







文章目录
CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
摘要
多模态图像融合的目的是使融合后的图像保持不同模态的优点,如功能高光和细节纹理。为了解决跨模态特征建模和分解所需模态特定特征和模态共享特征的挑战,我们提出了一种新的关联驱动特征分解融合(CDDFuse)网络。
首先,使用Restormer块提取跨模态浅层特征。
然后,引入了一种双支路transformer- cnn特征提取器,其中Lite Transformer (LT)块利用远程注意力处理低频全局特征,而Invertible Neural Networks (INN)块专注于提取高频局部信息。
进一步提出了一种基于嵌入信息的相关驱动损失,使低频特征相关,而高频特征不相关。
然后,基于lt的全局融合层和基于nn的局部融合层输出融合后的图像。
实验表明,CDDFuse在红外-可见光图像融合和医学图像融合等多种融合任务中取得了良好的效果。
代码地址
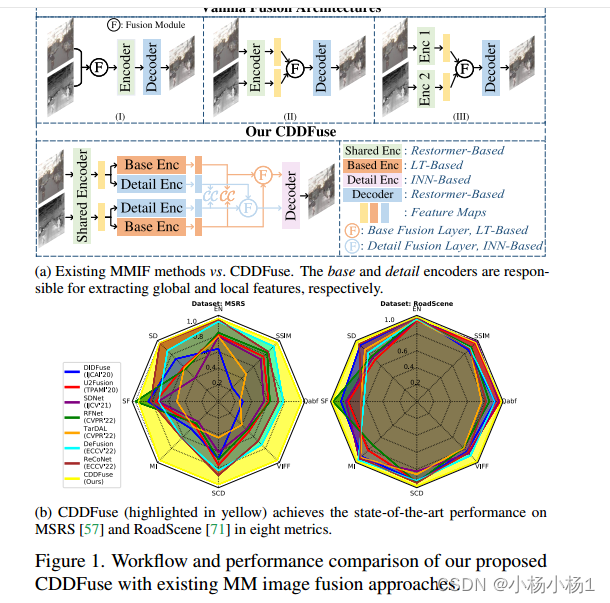
本文方法
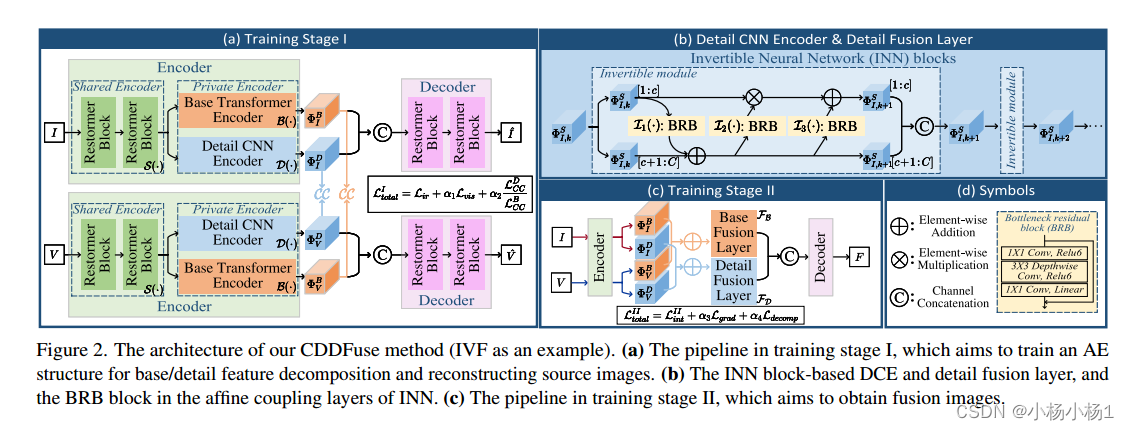
Base transformer encoder:用于从共享特征中抽取低频信息
Detail CNN encoder.:从共享特征中抽取高频信息,并且用到了INN网络,图b中
考虑到基/细节特征融合的感应偏置应该与编码器中的基/细节特征提取相似,我们在基/细节融合层中采用了LT和INN块
损失函数
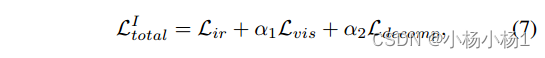
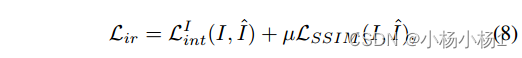
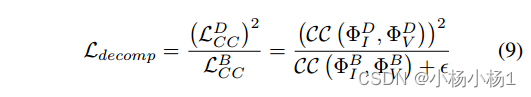
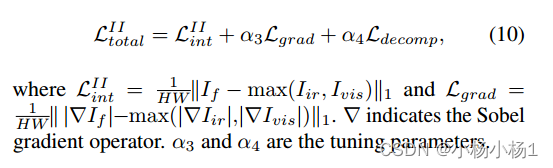
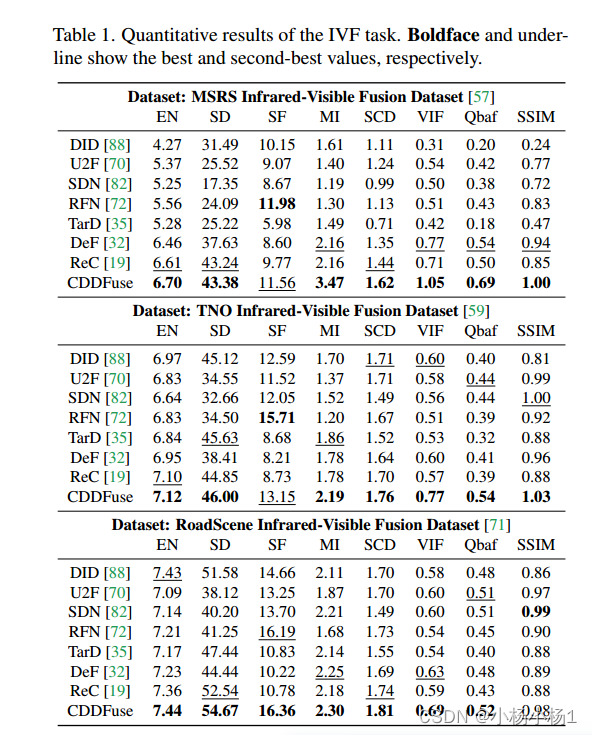
实验结果



















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











