







A*算法及其变种
本文详细介绍A*算法及其经典变种算法.
A*算法
这个网站https://www.redblobgames.com/pathfinding/a-star/introduction.html 以图解形式详细介绍了 A* 算法的原理和运行过程,还介绍了 A* 算法是如何从Dijkstra和BFS(Breadth First Search)发展而来的,十分推荐阅读原文.
本文的 A* 算法部分主要翻译总结自上述网站,并加上笔者的一些思考和总结.
学习知识,有一个由浅入深的过程.研究图搜索算法,离不开深度优先搜索 (Depth First Search, DFS) 和广度优先搜索 (Breadth First Search, BFS), 大部分算法都是由最基础的算法演变而来的.A* 算法的基石,就是广度优先搜索 (BFS).
本部分将从 BFS 开始介绍,看看算法是如何一步步进化到 A* 的.
广度优先搜索(BFS)
广度优先搜索,是算法里老生长谈的话题了.无论是在数据结构面试题还是科研中,都具有举足轻重的地位.

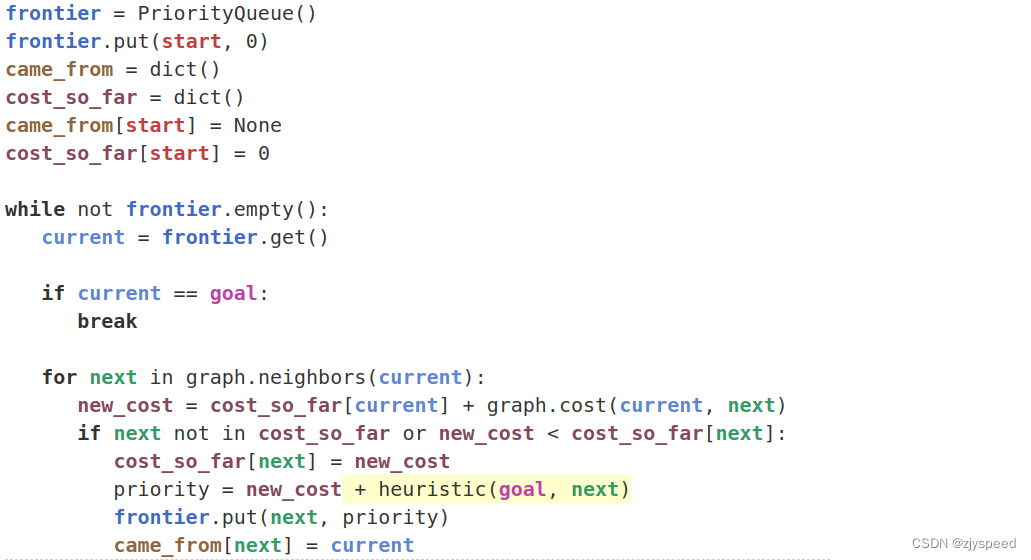
所谓广度优先,也就是优先搜索距源点距离较近的点,如上图所示,广度优先的视觉效果为以源点为中心的扩散搜索.代码如下:
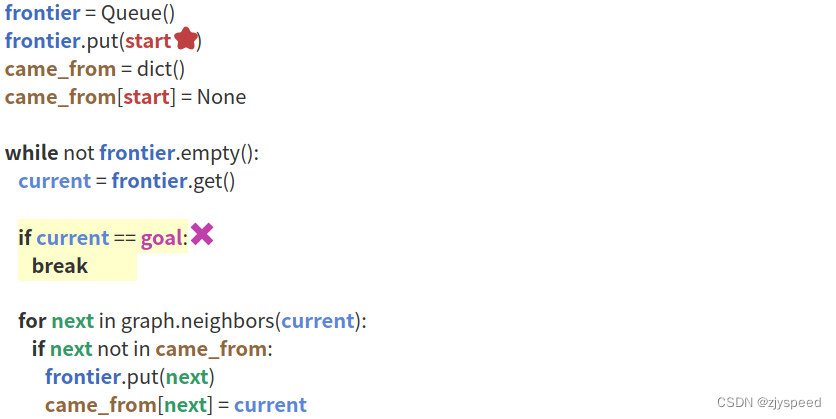
- frontier 表示当前的搜索边界,也可以理解为用于下一步搜索的备用节点集合(如 gif 中的蓝色方格),在编程中通常用优先级队列来表示
- came_from 记载了从起点到当前点的途径信息,回溯 came_from, 可以得到从起点到当前点的路径
- while 循环非常重要,这个循环框架是整个 A* 部分图搜索算法的核心部分,大致分为如下几步
- 按照既定规则,在当前的搜索边界 frontier 中选取一个方格 current 作为下一步的搜索点(这个既定规则,就是区分 BFS, Dijkstra, A* …等等算法的关键所在),在 BFS 中的规则是广度优先,而 frontier 边界中的点本来就是按遍历顺序排列的,直接选取队列首元素. 为了扩展方便,我们把这个既定规则,数学化表示成代价函数 f ( n ) f(n) f(n),算法每次都会选取队列中 f ( n ) f(n) f(n) 最小的进行下一步扩展,广度优先搜索的代价函数 f ( n ) f(n) f(n) 其实就是节点加入队列的顺序,那么就不需要进行优先级比较了,队列本来就是先入先出的.
- 扩展 current ,得到 current 的相邻节点集合 neighbors, 放入备用节点集合 frontier
Dijkstra
算法的研究,最终是要为应用服务的.在广度优先算法中,我们以当前点距起点的距离作为遍历的优先级.这样的遍历顺序在普通场景下尚可,但在某些复杂场景下却显得力不从心,例如过桥和过河,对我们来说同样的距离,过桥显然轻松的多.为此,算法将引入代价 cost 作为新的代价函数 f ( n ) = c o s t f(n) = cost f(n)=cost:
- 定义 cost: 从当前点 current 到起点的路径所需要的代价 (根据 cost 定义的不同,又可以诞生其他的算法,比如下文将要介绍到的 Greedy Best First Search 和 A*)
- 每次选取代价最小的节点优先遍历

代码如下:
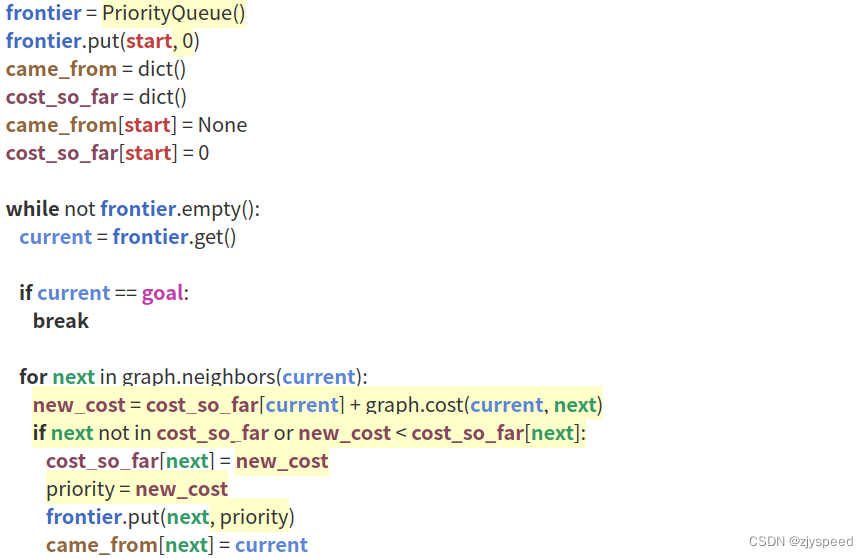
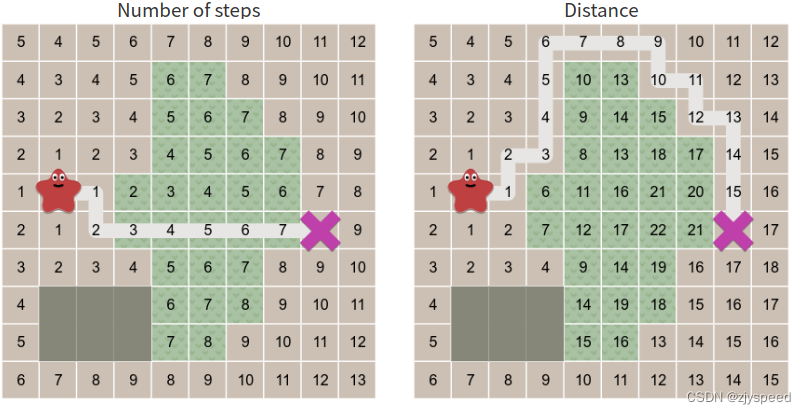
相比于 BFS,Dijkstra 算法新增了 cost_so_far 用于记录从当前点 current 到起点的路径所需要的代价,并将搜索规则改为优先搜索 cost 最小的点.如下图所示,,Dijkstra 算法会绕过中央难走的草地.
最佳优先搜索 Greedy Best First Search
在 BFS 和 Dijkstra 算法中,算法从起点开始向所有方向扩散遍历,直到最外层的扩散圈覆盖目标点. 这样的搜索会同时计算出从起点到包括目标点在内的的大量点的最优路径. 我们不禁思考这样的搜索有没有必要.
举个例子,我们想去直线距离 10km 外的商场,需要找到最近的道路,我们难道会绕着起点一圈一圈扩大搜索直到找到商场吗?这种搜索方法显然是有悖常理的,正常人的做法是沿着朝向商场的方向搜索,如果路走不通,才有可能往反方向走来绕过障碍.
这样沿着目标点方向的搜索,叫做启发式搜索 (Heuristic search),事实上,一切利用到目标点信息的搜索,都叫启发式搜索. 启发式搜索算法中,都有一个启发式函数 (Heuristic function),最简单的启发式函数就是当前搜索点 current 到目标点的距离:

前文提到,while 循环框架贯穿 A* 类搜索算法的始终,不一样的只是确定下一个搜索点的既定规则, 也叫代价函数,也就是优先级队列的比较规则,回顾一下:
- BFS 的规则: 顺序优先 f ( n ) = f(n) = f(n)= 加入队列的顺序(广度优先)
- Dijkstra 的规则: 到起点的距离优先: f ( n ) = c o s t _ s o _ f a r f(n) = cost\_so\_far f(n)=cost_so_far
可以看到,相比于启发式搜索,BFS 和 Dijkstra 没有方向性,相应的,这类搜索通常也称为盲目搜索.
在最佳优先搜索 (Greedy Best First Search) 中, while 循环框架中确定下一个搜索点的代价函数修改为启发函数: f ( n ) = h e u r i s t i c ( n , g o a l ) f(n) = heuristic(n, goal) f(n)=heuristic(n,goal)
如果使用当前搜索点 current 到目标点的距离(这里的距离是曼哈顿距离)为启发函数,则最佳优先搜索的优先级队列比较规则为到目标点的距离优先,代码如下:
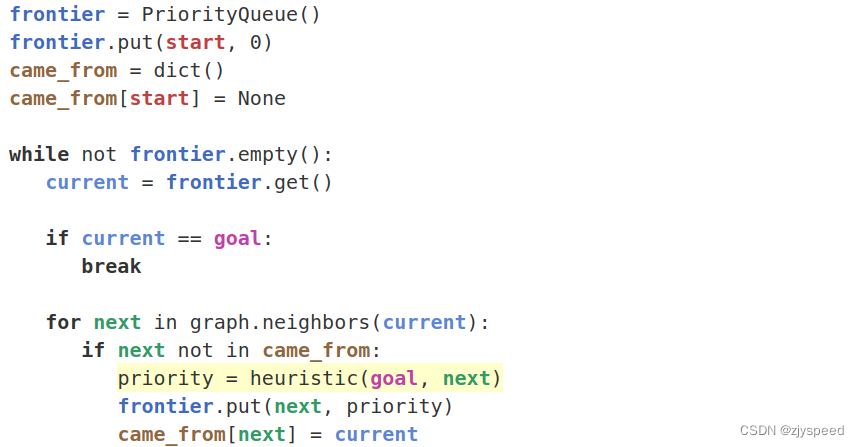
相比于 Dijkstra,最佳优先搜索直接朝着目标点方向行进:

当然,现实的情况没有这么理想,每一条路不可能都是坦途,如果有障碍物怎么办呢:

可以看到,最佳优先搜索仍然朝着目标点方向搜索,搜索空间虽然比 Dijkstra 小,但是走了弯路,也就是虽然搜索快,但是找到的路径不是最短路径.
那有没有方法,帮助我们找到又快又短的路径呢?
A*
受 Dijkstra 和 GBFS(Greedy Best First Search) 的启发,A* 决定博采众长.
- Dijkstra: 到起点的距离优先 : f ( n ) = c o s t _ s o _ f a r f(n) = cost\_so\_far f(n)=cost_so_far
- Greedy Best First Search:到目标点的距离优先 : f ( n ) = h e u r i s t i c ( n , g o a l ) f(n) = heuristic(n, goal) f(n)=heuristic(n,goal)
- A* : 到起点和目标点的距离之和优先: f ( n ) = c o s t _ s o _ f a r + h e u r i s t i c ( n , g o a l ) f(n) = cost\_so\_far + heuristic(n, goal) f(n)=cost_so_far+heuristic(n,goal)
代码如下:
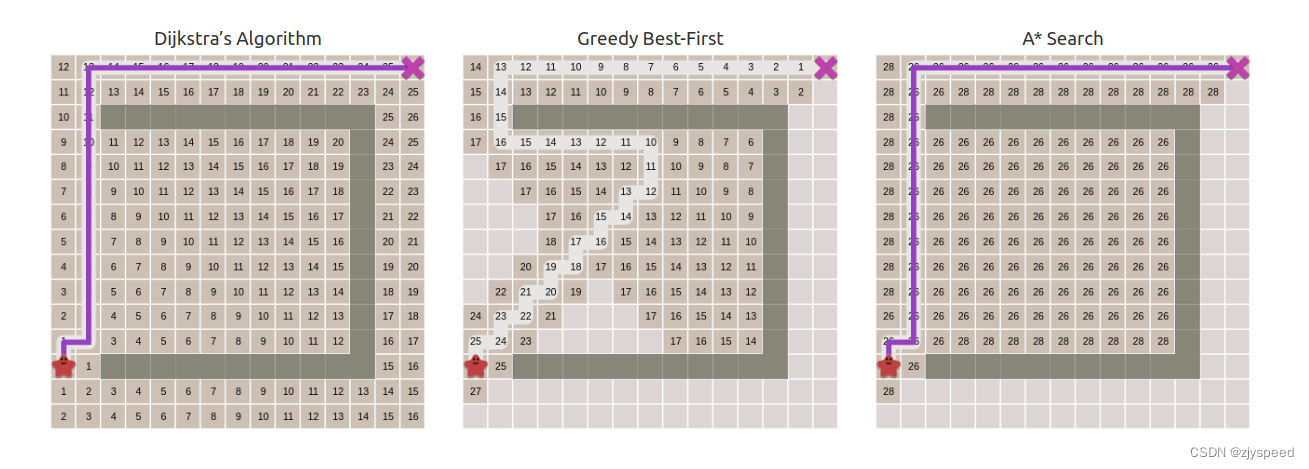
可以看到,博采众长之后,在上述地图,与 Dijkstra 相比, A* 算法能找到最短路径,且搜索空间更小;与 GBFS 相比,A* 算法能找到最短路径,但搜索空间更大.
到这里,就不得不提到算法最优性、完备性和效率之间的折衷了.
- 最优性: 指规划得到的路径在某个评价指标上是最优的,例如经常使用的路径长度指标,最短路径即是最优路径. 在上述算法中,Dijkstra 是最优的, 对A* 算法来说,只要启发函数没有低估到目标点的距离(称为启发函数的一致性(admissible)),A* 算法也是最优的.
- 完备性:如果在起点和目标点之间有解存在,算法一定能找到解. 在上述算法中,BFS、Dijkstra、A* 都是完备的,在有限状态空间图搜索中,最佳优先搜索 GBFS 也是完备的.
算法的效率取决于算法的平均搜索空间,用算法术语来说叫时间复杂度. 这里就不展开介绍了,上面的几个 gif 展示的搜索过程,可以直观的看到各个算法的搜索空间. 完备性、最优性与算法效率往往是矛盾的. 完备、最优注定了精益求精,更快的算法通常是次优的. 没有最好的算法,只有最适合的算法.
以下介绍的 A* 变种算法的提出,大都由于最优性、完备性和效率之间的折衷。限于篇幅和博主能力,A* 变种算法只简要的概括思想,具体内容可以阅读每个算法给出的参考文献。
为了便于下文介绍,我们需要对 A* 算法的术语描述进行一些修改:
-
上文提到,A* 算法的代价函数为: f ( n ) = c o s t _ s o _ f a r + h e u r i s t i c ( n , g o a l ) f(n) = cost\_so\_far + heuristic(n, goal) f(n)=cost_so_far+heuristic(n,goal) .
在这里需要简化一下A* 算法的代价函数的表示方法,这也是大部分文献中所采用的:
f ( n ) = g ( n ) + h ( n ) f(n) = g(n) + h(n) f(n)=g(n)+h(n)
其中, g ( n ) g(n) g(n) 代表着当前点 n n n 到起点的距离,也就是上文的 c o s t _ s o _ f a r cost\_so\_far cost_so_far, h ( n ) h(n) h(n) 代表着启发函数 h e u r i s t i c heuristic heuristic. 这里插一句题外话,规定 h h h 是因为 h h h 是 h e u r i s t i c heuristic heuristic 的首字母,那么 g g g 代表着什么?答案是没有什么,因为 A* 算法提出者在文章里就是这么规定的… -
上文提到,frontier 表示当前的搜索边界,也即为用于下一步搜索的备用节点集合,在一般的编程框架里,frontier 通常被称为 o p e n l i s t open \space list open list,一般翻译过来叫 O p e n Open Open 表. 相应于 o p e n l i s t open \space list open list,还有一个 c l o s e d l i s t closed \space list closed list,每次从 o p e n l i s t open \space list open list 中取出的优先级最高的节点 c u r r e n t current current 都会被放入 c l o s e d l i s t closed \space list closed list 中,表示该节点已经被探索过.
这里推荐一个非常好的网站,里面包括了很多图搜索算法和采样搜索算法的可视化搜索过程和编程实现: https://github.com/zhm-real/PathPlanning,下文的 gif 示例大部分取自该网站.
Bidirectional A*(双向A*)
双向 A* 算法维护两套 A* ,最精髓的思想在于从起点和终点分别、同时向对方搜索,但是双向搜索过程中的处理逻辑有很多需要考虑的地方:例如是轮流搜索还是优先搜索起点开始的 A*?
一种可能的搜索过程如下:
- 设从起点出发的 A* 为 A s t a r t ∗ A^*_{start} Astart∗,搜索过程维护的备用节点列表为 o p e n l i s t s t a r t open \space list_{start} open liststart;设从终点出发的 A* 为 A g o a l ∗ A^*_{goal} Agoal∗,搜索过程维护的备用节点列表为 o p e n l i s t g o a l open \space list_{goal} open listgoal
- 与原始的 A* 不同的是,双向 A* 中的每一个 A* 的终点是不断变化的,也就是 h e u r i s t i c ( n , g o a l ) heuristic(n, goal) heuristic(n,goal) 中的 g o a l goal goal 。具体来说,在每一次扩展下一步节点的过程中,A* 算法的 g o a l goal goal 始终是最原始的目标节点 g o a l goal goal ;但在双向 A* 中, A s t a r t ∗ A^*_{start} Astart∗ 以 o p e n l i s t g o a l open \space list_{goal} open listgoal 中优先级最小的节点来计算启发函数 h h h,而 A g o a l ∗ A^*_{goal} Agoal∗ 以 o p e n l i s t s t a r t open \space list_{start} open liststart 中优先级最小的节点来计算启发函数 h h h,两套 A* 按时间步轮流搜索。 一旦 A s t a r t ∗ A^*_{start} Astart∗ 或者 A g o a l ∗ A^*_{goal} Agoal∗ 找到了终点,说明两个算法相遇。

次优算法
Weighted A* (WA*)
回顾一下经典算法的代价函数:
A*:
f
(
n
)
=
g
(
n
)
+
h
(
n
)
f(n) = g(n) + h(n)
f(n)=g(n)+h(n)
Dijkstra:
f
(
n
)
=
g
(
n
)
f(n) = g(n)
f(n)=g(n)
GBFS:
f
(
n
)
=
h
(
n
)
f(n) = h(n)
f(n)=h(n)
Weighted A* 集思广益,为了满足用户各种情景的需求,设计了一个权重因子 ω \omega ω
f ( n ) = g ( n ) + ω × h ( n ) f(n) = g(n) + \mathbf{\omega} \times h(n) f(n)=g(n)+ω×h(n)
观察上述代价函数,发现:
- ω = 0 \omega = 0 ω=0 时,Weighted A* 退化为 Dijkstra
- ω = 1 \omega = 1 ω=1 时,Weighted A* 退化为 A*
- ω = ∞ \omega = \infty ω=∞ 时,Weighted A* 退化为 GBFS
在有限状态空间图搜索中,上述算法都是完备的,调整参数 ω \omega ω 便是算法最优性与求解速度之间的折衷。
Anytime Repairing A* (ARA*)
参考文献: ARA*: Anytime A* with Provable Bounds on Sub-Optimality
ARA* 做了两件事情:
- 快速找到一条可用的路径
- 用剩余时间对这条路径进行优化
当然,这个逻辑的提出已经不是什么新鲜事情了,ARA* 的精髓在于 用剩余时间对这条路径进行优化 这件事情是如何复用优化前的搜索路径结果、大大降低计算量的。具体可以参考论文。

Focal Search ( A ϵ ∗ A^*_\epsilon Aϵ∗)
参考文献:Studies in Semi-Admissible Heuristics
这篇论文介绍了三种次优算法,这里简要介绍其中最著名的 FOCAL Search,也叫
A
ϵ
∗
A^*_\epsilon
Aϵ∗,这是一种有界次优算法。
什么叫有界次优?设最优代价为 C 0 C_0 C0,给定算法参数 ϵ \epsilon ϵ,有界次优算法保证最后得到的解的代价 C ⩽ ( 1 + ϵ ) C 0 C \leqslant (1 + \epsilon)C_0 C⩽(1+ϵ)C0.
我们知道 A* 算法每次在 O p e n Open Open 表里取 f ( n ) f(n) f(n) 最小的节点进行下一步搜索。论文提到,搜索算法在搜索过程中事实上会得到许多 c o s t cost cost 相近的解,A* 算法每次都取最优比较费时间,多花的时间与得到的优化效果不成比例,俗称 “性价比不高”.
A ϵ ∗ A^*_\epsilon Aϵ∗ 在 A* 算法 O p e n Open Open 表的基础上,设计了一个 F O C A L FOCAL FOCAL 表,定义如下:
F O C A L = { n : f ^ ( n ) ⩽ ( 1 + ϵ ) m i n n ′ ∈ O P E N f ( n ′ ) } FOCAL = \{n: \hat{f}(n) \leqslant (1 + \epsilon)min_{n' \in OPEN} f(n')\} FOCAL={n:f^(n)⩽(1+ϵ)minn′∈OPENf(n′)}
其中, f ^ ( n ) = g ^ ( n ) + h ^ ( n ) \hat{f}(n) = \hat{g}(n) + \hat{h}(n) f^(n)=g^(n)+h^(n) , g ( n ) g(n) g(n) 和 h ( n ) h(n) h(n) 意义与 A* 算法中的一致, g ( n ) g(n) g(n) 代表着当前点 n n n 到起点的距离, h ( n ) h(n) h(n) 代表着启发函数 h e u r i s t i c heuristic heuristic.
也就是把 O p e n Open Open 表里 f ( n ) f(n) f(n) 值 “小于等于 ( 1 + ϵ ) (1 + \epsilon) (1+ϵ) 倍最小 f f f 值” 的所有节点放在一起,单独成立一个 F O C A L FOCAL FOCAL 表,focal 英语意思为焦点,非常形象。
不同于 A* 选最小 f f f 值节点作为下一步扩展节点, A ϵ ∗ A^*_\epsilon Aϵ∗ 将根据规则 h ^ F \hat{h}_F h^F 在 F O C A L FOCAL FOCAL 集合里选合适的节点作为下一步扩展节点,当 h ^ F = h ( n ) \hat{h}_F = h(n) h^F=h(n) 时,也就是根据 F O C A L FOCAL FOCAL 集合中的最小 h h h 值的节点来选择下一步扩展的节点。
论文提到, h ( n ) h(n) h(n) 用于估计 f f f 值,必须是一致的(admissable)启发函数; h ^ F \hat{h}_F h^F 用于在 F O C A L FOCAL FOCAL 集中选择节点,可以是不一致的。
通过设计 F O C A L FOCAL FOCAL 集, A ϵ ∗ A^*_\epsilon Aϵ∗ 避免了 A* 中很多“性价比低”的“精益求精”,使得算法在有界次优的前提下效率更高。
动态搜索
动态搜索(Dynamic search),也叫增量搜索(Incremental search)和长期规划(Lifelong search),可以在环境地图改变时,基于先前路径快速搜索出新的规划路径,而无需从头开始搜索。
Lifelong Planning A* (LPA*)
参考文献: Lifelong Planning A*
论文讲解: 终身规划A* 算法(LPA*):Lifelong Planning A*

Dynamic A* (D*)
参考文献:Optimal and Efficient Path Planning for Partially-Known Environments
论文讲解: D*路径搜索算法原理解析及Python实现

D* Lite
D* Lite 基于 Lifelong Planning A*.
参考文献:D* Lite
论文讲解:D* Lite路径规划算法

结语
限于笔者精力和能力,后半部分没有讲述的算法导向了一些热门讲解文章,大家可以参考。如果英语能力足够,还是建议大家直接看原网站和论文,翻译和表达总会有一些不尽如人意的地方。


















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











