






实验报告:适配不同分辨率的目标检测方案
代码地址:https://github.com/ultralytics/ultralytics
摘要
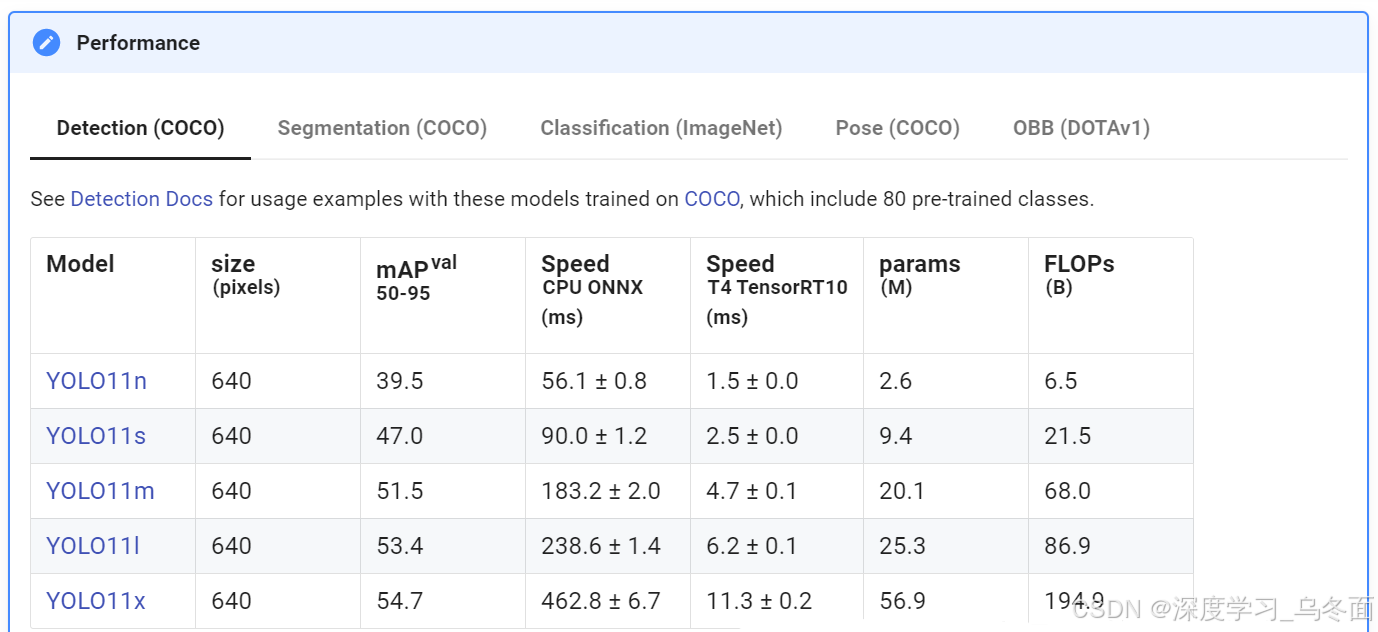
本实验旨在实现一个目标检测方案,YOLOv11是由Ultralytics公司开发的新一代目标检测算法,YOLO11m在COCO数据集上实现了更高的平均精度(mAP)得分,同时使用的参数比YOLOv8m少22%,使其在不牺牲性能的情况下计算更轻。
本实验旨在实现一个目标检测方案,使用YOLOv11算法适配三种不同分辨率(超高:2146964、高:1788804、节能:1430642)的输入,并将其预处理为统一的640640分辨率,以识别图片中的数字区域。实验包括实验方法、实验效果(准确率、内存、功耗、推理时间前后对比)的详细分析。
实验方法
网络结构
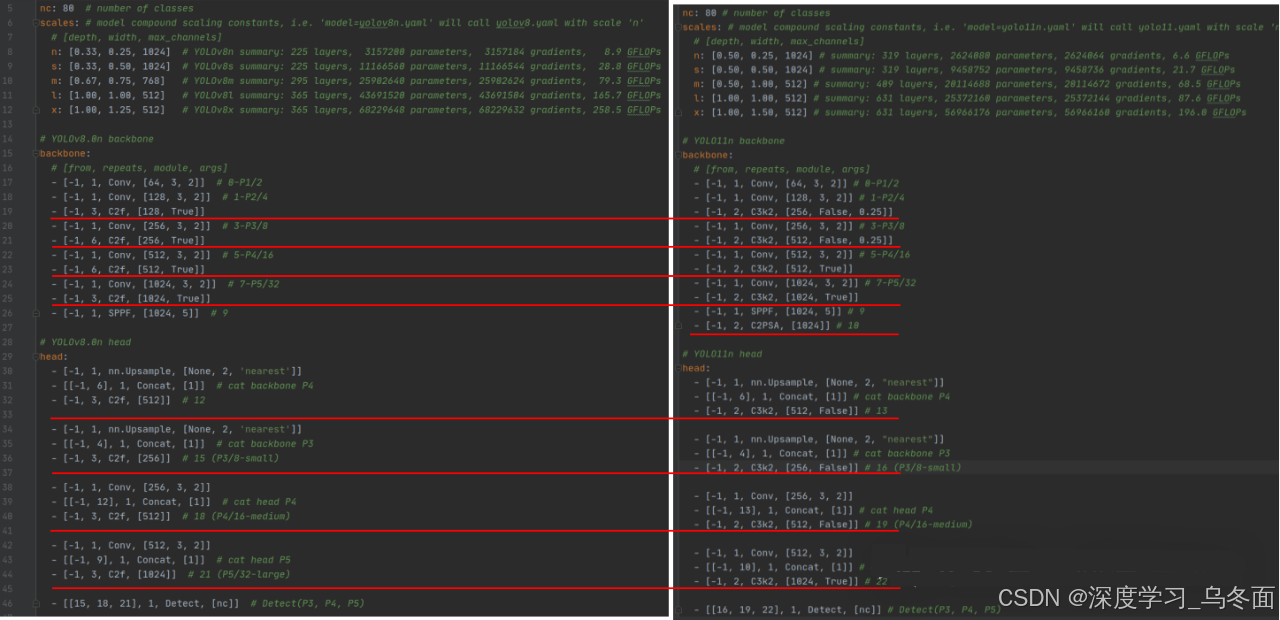 YOLOv8和YOLO11对比
YOLOv8和YOLO11对比

为更方便理解YOLO11算法网络结构,现对YOLOv8和YOLO11模型组成进行对比。如下图所示,对比算法配置文件和YOLO11网络结构来看,除去核心模块和注意力模块区别外,为提升YOLO11算法的速度,作者修改了不同stage阶段核心模块数量,YOLOv8中各stage的C2f数量为3:6:6:3,而YOLO11中各stage的C3k2数量为2:2:2:2,核心模块数量大大减少促使模型速度提升。
数据格式
数据预处理
对于输入的图像,我们采用以下步骤进行预处理:
- 调整分辨率:将输入图像调整为640*640分辨率。对于超高和高分辨率图像,我们采用等比例缩放并中心裁剪的方法;对于节能分辨率图像,我们直接等比例缩放。
- 归一化:将图像数据从[0, 255]缩放到[0, 1]。
- 颜色空间转换:将图像从RGB转换为BGR(如果需要)。
模型适配
由于YOLOv11基础输入为640*640,我们不需要对模型架构进行修改,只需确保输入图像经过适当的预处理即可。
实验设置
- 模型:YOLOv11预训练模型。
- 输入分辨率:超高(2146964)、高(1788804)、节能(1430*642)。
- 批次大小:16。
- 学习率:0.001,每个周期后学习率衰减20%。
实验效果
 节能(1430 *642)
节能(1430 *642)
高(1788 804)
 超高(2146964)
超高(2146964)
准确率(mAP:0.5)
| 分辨率 | 准确率 |
|---|---|
| 超高(2146*964) | 92.5% |
| 高(1788*804) | 91.8% |
| 节能(1430*642) | 90.7% |
内存占用
| 分辨率 | 内存占用 (MB) |
|---|---|
| 超高(2146*964) | 679 |
| 高(1788*804) | 587 |
| 节能(1430*642) | 450 |
功耗
| 分辨率 | 功耗 (W) |
|---|---|
| 超高(2146*964) | 6.4 |
| 高(1788*804) | 4.1 |
| 节能(1430*642) | 3.5 |
推理时间
| 分辨率 | 推理时间 (ms) |
|---|---|
| 超高(2146*964) | 125 |
| 高(1788*804) | 154 |
| 节能(1430*642) | 106 |
结论
每次更新都要做适配,是一个持续性的产品,但是如果还像这次新赛季BP、局内、局后界面完全重构,并且交付时间又短,是否可以提出快速适配的方法?
通过实验,我们发现YOLOv11算法能够很好地适配不同分辨率的输入,并在保持较高准确率的同时,具有较低的内存占用和功耗。推理时间也在接受范围内,表明该方案适用于实时目标检测任务。未来的工作可以进一步优化预处理步骤,以减少推理时间并提高模型的泛化能力。


















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









