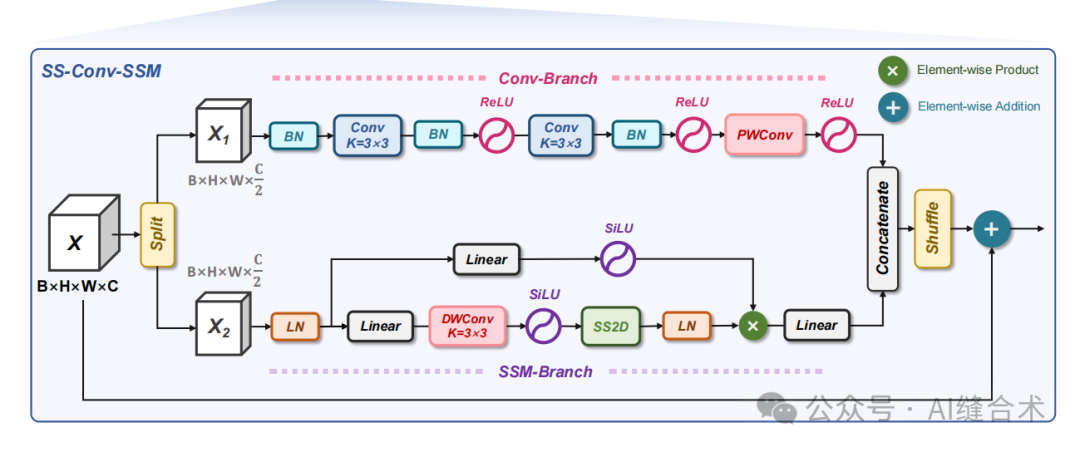
SS-Conv-SSM 是MedMamba模型中的一个主要组件,它通过以下步骤实现对特征图的处理:
1. 通道分割(Channel-Split):首先,SS-Conv-SSM Block将输入的特征图分割成两个组。这一步骤将特征图分为两个部分,以便分别处理。
2. 卷积分支(Conv-Branch):对其中一个组使用卷积操作。卷积分支包括一系列的卷积层和激活函数,具体操作如下:使用BatchNorm对特征图进行归一化,通过Conv3×3卷积层进行特征提取,使用BatchNorm对特征图进行归一化,应用ReLU激活函数,通过Conv3×3卷积层进行特征提取,再次使用BatchNorm对特征图进行归一化,再次使用ReLU激活函数。最后,通过PWConv(逐点卷积)进行最终的特征转换,随后使用ReLU激活函数。
3. SSM分支(SSM-Branch):对另一个组使用SSM分支进行处理。SSM分支的操作包括:使用LayerNorm进行层归一化,上分支应用Linear层进行特征转换,SiLU激活函数,下分支应用Linear层和DWConv(深度可分离卷积)进行特征转换,SiLU激活函数,SS2D模块进行特征提取,再次使用LayerNorm进行层归一化,与上分支点乘获取空间注意力,通过Linear层将两个分支的输出结果进行融合。
4. 通道拼接(Channel-Concatenation):将两个分支处理后的特征图进行通道拼接,以恢复通道维度的大小。
5. 通道洗牌(Channel-Shuffle):为了防止分组卷积操作导致通道间信息丢失,使用通道洗牌操作对特征图进行处理。
6. 输出:最终,SS-Conv-SSM Block的输出是通过将通道分割后的两个分支的输出进行通道拼接和通道洗牌后得到的特征图。
整个SS-Conv-SSM Block的设计旨在通过分组卷积和SSM层提取图像的局部和全局特征,同时通过通道洗牌避免信息损失,实现高效且准确的特征提取。
四、实验分析
1. 数据集:研究使用了16个医疗图像数据集,包括10种不同的成像模态和411,007张图像,以全面评估MedMamba在医疗图像分类任务中的有效性和潜力。
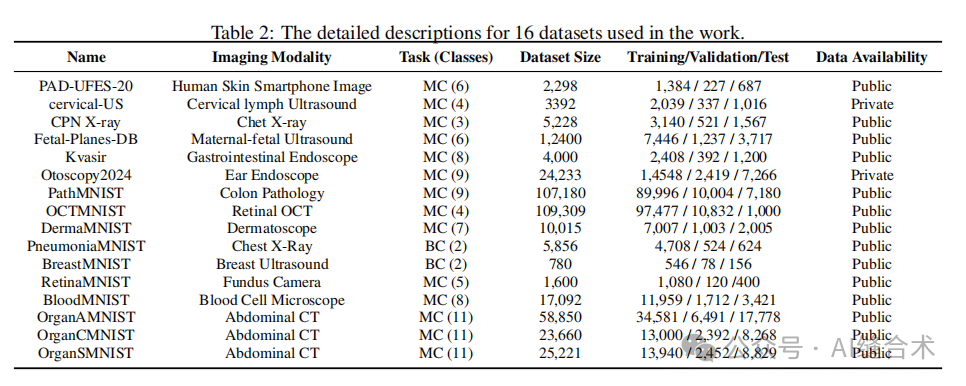
2. 实验细节:为了公平比较,所有图像被调整为224×224×3的大小,并进行了标准化处理。在训练过程中,使用了AdamW优化器和交叉熵损失函数,每个模型训练150个周期,采用早停策略防止过拟合。
3. 评估指标:报告了总体准确率、精确度、灵敏度、特异性、F1分数和ROC曲线下面积(AUC)作为标准评估指标。此外,还分析了模型的计算复杂度(FLOPs)和模型参数大小。
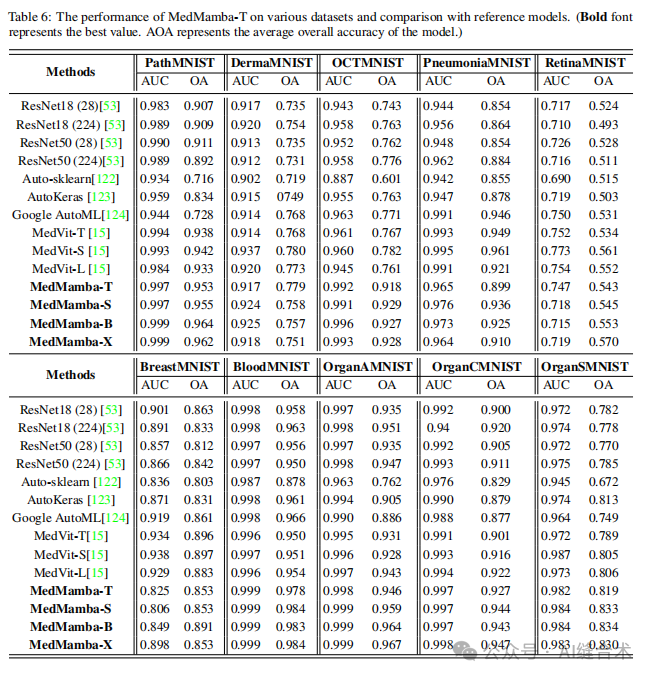
4. 实验结果:MedMamba在16个数据集上的表现与最先进的方法相比具有竞争力,尤其在处理不同成像模态和数据规模的医疗图像数据集时。MedMamba的变体在参数大小、FLOPs和总体准确率之间取得了良好的平衡。
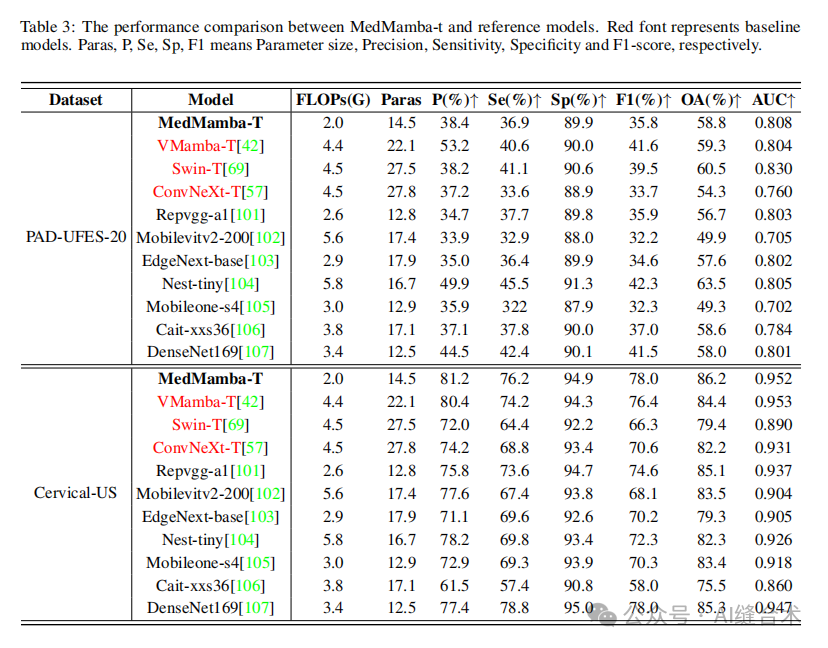
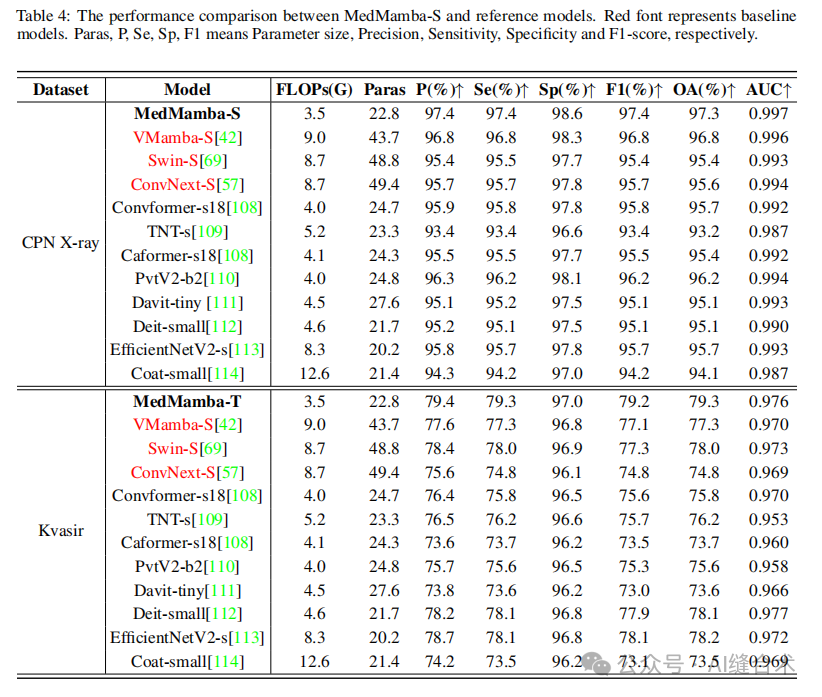
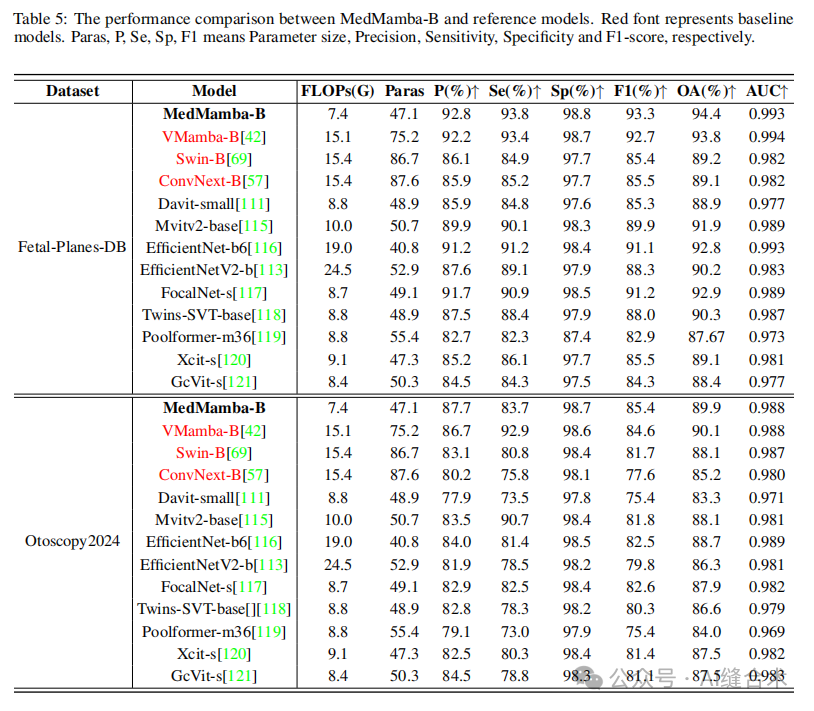
五、代码
https://github.com/AIFengheshu/Plug-play-modules
2025年全网最全即插即用模块,全部免费!包含人工智能全领域(机器学习、深度学习等),适用于图像分类、目标检测、实例分割、语义分割、单目标跟踪(SOT)、多目标跟踪(MOT)、RGBT、图像去噪、去雨、去雾、去模糊、超分等计算机视觉(CV)和图像处理任务,以及其他各类人工智能相关任务。持续更新中......


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











