







小罗碎碎念
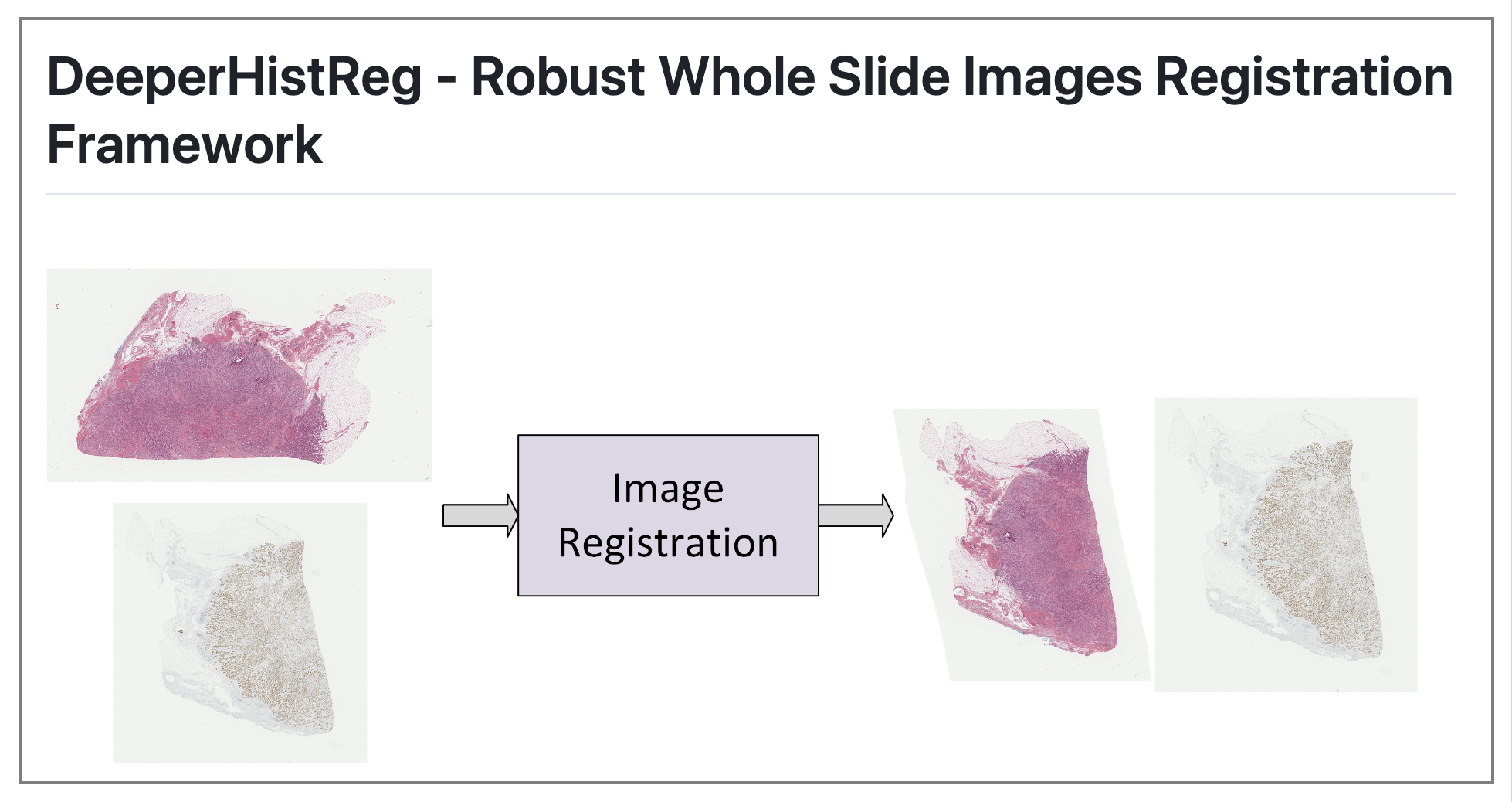
这篇文章介绍了一种名为RegWSI的全切片图像(WSI)自动配准方法,该方法结合了深度特征和基于强度的方法,并在ACROBAT 2023挑战赛中获得了第一名。

| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Marek Wodzinski | 西瑞士应用科学大学信息学研究所,波兰克拉科夫测量与电子系,帕多瓦大学神经科学系,日内瓦大学医学院 |
| 通讯作者 | Henning Müller | 西瑞士应用科学大学信息学研究所,日内瓦大学医学院 |
这项工作由Marek Wodzinski、Niccolò Marini、Manfredo Atzori和Henning Müller共同完成,他们提出了一种两步混合方法,包括基于深度学习和特征的初始对齐算法,以及基于强度的非刚性配准。这种方法不需要针对特定数据集进行微调,可以直接用于任何类型的组织和染色。配准时间短,适用于大型数据集的高效配准,并且作为开源软件发布。
文章评估了三种开放数据集:ANHIR、ACROBAT和HyReCo,并使用目标配准误差(TRE)作为评估指标。与现有的最先进解决方案相比,所提出的方法显示出显著的改进。
此外,文章还进行了几项消融研究,涉及配准分辨率、初始对齐的鲁棒性和稳定性。该方法在ACROBAT数据集上实现了最准确的结果,在HyReCo数据集上实现了细胞级配准精度,并且在ANHIR数据集上是评估的最佳方法之一。
文章所提出的方法在自动和鲁棒的WSI配准方面超越了其他最先进的解决方案,且该方法不需要针对特定数据集进行微调,并且可以用于多种显微镜图像。
该方法被整合到DeeperHistReg框架中,允许其他研究人员直接使用它来配准、转换和保存任何所需金字塔级别的WSI(分辨率高达220k x 220k)。
代码链接和数据集
-
代码链接:
- DeeperHistReg Library: https://github.com/MWod/DeeperHistReg/
-
数据集:
- ANHIR (Automatic Nonrigid Histological Image Registration Dataset): 这是一个用于评估WSI配准方法的数据集,包含481对图像,用于训练和评估配准算法。
- ACROBAT (Automatic Registration of Breast Cancer Tissue Dataset): 这个数据集包含乳腺癌临床切片,用于配准方法的验证。
- HyReCo (Hybrid Restained and Consecutive Histological Serial Sections Dataset): 包含连续和重新染色的组织切片,用于评估配准方法在不同情况下的表现。
一、引言
在数字病理学领域,全切片图像(WSIs)的自动配准对于多个下游应用至关重要,包括多模态诊断预测、注释传递以及连续切片的三维重建。
然而,提出一种无需针对特定数据集进行微调或超参数适配的自动、稳健且高效的WSI配准方法具有挑战性。这些挑战包括:
- 不同医疗中心使用不同设备、染料和采集协议导致的高异质性和质量差异
- 无法假设已配准WSIs的相对方向,导致学习型方法需要较大的感受野
- WSIs的高分辨率与相对较低的计算复杂性的需求之间的矛盾
数字病理学中的数据异质性极大,样本来自人体几乎所有部位以及其他物种,遵循不同采集中心的标准进行制备,并使用各种扫描仪进行数字化。
样本质量差异大,存在大量潜在的人工痕迹。这些因素要求数字病理学算法具有高度泛化能力。当前最先进的WSI配准方法仍需对学习型解决方案进行微调,或对传统迭代方法进行超参数调整。
与放射学不同,在数字病理学中,无法假设已配准图像的初始方向和空间偏移。
因此,传统的基于强度的方法通常失效,使得WSIs的初始对齐变得极具挑战性。这一问题对学习型方法的影响更大,导致需要大感受野,限制了CNN架构的有效性。
WSIs的高分辨率使得高效配准变得困难。WSIs通常以金字塔格式保存,最高分辨率超过200k x 200k像素。这使得WSIs的大小远超过高分辨率的CT或MR三维体积,导致计算复杂度显著增加。
考虑到配准通常是下游任务之前的初始处理步骤,配准时间应相对较短。对于连续切片,可以通过合理的下采样来缓解问题,但对于重新染色的切片,应保持高分辨率以实现细胞级别的配准精度。
二、相关研究工作总结
在全切片图像(WSI)自动配准领域,已有众多贡献,包括开放数据集的可用性以及方法学上的进展。
目前存在三个主要的开放数据集用于评估WSI配准的进展:ANHIR数据集、ACROBAT挑战赛数据集和HyReCo数据集。这些数据集涵盖了多种组织类型、染料和不同的质量水平,为研究者提供了评估配准算法性能的多样本【1】【8】【9】【10】【11】。
医学图像配准是一个具有显著贡献的研究领域,但由于WSIs的特殊挑战,通用配准方法通常失效【14-24】。针对WSIs的特定贡献是必要的,其中最成功的两种方法是HistokatFusion和VALIS,均基于传统的迭代图像配准【26】【27】。此外,还有其他基于经典算法的科学贡献,但实际应用中并不直接有用【28-33】。
深度学习方法在WSI配准方面也有贡献,如TUB方法、DeepHistReg方法以及CNN引导的结构特征方法等【34】【35】【36】【37】。近期研究尝试解决WSI的初始对齐问题,使用变换器来增加感受野,以及提出端到端的仿射配准方法【38】【39】【40】。
当前最先进配准算法的局限性
- 大多数方法仅使用单个数据集进行评估,且很少来自不同采集中心;
- 算法需要对新数据集进行微调或超参数调整;
- 初始对齐不稳健,导致许多失败;
- 源代码很少公开,不允许其他研究者直接复制实验或在实际应用中使用这些方法。
在本研究中,作者解决了以下局限性:
- 在多个不同医疗中心采集的数据集上评估了提出的方法,并显示出良好的稳定性和泛化能力;
- 提出的方法不需要对任何新数据集进行微调、重新训练或参数调整;
- 初始对齐方法在几乎所有情况下都能正确工作;
- 作者公开发布了源代码,并将其纳入DeeperHistReg框架,允许其他人在研究和实际应用中使用该算法。
三、方法
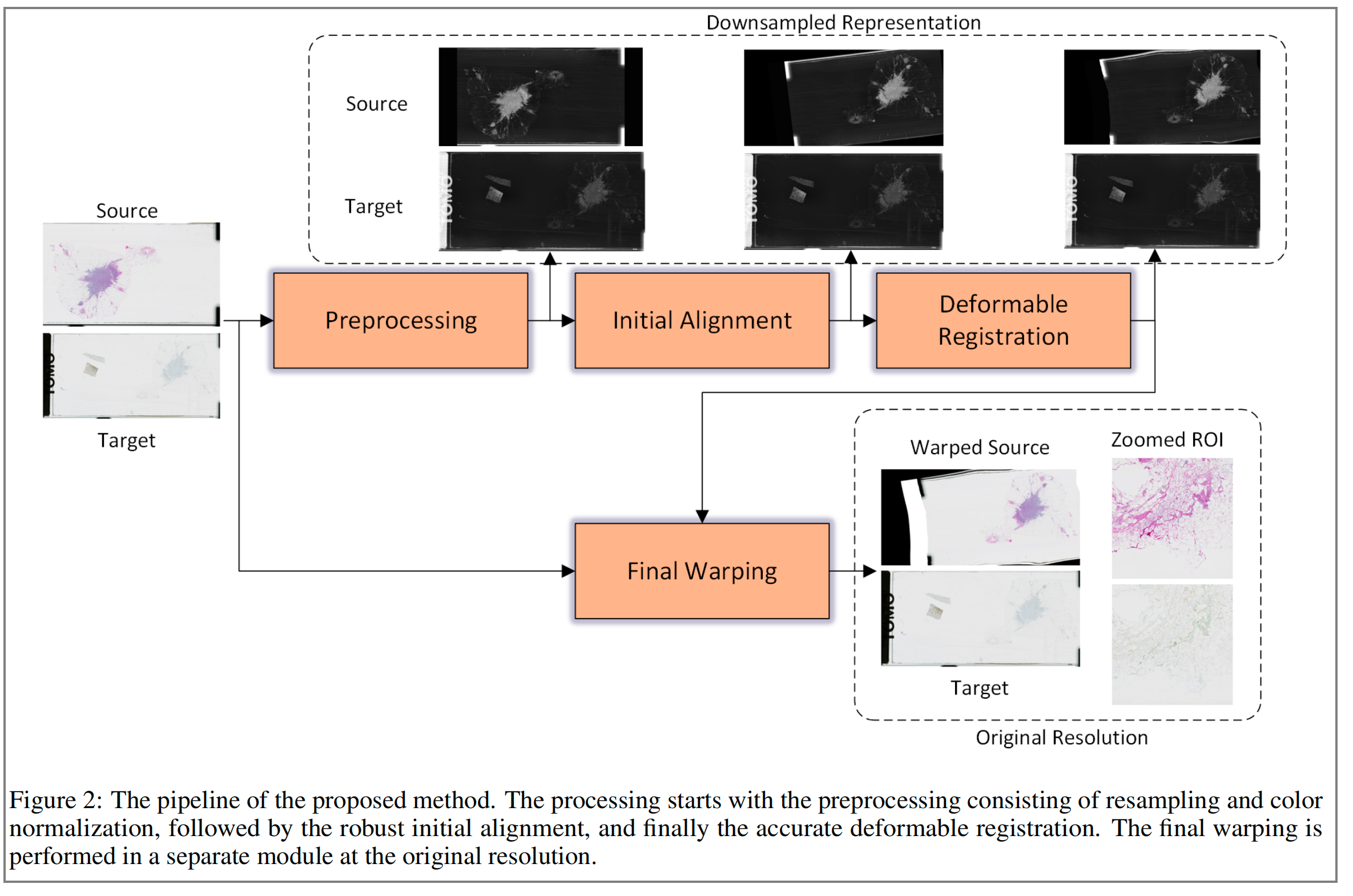
本研究提出的方法分为三个步骤:预处理、初始对齐和可变形配准。
- 预处理旨在将输入图像转换到相同的颜色空间,并重采样到后续配准步骤所需的分辨率。
- 初始对齐通过寻找全局仿射变换来大致匹配图像。
- 可变形配准计算密集位移场,以恢复更复杂和非刚性的变形。
流程图
-
输入图像:
- 左上角显示了两幅图像,分别标记为“Source”(源图像)和“Target”(目标图像)。
-
预处理(Preprocessing):
- 预处理步骤包括重采样(resampling)和颜色归一化(color normalization)。重采样是为了调整图像的分辨率,使其适合后续处理。颜色归一化则是为了统一图像的颜色特征,减少不同图像间的颜色差异。
-
初始对齐(Initial Alignment):
- 在预处理之后,进行初始对齐。这一步是为了快速找到源图像和目标图像之间的大致对应关系,为后续的精细对齐提供基础。
-
可变形配准(Deformable Registration):
- 初始对齐后,进行可变形配准。这一步涉及到更精细的调整,允许图像中的某些部分进行非刚性变换,以更好地匹配目标图像。
-
最终变形(Final Warping):
- 在可变形配准之后,进行最终变形。这一步是在原始分辨率下进行的,以确保变形的精确性。最终变形的结果是源图像被调整到与目标图像完全对齐。
-
输出图像:
- 最终,源图像被变形并叠加在目标图像上,形成一幅新的图像,其中源图像的感兴趣区域(ROI)被放大显示,以便于观察配准效果。
-
流程总结:
- 整个流程从预处理开始,通过初始对齐和可变形配准,最终在原始分辨率下完成最终变形。这种方法适用于需要高精度对齐的图像处理任务,如医学图像分析。
这个流程图清晰地展示了图像配准的各个步骤,以及它们是如何相互关联的。通过这种分步处理,可以有效地提高图像配准的准确性和效率。
3-1:预处理
预处理首先自动估计金字塔层级,然后根据非刚性配准步骤所需的分辨率进行加载和重采样。
选择最接近所需分辨率的高分辨率层级,然后加载图像并进行重采样。这种方法限制了计算复杂度,因为初始下采样使用的是相对相似的分辨率。初始加载和重采样采用PyVips [41]基于块的方法实现。
由于输入图像可能存储在不支持金字塔表示的格式中,因此初始下采样是必要的。对于此类情况,如果对每个流程步骤执行基于块的下采样,将显著增加配准时间。
接下来,将图像转换为灰度,归一化到[0-1]范围,并使用CLAHE算法处理两个图像。最后,图像再次重采样到初始对齐步骤配置中定义的分辨率,在此之前进行高斯平滑以避免混叠。
由于插值仅执行下采样,并且最多应用两次,因此插值误差可以忽略不计。
3-2:初始对齐
初始对齐基于预训练的SuperPoint和SuperGlue方法 [42, 43]。
SuperPoint负责特征提取,SuperGlue负责特征配对。配对的特征用于通过最小二乘法计算仿射变换矩阵。重要的是,SuperPoint和SuperGlue算法并未针对组织学数据进行微调。基于自监督学习的训练权重直接用于计算和匹配特征,这证实了SuperPoint特征提取器的优越泛化能力。
然而,SuperPoint和SuperGlue方法不具备方向和尺度不变性。因此,作者通过将它们嵌入到一个流程中,首先将源图像和目标图像重采样到给定分辨率(以在不同尺度上提取特征),然后以给定角度旋转源图像以提高对初始方向的鲁棒性,从而扩展这些方法。
接着,对每个尺度和方向重复执行特征提取和配对。选择由SuperGlue计算匹配数量最多的结果作为最终结果。对最佳尺度和初始方向进行穷尽搜索对于提高初始对齐的鲁棒性至关重要,使其适用于各种数据集。
尽管对于高质量数据集,单一尺度和方向可能足够,但对于质量较差和含有伪影的情况,穷尽方法对鲁棒性有积极影响。
初始对齐过程如图3所示。
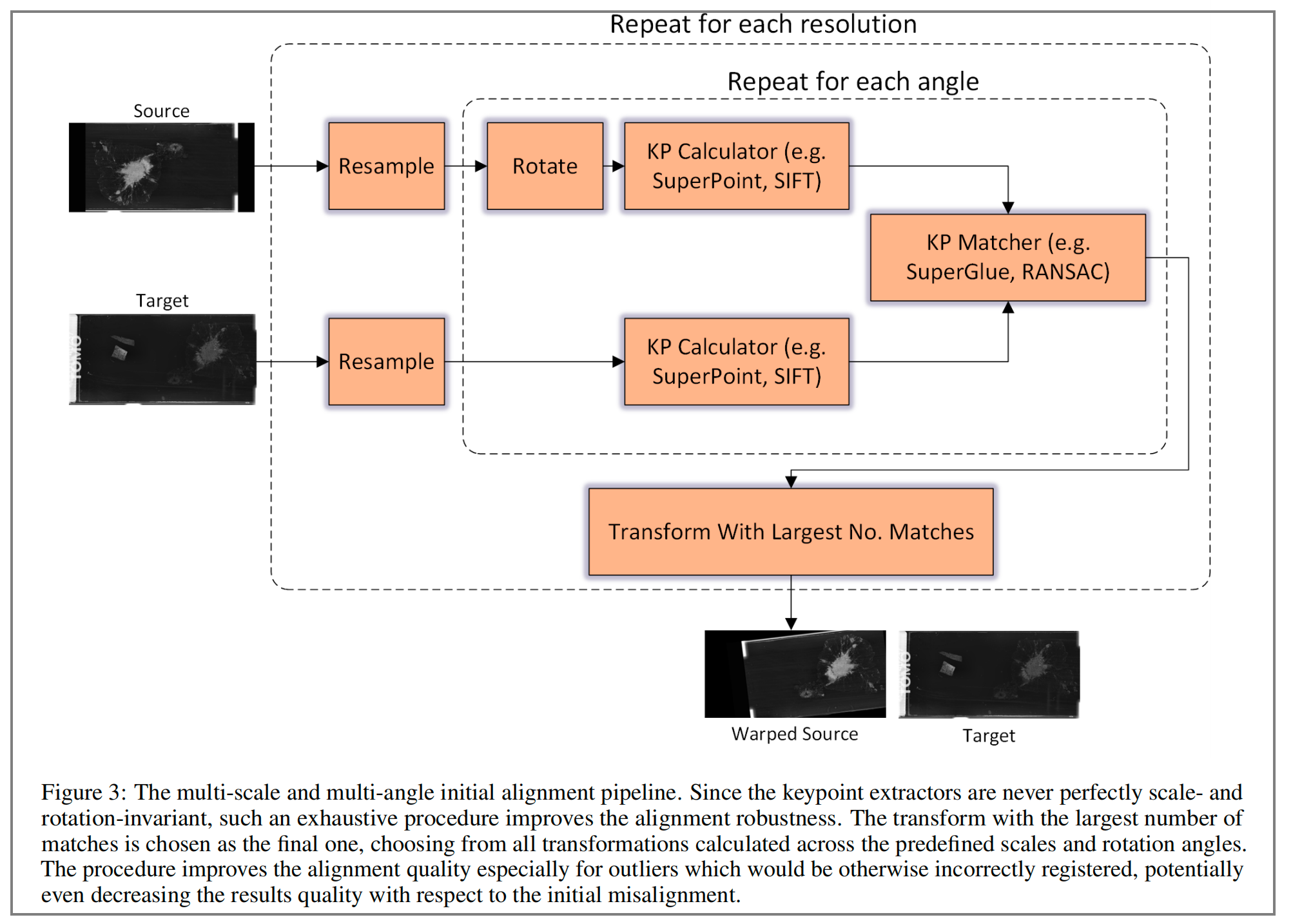
- 输入图像:
- 图中显示了两幅图像,分别标记为“Source”(源图像)和“Target”(目标图像)。
- 重采样(Resample):
- 对源图像和目标图像进行重采样,以生成不同分辨率的图像。这是多尺度处理的一部分,有助于在不同尺度上寻找最佳对齐。
- 旋转(Rotate):
- 对重采样后的图像进行旋转,以生成不同角度的图像。这是多角度处理的一部分,有助于在不同角度上寻找最佳对齐。
- 关键点计算器(KP Calculator):
- 使用关键点检测算法(如SuperPoint或SIFT)在旋转后的图像上计算关键点。关键点是图像中具有独特特征的点,用于后续的匹配。
- 关键点匹配器(KP Matcher):
- 使用关键点匹配算法(如SuperGlue或RANSAC)在源图像和目标图像的关键点之间寻找匹配。RANSAC是一种用于从包含噪声的数据中估计数学模型参数的迭代方法,它可以提高匹配的准确性。
- 重复每个分辨率和角度:
- 对于每个分辨率和每个角度,重复上述过程。这意味着在不同的尺度和角度上,都会进行关键点的计算和匹配。
- 选择最佳变换:
- 从所有预定义的尺度和旋转角度计算出的所有变换中,选择匹配数量最多的变换作为最终的变换。这表明该变换在多个尺度和角度上都能提供最佳的对齐效果。
- 应用变换:
- 将选定的变换应用于源图像,得到变换后的源图像(Warped Source)。
- 输出图像:
- 最终,变换后的源图像与目标图像进行比较,以评估对齐的质量。
这种方法特别适用于关键点提取器不是完全尺度和旋转不变的场景,通过穷举的方式,可以更全面地考虑不同条件下的对齐效果,从而选择最佳的对齐方案。
3-3:非刚性配准
非刚性配准实现为一个基于多层级实例优化的迭代算法。
目标函数定义为局部归一化互相关(NCC)作为相似性度量的加权求和,以及扩散正则化作为正则项,具体如下:
O
REG
(
S
,
T
,
u
)
=
NCC
(
S
i
∘
u
i
,
T
i
)
+
θ
i
Reg
(
u
i
)
,
O_{\text{REG}}(S, T, u) = \text{NCC}(S_i \circ u_i, T_i) + \theta_i \text{Reg}(u_i),
OREG(S,T,u)=NCC(Si∘ui,Ti)+θiReg(ui),
其中,( S_i ) 和 ( T_i ) 分别表示第 ( i ) 层分辨率水平上的源和目标切片,( u_i ) 是计算得到的位移场,( \theta_i ) 表示第 ( i ) 层分辨率水平上的正则化系数,NCC 表示归一化互相关,Reg 是扩散正则化,( \circ ) 表示变形操作,N 是分辨率水平数。
作者选择局部 NCC 作为相似性度量,因为与 CT/MRI 配准不同,局部对比度的变化可以通过互相关准确捕捉。此外,作者最近的研究证实了 NCC 在组织学配准中的巨大潜力,其性能优于多模态指标,如模态独立邻域描述符、互信息或归一化梯度场 [44, 8, 30, 35]。
非刚性配准从使用初始对齐步骤中找到的变换来变形源图像开始。
通过将仿射矩阵转换为位移场并执行双三次插值来实现变形。作者选择这种方法是因为用仿射变换初始化位移场影响了扩散正则化项,并期望优化器具有更大的感受野。
理论上,作者可以通过使用曲率正则化来避免这种情况,然而,初步消融实验证实,曲率正则化会降低结果质量,并且比扩散正则化更容易产生折叠。
此外,所提出的初始对齐步骤是稳健且有效的,因此可以作为可变形配准的初始状态。非刚性配准的结果被保存,并可以通过使用基于 B-样条的升采样在任何所需的分辨率水平上用于变换源图像。
所有超参数都可以分别为每个分辨率水平进行调整。
相似性度量和正则化的相对权重可以为每个分辨率分别设置,这是有意义的,因为在更高分辨率上,应增加正则化的权重以避免组织折叠。
学习率也是如此,在粗分辨率上较高,然后在分辨率增加时降低。迭代次数在配准设置中预定义,没有早期停止机制。作者决定使用固定数量的迭代,因为调整这个参数需要与最佳正则化系数和学习率的组合网格搜索,这超出了作者基础设施的计算能力以及 Grand-Challenge 平台的评估可能性。
此外,这种超参数调整需要针对每个数据集分别进行。因此,作者决定设置固定参数,并展示所提出方法的鲁棒性,因为其准确性在没有任何专门超参数调整的情况下优于其他方法。
3-4:数据集
评估使用了三个公开数据集:
- (i) 自动非刚性组织学图像配准数据集(ANHIR)
- (ii) 自动乳腺肿瘤组织配准数据集(ACROBAT)
- (iii) 混合染色和连续组织学连续切片数据集(HyReCo)。
每个数据集的代表性配准对如图1所示。
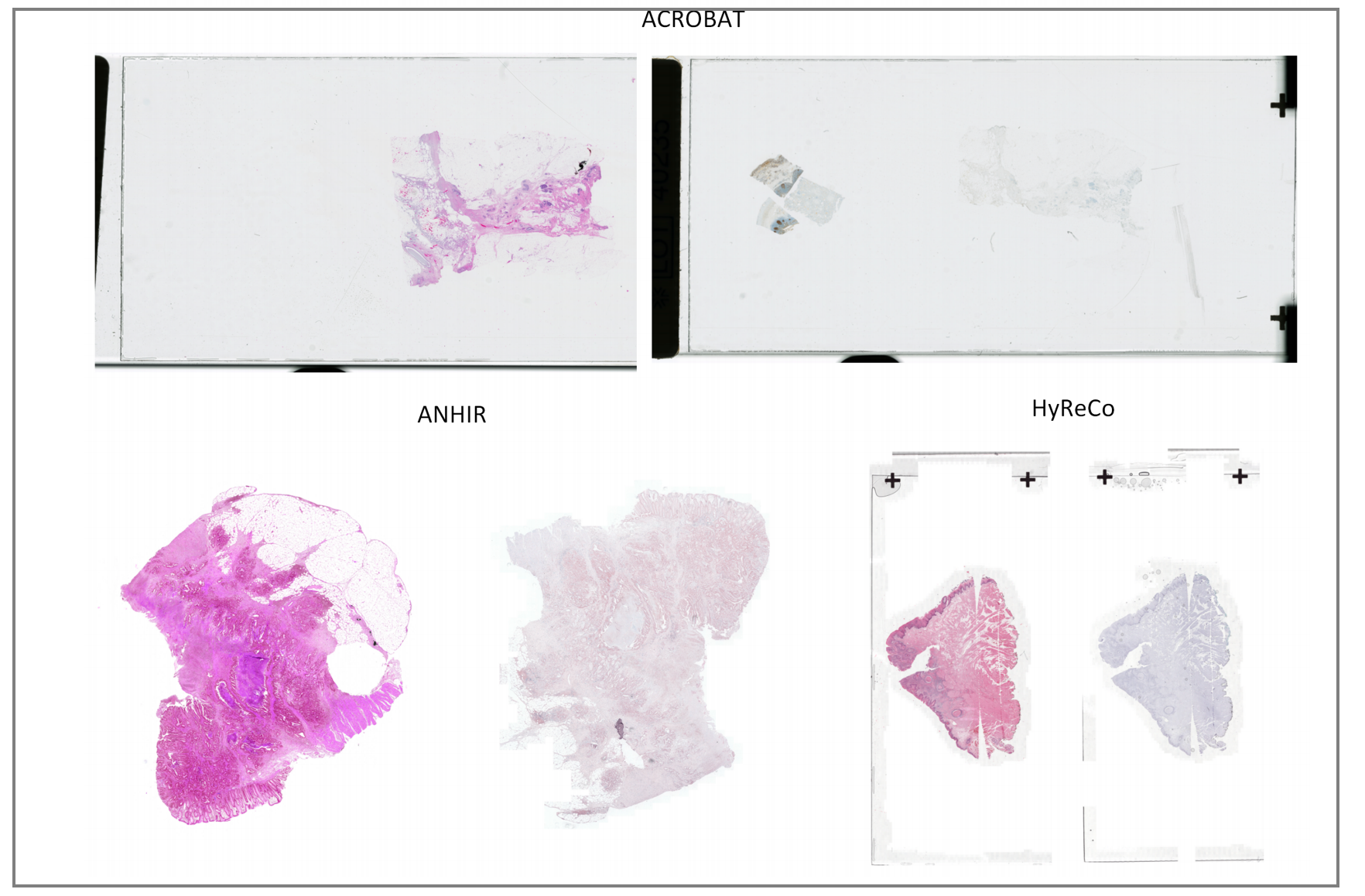
ANHIR数据集
ANHIR数据集包含481对图像,分为230对训练集和251对评估集[1, 45, 46, 47, 48]。值得注意的是,ANHIR数据集和评估集存在偏差,几乎一半的数据集需要从评估中排除。
尽管系统中的结果在训练集和评估子集中进行了汇总,但训练集的注释是公开发布的。因此,为了进行公平比较,作者从ANHIR数据集中排除了所有训练对(N=230)。评估是使用ANHIR组织者提供的脚本[44]在服务器端自动进行的。观察者间变异性为图像大小的0.05%,这可以作为自动配准方法可能达到的最佳性能的指标,低于此值的方法将无法区分[1]。
图像以.jpg和.png格式提供,没有分辨率金字塔和元数据。数据集中有8种不同的组织类型,使用了10种不同的染料进行染色。关于数据集的完整描述可以在[1]中找到。
ACROBAT数据集
ACROBAT数据集包含连续的女性乳腺癌切片。训练、验证和测试案例分别为750、100和303个。
由于案例使用了苏木精-伊红(H&E)、ER、KI67、PGR和HER2进行染色,因此训练、验证和测试的WSIs分别为3406个(训练案例使用了多种染料)。
WSIs是通过一台NanoZoomer S360和两台不同的NanoZoomer XRs获取的。图像以10X放大倍率保存并发布为.tiff格式,从原始40X缩小。数据集由13位经验丰富的个体在原始40X尺度上进行注释。
在本文中,评估是在100个隐藏的验证对上使用ACROBAT评估平台[49]进行的。遗憾的是,303个测试案例是隐藏的,并未公开发布。ACROBAT数据集的描述可以在[8, 9]中找到。
HyReCo数据集
HyReCo数据集于2021年发布,其独特之处在于提供了连续和重新染色的切片。该数据集在Radboud大学医学中心获取,并由Fraunhofer MEVIS的经验丰富的研究人员进行注释。
数据集包含9个高分辨率的连续切片,每个切片用H&E、CD8、CD45和KI67进行染色。每个切片有11到19个注释地标,每种染色产生138个注释,总共690个注释。
地标由两位经验丰富的研究人员放置并验证。额外的切片使用PHH3重新染色,产生了54对重新染色的H&E/PHH3,每对大约有43个注释。
切片以BigTIFF格式保存并发布,相应的地标在CSV文件中发布。HyReCo数据集及其完整描述可在[10, 11]中找到。
3-5:实验设置
作者将提出的方法与现有最先进解决方案进行了比较。
目标配准误差(TRE)被用作评估指标。对于ACROBAT和HyReCo数据集,作者报告物理单位下的TRE,而对于ANHIR数据集,作者按照ANHIR数据集创建者引入的惯例,通过除以图像对角线(rTRE)进行归一化,以与其他报告结果的方法保持一致[1, 25]。
作者进行了几项消融研究,以确认方法的鲁棒性以及最关键超参数的影响。实验验证了以下方面:
- (i) 每个配准步骤的影响
- (ii) SuperPoint/SuperGlue方法与传统SIFT/RANSAC方法[30]的差异
- (iii) 旋转角度和分辨率数量对初始对齐稳定性的影响
- (iv) 分辨率对非刚性配准质量的影响,包括连续切片和重新染色切片
所有算法和实验均使用PyTorch库实现,并基于PyVips[41]进行了扩展。实验是在配备24 GB专用内存的NVIDIA RTX 3090 GPU上进行的。
提出的方法被集成到DeeperHistReg框架中,并已公开发布[7]。该方法不需要任何微调或重新训练即可用于其他数据集。
四、结果
4-1:仿射配准与非刚性配准比较
图5展示了每个配准步骤后的平均和中等TRE分布。
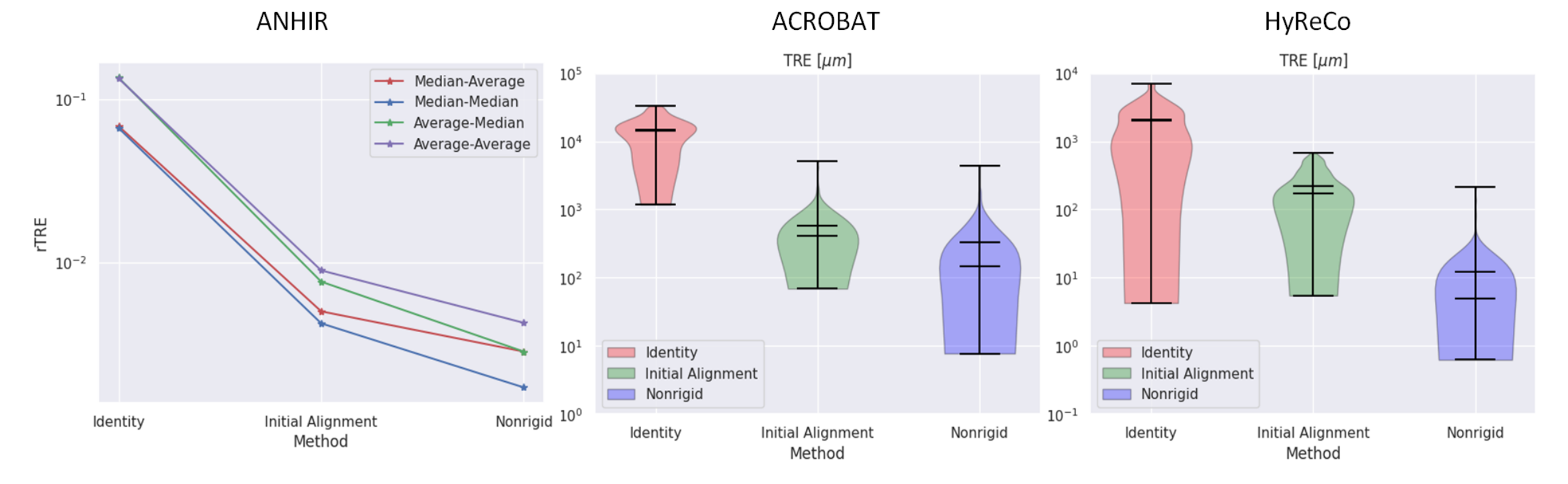
小提琴图中的刻度分别代表平均值和中等值。可以观察到,配准步骤提高了大多数配准对的齐准度,没有一例可以被认为是失败的(即配准后平均/中等TRE显著增加的情况)。
ANHIR数据集在配准前、仿射对齐后和非刚性配准后的中等-平均rTRE分别为0.0683、0.0050和0.0029。对于ACROBAT数据集,后续配准步骤后的中等TRE(以微米为单位)分别为14424.35、409.86和137.27。最后,对于HyReCo数据集,初始对齐和非刚性配准后的中等TRE(以微米为单位)分别为174.90、4.96(连续)和12.24、0.59(重新染色)。
这证实了每个配准步骤后的显著改进(p值<0.01)。每个算法步骤后的配准可视化示例见图4。
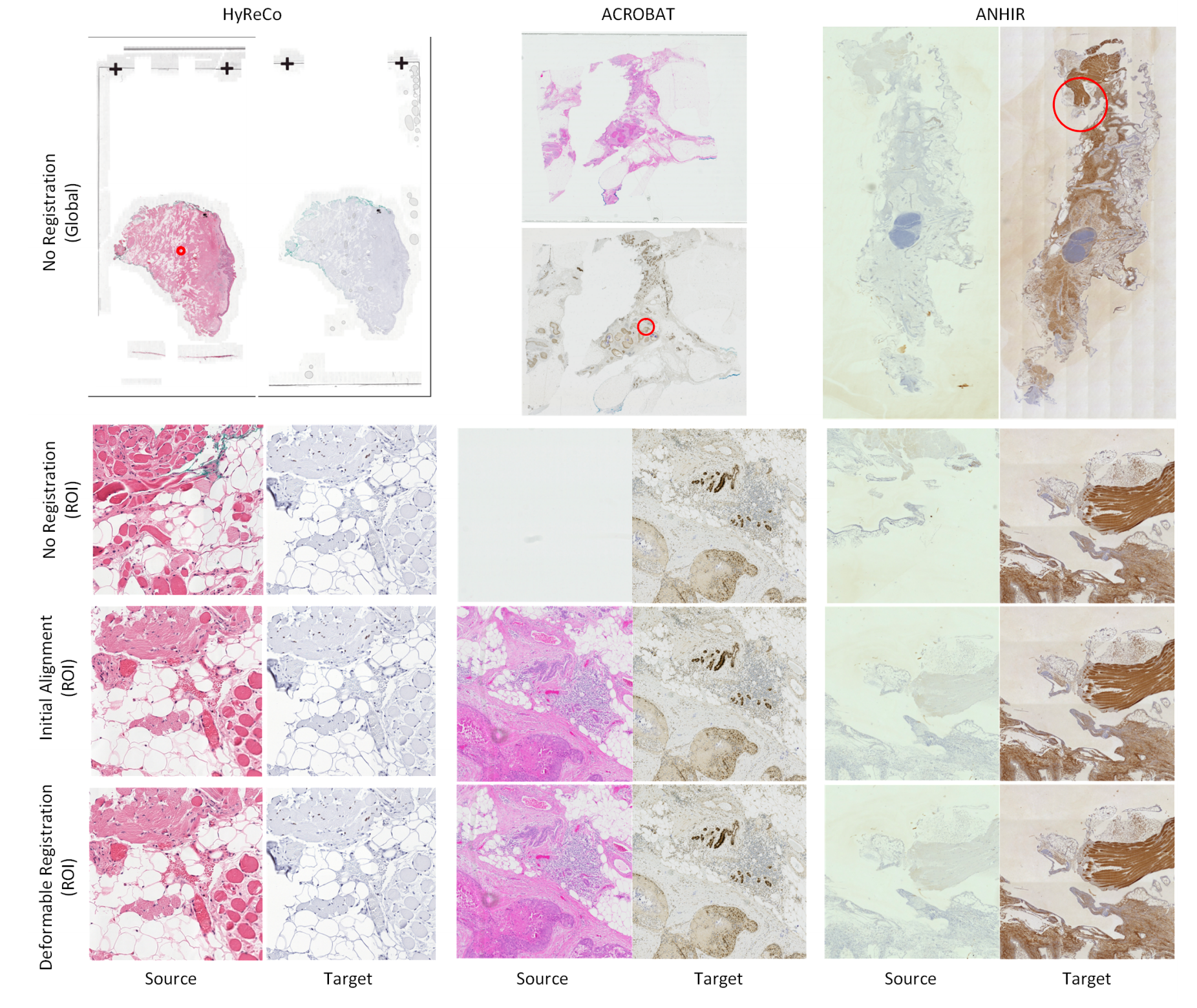
重要的是,所有非刚性实验中的折叠比例(定义为具有负雅可比矩阵的像素数与所有像素数的比率)低于0.1%。
4-2:SuperPoint-SuperGlue与SIFT-RANSAC比较
一项消融研究证实了新颖的SuperPoint/SuperGlue初始配准方法对现有最先进的SIFT/RANSAC方法的影响。
结果如图6所示。
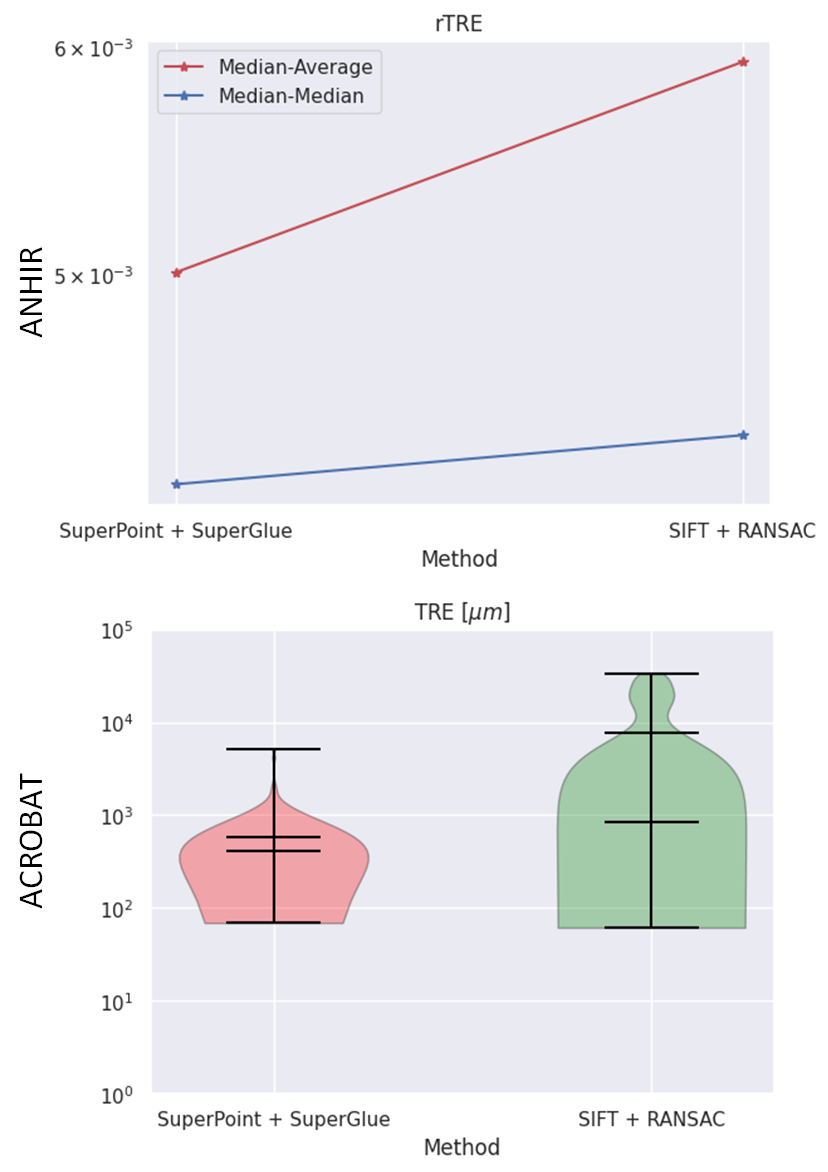
可以注意到,基于学习的方法更为鲁棒,没有出现SIFT/RANSAC方法中常见的失败情况。ANHIR数据集上SuperPoint/SuperGlue和SIFT+RANSAC的中等-平均rTRE分别为0.0050和0.0059。对于ACROBAT数据集,这两种方法的平均TRE(以微米为单位)分别为409.86和852.43。由于SIFT/RANSAC方法在HyReCo数据集上的失败率超过10%,因此省略了比较。
此外,提出的学习方法在计算上更为高效(大约15秒对比大约27秒),然而,考虑到后续非刚性配准和最终图像变形所需的时间,这种效果可以忽略不计。
4-3:角度数量和尺度数量的稳定性
关于尺度数量影响的实验结果展示在表1中
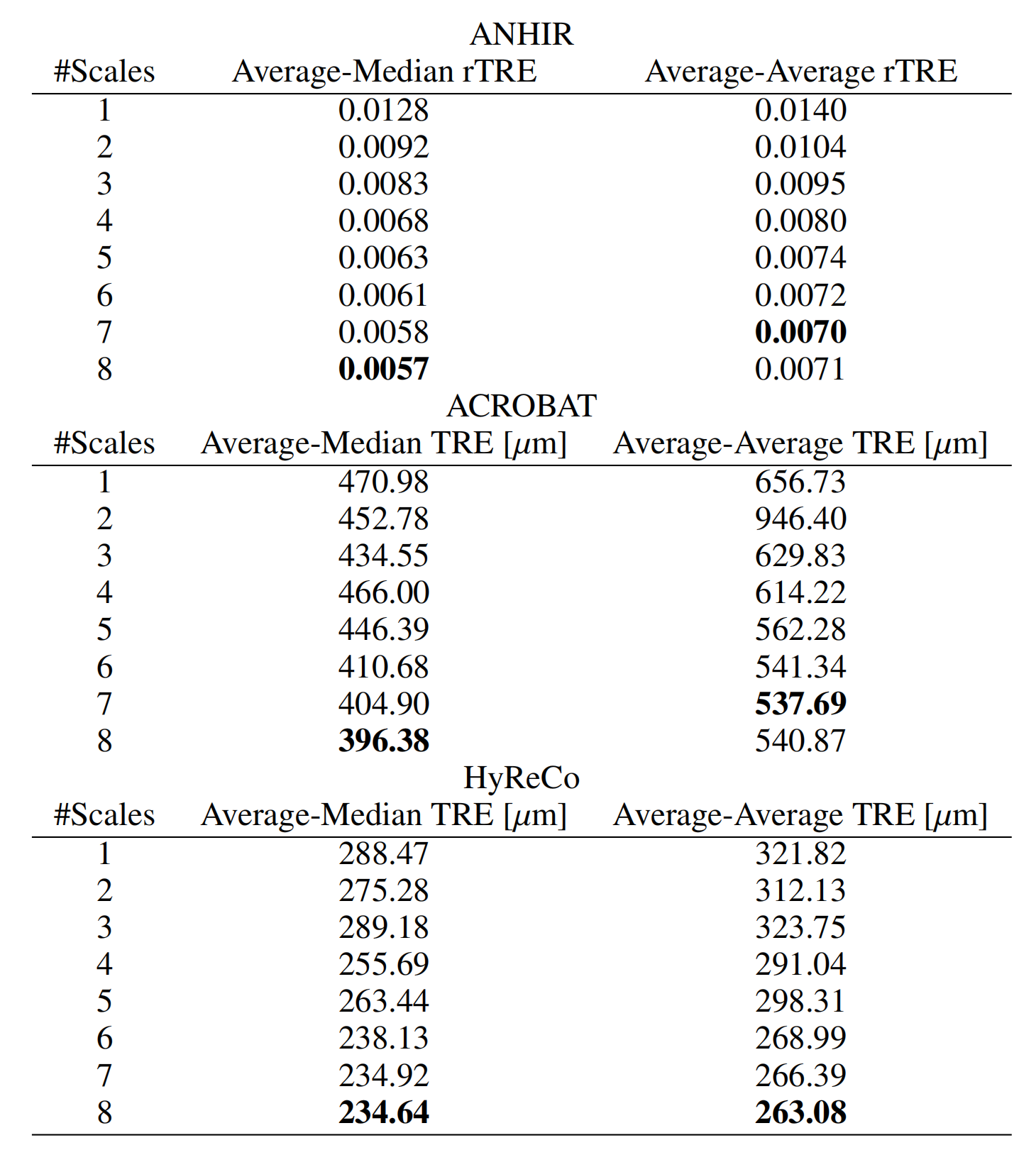
使用单一尺度与使用八个尺度之间的差异显著(ANHIR数据集的rTRE从0.0128降至0.0057,ACROBAT数据集的TRE从470.98微米降至396.38微米,HyReCo数据集的TRE从288.47微米降至232.64微米)。
旋转角度步长的影响展示在表2中
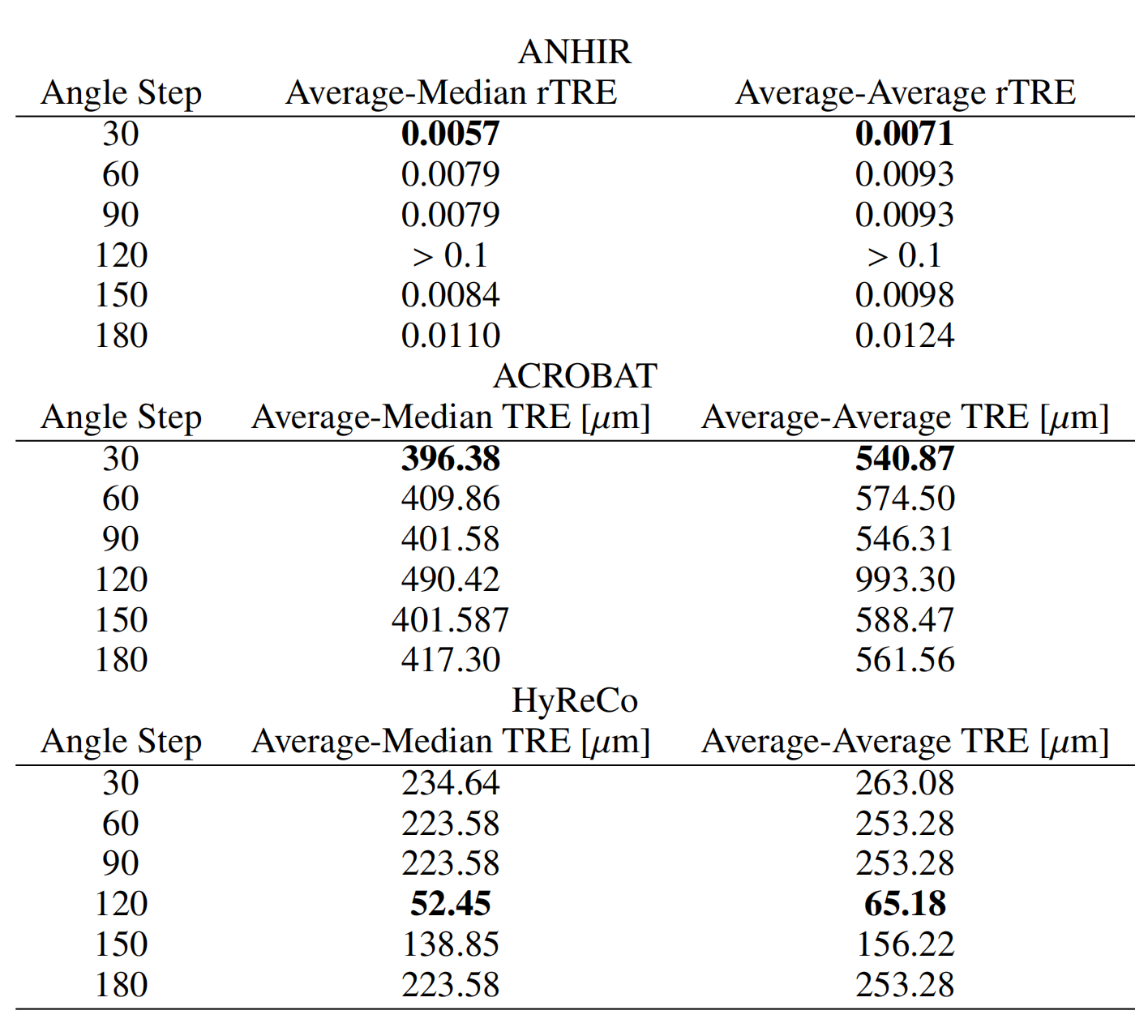
小角度步长(30度对比180度)同样具有显著影响(ANHIR数据集的rTRE从0.0057增至0.0110,ACROBAT数据集的TRE从396.38微米增至417.30微米),HyReCo数据集除外,其中…的稳定性,没有初始对齐的失败情况。
4-4:分辨率对连续切片和重新染色切片的影响
图7展示了配准分辨率对非刚性配准步骤的影响以及HyReCo数据集中连续切片与重新染色切片之间的比较
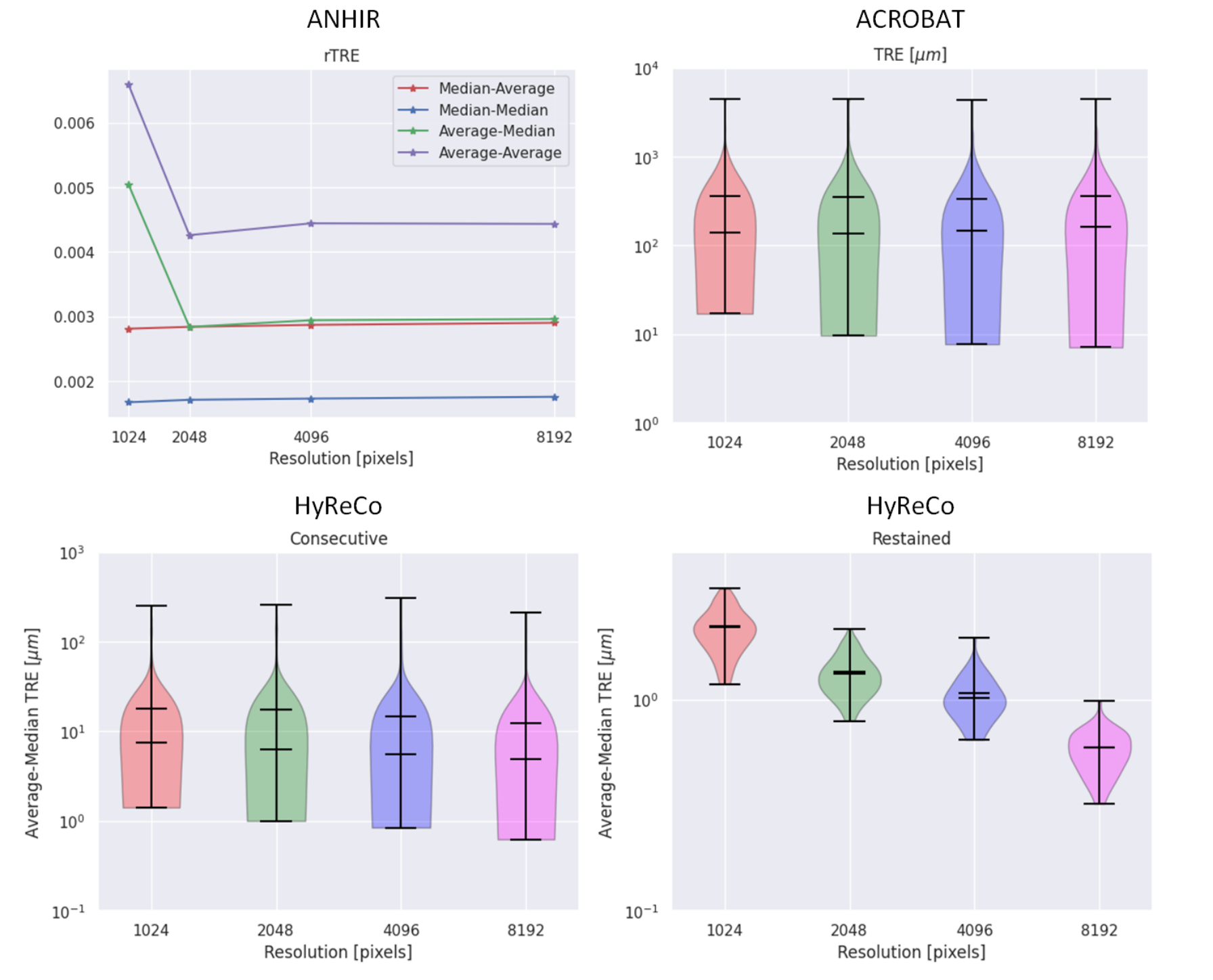
注意!这里仅报告了HyReCo数据集的连续切片与重新染色切片之间的比较,因为其他数据集仅包含连续切片。
可以注意到,对于连续切片,用于配准的分辨率影响较小,并且容易达到饱和(变化不显著),然而,对于重新染色的切片,进一步提高分辨率会继续显著(p值<0.01)改善配准质量(MTRE分别为2.20、1.33、1.01、0.59微米,对应的分辨率为10242、20482、40962、81922)。
因此,将配准分辨率提高到81922以上,仅对重新染色的切片有益,然而,由于GPU内存限制,这样的改变将需要采用基于补丁的配准方法。
五、讨论与结论
通过比较连续切片与重新染色切片的配准精度(如图7所示),可以得出一些有趣的观察结果,这些结果证实了HyReCo数据集创建者[10]的发现。提高配准分辨率显著降低了重新染色切片的TRE,然而对于连续切片,影响较小,进一步增加分辨率并不会改善结果。
尽管非刚性配准相较于初始仿射对齐显著提高了精度,但应注意到,对于连续切片,实现细胞级别的配准精度可能是挑战性的,甚至可能无法实现。
配准精度强烈依赖于切片质量,因此,为了尽可能实现精确配准,仔细准备切片至关重要。
初始对齐方法稳定且鲁棒,如图5和表1、表2所示。
在HyReCo数据集中,失败情况不显著,而在ANHIR和ACROBAT数据集中没有失败情况。初始对齐降低了ANHIR和ACROBAT数据集中所有配准对的初始TRE,仅增加了HyReCo数据集中包含多个组织切片的配准对的TRE。
表1、表2证实了多尺度和多角度方法的影响。尽管对于高质量切片并非必要,但它提高了低质量切片的稳定性。结果还显示,组织通常旋转0度、45度、90度、135度或180度。角度步长为60度或120度的实验产生了几个异常值。
有人可能会认为HyReCo数据集的初始对齐性能不佳,然而,事实证明,这对于连续切片和重新染色切片的后续可变形步骤并无影响。此外,性能不佳是由应在质量控制步骤中解决的问题引起的。
该算法具有几个优势。
背景分割[50, 51],作为其他贡献的预处理步骤,并非必要。背景分割通常降低了配准方法的鲁棒性和泛化能力,因为当前的分割基于学习技术。
对于苏木精-伊红(H&E)图像,问题可以认为是已解决的,然而,现有最先进方法在其他染色上仍存在困难,需要进一步改进。因此,通过使用基于特征的方法进行初始对齐,消除背景分割的必要性,提高了鲁棒性并消除了基于强度的流程中的易错部分。
另一个优势与该方法的高鲁棒性和泛化能力相关。尽管方法的某些部分基于学习,但它们不需要针对新数据集进行微调。实例优化方法通过设计,在推理时优化捕获了WSIs的异质性,而SuperPoint/SuperGlue方法以其高稳定性和可靠性而著称。
代码开源
作者公开发布了方法的源代码,并将其纳入DeeperHistReg框架,允许复现结果并在研究中使用该方法。该方法即开即用,用户只需克隆仓库,设置待配准图像的路径,并运行配准。这对于数字病理学领域是一个重大贡献,因为其他配准方法往往是闭源的,或者具有高门槛,需要终端用户具备配准专业知识。
重要的是,DeeperHistReg框架不仅允许执行配准,还可以加载任何OpenSlide兼容格式的图像,转换WSIs,并保存任何所需分辨率级别的输出。
作者的其他实验也证实了该方法适用于其他显微图像,例如未染色、DAPI染色或ExM图像,无需调整参数。
在未来的工作中,作者计划以几种方式扩展该方法。
首先,作者预测使用自监督学习在大组织学数据集上微调SuperPoint和SuperGlue方法,例如来自BigPicture联盟[52]的数据,可以进一步提高初始对齐的鲁棒性,并允许跳过多尺度和多方向步骤。此外,为体数据提出SuperPoint和SuperGlue方法的变体可能对放射学[15]中的初始对齐有益。
另一个作者计划探索的方向是使用染色标准化和转换来改进预处理步骤。源图像和目标图像的颜色空间标准化可能会显著影响可变形配准的质量。最后,非刚性配准处理复杂变形的困难可以通过专门用于恢复大位移的深度模型的神经实例优化来解决,例如LapIRN [16, 53]。
综上,作者提出了一种自动、稳健且精确的WSI配准方法。作者使用了三个公开数据集:ANHIR、ACROBAT和HyReCo对该方法进行了评估,执行了多项消融研究,并将其与其他最先进方法进行了比较。
作者免费发布了源代码,并将其纳入DeeperHistReg框架,允许其他研究人员在其研究中使用该方法,并轻松复现结果。提出的方法对数字病理学领域做出了重要贡献。


















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









