






LIO-SAM学习系列文章目录
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
最近重新回头看LIO-SAM的代码,发现之前很多不懂的地方都豁然开朗,果然学习还是得回顾的。但是在IMU预积分和因子图优化这一块还是理解的不够到位,因此再捡起来学一学。
IMU预积分不理解的可以看一下知乎上一位大佬在一维上的讲解:
imu预积分原理的个人理解
讲解的很棒,理解了一维推广到SLAM中的三维也是一样的道理。
ok,废话不多说,下面开始讲因子图优化
一、因子图是什么?
因子图是一种用于处理大量变量和约束关系的图形模型,被广泛应用于机器人等领域的状态估计和感知问题。在SLAM中,因子图被用来描述机器人在未知环境中的位置和地图信息。SLAM问题中,机器人需要同时进行定位和建图,因此需要在不确定性和噪声的条件下处理大量的测量和状态变量。因此,SLAM问题可以描述为一个大规模的非线性最小化问题,其中目标是最小化所有测量和状态变量的误差,从而获得最准确的地图和机器人位置。因子图可以很好地解决SLAM问题中的大规模非线性优化问题。当测量数据增加时,因子图提供了一种自适应建图的方法,能够快速完成数据的处理。此外,因子图还可以帮助机器人对测量数据的不确定性进行建模和处理,使机器人能够更准确地估计自身位置和地图信息。
我的理解:简单的说,在SLAM中,需要通过当前时刻机器人的状态量和当前时刻到下一时刻之间的传感器观测量来预测下一时刻机器人的状态量。因子图模型就是一个机器人可以利用机器人状态量和多个传感器观测量(传感器测量值)
来构建约束从而优化最终得到下一时刻的状态量。
下面从数学上来理解:
这里记录一下董博士如何通过贝叶斯网络引入因子图模型。

SLAM问题可以用以上图描述,黄色圆形为机器人状态量,蓝色圆形为路标点状态量,红色圆圈为机器人对路标点的观测量,绿色圆形为机器人自身的观测量(也可以理解为机器人的里程计)。将机器人的状态设为X机器人的观测量设为Z。因此机器人SLAM的概率模型为:
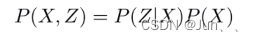
上述式子中P(X,Z)为联合概率,P(X)为状态变量的概率,P(Z|X)为机器人在当前状态下观测变量的条件概率(可以由传感器的模型得到)。
下面讨论P(Z|X):
上面第一幅图中每个观测量(红色和绿色圆圈)都只与由极少数状态量(两个)有关,因此利用因子图的这个特点,可以得到以下式子:
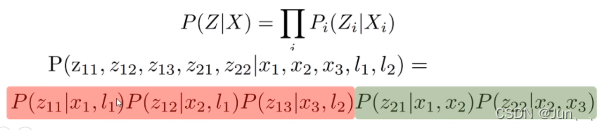
可见三个路标点的观测变量概率和两个里程计变量的概率是通过相乘的形式联系起来。条件概率可以分解成互相之间的乘积形式。根据这个特点也简化了后续因子图计算。
概率模型的定义:假设知道系统的状态变量(机器人所在位置、路标点所在位置),可以推测出机器人得到的观测量(观测量是通过某些传感器得到的,而传感器有已知模型,可以通过数据手册得到),即已知机器人的状态量和传感器的模型,就可以推算出机器人的观测量。这是一个生成模型,即给的是系统的状态变量,推出系统的观测变量。
但是SLAM是一个状态估计问题,相信高博已经和大家讲过了 哈哈。
SLAM是已知系统的观测变量,推出系统的状态变量。也就是P(X|Z)
通过贝叶斯定律我们可以知道:
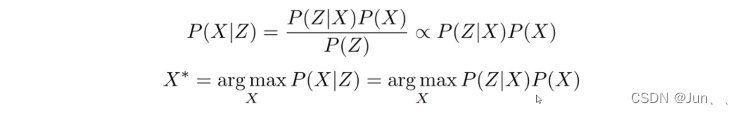
上面第一个式子是由贝叶斯定律得到的,由于分母P(Z)与状态量X无关,所以可以简化为右边的形式,即似然概率P(Z|X)*先验概率P(X)。
求解SLAM状态估计P(X|Z)最大概率的问题转化成上图中第二个式子。而这里的P(Z|X)是由传感器模型给定的。
前面我们分析过P(Z|X)可以有多个观测变量的乘积相乘得到。每一个观测变量在贝叶斯网络里都是单独求解的(相互独立),所以所有的条件概率都是乘积的形式,且可分解,在因子图里面,分解的每一个项就是一个因子,乘积乘在一起用图的形式来描述就是因子图,如下图所示。
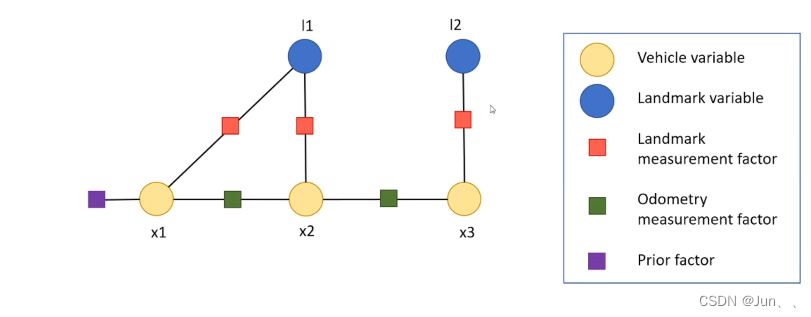
因子图包含两种节点。即状态量和观测量。其中状态量一般以圆圈表示,如图中的机器人自身状态量(黄色)和路标点状态量(蓝色)。观测量一般以正方形表示,也叫做“因子”,如图中的路标点观测量(红色)和机器人里程计观测量(绿色)。上图中还有一个紫色的先验因子,这个先验因子就是指上面公式中的先验概率P(X)。
先验因子的作用:用于固定因子图,防止出现多个解的情况。可以理解为这个先验因子把后面的因子图固定在这个地方,如果没有这个先验因子(也可以叫做约束),因子图可以出现在任何地方。
至于如何求解这个因子图,就是求出上述所有因子的条件概率的乘积,得到最大概率,求出的系统状态就是通过观测和状态约束推测的最可能的状态。

接下来看因子图中的每个因子

因为一个因子描述的是一个传感器观测到的观测变量,现实生活中,大多数传感器的观测都是包含高斯噪声的,因此每一个因子得到的概率就可以使用指数函数来定义。
这里引入一个error function,就是上图中的f,也就是预测量-观测量。希望error是越小越好,这就说明观测值和预测值是接近的。套到P(Z|X)里面来看,因子图的求解是要所有因子的乘积最大化。而对于负指数函数形式,每一个因子乘积最大化代表里面的fx最小化。这正好符合希望误差函数的误差最小化。即系统状态与观测值越吻合,error越小,那φ就越大(MAP最大),就是希望能找到这么一组状态变量能尽可能和观测量吻合。

然后,就转为一个最小二乘问题,这一块相信高博在十四讲中已经讲的很清楚了,我就不继续啰嗦了。
二、如何使用因子图
总结
提示:这里对文章进行总结:
















 9428
9428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









