







文章目录
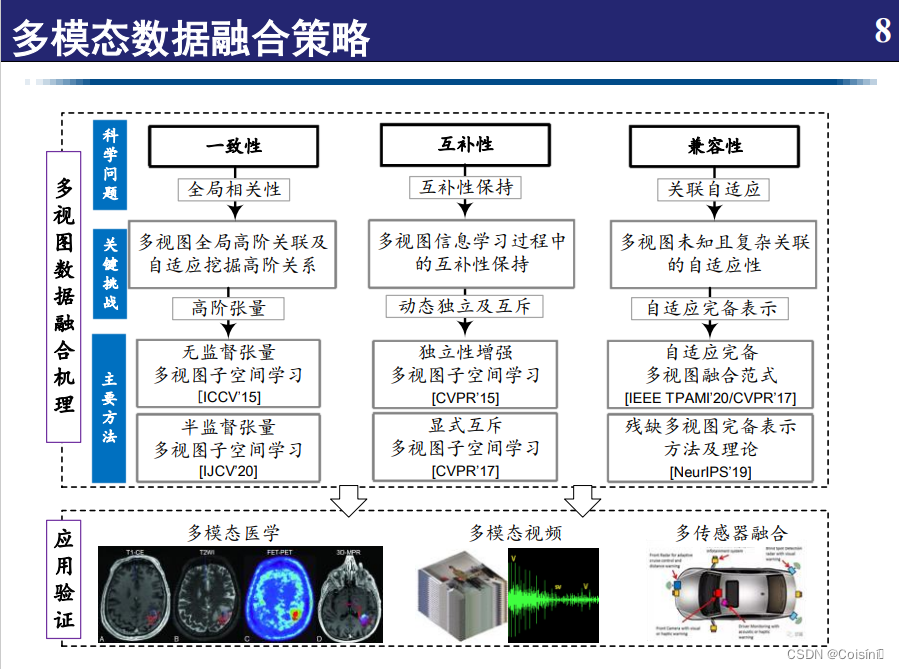
主要是从【互补性】出发,但是由于噪声…[截图源:2020年天津大学张长清副教授讲座]
主要思想
提出一种针对低质量数据的通用的动态多模态融合框架,利用多模态融合得到的泛化误差去动态更新各个单模态预测器, 使得多模态决策倾向于更多地依赖于高质量模态 ,而不是其他模态 。通过动态确定每种模态的融合权重来减轻不可靠模态的影响。(每种模态的backbone为imageNet或ResNet)
Mark(Latex公式):花写字母采用\mathcal书写,艺术字效果采用\mathbb。其他Latex公式可见:Latex公式
相关视频链接
论文思路
定义泛化误差评价多模态融合的性能(是否优于单模态最优值,从理论上确定动态多模态融合和不确定性估计之间的联系)
Abstract
多模态融合的内在挑战是精确地捕获跨模态相关性并灵活地进行跨模态交互。为了充分释放每种模态的价值,减轻低质量多模态数据的影响,动态多模态融合成为一种有前途的学习范式。尽管它被广泛使用,在这一领域的理论依据仍然显着缺乏。我们能设计一个可证明鲁棒的多模态融合方法吗?本文从泛化的角度,在一个最流行的多模态融合框架下,为回答这个问题提供了理论上的理解。我们继续揭示,几个不确定性估计解决方案是自然可实现强大的多模态融合。然后提出了一种新的多模态融合框架质量感知多模态融合(QMF),它可以提高性能的分类精度和模型的鲁棒性。多个基准上的广泛实验结果可以支持我们的发现。
1. Introduction
我们对世界的感知是基于多种模态的,例如,触觉、视觉、听觉、嗅觉和味觉。随着传感技术的发展,我们可以轻松地收集各种形式的数据进行分析。例如,自动驾驶和可穿戴电气设备中的多传感器(Xiao等人,2020; Wen等人,2022),或医学诊断和治疗中的各种检查(Qiu等,2022; Acosta等人,2022年)。直觉上,融合来自不同模态的信息提供了探索跨模态相关性并获得更好性能的可能性。然而,[以往工作的缺陷:]传统的融合方法在很大程度上忽略了不可靠的多模态数据的质量。在现实世界中,不同模态的质量通常会因意外的环境问题而变化。最近的一些研究已经从经验和理论上表明,多模态融合可能会在低质量的多模态数据上失败,例如,不平衡(Wang等人,2020年; Peng等人,2022; Huang等人,2022)、噪声或甚至损坏(Huang等人,2021 b)多模态数据。经验上,认识到多模态模型不能总是优于单模态模型,特别是在高噪声中(Scheunders & De Backer,2007; Eitel等人,2015; Silva等人,2022)或不平衡的模态质量(Wu等人,2022; Peng等人,2022)水平。从理论上讲,以前的研究证明,在有限的数据量设置下,多模态学习的优势可能会消失(Huang et al.,2021 a),这意味着跨模态关系的利用不是免费的午餐。为了充分释放每种模态的价值并减轻低质量多模态数据的影响,[解决方案:]引入动态融合机制是获得可靠预测的一种有前途的方法。作为一个具体的例子,以前的工作(Guan等人,2019)提出了一种动态加权机制来描述场景的光照条件。通过引入动态,他们可以从多光谱数据中整合可靠的线索,用于全天候应用(例如,安全监控和自动驾驶中的行人检测)。动态融合已经用于各种现实世界的多模态应用,包括多模态分类(Han等人,2021; Geng等人,2021; Han等人,2022 b)、回归(Ma等人,2021)、对象检测(Li等人,2022 a; Zhang等人,2019年; Chen等人,2022 b)和语义分割(Tian等人,2020年)。虽然动态多模态融合在实践中表现出了很好的力量,但在这一领域的理论认识显着缺乏以下基本的开放问题:我们能否在实践中实现可靠的多模态融合的理论保证
本文试图阐明鲁棒多模态融合的理论优势和准则。跟随先前的多模态学习理论工作(Huang et al.,2021 b; Wang等人,2020),我们研究的框架也是从决策级多模态融合中抽象出来的,这是多模态学习中最基本的研究课题之一(Baltrušaitis et al.,2018年)。特别是,我们设计了一个新的质量感知多模态融合(QMF)框架多模态学习。我们的框架的关键在于利用基于能量的不确定性来表征每个模态的质量。我们的贡献可归纳如下:
- 本文提供了一个严格的理论框架来理解鲁棒多模态融合的优势和标准,如图2所示。首先,我们从Rademacher复杂度的角度描述了决策级多模态融合方法的泛化误差边界。然后,我们确定在什么条件下动态融合优于静态,即,当多模态融合的融合权值与单模态泛化误差负相关时,动态融合方法的性能优于静态融合方法。
- 在理论分析的基础上,进一步揭示了动态融合的泛化能力与不确定性估计的性能是一致的。这直接暗示了设计和评价新的动态融合算法的原则。
- 直接由上述分析的动机,我们提出了一种新的动态多模态融合方法称为质量感知多模态融合(QMF),它的实现被证明具有更好的泛化能力。如图1所示,对常用基准进行了大量实验,以经验验证理论观察结果。
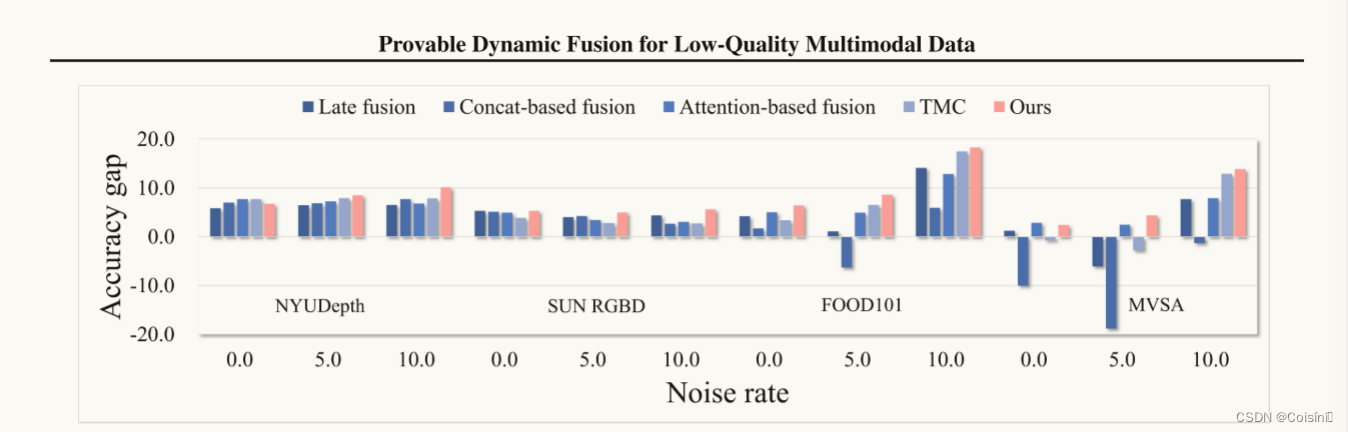
图1.多模态学习方法之间的准确性差距的可视化(例如,后期融合,对齐融合,MMTM)和使用含有噪声的多模态数据的最佳单模态学习方法。注意到,现有的多模态融合方法的性能显着降低相比,他们最好的单模态对应在高噪声制度,而所提出的QMF一贯优于其他对低质量的数据的单模态方法。
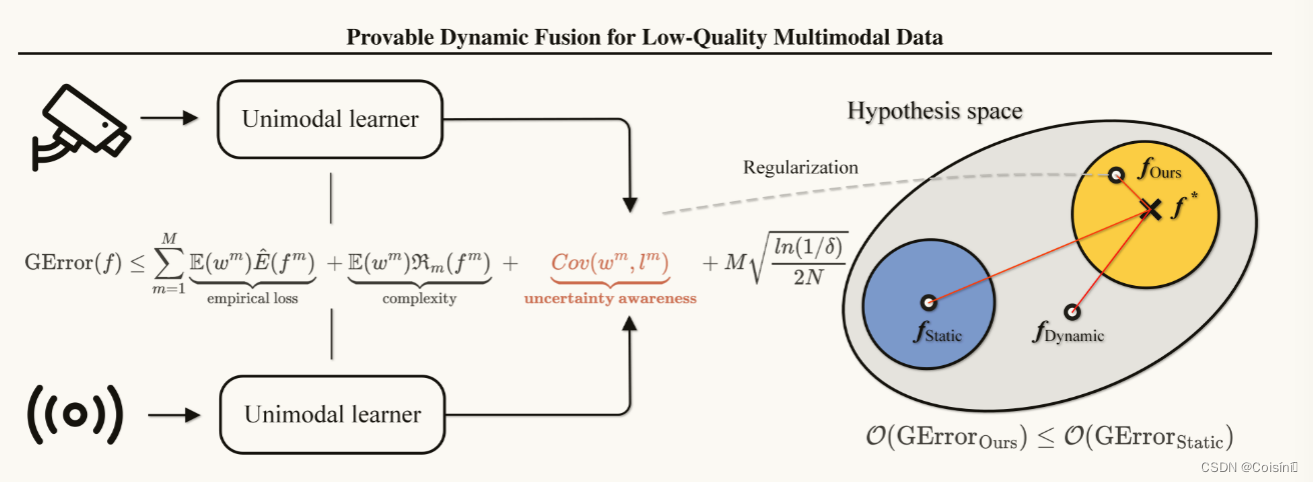
图2.左侧:多模态融合方法f的泛化误差上界可以通过其在经验损失、模型复杂性和不确定性意识方面对每个模态的性能来表征。右:动态与静态多模态融合假设空间,其中后者是前者的子集。
f
s
t
a
t
i
c
f_{static}
fstatic、
f
d
y
n
a
m
i
c
f_{dynamic}
fdynamic分别是静态融合方法和动态融合方法的假设条件,
f
∗
f^*
f∗是真实映射。通俗来讲,更接近真实的映射会导致更少的错误。在某些特定条件下,动态多模态融合方法(例如,所提出的QMF)可以被很好地正则化,从而可证明地实现更好的泛化能力。
2. Related works
2.1. Multimodal Fusion
多模态融合是多模态学习中最原始和最基本的主题之一,其通常旨在将模态特征集成到下游多模态学习任务的联合表示中。多模式融合可分为早期融合、中期融合和晚期融合。虽然神经科学和机器学习的研究表明,中间融合可能有利于表征学习(Schroeder & Foxe,2005; Macaluso,2006),但后期融合仍然是最广泛使用的多模态学习方法,因为它的解释和实用简单。通过引入基于各种策略的模态级动态,动态融合实际上提高了整体性能。作为一个具体的例子,以前的工作(Guan等人,2019)提出了一种动态加权机制来描述场景的光照条件。通过引入动态,他们可以从多光谱数据中整合可靠的线索,用于全天候应用(例如,安全监控和自动驾驶中的行人检测)。结合附加的动态机制(例如,简单的加权策略或DempsterShafer证据理论(Shafer,1976)),最近的基于不确定性的多模态融合方法在各种任务中显示出显著的优点,包括聚类(Geng等人,2021)、分类(Han等人,2021; 2022 b; Tellamekala等人,2022; Subedar等人,2019年; Chen等人,2022 a)、回归(Ma等人,2021)、目标检测(Zhang等人,2019年; Li等人,2022 b)和语义分割(Tian等人,2020年; Chang等人,2022年)。
2.2. Uncertainty Estimation
多模态机器学习在各种实际应用中取得了巨大的成功。然而,目前的融合方法的可靠性仍然是值得注意的未探索的,这限制了它们在安全关键领域(例如,金融风险、医疗诊断)。**不确定性估计的动机是表明机器学习模型给出的预测是否容易出错。**在过去的几十年中,已经提出了许多不确定性估计方法,包括贝叶斯神经网络(BNN)(Denker & LeCun,1990; Mackay,1992; Neal,2012)及其变种(Gal & Ghahramani,2016; Han等人,2022 a)、深合奏(Lakshminarayanan等人,2017; Havasi等人,2021)、预测置信度(Hendrycks & Gimpel,2017)、Dempster-Shafer理论(Han等人,2021)和能量评分(Liu等人,2020年)。预测置信度期望预测的类别概率与经验准确度一致,这通常在分类任务中提到。Dempster-Shafer理论(DST)是贝叶斯理论对主观概率的推广,也是建模认知不确定性的一般框架。能量评分是一种很有前途的捕获分布外(OOD)不确定性的方法,这种不确定性是在机器学习模型遇到与其训练数据不同的输入时出现的,因此模型的输出是不可靠的。最近的大量研究已经研究了OOD不确定性的问题(Ming等人,2022年; Chen等人,2021; Meinke & Hein,2019; Hendrycks等人,2019年)。在本文中,我们调查的预测置信度,Dempster-Shafer理论和能量分数,主要是由于其理论的可解释性和有效性。
3. Theory
在本节中,我们首先在3.1节中澄清使用的多模态融合的基本符号和正式定义。然后,我们在第3.2节中提供了主要的理论结果,从泛化能力的角度严格证明了动态融合方法何时以及如何工作(Bartlett & Mendelson,2002)。由于篇幅限制,我们将全部细节推迟到附录A,只给出证明的简短摘要。
3.1. Preliminaries(准备工作)
我们通过为我们的理论框架引入必要的符号来初始化。考虑在数据 ( x , y ) ∈ X ∗ Y (x,y)∈X * Y (x,y)∈X∗Y上的学习任务,其中 x = x ( 1 ) , x ( 2 ) , . . . , x ( M ) x={x^{(1)},x^{(2)},...,x^{(M)}} x=x(1),x(2),...,x(M)具有M个模态, y ∈ Y y∈Y y∈Y表示数据的标签。多模态训练数据被定义为 D t r a i n = { x i , y i } i = 1 N D_{train}=\{x_i,y_i\}^N_{i=1} Dtrain={xi,yi}i=1N。具体来说,我们使用X,Y和Z来表示输入空间,目标空间和潜在空间。类似于先前在多模态学习理论中的工作(Huang等人。2021年),我们定义$h:X \mapsto Z 是从输入空间到潜在空间的多模态融合映射, 是从输入空间到潜在空间的多模态融合映射, 是从输入空间到潜在空间的多模态融合映射,g:Z\mapsto Y 是一个任务映射。我们的目标是学习一个可靠的多模态模型 是一个任务映射。我们的目标是学习一个可靠的多模态模型 是一个任务映射。我们的目标是学习一个可靠的多模态模型f=g \circ h(x) ,在未知的多模态测试数据集 ,在未知的多模态测试数据集 ,在未知的多模态测试数据集D_{test} 表现良好, 表现良好, 表现良好,D_{train} 和 和 和D_{test} 都来自于 都来自于 都来自于X * Y 上的联合分布 上的联合分布 上的联合分布D 。这里 。这里 。这里f=g \circ h(x)$表示h和g的复合函数。
3.2. When and How Dynamic Multimodal Fusion Help(动态多模态融合在何时以及如何进行帮助)
为了简单起见,我们提供了在两分类设置中使用逻辑损失函数的集合式后期融合策略的分析。我们的分析遵循这个路线图:(1)我们首先使用Rademacher复杂度(Bartlett & Mendelson,2002)来描述动态后期融合的泛化误差界,然后将该界分成三个分量(定理1);(2)在此基础上,进一步证明了动态融合在一定条件下具有较好的泛化能力(定理2)。我们以如下基本设置开始分析。
基本设置:在一个含有M个输入模态以及二分类的场景下,我们将 f m f^m fm定义为在模态 x m x^{m} xm上的单模态分类器。后期融合多模态方法的最终预测通过对来自不同模态的决策进行加权来计算: ∑ m = 1 M w m ⋅ f m ( x ( m ) ) \sum^M_{m=1}w^m\cdot f^m(x^{(m)}) ∑m=1Mwm⋅fm(x(m))其中 f ( x ) f(x) f(x)表示最终的预测值。与静态后期融合不同,动态多模态融合中的权值是动态生成的,并且针对不同的样本而变化。为了清楚起见,我们使用下标来区分它们,即 w s t a t i c m w^m_{static} wstaticm是指静态后期融合中模态 M M M的总体权重,而 w d y n a m i c m w_{dynamic}^m wdynamicm是指动态融合中的权重。具体而言, w s t a t i c m w^m_{static} wstaticm是一个常数,并且 w s t a t i c m ( ⋅ ) w^m_{static}(\cdot) wstaticm(⋅)是一个关于输入样本 x x x的函数,二分类多模态分类器的泛化误差定义为:
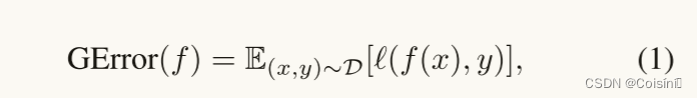
其中的
D
D
D是一个未知的联合分布,并且
l
l
l是逻辑损失函数。为了方便起见,我们将单模态分类器损失
l
(
f
m
(
x
m
)
,
y
)
l(f^m(x^m),y)
l(fm(xm),y)简化为
l
m
l^m
lm并且在下面的分析中省略输入。现在我们提出第一个关于多模态融合的主要结果。
定理1(多模态融合的泛化边界)。令
D
t
r
a
i
n
=
x
i
,
y
i
i
=
1
N
D_{train}={x_i,y_i}^N_{i=1}
Dtrain=xi,yii=1N是含有
N
N
N个样本的训练数据集。
E
^
(
f
m
)
\hat{E}(f^m)
E^(fm)是在
D
t
r
a
i
n
D_{train}
Dtrain上
f
m
f^m
fm的单模态经验误差(笔记:经验误差也就是在训练集上的训练误差,它一般与population loss相对,population loss是对于整个数据集而言)。则对于
H
\mathcal{H}
H中的任何假设
f
\mathcal{f}
f(即:
H
:
X
→
(
1
,
1
)
,
f
∈
H
\mathcal{H}:\mathcal{X}\rightarrow(1,1),\mathcal{f}∈\mathcal{H}
H:X→(1,1),f∈H)且
1
>
δ
>
0
1>δ>0
1>δ>0,概率至少为
1
−
δ
1-δ
1−δ,它认为:

其中
E
(
w
m
)
\mathbb{E}(w^m)
E(wm)是联合分布
D
\mathcal{D}
D的融合权重的数学期望,
R
m
(
f
m
)
\mathcal{R_m}(f^m)
Rm(fm)是
R
a
d
e
m
a
c
h
e
r
\mathbb{Rademacher}
Rademacher复杂度(
) , C o v ( w m , l m ) Cov(w^m,\mathcal{l}^m) Cov(wm,lm)是融合权重和损失之间的协方差。
直觉上,定理1证明了多模态分类器的泛化误差由所有的单模态分类器的经验损失、模型复杂度以及融合权重与单模态损失之间的协方差的加权平均性能来限定。这段可以用在论文中在建立了一般的误差界之后,我们的下一个目标是验证动态多模态后期融合何时能够达到比静态后期融合更紧的界限。不正式的来说,在表达式1中 T e r m − C o v Term-Cov Term−Cov测量了 w m \mathcal{w}^m wm和 l m \mathcal{l}^m lm的联合变化率(正规翻译是联合变异性,这里是方便理解)。请记住,在静态多模态融合中, w s t a t i c m w^m_{static} wstaticm是一个常数,这意味着对于任何静态融合方法, T e r m − C o v = 0 Term-Cov=0 Term−Cov=0。因此,静态融合方法的泛化误差减小到:

因此,当
T
e
r
m
−
L
Term-L
Term−L和
T
e
r
m
−
C
Term-C
Term−C的总和在动态融合中是不变的或更小,并且Term-Cov ≤ 0时,我们可以确保动态融合可证明优于静态融合。得出的结论 这个定理被正式表示为
定理2 设
O
(
G
E
r
r
o
r
(
f
d
y
n
a
m
i
c
)
)
\mathcal{O}(GError(f_{dynamic}))
O(GError(fdynamic)),
O
(
G
E
r
r
o
r
(
f
s
t
a
t
i
c
)
)
\mathcal{O}(GError(f_static))
O(GError(fstatic))分别为采用动态和静态融合策略的多模态分类器的泛化误差上界。
E
^
(
f
m
)
\hat{E}(f^m)
E^(fm)是在定理1中定义的
D
t
r
a
i
n
D_{train}
Dtrain上的
f
m
f^m
fm的单模态经验误差,则对于
H
:
X
→
(
−
1
,
1
)
\mathcal{H}:\mathcal{X}\rightarrow(-1,1)
H:X→(−1,1)且
1
>
δ
>
0
1>δ>0
1>δ>0中的任何假设
f
d
y
n
a
m
i
c
f_{dynamic}
fdynamic,
f
s
t
a
t
i
c
f_{static}
fstatic,以下结论成立:
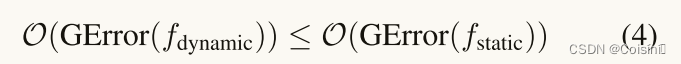
概率至少为
1
−
δ
1-δ
1−δ,如果我们有
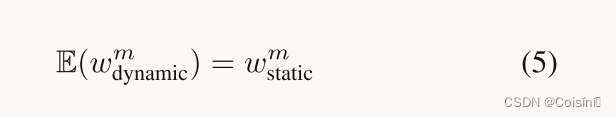
并且
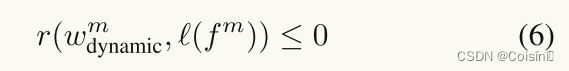
其中
r
r
r是皮尔逊相关系数,其测量动态融合权重
w
d
y
n
a
m
i
c
m
w^m_{dynamic}
wdynamicm和单模态损失
l
m
\mathcal{l}^m
lm之间的相关性。
补充内容:皮尔逊相关系数
最常用的相关就是皮尔逊相关(Pearson correlation),得名于Karl Pearson, 他从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的,这个相关系数也称作“皮尔逊积矩相关系数(Pearson Product-Moment Correlation)”。皮尔逊相关系数通常用字母r表示(所以常常写作 Pearson’s r,当然也有用\rho来表示),衡量两个随机变量之间的线性关系(或者说线性关联度)。
两个变量之间的总体(population)的皮尔逊相关系数定义为两个变量之间的[协方差]和[标准差]之积的商(或者说,归一化的协方差),通常用\rho表示,定义如下:
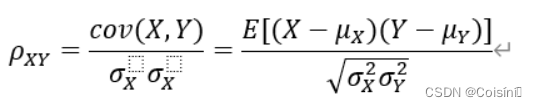
估算[样本]的协方差和标准差,可得到([样本]的)皮尔逊相关系数,常用英文小写字母
r 代表,r 的表达式如下所示:
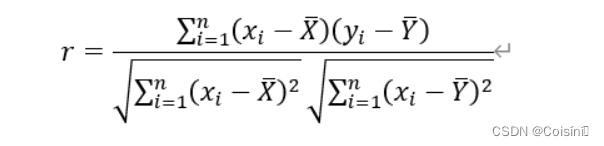
* 以上分母中后半部分应该是
y
i
y_i
yi而不是
x
i
x_i
xi。其中,
x
‾
\overline{x}
x和
y
‾
\overline{y}
y分别表示两者的样本均值。 R=1表示两者完美的正向线性相关,即满足Y = aX+b(a>0)的关系; R=-1表示两者完美的负向线性相关,即满足Y = aX+b(a<0)的关系. 在X-Y散点图上看的话,散点图完全处于一条直线上。R=0则表示两者没有(线性)相关性。

需要注意的是,皮尔逊相关系数只是线性关系的度量,如果为0的话,那只是表示两个变量之间没有线性关系,但是它们之间仍然可能存在别的关系!如下图所示:

这个散点图中的x和y之间的皮尔逊相关系数为0,但是仅目测就知道两者之间并不是毫无关系,事实上它们之间存在着完全的平方关系。 另外一个常见的误解是把相关关系当成了因果关系。
Example1:
# Example1
dat1 = np.array([3,5,1,6,7,2,8,9,4])
dat2 = np.array([5,3,2,6,8,1,7,9,4])
fig,ax = plt.subplots()
ax.scatter(dat1,dat2)
stats.pearsonr(dat1,dat2)
(0.8999999999999999, 0.0009430623223403325)

计算结果表明这两个序列的皮尔逊相关系数高达0.9。stats.pearsonr()除了返回相关系数外,还顺带计算了对应的p-value。直观的理解是,p-value表示两个零相关的序列能够给出这个相关系数的概率,以上p-value为0.0009表明两个零相关的序列的相关系数的绝对值大于等于0.9的概率不足千分之一。从另一个侧面说明了这个相关系数结果的置信度。
Remark.从理论上讲,优化相同的函数类有效地导致相同的经验损失。假设对于每个模态 m m m,我们在动态和静态融合中使用的单模态分类器 f m f^m fm具有相同的架构,则单模态分类器 R m ( f m ) \mathcal{R}_m(f^m) Rm(fm)和经验风险估计 E ^ ( f m ) \hat{E}(f^m) E^(fm)的内在复杂度可以是不变的。因此,在这种情况下,我们认为:
由5式:
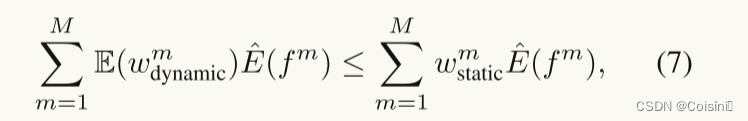
且
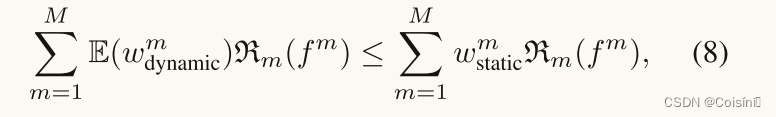
如果等式5适用于所有模态
m
\mathcal{m}
m,则根据定理2,很容易得出如下结论:实现可靠的动态多模态融合的主要挑战是为满足等式2的每个模态学习合理的满足于等式5和等式6的
w
d
y
n
a
m
i
c
m
w^m_{dynamic}
wdynamicm。
4. Method
现在我们继续回答“如何实现鲁棒动态融合?“.在本节中,我们从理论上确定动态多模态融合和不确定性估计之间的联系。然后,提出了一个统一的动态多模态融合框架,名为质量感知多模态融合(QMF)。接下来,我们将展示如何在决策级后期融合和分类任务中实现此框架,以支持我们的研究结果。
4.1. Coincidence with Uncertainty Estimation(与不确定性估计保持一致性)
首先,我们专注于如何满足等式6。正如我们在2.2节所讨论的,各种不确定性估计方法的共同动机是提供一个指标,表明模型给出的预测是否容易出错。这种动机本质上接近于获得满足等式6的权重。笔记:当多模态融合的融合权值与单模态泛化误差负相关时,动态融合方法的性能优于静态融合方法。[这一结论在一开始的主要贡献中也提到了] 我们用以下假设来表述这个主张:
假设1. 给定模态 m m m上有效的不确定性估计量 u m : X → R u^m:\mathcal{X}\rightarrow\mathbb{R} um:X→R,要估计的不确定性 u m ( x ) u^m(x) um(x)与其模态特定的损失 l m ( x ) : r ( u m , l m ( x ) ) ≥ 0 \mathcal{l^m(x)}:r(u^m,l^m(x))≥0 lm(x):r(um,lm(x))≥0正相关,其中 r \mathcal{r} r是皮尔逊相关系数。
这种洞察力提供了索新的动态融合方法证明优于传统的静态融合方法的机会。类似于先前的动态融合方法(Blundell等人,2015; Zhang等人,2019年; Han等人,2022 b),我们部署模态级权重策略来引入动态。
不确定性加权。不确定性感知融合权重
w
m
:
X
→
R
w^m:\mathcal{X}\rightarrow\mathbb{R}
wm:X→R是对应于不确定性的线性负相关函数。
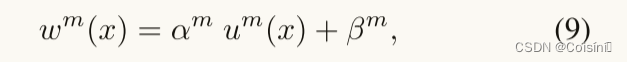
其中
a
m
<
0
a^m<0
am<0,
β
m
≥
0
β^m≥0
βm≥0是模态特定的超参数。
u
m
(
x
)
u^m(x)
um(x)是模态
m
m
m的不确定性。通过调整超参数
a
m
a^m
am和
β
m
β^m
βm,我们可以保证动态融合权重值同时满足等式5 和 等式6。这个引理形式上可以表述为:
引理1(可满足性)。在假设1下,对于任意 w s t a t i c m ∈ R \mathcal{w}^m_{static} ∈ \mathbb{R} wstaticm∈R,总是存在 β m ∈ R β^m ∈ \mathbb{R} βm∈R使得:
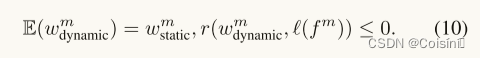
一旦我们得到融合权重,我们就可以根据以下规则在决策级进行不确定性感知加权融合。
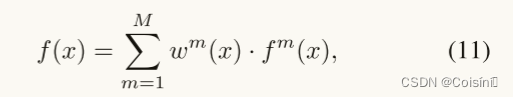
其中
f
m
(
x
)
f^m(x)
fm(x)定义在3.2小节,其表示对模态
m
m
m的单模态预测。
4.2. Enhance Correlation by Additional Regularization(通过额外的正则化增强相关性)
补充:能量分数
在论文《Energy-based Out-of-distribution Detection》的第3节(基于能量的分布外检测)提到:分布外检测是一个二分类问题,它依赖于一个分数来区分分布内以及分布外的例子。一个评分函数可以区分分布内和分布外的值。一个自然的选择是使用数据的密度函数
ρ
(
x
)
\mathcal{ρ}(x)
ρ(x),并且考虑具有较低可能性(指的是密度函数)的示例是OOD。虽然可以通过诉诸基于能量的模型来获得判别模型的密度函数:
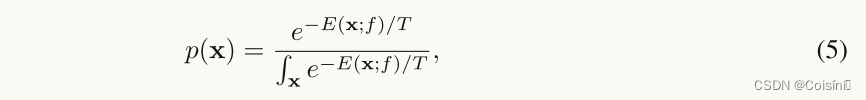
Remark:关于
E
(
x
;
f
)
E(x;f)
E(x;f)的公式已经在第2小节给出:
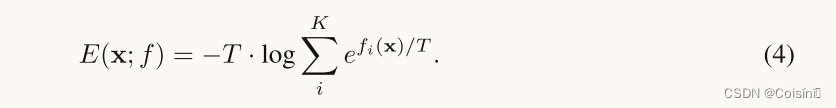 归一化密度
Z
=
∫
X
e
−
E
(
x
;
f
)
/
T
\mathcal{Z}=\int_Xe^{-E(x;f)/T}
Z=∫Xe−E(x;f)/T(相对于X)可能很难计算,甚至无法在输入空间上进行可靠的估计。为了缓解这一挑战,我们的关键观察是,没有归一化根本不会影响OOD检测。具有较高出现概率的数据点相当于具有较低能量。要看到这一点,我们可以采取对等式5的两边取log。
归一化密度
Z
=
∫
X
e
−
E
(
x
;
f
)
/
T
\mathcal{Z}=\int_Xe^{-E(x;f)/T}
Z=∫Xe−E(x;f)/T(相对于X)可能很难计算,甚至无法在输入空间上进行可靠的估计。为了缓解这一挑战,我们的关键观察是,没有归一化根本不会影响OOD检测。具有较高出现概率的数据点相当于具有较低能量。要看到这一点,我们可以采取对等式5的两边取log。
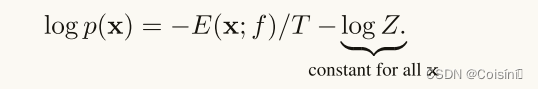
上面的等式表明: E ( x ; f ) E(x;f) E(x;f)实际上与对数似然函数线性对齐,这对于OOD检测是理想的。具有较高能量(较低似然性)的示例被视为OOD输入。具体地,我们建议使用等式4中的能量函数 E ( x ; f ) E(x;f) E(x;f)用于ODD检测。
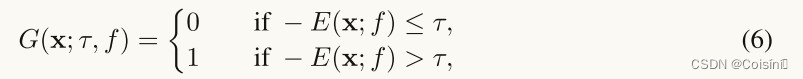
在其中,
τ
\mathcal{τ}
τ是能量的阈值。在实际应用中,我们使用分布内的数据作为阈值,以便ODD检测器
G
(
x
)
G(x)
G(x)正确分类高比例的输入。在这里 我们使用负能量函数
−
E
(
x
;
f
)
-E(x;f)
−E(x;f)来与阳性(分布内)样本得分较高的传统定义保持一致。能量分数本质上是非概率性的,它可以通过
l
o
g
s
u
m
e
x
p
logsumexp
logsumexp算子进行方便的计算得出。与JEM不同的是我们的方法不需要显式估计密度Z,因为Z与样本无关(指的是分布外的样本),并且不影响整体能量分数分布。
通过上述分析,在3.2小节中提出的鲁棒多模态融合的核心挑战已经在假设1中简化为了获取一个高效的不确定性估计量。在我们的实现中,我们利用能量分数(Liu et al.,2020),这是一个在文献中被广泛接受的不确定性学习的度量单位。能量分数桥接了给定数据点的Helmholtz自由能量与其密度之间的差距。对于多模态数据,不同模态的密度函数可以通过相应的能量函数来估计:
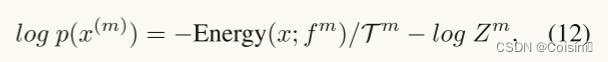
其中,
x
(
m
)
x^{(m)}
x(m)是第m个输入模态,
f
m
f^m
fm是单模态分类模型,
E
n
e
r
g
y
(
⋅
)
Energy(\cdot)
Energy(⋅)是能量函数,
Z
m
Z^m
Zm是对于所有的
x
m
x^m
xm的一个难以处理常数。上面的等式表明
−
E
n
e
r
g
y
(
x
(
m
)
;
f
m
)
-Energy(x^{(m)};f^m)
−Energy(x(m);fm)与密度
ρ
(
x
(
m
)
)
ρ(x^{(m)})
ρ(x(m))线性对齐,输入
X
X
X的第m个模态的能量分数可以计算为:
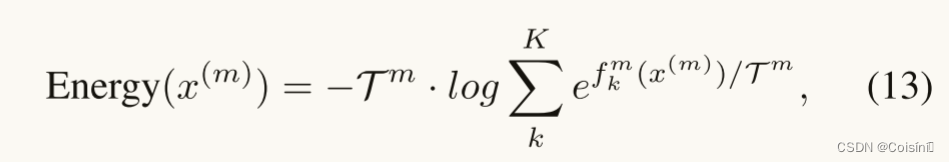
其中
f
k
m
(
x
(
m
)
)
f^m_k(x^{(m)})
fkm(x(m))指的是对应于第
k
k
k个类别标签的分类器
f
m
f^m
fm的输出
logits,
τ
m
\mathcal{τ}^m
τm是一个温度系数(参数讲解)【对于这样一个超参数,直译为“温度系数”,在很多任务中都可以看到,特别是计算机视觉的分类任务中,研究人员往往在
s
o
f
t
m
a
x
softmax
softmax损失基础上额外增加一个温度系数
τ
τ
τ,针对不同的任务,取不同的超参数值。正如字面意义,假设该系数所参与的计算过程就是一个烧水的过程,温度越高,水沸腾越剧烈,这就可以类比信息熵增减的过程,温度系数越大,熵就越高,混乱程度越高,那么
s
o
f
t
m
a
x
softmax
softmax函数输出的各类别概率差距会越来越小(因为差距越小那么看出最优结果也就越困难,对应于熵越高),曲线也会愈发平滑。相反,温度系数越小,函数曲线也会愈发陡峭。】直觉上,更均匀分布的预测导致更高估计的不确定性。然而,实验表明,在没有额外正则化的情况下以这种方式估计的不确定性不足以满足我们的假设1。为了解决这个问题,我们提出了一种基于采样的正则化技术,以增强原始方法的相关性。提高估计的不确定性和相应损失之间的相关性的最简单和直接的方法是利用训练阶段的样本损失作为监督信息。然而,由于深度神经网络的过度参数化现象,在训练过程中损失不断减少到零。受贝叶斯学习(Maddox et al.,2019)和不确定性估计(Moon等人,2020; Han等人,2022 a)的启发,我们建议利用来自历史训练轨迹的信息来正则化融合权重。具体地,给定样本的第m模态
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),
x
i
m
x^m_i
xim 的训练平均损失计算为:
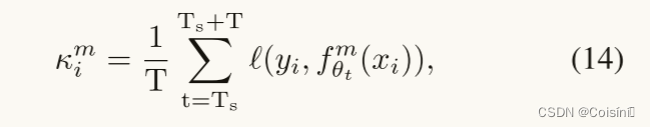
其中
f
θ
t
m
f^m_{θ_t}
fθtm是每个迭代
e
p
o
c
h
t
epoch\space t
epoch t上的单模态分类器,参数为
θ
t
θ_t
θt。在训练
T
s
−
1
T_s-1
Ts−1个epochs之后,我们采样
T
T
T次并计算平均训练损失。
经验上,最近的工作(Geifman等人,2019)表明,与难以分类的样本相比,容易分类的样本在训练期间更早地被学习(例如,噪声样本(Arazo等人,2019年))。期望通过在训练期间学习以下关系来正则化动态融合模型:
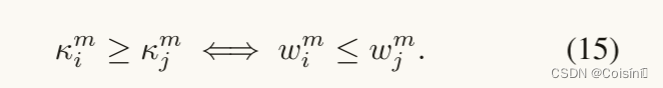
我们现在给出正则化项的完整定义如下:
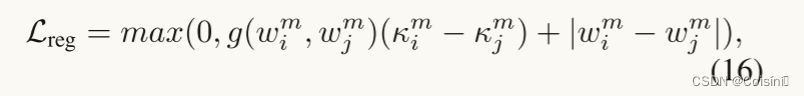
其中:
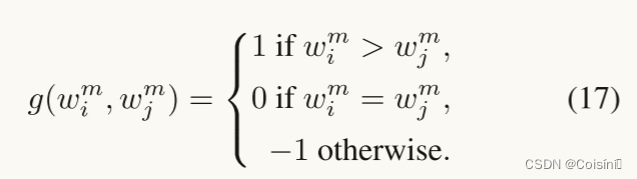
受多任务学习的启发,我们将总损失函数定义为多个模态的标准交叉熵分类损失和正则化项的总和:
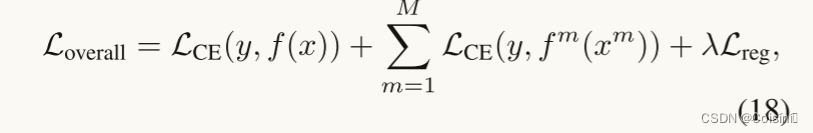
其中
λ
λ
λ是控制正则化强度的超参数,
L
C
E
\mathcal{L}_{CE}
LCE和
L
r
e
g
\mathcal{L}_{reg}
Lreg分别是交叉熵损失和正则化项。整个训练过程如算法1所示。
 对QMF有效性的直观解释。
对QMF有效性的直观解释。
在不失一般性的情况下,我们假设模态 x A x^A xA是干净的,并且模态 x B x^B xB由于未知的环境因素或传感器故障而有噪声。此时, x A x^A xA在干净训练数据的分布中,但 x B x^B xB明显偏离它。因此,我们有 u ( x A ) ≤ u ( x B ) u(x^A)≤u(x^B) u(xA)≤u(xB),即 w A ≥ w B w^A≥w^B wA≥wB。因此,对于我们的QMF,多模态决策将倾向于更多地依赖于高质量模态 x A x^A xA而不是其他模态 x B x^B xB。通过动态确定各模态的融合权值,可以减轻不可靠模态的影响。
5. Experiment
在本节中,我们对不同应用程序的多个数据集进行实验。需要核实的主要问题如下:
- Q1效率I。所提出的方法是否具有更好的泛化能力?(支持定理1)
- Q2有效性II。不确定性感知的动态多模态融合在什么条件下工作?(支持定理2)
- Q3可靠性。所提出的方法是否对模态的不确定性有有效的感知?(支持假设1)
- Q4消融研究。在我们的方法中,性能改进的关键因素是什么?
5.1. Experimental Setup
我们简要介绍了这里的实验装置,包括实验数据集和比较方法。更多详细设置请参见附录B。
任务和数据集。 我们在两个多模态分类任务中评估了我们的方法。
- 场景识别:纽约大学深度V2(Silberman等人,2012)和SUN RGBD(Song等人,2015)是两个公共室内场景识别数据集,其与两种模态相关联,即,RGB和深度图像。
- 图像-文本分类:UPMC FOOD 101数据集(Wang等人,2015)包含由Google图像搜索获得的(可能有噪声)图像和相应的文本描述。MVSA情感分析数据集(Niu等人,2016)包括一组带有从社交媒体收集的手动注释的图像-文本对。虽然上述数据集都是在 M = 2 M = 2 M=2的条件下,但很直观,很容易推广到 M ≥ 3 M ≥ 3 M≥3。
评价指标。 由于涉及随机性,我们报告了NYU Depth V2和SUN RGB-D在10种不同种子上的平均准确度、标准差和最差情况准确度。为了与现有的工作一致(Han等人,2022 c; Kiela等人,2019; Yadav & Vishwakarma,2023),我们在UMPC FOOD 101上重复实验3次,在MVSA上重复实验5次。
比较方法。 对于场景识别任务,我们将所提出的方法与三种静态融合方法进行了比较:后期融合,基于级联的融合,基于对齐的融合方法(Wang等人,2016)和两种代表性的动态融合方法,即,MMTM(Joze等人,2020)和TMC 3(Han等人,2021年)。对于图像-文本分类,我们与强单模态基线(即,Bow,Bert和ResNet-152)以及复杂的多模态融合方法,包括Late fusion、ConcatBow、ConcatBERT和最近的sota MMBT(Kiela等人,2019年)。
5.2. Experimental Results
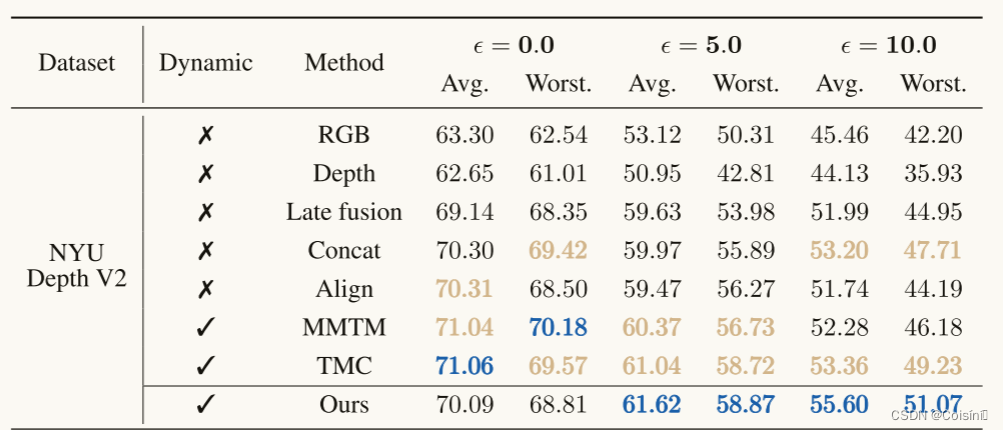
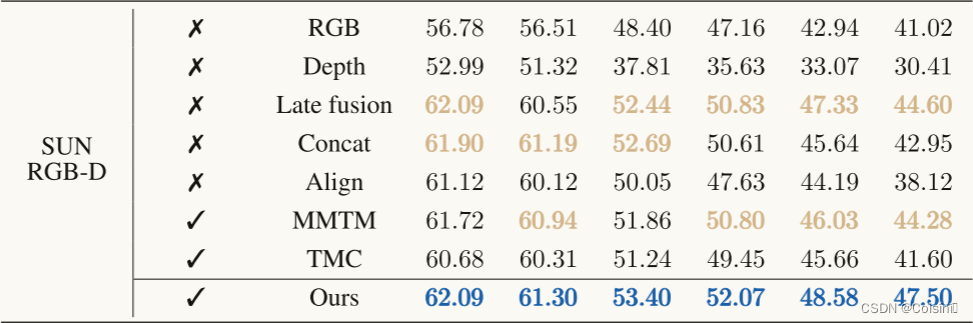
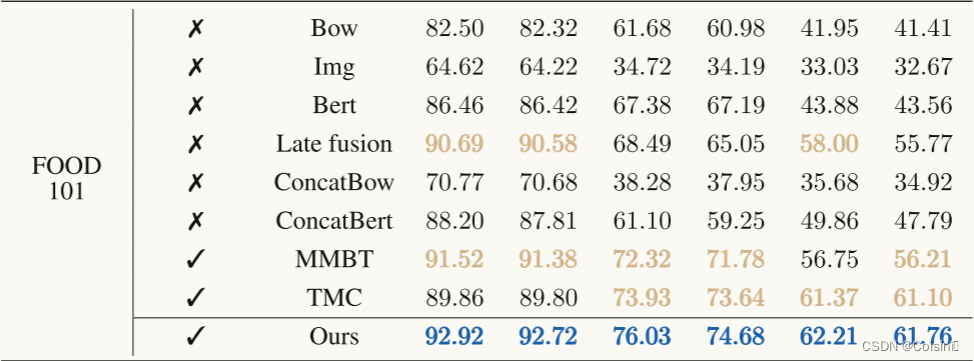
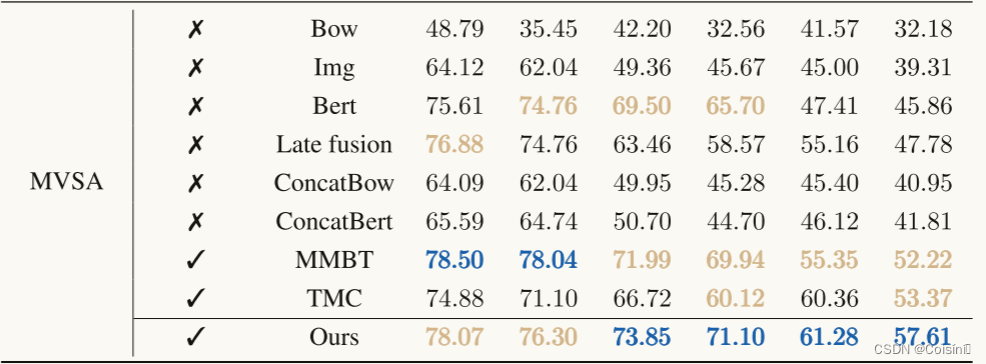
分类鲁棒性(Q1)。 为了验证不确定性感知加权融合的鲁棒性,我们根据之前的工作(Han等人,2021年; Ma等人,2021; Verma等人,2021年; Hu等人,2019年; Xie等人,2017年)。不同类型噪声(如椒盐噪声)下的更多结果见附录C.2。实验结果示于表1中。据观察,QMF通常表现在前三名的平均和最坏情况下的准确性。这一观察结果表明,QMF具有更好的泛化能力比他们的同行实验。还值得注意的是,QMF优于现有技术的方法(即,MMBT和TMC)在大规模基准测试UPMC FOOD 101上的仿真结果表明了该方法的优越性。
表1。当50%的模态被高斯噪声破坏时的分类比较,即零均值,方差为 ϵ ϵ ϵ。最好的三个结果以粗体棕色显示,最好的结果以粗体蓝色突出显示。完整结果及标准差见附录。
与不确定性估计的连接(Q2)。 我们进一步与各种不确定性估计算法实现的QMF进行比较,即,预测置信度(Hendrycks & Gimpel,2017)和Dempster-Shafer证据理论(DST)(Han等人,2021年)。根据图3所示的比较结果,很明显(i)泛化能力(即,平均和最坏情况下的准确性)的动态融合方法符合他们的不确定性估计能力和(ii)我们的QMF在同一时间实现了最佳性能的分类精度和不确定性估计。这种比较揭示了QMF优于其他融合方法的根本原因,并支持定理2。我们展示了在零均值和方差为10的高斯噪声下的NYU Depth V2和SUN RGB-D的结果。
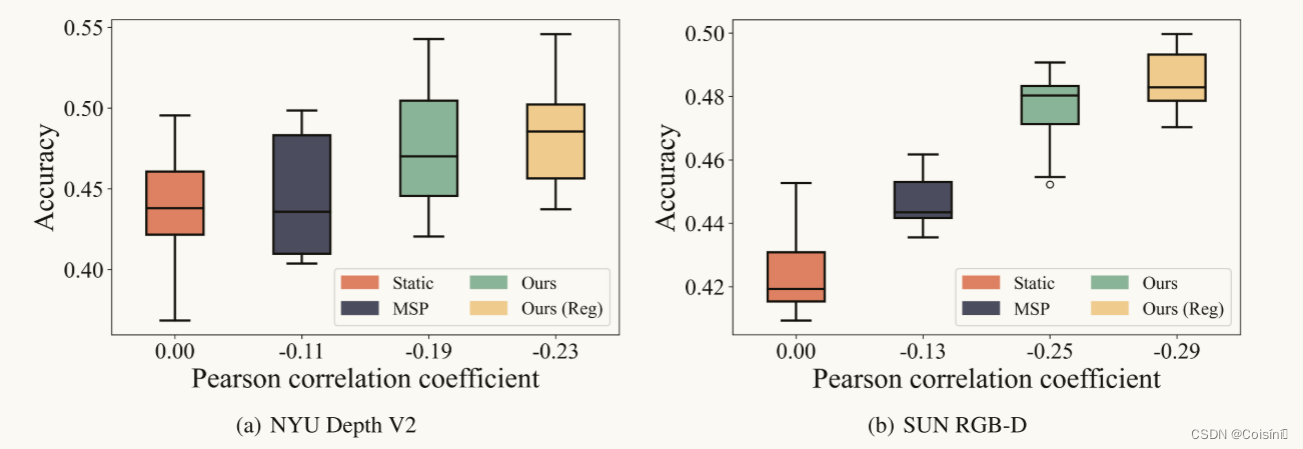
图3.通过10次随机试验,对不同融合方法的精度和皮尔逊相关系数进行了检验。平均和最坏情况下的准确度与不确定度估计能力高度一致。
QMF的可靠性(Q3)。 在UPMC FOOD-101上,我们采用表3中不同的模式计算了等式9中定义的融合权重。据观察,QMF的融合权重与其他不确定性估计方法(在相关性方面)相比,具有最有效的感知模态质量能力。这一观察证明了我们对等式9中不确定性感知权重的期望。
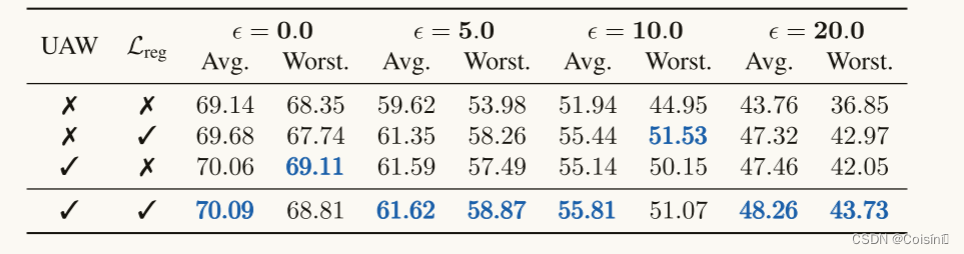
消融研究(Q4)。 我们比较不同的组件组合(即,不确定性感知加权和正则化项 L r e g \mathcal{L}reg Lreg)。在这里,我们也在表2中的NYU Depth V2上使用高斯噪声,更多结果可以在附录C.1中找到。很容易得出结论:1)添加 L r e g \mathcal{L}reg Lreg有利于获得更合理的融合权重; 2)使用全QMF可以预期最佳性能。请参阅表格。附录C.1中的第4节,具有标准差的完整结果。
表2. NYU Depth V2的消融研究。含标准差的完整结果见附录C.1。其中的 ε ε ε表示的是方差
总之,实证结果可以支持我们的理论研究结果。这些工作确定了动态多模态融合方法的性能增益。所提出的方法可以帮助提高多个数据集上的鲁棒性。
6. Limitations(局限性)
即使所提出的方法实现了更优益的性能,仍然存在一些潜在的局限性。首先,QMF的融合权重是基于不确定性估计的,这在真实的世界中是一个具有挑战性的任务。例如,在我们的实验中,我们只能在NYU Depth V2和SUN RGB-D数据集上实现轻度Pearson‘s r。因此,探索新的不确定度估计方法在未来的工作中具有重要的意义和价值。其次,虽然我们描述了所提出的方法的泛化误差界,我们的理论依据是基于假设1。然而,先前的工作(Fang等人,2022)揭示了OOD检测在某些场景下是不可学习的。因此,如何进一步表征动态多模态融合的泛化能力仍然是一个具有挑战性的开放性问题。
7. Conclusions and Future works
在多模态融合中引入动态特性已经在各种应用中取得了显著的实验结果,包括图像分类、目标检测和语义分割。许多SOTA的多模态模型引入动态融合策略,但这种技术提供的归纳偏置还没有得到很好的理解。在本文中,我们提供了严格的分析,了解什么时候以及什么样的动态多模态融合方法在嘈杂的多模态数据上更鲁棒。这些发现表明不确定性学习和鲁棒多模态融合之间的联系,这进一步暗示了设计新的动态多模态融合方法的原则。最后,我们在多个基准上进行了广泛的实验,以支持我们的发现。在工作中使用了基于能量的加权策略的设计,其他的不确定性估计方法值得探索。另一个有趣的方向是在更一般的环境下证明动态融合。
Acknowledgments
本研究得到了国家自然科学基金(批准号:61976151)和A* STAR 中央研究基金的部分资助,并在此对MindSpore和CAAI的支持表示感谢。作者要感谢Zhipeng Liang(香港科技大学)检查数学细节,以及Zongbo Han,Huan Ma(天津大学)对写作的评论。作者还感谢ICML匿名同行评审员的建议。
References
略
代码整理



















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











