







文章目录
Context-Aware Voxel-Wise Contrastive Learning for Label Efficient Multi-organ Segmentation
摘要
医学图像分割是许多临床应用的先决条件,包括疾病诊断、手术计划和计算机辅助干预。由于在获得专家级准确、注释密集的多器官数据集方面存在挑战,现有的多器官分割数据集要么样本数量较少,要么只对少数器官而不是所有器官进行注释,这些数据被称为部分标记数据。以前有人试图开发标签有效的分割方法,利用这些部分标记的数据集来提高多器官分割的性能。然而,这些方法中的大多数都受到限制,即它们只使用数据集中的标记信息,而没有利用大量未标记的数据。为此,我们提出了一种上下文感知的体素对比学习方法,以充分利用部分标记数据集中的标记和未标记数据,提高多器官分割性能。
本文方法
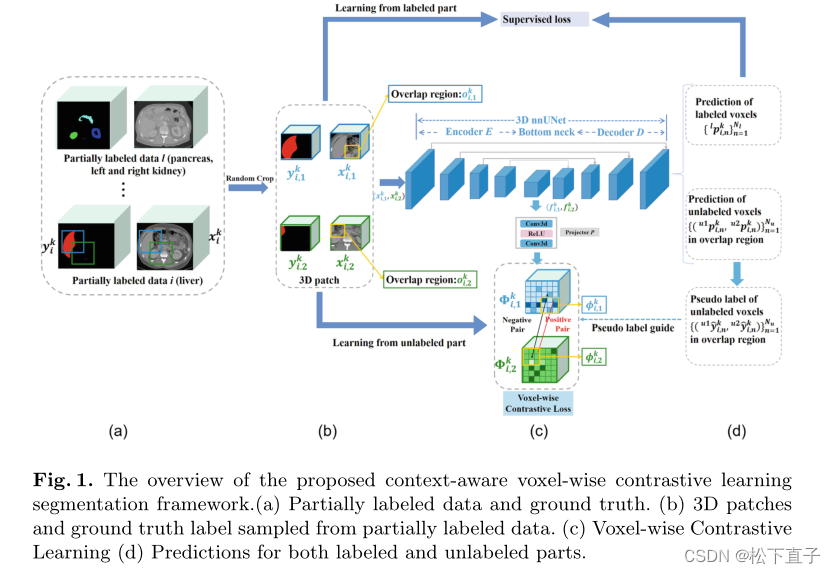
(a) 部分标记的数据和标签
(b) 从部分标记的数据中采样的3Dpatch和标签
(c) 体素对比学习
(d)标记和未标记部分的预测
图1显示了总体架构。从该图中可以看出,有两个分支,即一个用于标记的体素,另一个用于未标记的体素。对于标记的体素,我们计算交叉熵(CE)损失和dice损失。对于未标记的部分,我们计算上下文感知的体素对比学习损失。
有监督损失
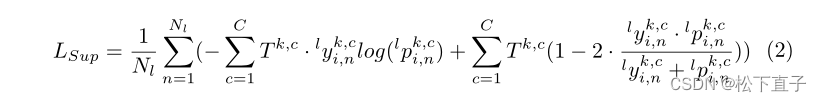
Context-Aware Contrastive Learning Loss for Unlabeled Voxels
基于patch/子体积的策略来训练网络时,由于上下文信息的差异,当体素位于不同的补丁中时,体素的预测可能不同。使用上下文感知的对比学习来最大限度地减少这种不一致性,从而使我们能够利用部分标记数据集中的大量未标记数据
在每次训练迭代中,在我们将两个重叠的3D补丁送到我们的网络以获得预测之后,我们将重叠区域中的未标记体素的预测pki分组为一个集合,然后下采样,对于属于同一个体素,我们希望相应的特征接近
为此,我们设计了一个方向对比度损失(DC损失)来训练我们的网络,以便对齐从不同patch预测中获得的相同体素的特征。
还要求对齐特征的置信度应大于某个阈值,以确保对齐特征的质量。
DC Loss如下:
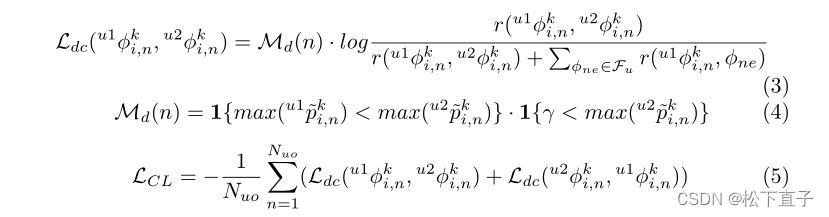
需要仔细结合图和公式体会
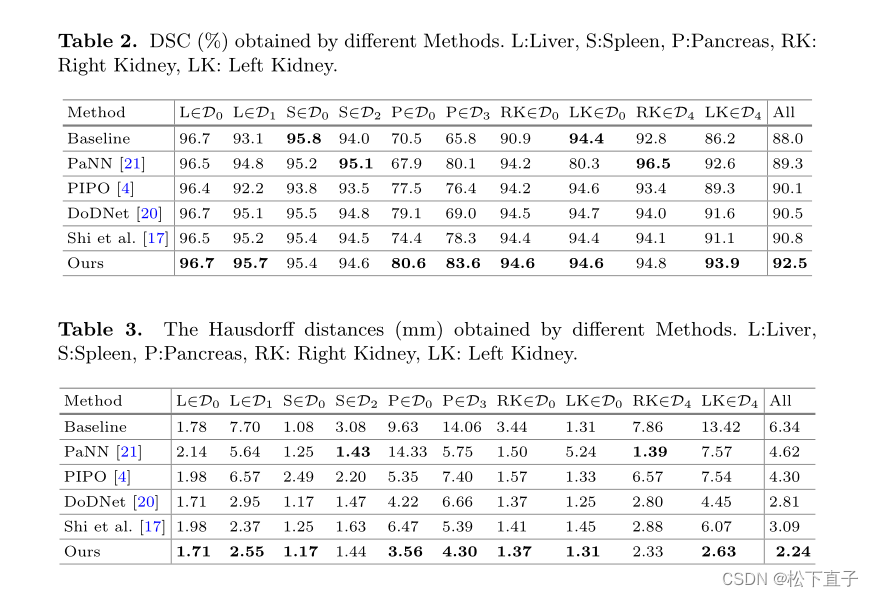
实验结果
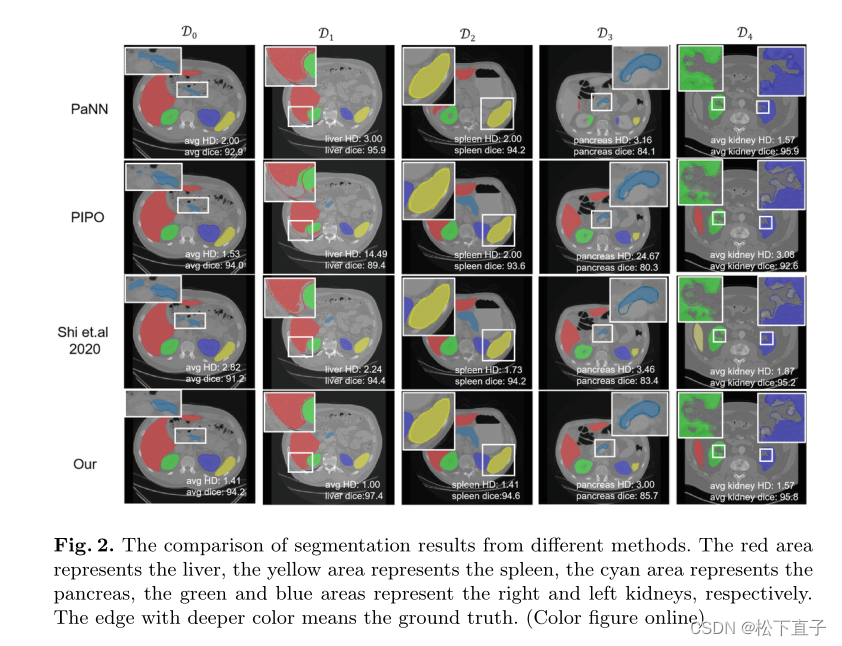
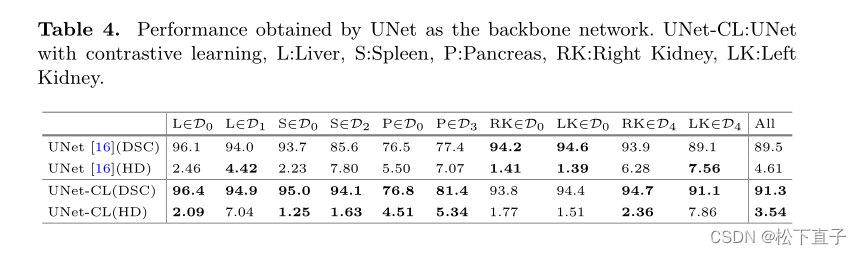


















 42
42

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











