







各位朋友,新的一年好呀,好好干,出成果!不知不觉从9月份开始写到现在也写了40篇文章了,文章如有诸多问题还请批评指出。随着学习的深入的确发现之前的一些文章有一些问题或者有遗漏的地方,等过年有空再整理下吧。
言归正传,现在越来越多搞SLAM的人开始用因子图优化,目前我也在学习中,有很多问题,因此再开一个专栏。
话不多说,开始第一篇。
先上链接:
因子图的理论基础与在机器人中的应用 - 深蓝学院 - 专注人工智能的在线教育www.shenlanxueyuan.com/open/course/28正在上传…重新上传取消
个人觉得董靖博士讲的很好,但是可能只能简单入门下因子图优化的概念,想要深入还得去看原著,这个后面再谈,先入个门。
第一部分:因子图(Factor graph)模型在机器人领域(感知)
概率模型到因子图模型
定义一个简单的机器人问题(SLAM)
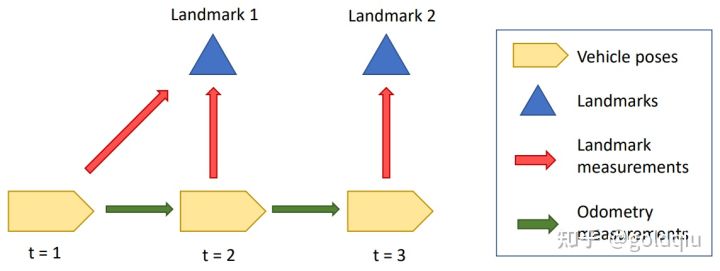
假设有一个机器人在往前运动,运动过程中能观测到两个路标点,定义了三个时间,在三个时间中有对路标点的观测量和机器人自身运动的估计量(里程计)
用贝叶斯网络(Bayes Net)来描述SLAM建模问题。
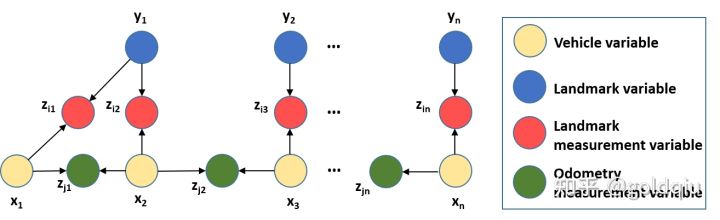
在贝叶斯网络中通过有向的边来连接一些变量。图中定义了两类四种变量。蓝色圆圈是路标节点变量,黄色圆圈是机器人状态变量,都属于状态变量。红色圆圈是机器人对路标点的观测变量,绿色圆圈是机器人对自身运动的观测变量,都属于第二类变量-观测变量。这个贝叶斯网络实际上描述了状态变量和观测变量的联合概率模型。
概率模型的定义:假设知道系统的状态变量(机器人所在位置、路标点所在位置),可以推测出机器人得到的观测量(观测量是通过某些传感器得到的,而传感器有已知模型,可以通过数据手册得到),即已知机器人的状态量和传感器的模型,就可以推算出机器人的观测量。
所以得到了一个生成模型(generative model):用一个贝叶斯网络来描述系统模型,在已知状态量的情况下,如何得到观测量。
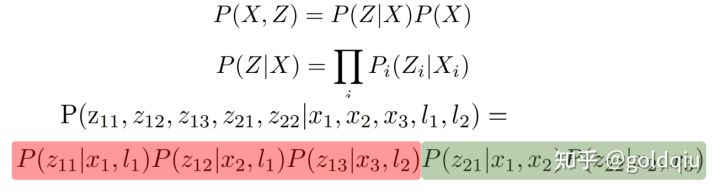
X为机器人状态量,Z为观测量。
假设知道系统状态的概率分布和给定系统状态下的观测量的条件概率(通过传感器的概率模型),相乘得到的联合概率就是系统状态变量和观测变量的联合概率。
观测变量的条件概率的特点:路标点1的观测变量只跟时间1下的机器人的位置(状态变量)和路标点1的位置有关,跟路标点2无关。图中可以很清晰地看到,路标点1的观测变量通过两个边连接到机器人的位置变量和路标点1的位置变量。这就说明这个观测变量是由这两个边连接的机器人的位置变量和路标点1的位置变量单独决定的。极少的状态变量决定每一个单独的观测变量,这对后面构建的矩阵的稀疏特性至关重要。
所有观测变量的条件概率是以一个乘积的形式存在的。在示例中公式的红色部分,三个观测变量的条件概率相互独立,相乘起来。同样绿色部分是两个odometry的观测变量,也相乘起来。这些条件概率可以分解。
但现实生活中需要求解的问题是知道观测量,需要求解状态量,是一个状态估计的问题(SLAM问题)。
因子图就是这样一类估计模型(reference model )。应用贝叶斯定律(Bayes rule):给定Z,求解X的概率(估计模型)正比于给定X,求解Z的概率(生成模型)。
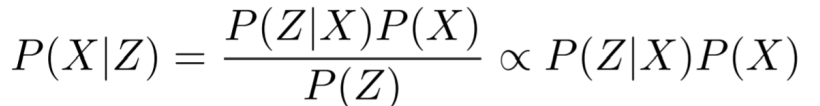
分母的Z先验值是跟X无关的(相互独立),可以省略。
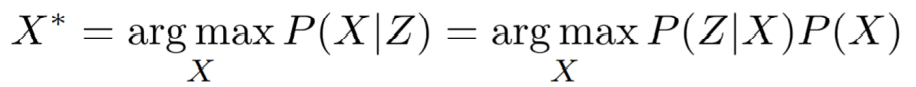
对于求解的状态估计问题,就是给定系统观测量,求解系统状态量,使得这个条件概率最大。也就是求解MAP(最大后验分布 maximum posterior inference), 公式中右边项的X是先验概率(prior),一般是上一帧的最优后验概率,P(Z|X)是似然概率(likelihood,由传感器模型给定) ,左边就是最大后验概率。
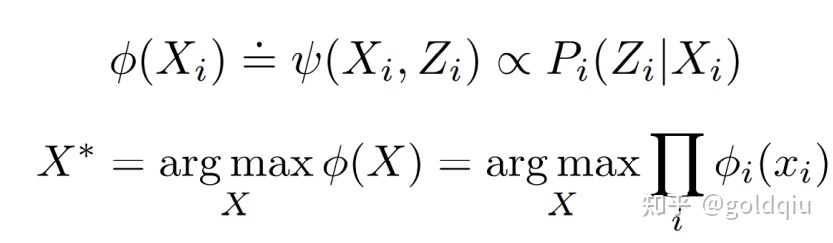
每一个观测变量在贝叶斯网络里都是单独求解的(相互独立),所以所有的条件概率都是乘积的形式,且可分解,在因子图里面,分解的每一个项就是一个因子,乘积乘在一起用图的形式来描述就是因子图。
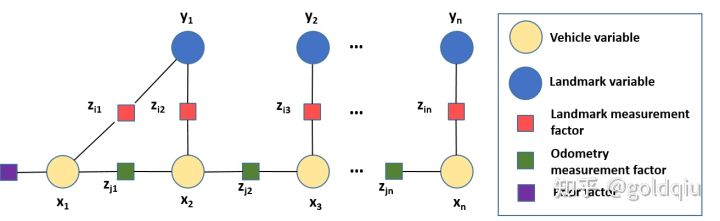
因子图里面包括两类节点和边
节点:状态变量(圆圈),是估计求解的变量。
观测节点(就是因子,用方块标定),每一个因子表示每一个得到的观测量。
因子图里面还会包括一个先验因子(prior factor),就是公式中X的先验值(先验概率),用来固定整个系统的解,避免数值多解,达到数值可解 。
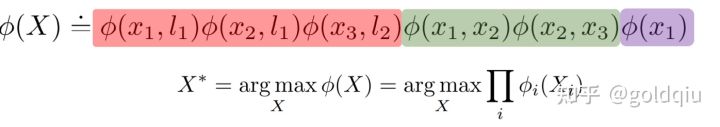
整个因子图实际上就是每个因子单独的乘积。红色对应观测量因子,绿色对应状态量之间的因子(里程计),紫色是先验因子。求解因子图就是将这些因子乘起来,求一个最大值,得到的系统状态就是概率上最可能的系统状态。

根据中心极限定理,绝大多数传感器的噪音是符合高斯分布的,所以每个因子都是用指数函数来定义的,指数函数对应了error function,包括两个部分:系统状态量和观测量。error function实际上表示的是用状态量去推测的观测量与实际观测量的区别。
以odometry factor为例,它的error function是:后一个位置减去前一个位置(预估的量,因为后一个位置是预估的),再减去实际观测到的量,其实就是预估的量减去观测的量。
Landmark factor的error function也一样,是用Xi和Lj推测出来的观测点的位置量减去实际的观测点位置量。
希望error是越小越好,这就说明观测值和预测值是接近的。套到MAP里面来看,因子图的求解是要所有因子的乘积最大化。而对于负指数函数形式,每一个因子乘积最大化代表里面的fx最小化。这正好符合希望误差函数的误差最小化。即系统状态与观测值越吻合,error越小,那φ就越大(MAP最大),就是希望能找到这么一组状态变量能尽可能和观测量吻合。
概率问题转化为非线性最小二乘问题
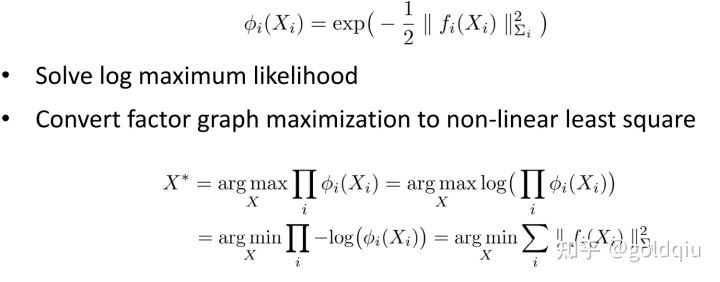
对定义的因子图乘起来的概率,希望能够最大化,假设所有因子都是负指数函数形式,对函数取负对数,则负指数函数最大化问题实际上等于一个非线性最小二乘问题。常用方法是迭代法,如高斯牛顿。

给定一个初始值,通过某种办法或推测一组可能的系统状态变量,去求解一个修改量(dx),让最小二乘值尽可能变小,求出dx再加上原来的x(即修改了初始值),再代回原来的函数,迭代调整初始值,达到一定的停止条件后,求出最优的一个修改值。
中间求解增量的步骤一般是通过线性化来做(对非线性函数做一阶泰勒展开),得到线性最小二乘问题(linear least square)。

方式一:通过normal equation来求解
JtJ矩阵是正定矩阵(Jacobian矩阵满足列满秩),做Cholesky分解(Cholesky factorization), 将JtJ分解成RtR,而R是上三角阵,实际上是求解两个上三角阵的线性方程组。

方式二:直接求解
通过QR分解,如果给定只有J,不计算Jt,对J进行QR分解,可以直接求解出R。
QR分解的速度会慢一些,但Cholesky分解的数值稳定性要差,一般是要根据所求解系统的性质来决定。

对于Jacobian矩阵,每一行(block)对应的是一个因子,比如说紫色部分表示的是prior因子,绿色表示的是odometry因子,红色表示路标点观测因子。紫色一行只有一个(只在X1有非零项)是因为先验因子只影响了一个状态(X1), 同样对于里程计因子,只有X1和X2有连接,所以在J矩阵中第二行只有X1,X2有非零项。
J矩阵具有稀疏的性质,因为每一个观测量相关的系统状态量很少(每一行只填了很少),对于求解比较有利,稀疏性越好,求解速度越快。因子图生成的线性代数概率模型有很好的稀疏性,所以因子图求解这类问题效率很高。
额外说明:对于J矩阵,每一个变量摆在哪里,变量的顺序对于求解的性能有很大的关系,这就是线性系统求解的ordering的问题。对于不同的ordering,求解出来的上三角阵的稀疏程度不一样。通过调整变量元素的顺序(ordering),可以得到稀疏性比较好的矩阵,对于直接方法(QR分解),元素的ordering是很重要的。找最好的ordering是NP hard的问题, 现实生活中不会去找,因为非常慢。一些线性代数领域的专家,开发了找近似最优ordering的方法,比如COLAMD。

因子图的平滑增量优化特性
在机器人运行的过程,因子图往往是逐渐成长和增大的。比如说在往前移动的过程中,加了一组节点,随着观测的数据越来越多,加了越来越多的因子进来。 每一次求解都是比上次多一些因子,而且大部分因子图跟之前因子图是基本一致的,这是增量推理(incremental inference)。假设因子图只加了一点, 其他都没变,如果从零开始求解,矩阵会越来越大,求解速度会越来越慢,而且绝大多数都是重复性的工作。
如何避免这个问题?如何能够在求解状态变量越来越多的情况下引出一个近似常数。最常用的办法是isam,有isam1和isam2
isam1实际上做的是增量QR分解(Incremental QR Factorization):给定一个J矩阵,可以分解成Q和R,假设因子图其他都不变,之前的因子图还在,加了一些新的因子。每一个因子对应的是J矩阵的每一行,所以新加了几个因子,就是在J矩阵中增加了几行。问题就是如果在已知分解出来的QR的情况下,J增加了几行,如何快速算出R矩阵。
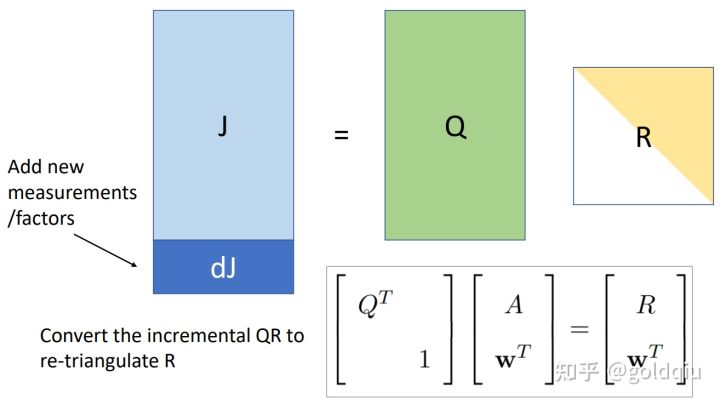
ISAM1论文公式中的A就是图中的J,如果A矩阵下面加一行(Wt),左边乘一个扩展的正交矩阵,右下角标一个1,就能够将增量的那一行加到R项。通过这个就能够将增量QR分解转化成增量三角化R的问题,就是如果R增加了几列,如何通过正交阵将矩阵重新变成三角阵。
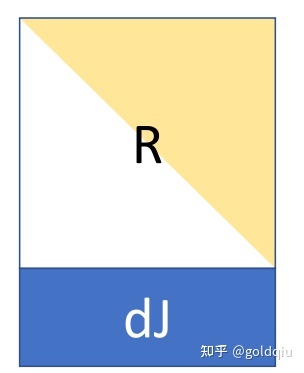
通过given rotation的办法:如果在R矩阵的下一列加了一个非零元素,左乘given旋转矩阵,可以将非零元素变成零元素,对应的代价是左乘后的矩阵那一行的0后面加了一些非零元素。一步一步做这个步骤,将这个行每一个元素右边的元素逐渐消为0,消到最后一个元素,得到的矩阵是一个密集的三角阵,大小是跟从哪里开始消元相关的。
特殊情况:比如机器人顺时针转圈,元素就普通得按时间ordering来排,假如新加了一个元素,建立了回环,机器人观测到一开始第一帧第二帧观测到的东西,变量会影响最开始的元素,会增加很大的密集三角阵。这样处理时间会很慢,内存也会比较大,所以需要定期进行reordering,重新排序,重新做QR分解,才会得到比较稀疏的R矩阵,计算速度才会比较快。
注意:ISAM1是讨论线性系统,求解因子图是用的迭代方法或线性代数的方法,实际上是增量做了每一步线性化求解的步骤,也就是做线性增量QR分解的过程中,线性化点没有变过。线性化点是影响系统求解精度(如求解卡尔曼滤波问题,线性化点很重要),而增量QR分解本身是不解决重线性化的问题,所以对于isam1,需要定期重排序,重线性化(定期更新),确保求解有一定精度。
isam2(利用贝叶斯树线性因子图推理):
将因子图转换成树状结构,如果是增加了少量因子(少量系统变量),只需要增加少许树上的节点,不需要重新求解整个树,速度比较快。如果遇到很大的回环,因为大部分变量都有触及,贝叶斯树中很多元素会被移动,有大量节点需要重新计算,所以无论isam1的增量QR分解和isam2的贝叶斯树,遇到大回环情况,也是需要重新求解。
贝叶斯树是理论最优的方法,isam1是偏经验的方法,贝叶斯实现起来比较难。可以根据需求选择isam1还是isam2。















 9461
9461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









