







小罗碎碎念
这篇文章聚焦于医学AI领域的前沿研究,提出了一种名为HistoGPT的视觉语言模型,旨在解决传统组织病理学报告生成耗时、标准化不足的问题。

模型通过结合视觉基础模型(如CTransPath和UNI)与大型语言模型(BioGPT),利用跨注意力机制实现从患者多张全分辨率组织全切片图像(WSIs)生成病理报告。
其训练数据来自6705例皮肤科患者的15,129张WSIs及对应报告,覆盖167种皮肤疾病,并通过两阶段训练(图像预训练和图文微调)提升性能,推理阶段采用集成优化(ER)方法增强报告的完整性和多样性。
在技术验证方面,HistoGPT展现出显著的临床价值与技术优势。自然语言处理指标和领域专家分析表明,其生成的报告质量与人类相当,尤其在常见恶性肿瘤的诊断中表现突出。
模型具备零样本预测能力,可准确推断肿瘤亚型、厚度及边缘状态,在国际多中心临床研究中,对不同扫描仪类型、染色协议和活检方法的外部队列均有良好泛化性。此外,通过梯度注意力图实现的文本-图像可视化解释,为模型决策提供了可追溯的病理依据,增强了医学AI的可信度。
研究同时指出,HistoGPT在罕见病诊断、复杂组织形态区分等场景仍存在局限性,未来需通过扩大训练数据多样性、优化视觉模块特征提取能力及引入人类反馈强化学习(RLHF)进一步提升。
该研究为医学AI在病理报告自动化领域的应用奠定了基础,其技术框架和多中心验证经验为后续泛癌种模型开发提供了参考,推动AI从辅助工具向临床决策支持系统的深度融合迈进。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量67,000+,交流群总成员1500+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
对推文中的内容感兴趣,想深入探讨?在处理项目时遇到了问题,无人商量?加入小罗的知识星球,寻找科研道路上的伙伴吧!
一、文献概述
本文介绍了由德国亥姆霍兹慕尼黑中心等机构开发的视觉语言模型HistoGPT,其核心功能是从高分辨率组织全切片图像(WSIs)生成皮肤科病理报告。

1-1:研究背景与目标
- 病理报告现状:传统病理报告依赖病理学家显微镜观察后手动撰写,耗时、耗力且标准化程度低。例如,基底细胞癌诊断仅需数秒,但撰写报告需更长时间。
- AI的潜力:现有AI模型多基于图像块分析(如PLIP、CONCH),无法处理全切片图像或生成完整文本报告。HistoGPT旨在填补这一空白,实现从全切片图像到结构化报告的端到端生成。
1-2:HistoGPT模型架构与训练
模型组成
- 视觉模块:采用CTransPath(小/中型模型)或UNI(大型模型)作为补丁编码器,提取图像特征。
- 语言模块:基于BioGPT(类似GPT-3架构),通过跨注意力机制(XATTN)融合视觉特征生成文本。
- 位置编码:大型模型引入三维位置嵌入,编码补丁的空间坐标和所属切片信息,提升空间感知能力。
训练数据
使用6705例皮肤科患者的15,129张全切片图像及对应报告(含167种皮肤病),覆盖基底细胞癌(BCC)、鳞状细胞癌(SCC)等常见恶性肿瘤及良性病变。
训练阶段
- 图像预训练:通过多实例学习(MIL)预训练视觉模块,预测患者诊断。
- 图文微调:冻结视觉模块,仅训练跨注意力层,结合GPT-4文本增强避免过拟合。
推理方法
采用集成优化(ER)生成多版本报告,通过GPT-4聚合结果,提升报告完整性和多样性。
1-3:关键能力与性能
病理报告生成质量:
- 语义匹配:生成报告与人类报告的关键词重叠率(Jaccard指数)达64%-67%,远超纯文本模型BioGPT-1B(44%)和GPT-4V(54%)。
- 专家评估:在双盲实验中,45%的病例中AI报告与人类报告无差异,15%的病例中AI报告更优,尤其在BCC、脂溢性角化病等常见疾病中表现突出。
零样本预测能力:
- 肿瘤特征预测:无需额外训练,可直接预测肿瘤厚度(RMSE=1.8 mm,皮尔逊相关系数0.52)、亚型(如BCC亚型加权F1=0.63)和手术切缘状态(F1=74%)。
- 跨中心泛化:在5个外部队列(不同国家、染色协议、活检类型)中,分类准确率达65%-98%,优于传统多实例学习模型(MIL)。
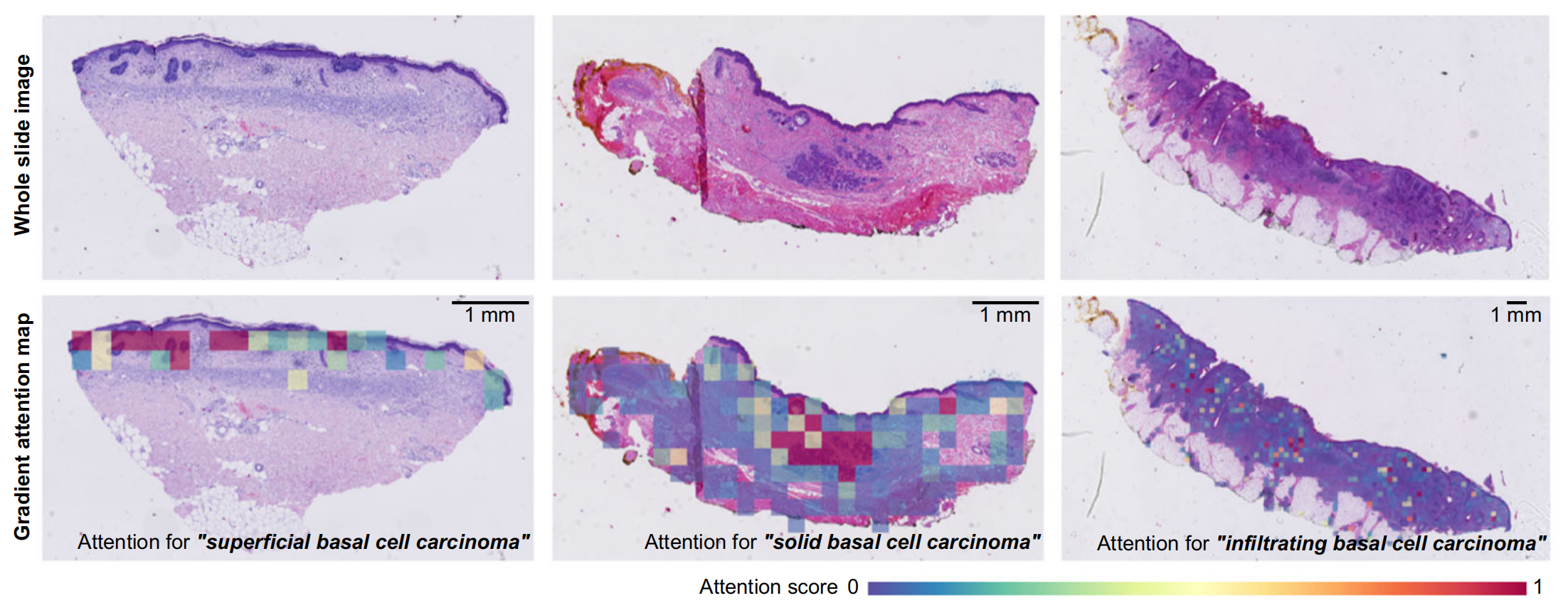
可解释性
通过梯度注意力图可视化文本与图像区域的对应关系,例如“基底细胞癌”关键词对应肿瘤区域的高注意力分数,提升模型透明度。
1-4:临床研究与局限性
- 多中心验证:在梅奥诊所、德国明斯特大学等3个机构的真实临床数据中,HistoGPT对常见肿瘤(如BCC、日光性角化病)的报告准确性评分≥3(满分5),但对罕见病(如炎症性疾病)或需临床信息的病例(如二次切除)表现较差。
- 局限性:
- 数据偏差:训练数据存在类不平衡,罕见病样本不足导致泛化能力有限。
- 视觉模块瓶颈:对相似形态的疾病(如 melanoma与SCC)易混淆,依赖更高分辨率图像或强化视觉特征区分能力。
- 临床适用性:目前为研究原型,未获医疗认证,需进一步大规模验证和伦理审查。
1-5:意义与未来方向
- 研究价值:HistoGPT首次实现从全切片图像生成临床级病理报告,结合零样本推理和可解释性,为病理学家提供高效辅助工具,尤其适用于标准化报告撰写和初步诊断。
- 未来优化:
- 引入人类反馈强化学习(RLHF)校准预测,提升临床相关性。
- 扩展至其他癌种(如乳腺癌、结直肠癌),构建泛癌病理模型。
- 探索多模态融合(如基因组数据),提升诊断全面性。
二、HistoGPT:一个用于皮肤病理学的基础视觉语言模型
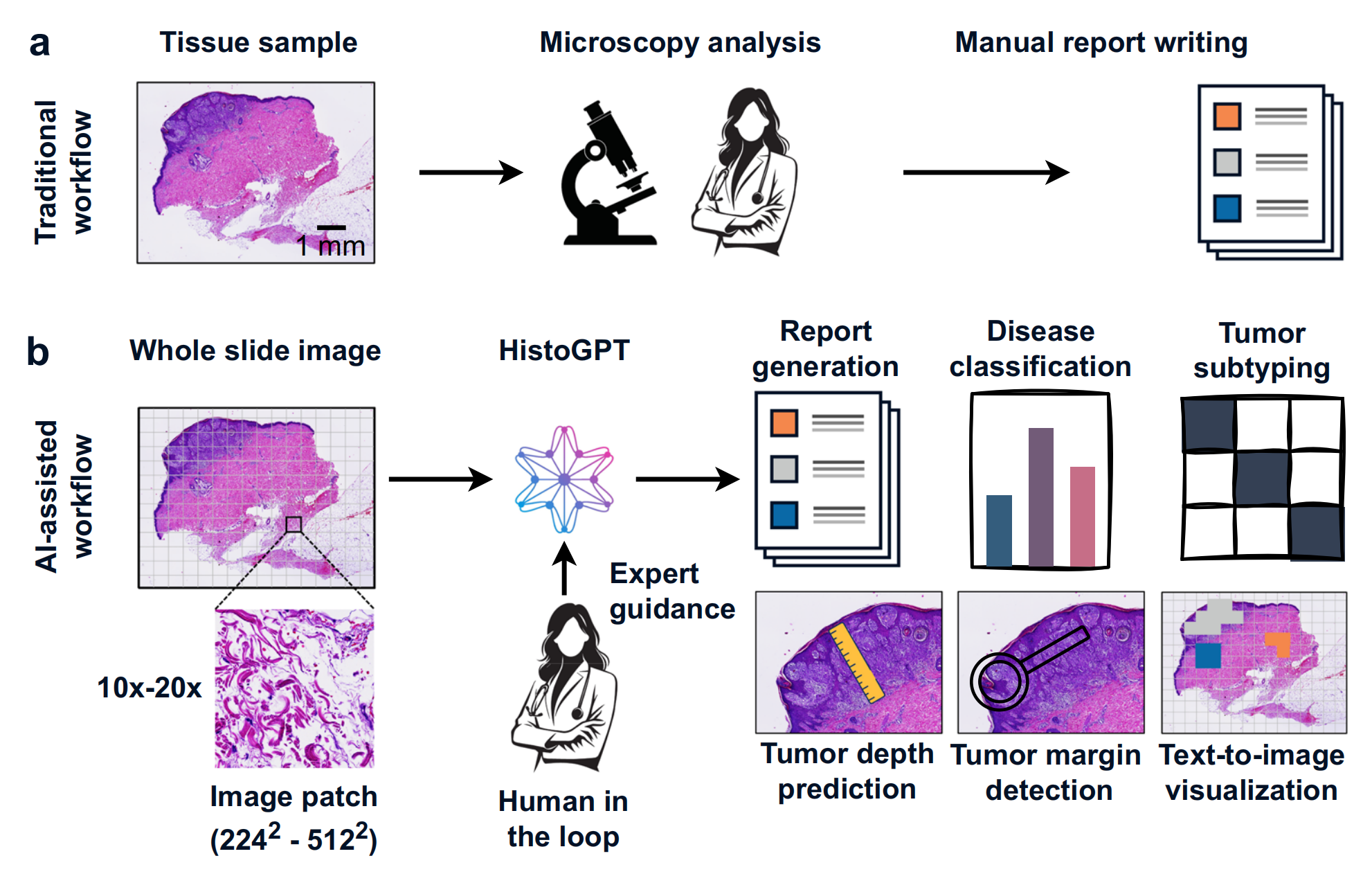
2-1:传统病理工作流程
传统病理诊断中,病理学家先对组织样本(Tissue sample)进行显微镜分析(Microscopy analysis) ,再手动撰写报告(Manual report writing) 。

此过程耗时费力,且因不同病理学家操作存在非标准化问题。
2-2:HistoGPT辅助的病理工作流程
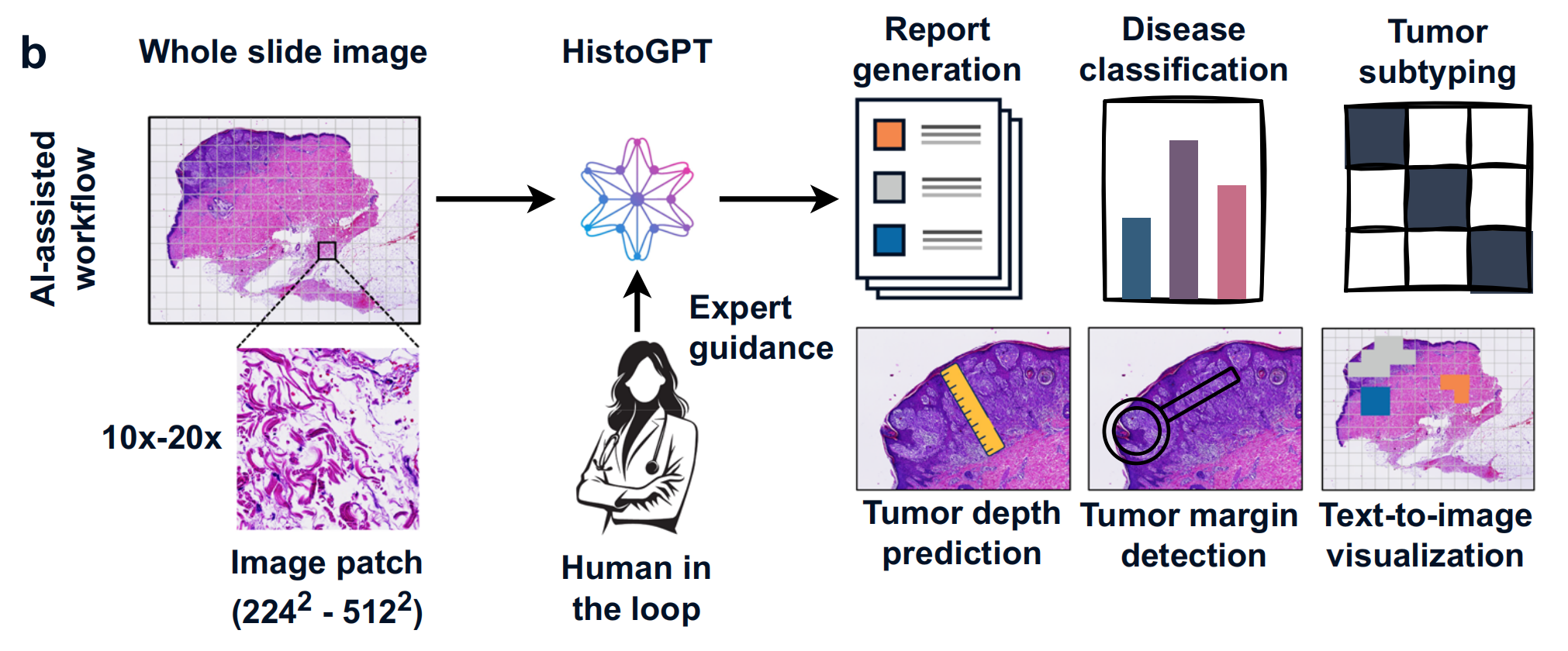
- 输入:将全切片图像(Whole slide image)输入HistoGPT ,图像会被分割成图像块(Image patch ,尺寸在224² - 512² )。
- 功能与输出:在专家指导(Expert guidance ,即 “人在回路” Human in the loop )下,HistoGPT可进行报告生成(Report generation) 、疾病分类(Disease classification) 、肿瘤亚型分类(Tumor subtyping) ,还能预测肿瘤深度(Tumor depth prediction) 、检测肿瘤边缘(Tumor margin detection) 以及实现文本到图像的可视化(Text - to - image visualization) ,提升模型可解释性,为病理学家提供辅助诊断参考。
2-3:HistoGPT生成的病理报告示例
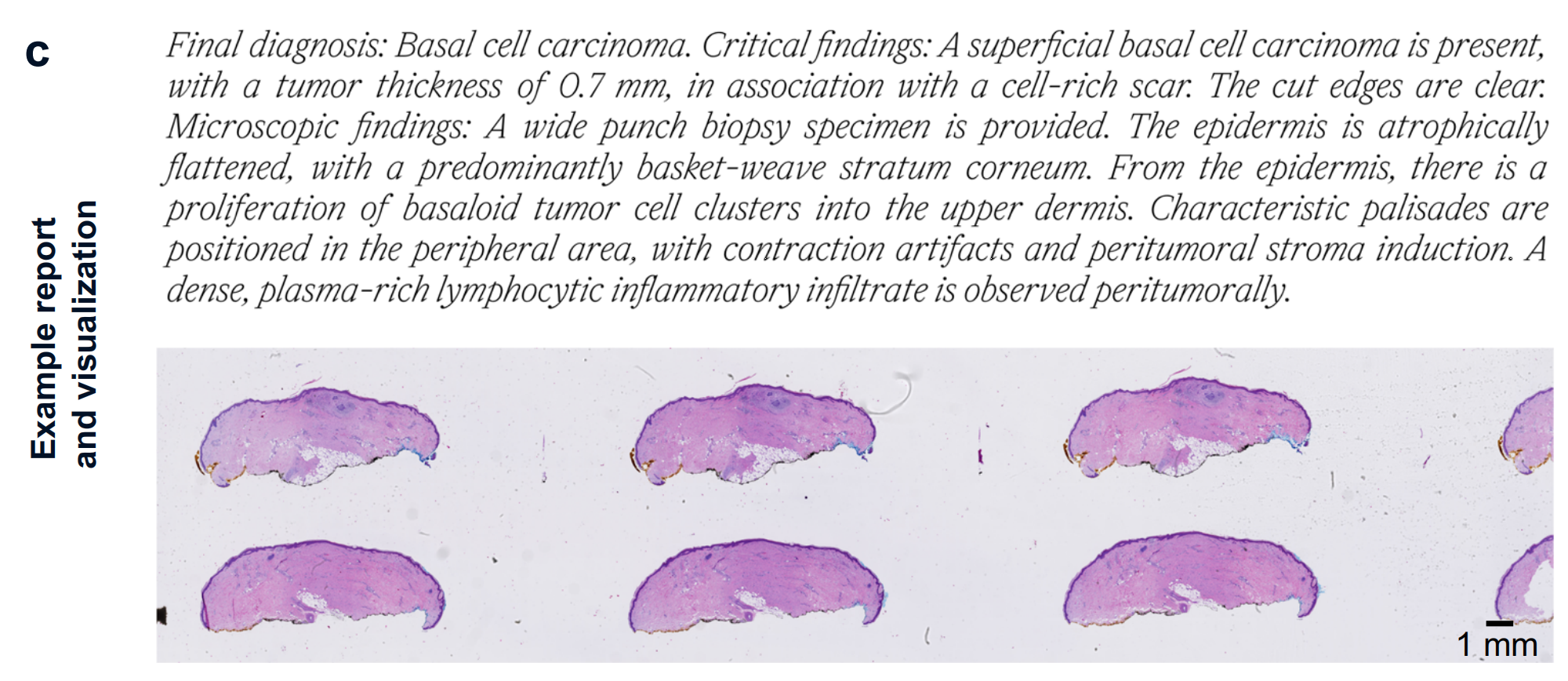
以基底细胞癌病例为例,报告包含最终诊断(Final diagnosis :基底细胞癌 )、关键发现(Critical findings :存在浅表性基底细胞癌,肿瘤厚度0.7毫米,伴有富细胞瘢痕,切缘清晰 )、微观发现(Microscopic findings :打孔活检标本,表皮萎缩,肿瘤细胞增殖模式等 )。
这些示例展示了HistoGPT生成报告的内容结构和详细程度,且报告可用于填充标准化模板,辅助病理诊断工作。
三、HistoGPT架构细节
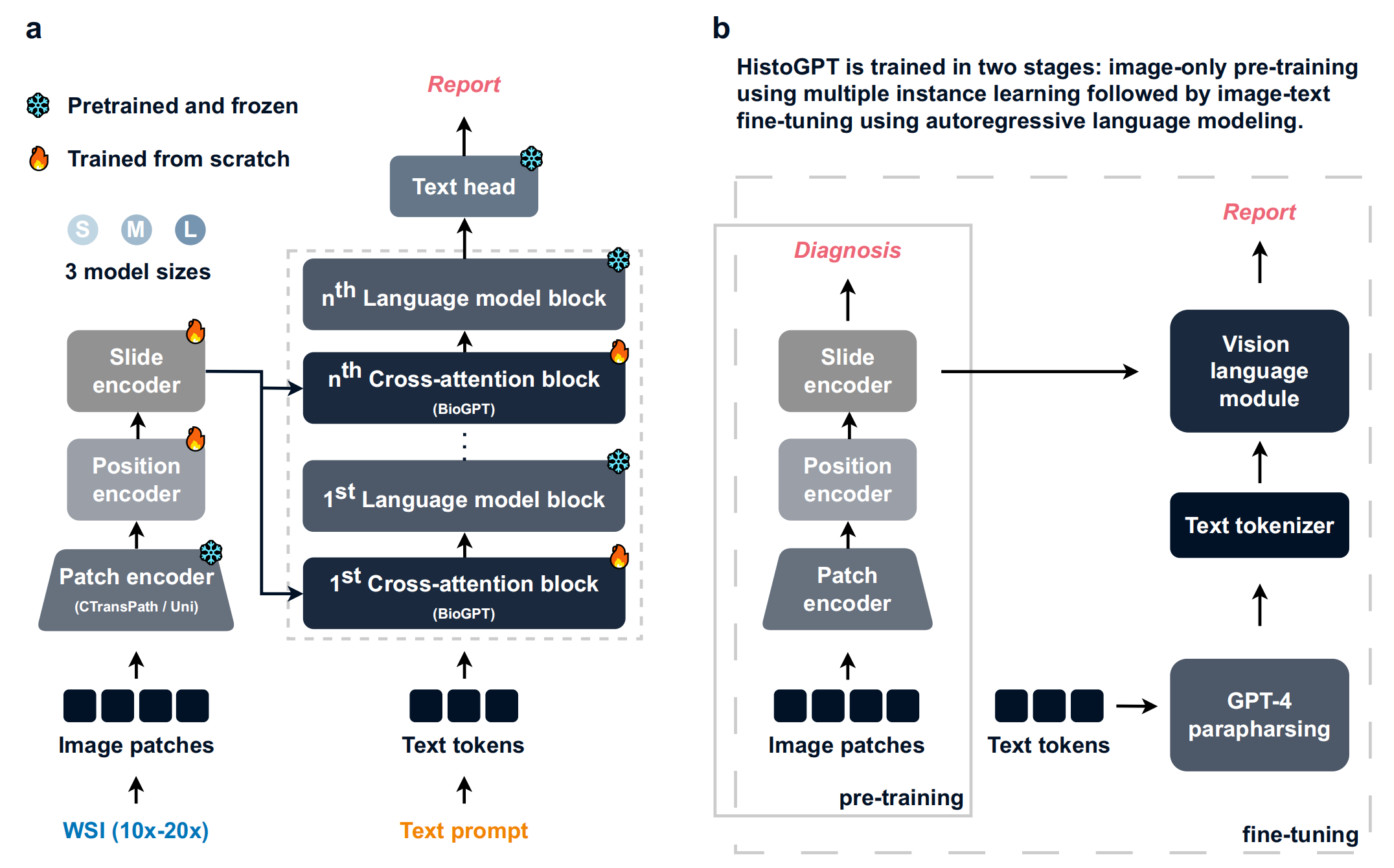
3-1:HistoGPT模型架构
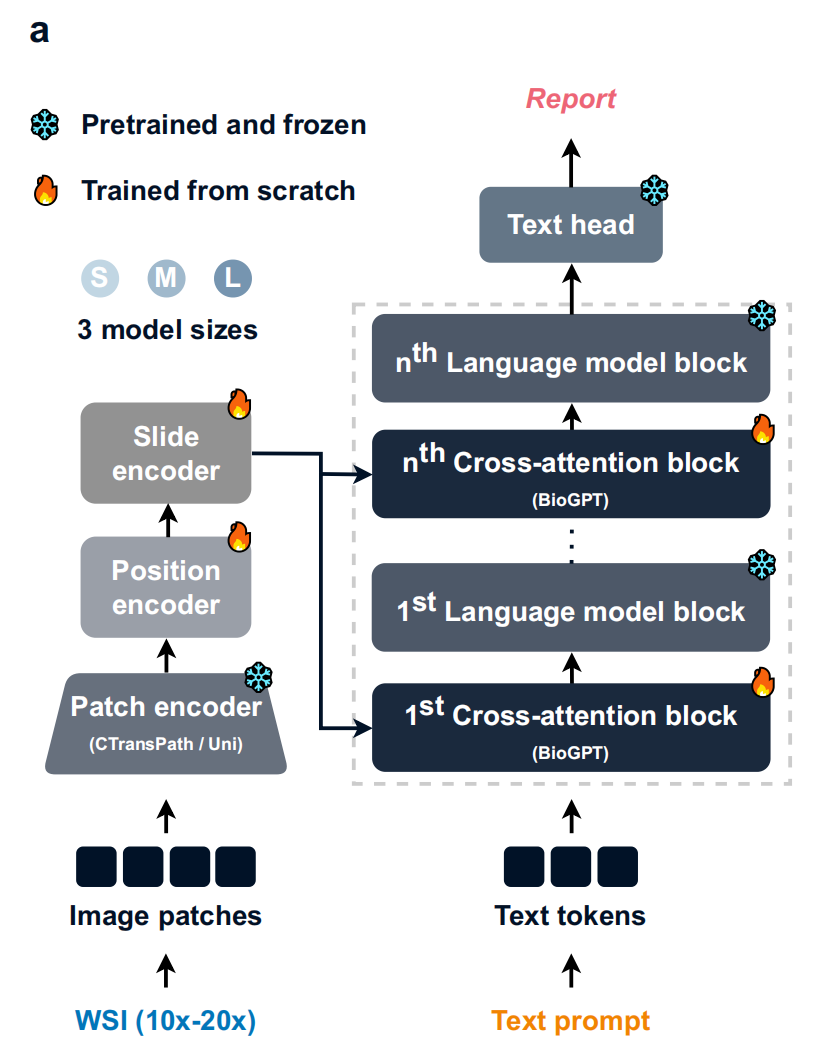
- 图像处理路径:全切片图像(WSI,放大倍数10x - 20x )先被分割成图像块(Image patches) ,经补丁编码器(Patch encoder,HistoGPT - S/M用CTransPath ,HistoGPT - L用Uni )、位置编码器(Position encoder ,仅HistoGPT - S/L使用 )和切片编码器(Slide encoder )处理,提取图像特征。
- 文本处理路径:文本提示(Text prompt)转化为文本标记(Text tokens) ,进入由BioGPT构成的跨注意力模块(Cross - attention block ,tanh - gated XATTN )和语言模型模块(Language model block) ,实现图像与文本信息融合。
- 输出:最后通过文本头(Text head)生成病理报告(Report) 。模型有小(S)、中(M)、大(L)三种规模,部分模块是预训练且冻结的,部分则从头训练。
3-2:HistoGPT训练流程
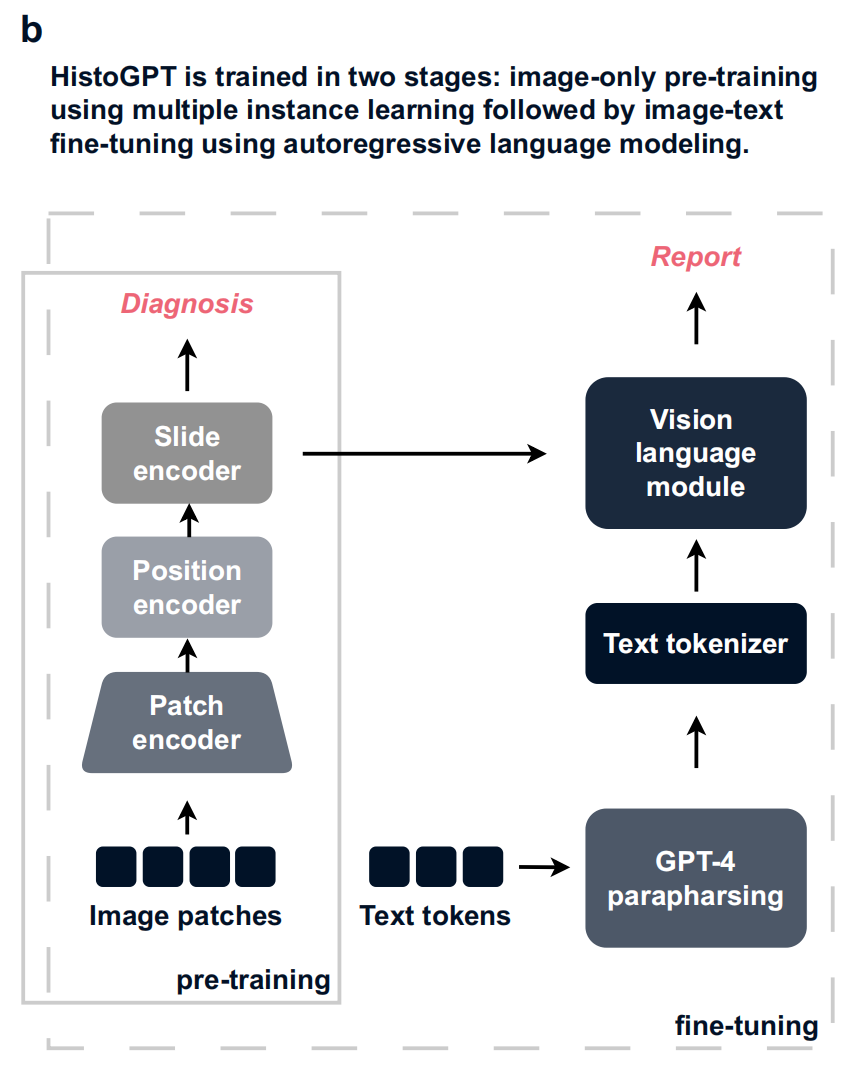
- 预训练阶段(pre - training):仅用图像数据,通过多实例学习(MIL) ,利用补丁编码器、位置编码器和切片编码器处理图像块,目标是疾病诊断(Diagnosis) ,让模型学习图像特征与疾病关联。
- 微调阶段(fine - tuning):引入文本数据,文本标记先经GPT - 4释义(paraphrasing ,防止模型在相同句子上过拟合 ),再经文本标记器(Text tokenizer)处理后进入视觉语言模块(Vision language module) ,结合预训练图像特征,用自回归语言建模进行图像 - 文本联合微调,生成病理报告(Report) 。
3-3:HistoGPT推理方法
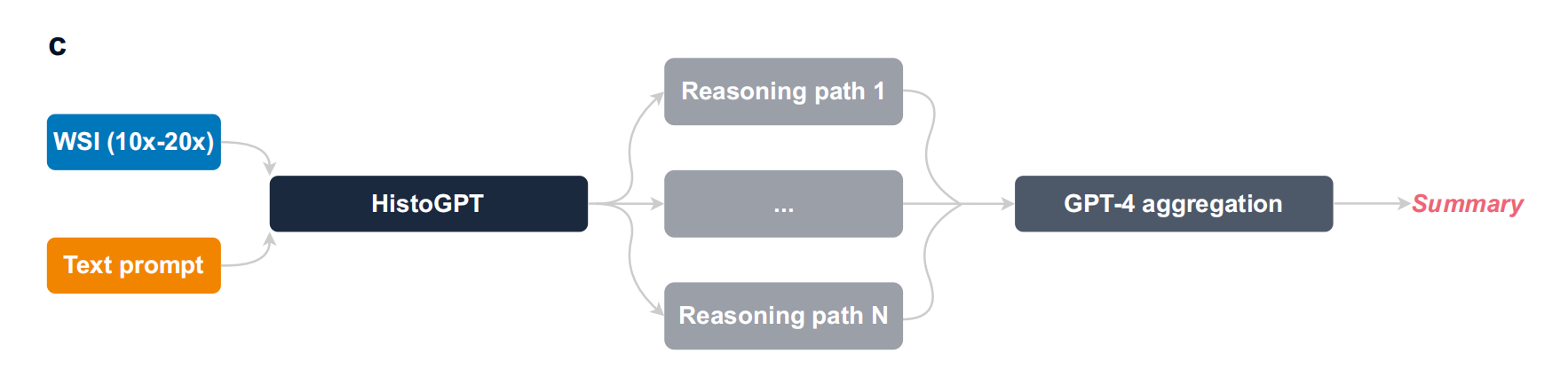
采用集成优化(ER)推理方法。输入全切片图像(WSI)和文本提示,HistoGPT随机生成多条推理路径(Reasoning path 1到Reasoning path N )下的可能报告,运用温度、top - p、top - k采样捕捉输入图像不同方面。再通过聚合模块(GPT - 4 )将结果整合,给出病例综合描述,提供更全面准确的病理报告。
四、HistoGPT生成与人类水平相当的病理报告
4-1:数据集疾病分布
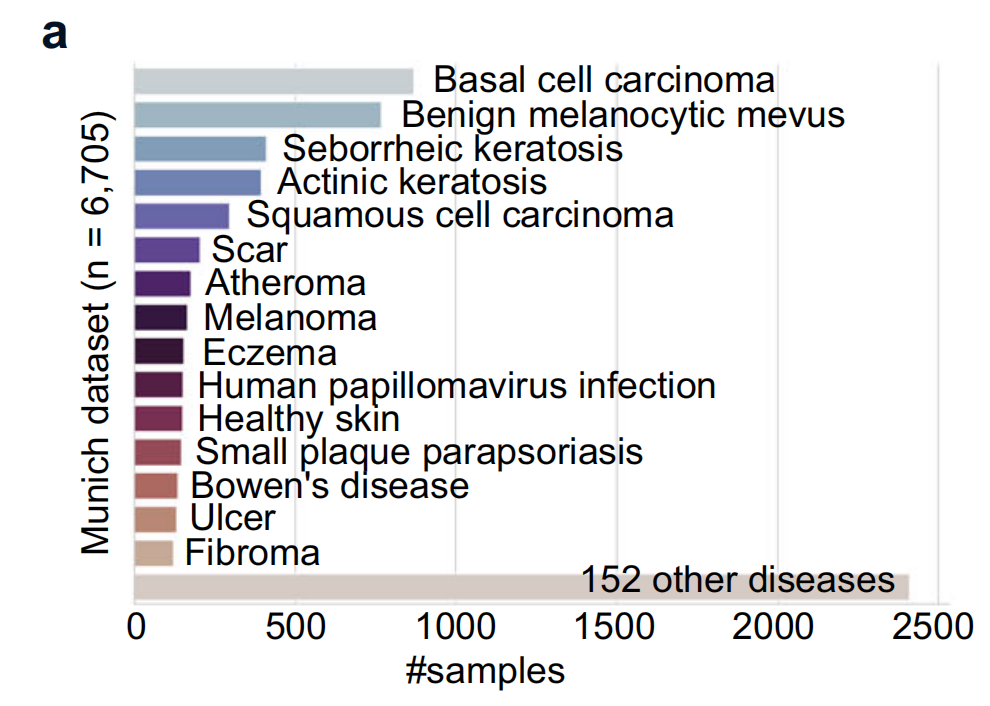
展示了内部慕尼黑数据集的疾病分布情况,涵盖6705例患者的15,129张全切片图像,涉及167种皮肤病。主要疾病包括基底细胞癌(BCC)、脂溢性角化病(SK)、良性黑素细胞痣(BMN)等 。
该数据集用于训练和测试HistoGPT模型,按75/25比例在患者层面划分训练集和测试集。
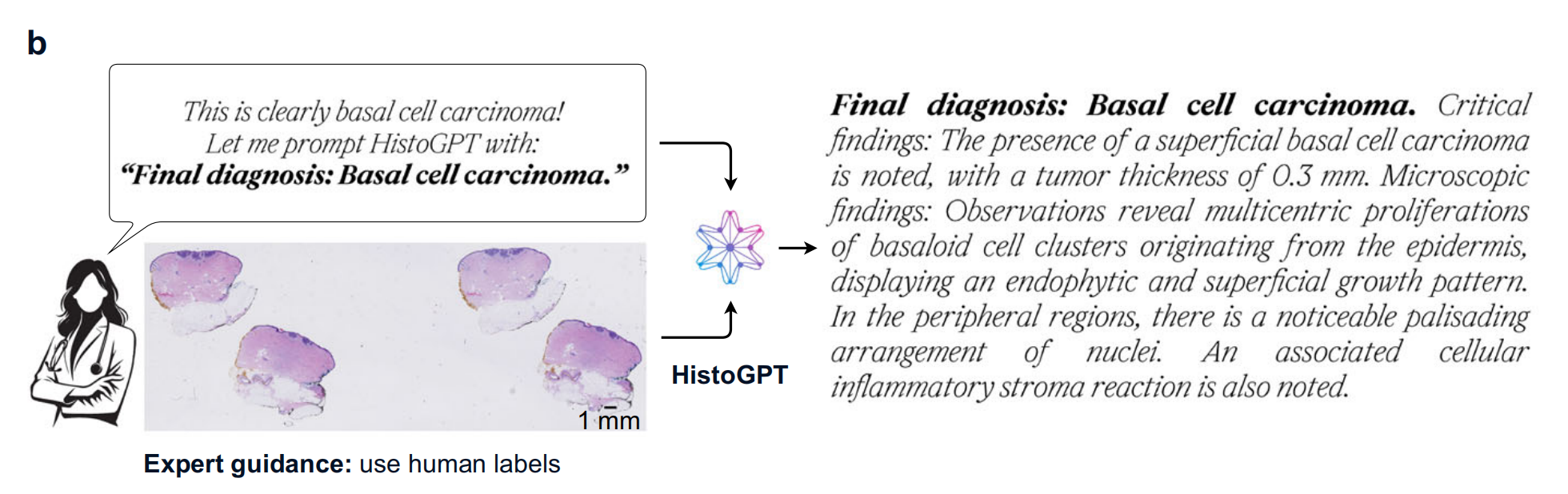
4-2:专家指导下HistoGPT报告生成示例
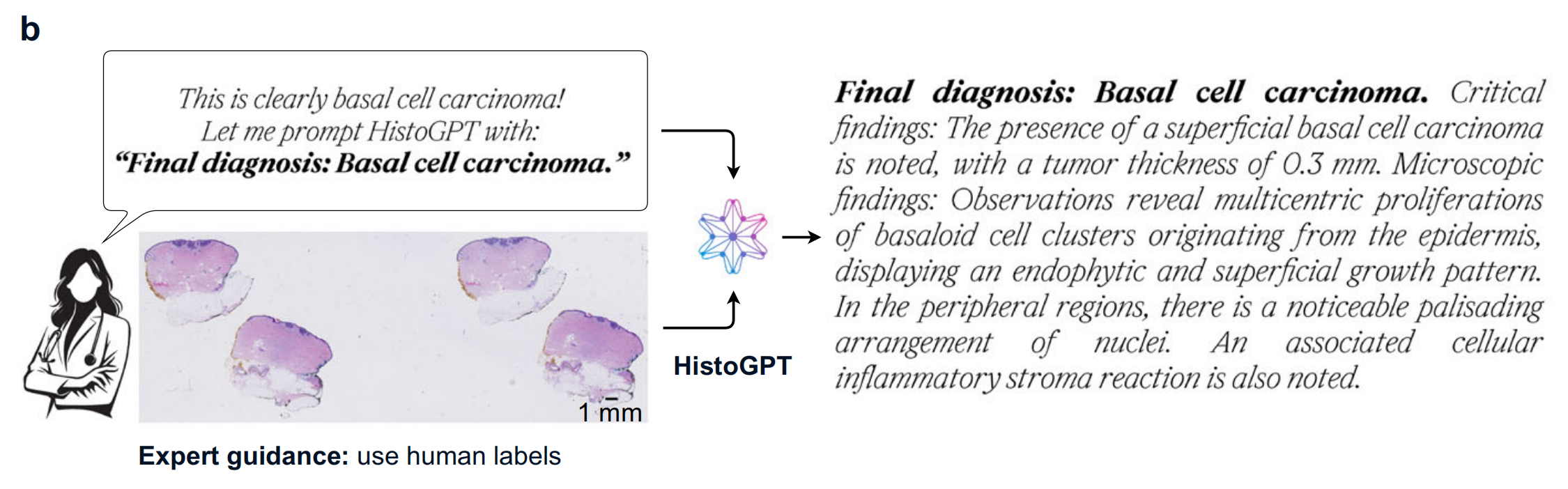
专家判断图像为基底细胞癌,以“Final diagnosis: Basal cell carcinoma.”作为提示词输入HistoGPT ,模型生成包含最终诊断、关键发现和微观发现等内容的病理报告,体现其在专家引导下生成专业病理报告的能力。
4-3:病理报告评估方法
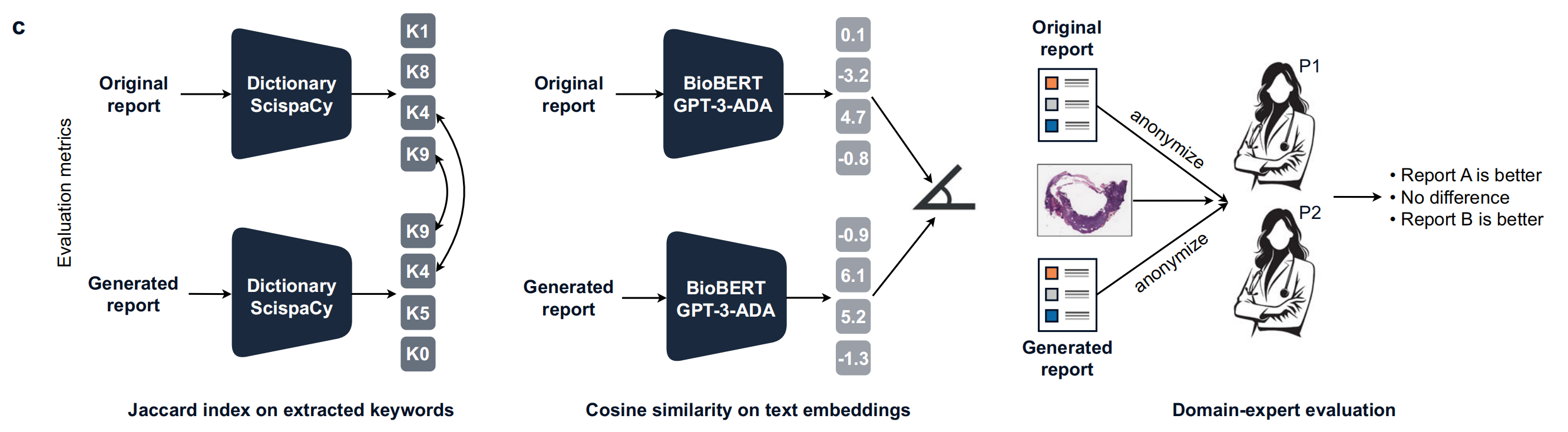
- 关键词提取:使用皮肤病学词典(Dictionary)和SciSpaCy从原始报告和生成报告中提取关键医学术语,计算Jaccard指数衡量关键词重叠程度。
- 文本嵌入相似性:利用生物医学语言模型BioBERT计算原始报告和生成报告文本嵌入的余弦相似度,评估语义相似性。还使用GPT - 3 - ADA模型进行相关评估。
- 领域专家评估:两位独立的外部皮肤科病理学家(P1和P2)对100份原始报告和专家引导生成的报告进行评估,判断报告A更好、无差异或报告B更好。
4-4:模型性能对比
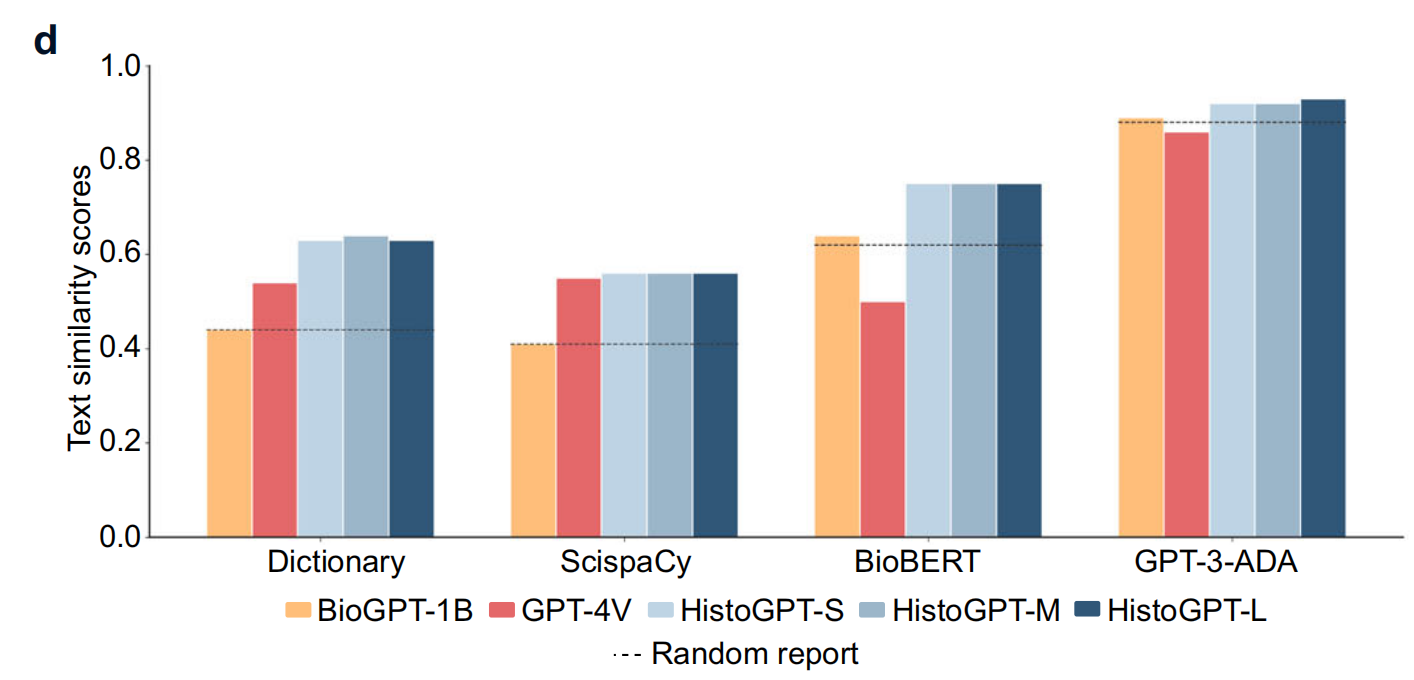
展示不同模型(BioGPT - 1B、GPT - 4V、HistoGPT - S、HistoGPT - M、HistoGPT - L )在文本准确性(Dictionary、SciSpaCy )和文本相似性(BioBERT、GPT - 3 - ADA )指标上的表现。
HistoGPT模型在各项指标上优于BioGPT - 1B和GPT - 4V ,表明其生成病理报告的能力更接近人类水平。
4-5:领域专家评估结果
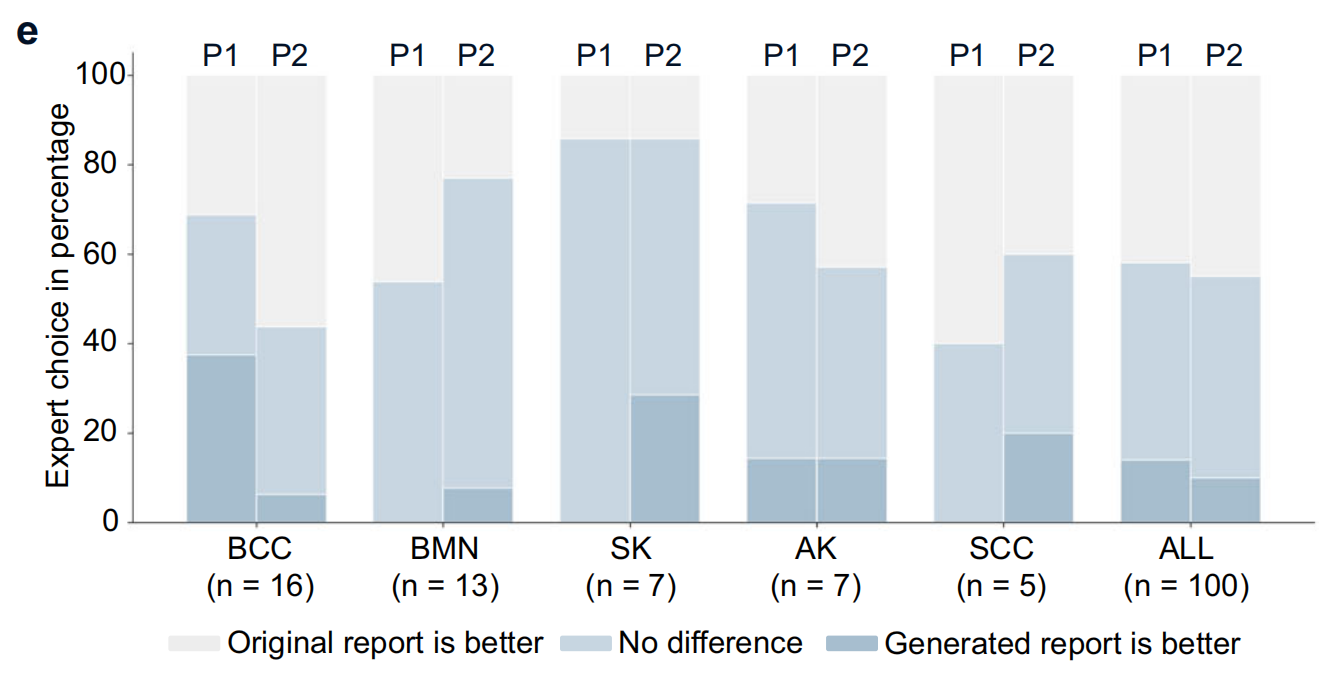
呈现两位病理学家(P1和P2)对不同疾病(BCC、BMN、SK、AK、SCC等 )病理报告的评估结果,包括判断报告A更好、无差异或报告B更好的比例,说明HistoGPT生成的报告在专家评估中得到较高认可 。
五、HistoGPT框架思路解析
HistoGPT是一种多模态AI系统,可从皮肤科组织样本的全切片图像(WSIs)生成高度准确的病理报告。
该系统处理不同尺寸的组织病理学图像,提取有意义的特征,并生成临床级文本报告,内容包括疾病分类、肿瘤亚型预测、肿瘤厚度估计和其他关键诊断信息。
系统基于包含6,000例患者报告对、覆盖150多种皮肤状况(包括健康、炎症和癌性组织类型)的12,000多张WSIs的大规模数据集进行训练。
HistoGPT通过注意力可视化提供完全可解释性,使临床医生能够了解哪些图像区域促成了特定诊断结论。
5-1:核心功能
HistoGPT结合计算机视觉和自然语言处理,提供以下关键功能:
| 功能 | 描述 |
|---|---|
| WSI处理 | 通过智能分块和特征提取处理不同尺寸的全切片图像 |
| 报告生成 | 生成包含临床术语和结构化发现的全面病理报告 |
| 可解释性 | 提供将生成文本与特定图像区域关联的注意力可视化 |
| 集成优化 | 通过多重采样和外部语言模型集成提高输出质量 |
| 可扩展架构 | 通过分层特征提取高效处理千兆像素图像 |
5-2:HistoGPT系统组件
这张图展示了HistoGPT系统的架构,涵盖输入处理、特征提取、核心模型、训练以及推理等层面。
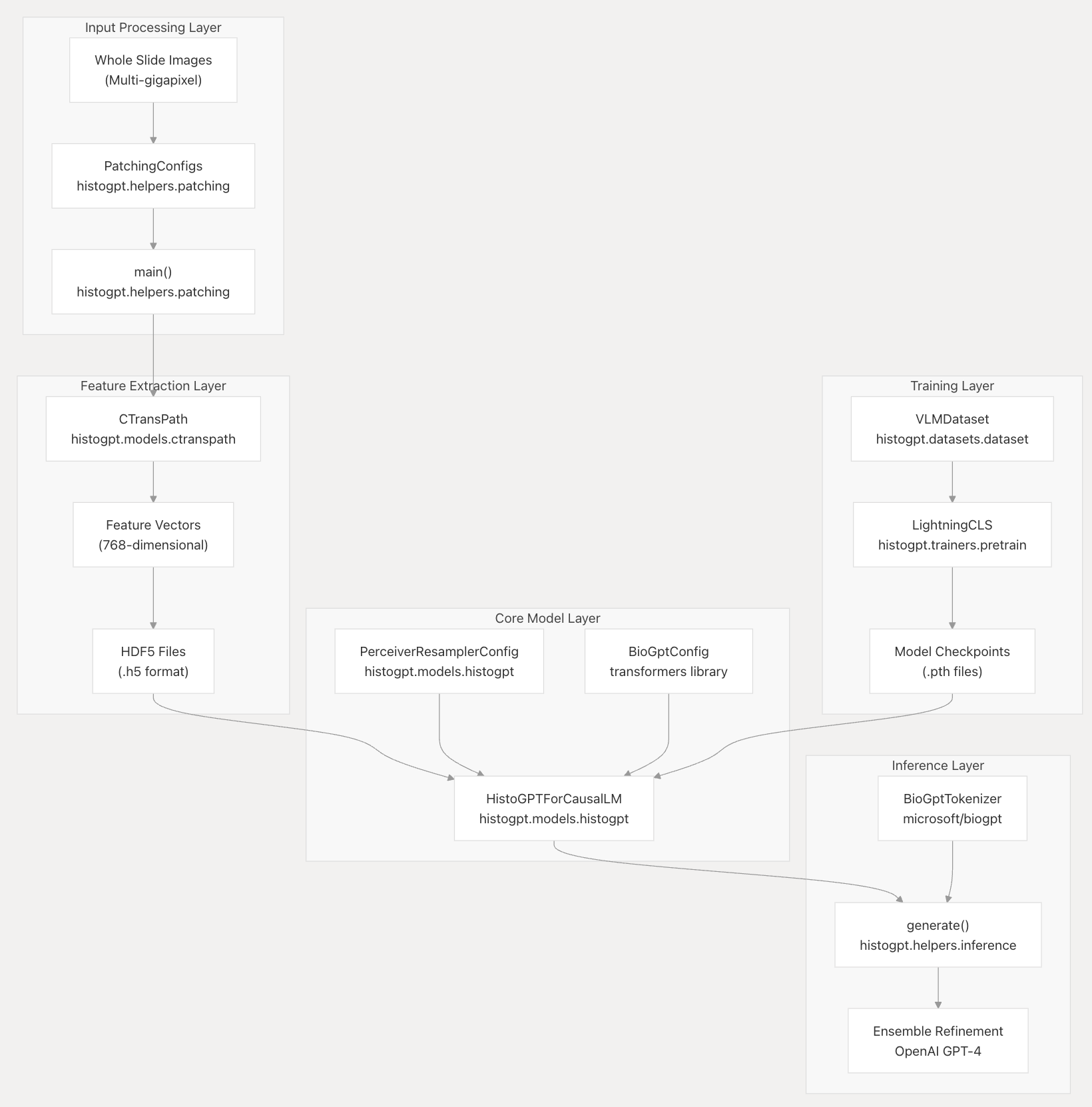
输入处理层(Input Processing Layer)
- 输入:接收多千兆像素的全切片图像(Whole Slide Images )。
- 处理:通过
histogpt.helpers.patching模块中的PatchingConfigs进行配置,再由main()函数执行处理,将图像进行分块等操作,为后续处理做准备。
特征提取层(Feature Extraction Layer)
- 模型:利用
histogpt.models.ctranspath中的CTransPath模型进行特征提取。 - 输出:生成768维的特征向量(Feature Vectors ),并存储为HDF5文件(.h5格式 ),方便后续核心模型调用。
核心模型层(Core Model Layer)
- 配置:结合
histogpt.models.histogpt中的PerceiverResamplerConfig和transformers库中的BioGptConfig。 - 模型:构建
histogpt.models.histogpt中的HistoGPTForCausalLM模型,整合图像特征与语言模型能力,是整个系统的核心。
训练层(Training Layer)
- 数据集:使用
histogpt.datasets.dataset中的VLMDataset来管理训练数据。 - 训练框架:通过
histogpt.trainers.pretrain中的LightningCLS框架进行训练,训练过程中会生成模型检查点(Model Checkpoints ,.pth文件 ),用于保存模型参数,方便后续继续训练或推理使用。
推理层(Inference Layer)
- 分词器:采用
microsoft/biogpt的BioGptTokenizer对输入文本进行分词处理。 - 推理函数:通过
histogpt.helpers.inference中的generate()函数进行文本生成,最后利用OpenAI的GPT - 4进行集成优化(Ensemble Refinement ),提升推理结果的质量 。
5-3:数据处理流程
Stage1:WSI处理(WSI Processing)
- 输入:原始WSI文件(格式为.svs、.ndpi、.tif )。
- 处理:通过
PatchingConfigs进行补丁提取,设置补丁大小为256 ;接着进行质量过滤,使用白色阈值(white_threshold )为170、185 ,边缘阈值(edge_threshold )为2 ,对图像质量进行筛选。
Stage2:特征提取(Feature Extraction)
- 模型:利用CTransPath模型(权重文件为ctranspath.pth )。
- 输出:提取768维的特征向量(feats[]数组 ),并存储为HDF5格式。
Stage3:模型处理(Model Processing)
- 操作:使用640个可学习查询(learnable queries )的PerceiverResampler ;通过门控交叉注意力(Gated Cross-Attention )融合视觉与文本信息;再经BioGPT解码器进行自回归生成。
Stage4:输出生成(Output Generation)
- 操作:调用
generate()函数,设置top - k为40、top - p为0.95 ;最后通过BioGptTokenizer解码,输出临床文本形式的病理报告。 整个流程从原始图像输入开始,经一系列处理步骤,最终生成专业的病理报告。
5-4:模型架构组件
这张图展示了HistoGPT中视觉组件与语言组件融合的架构。
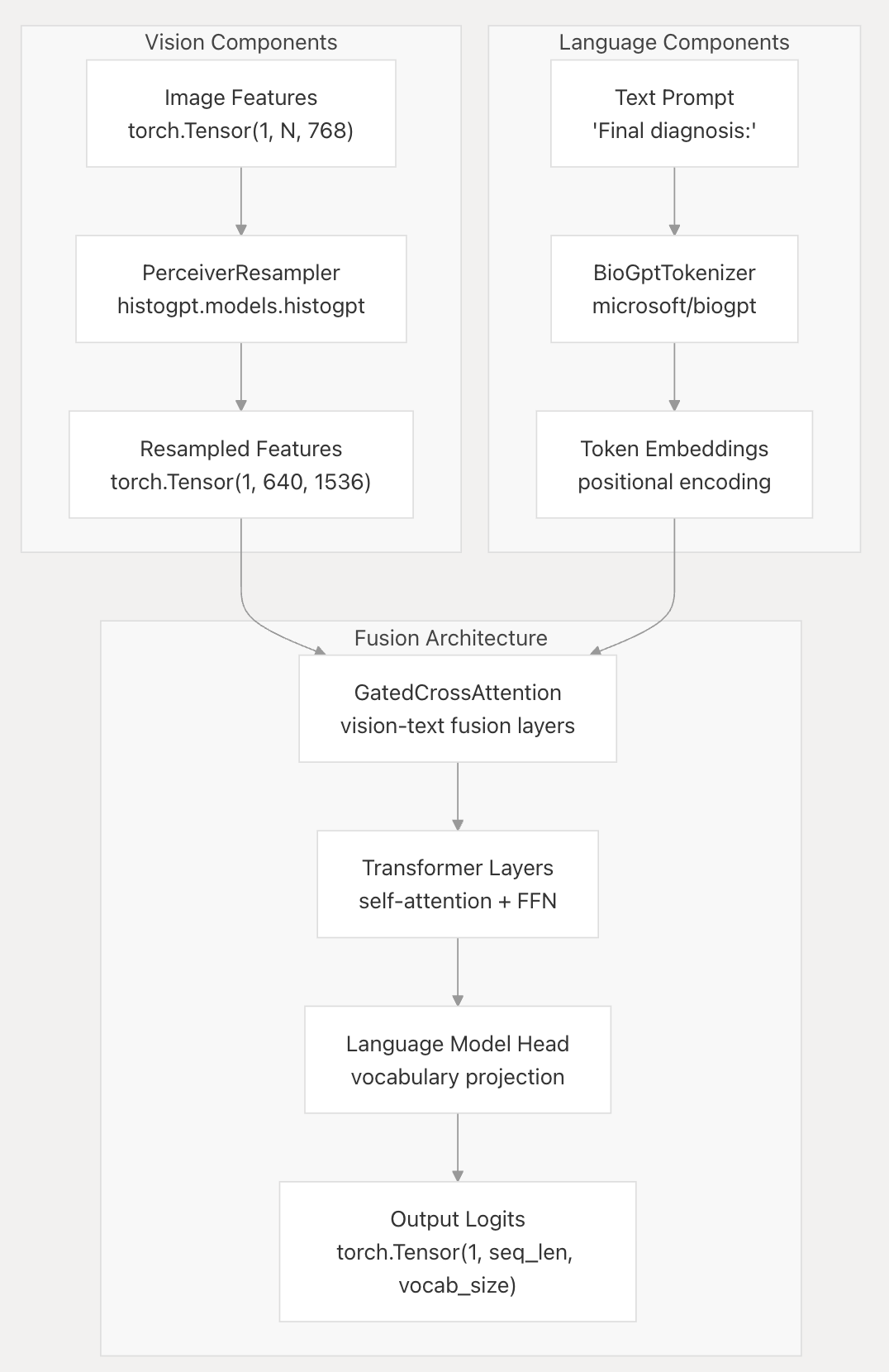
视觉组件(Vision Components)
- 图像特征提取:获取图像特征,以torch.Tensor形式存储,维度为(1, N, 768) 。
- 特征重采样:通过
histogpt.models.histogpt中的PerceiverResampler对图像特征进行处理,得到重采样后的特征,维度变为(1, 640, 1536) 。
语言组件(Language Components)
- 文本提示输入:输入文本提示,如“Final diagnosis:” 。
- 分词处理:使用
microsoft/biogpt的BioGptTokenizer对文本提示进行分词,得到词嵌入(Token Embeddings),并进行位置编码(positional encoding)。
融合架构(Fusion Architecture)
- 跨模态融合:利用门控交叉注意力(GatedCrossAttention)层,将视觉特征与文本特征进行融合。
- 进一步处理:融合后的特征通过Transformer层,包含自注意力(self-attention)和前馈神经网络(FFN) ,进一步处理特征。
- 语言模型头:经过处理的特征通过语言模型头(Language Model Head)进行词汇投影(vocabulary projection) 。
- 输出逻辑值:最终输出逻辑值(Output Logits),以torch.Tensor形式呈现,维度为(1, seq_len, vocab_size) ,用于后续生成病理报告等任务。 该架构实现了视觉与语言信息的有效融合与处理。
5-5:推理工作流程
典型的推理工作流程包括三个主要步骤:
- 特征提取:使用
histogpt.helpers.patching中的main()函数和PatchingConfigs处理WSI - 模型加载:将预训练权重加载到
HistoGPTForCausalLM实例中 - 报告生成:使用
histogpt.helpers.inference中的generate()函数生成文本
5-6:训练工作流程
训练涉及LightningCLS框架,数据集通过VLMDataset和MILDataset类管理。系统支持分布式训练和自动检查点。
集成点
| 组件 | 用途 | 关键类 |
|---|---|---|
| 数据处理 | WSI处理和特征提取 | PatchingConfigs, main() |
| 模型核心 | 视觉-语言融合与生成 | HistoGPTForCausalLM, PerceiverResampler |
| 推理 | 文本生成和优化 | generate(),集成方法 |
| 训练 | 模型训练和优化 | LightningCLS,数据集类 |
| 可视化 | 注意力分析和解释 | CLAM工具,注意力图 |
5-7:技术依赖
HistoGPT基于以下关键技术基础构建:
- PyTorch:用于模型实现的核心深度学习框架
- Transformers:HuggingFace库,提供
BioGptConfig和BioGptTokenizer - Lightning:PyTorch Lightning训练基础设施
- SlideIO:用于WSI处理的医学成像库
- OpenAI API:通过GPT-4集成实现外部优化
- CLAM:用于全切片图像分析的专用工具
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!


















 5544
5544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









