






Abstract
-
EVA是一个基础的Transformer视觉模型
-
预训练任务:训练的图片是masked掉的50%的patches, 模型的任务是预测被遮挡的图像特征。
模型经过预训练,学会了通过图像和文本的对齐关系来重构被遮挡的部分,使其能够理解图像和文本之间的关联。 -
通过这个预训练任务,我们能够高效地将EVA扩展到十亿个参数。
-
这样就可以得到很大的模型,在下游任务上会有很好的表现
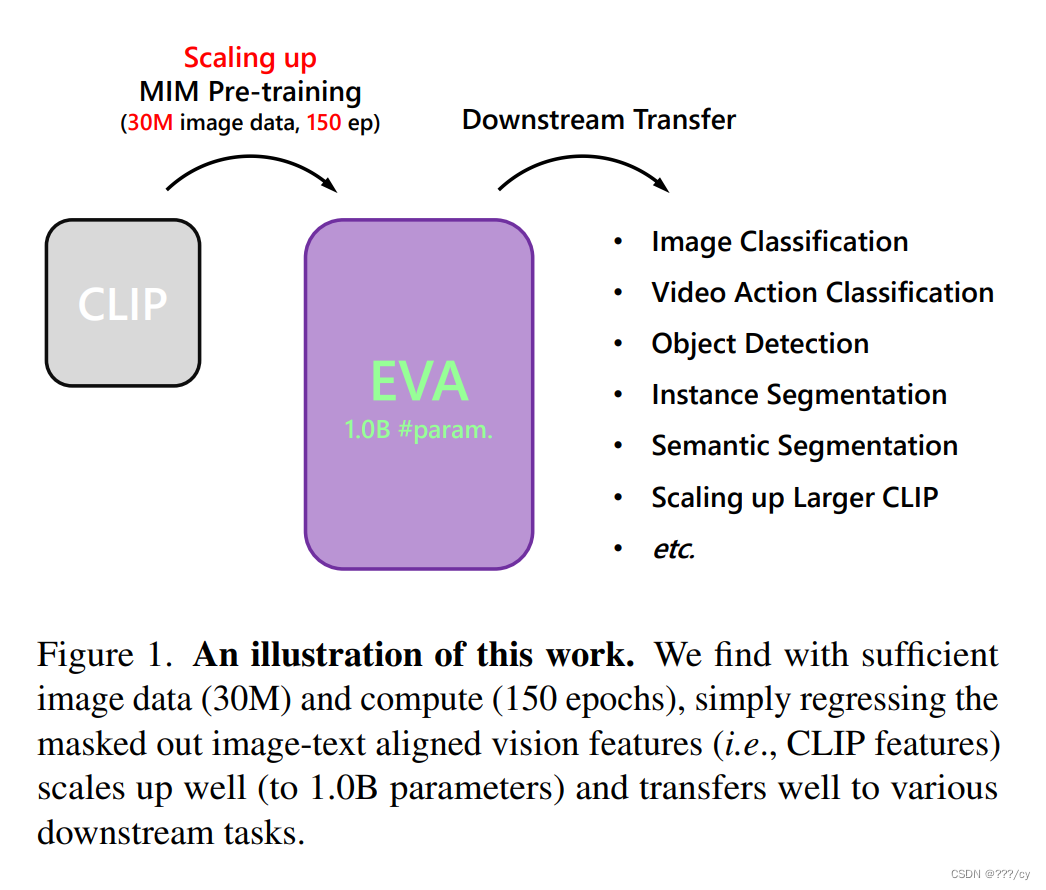
通过MIM 预训练,使得基于CLIP的预训练模型变大,得到1B param的EVA
,这个EVA模型迁移在下游任务中表现非常好。
Highlight
- 用EVA初始化的CLIP模型,无论文是数据量,还是GPUs消耗情况,都比原始的CLIP要高效和有效。这样不但加速了训练的过程,而且提高了zero-shot classification的表现。
Introduction
- 为大规模视觉表征学习找到了一个合适的MIM预训练目标
- 在1B-parameters with 亿级未标签的数据 的量级 探索它的极限
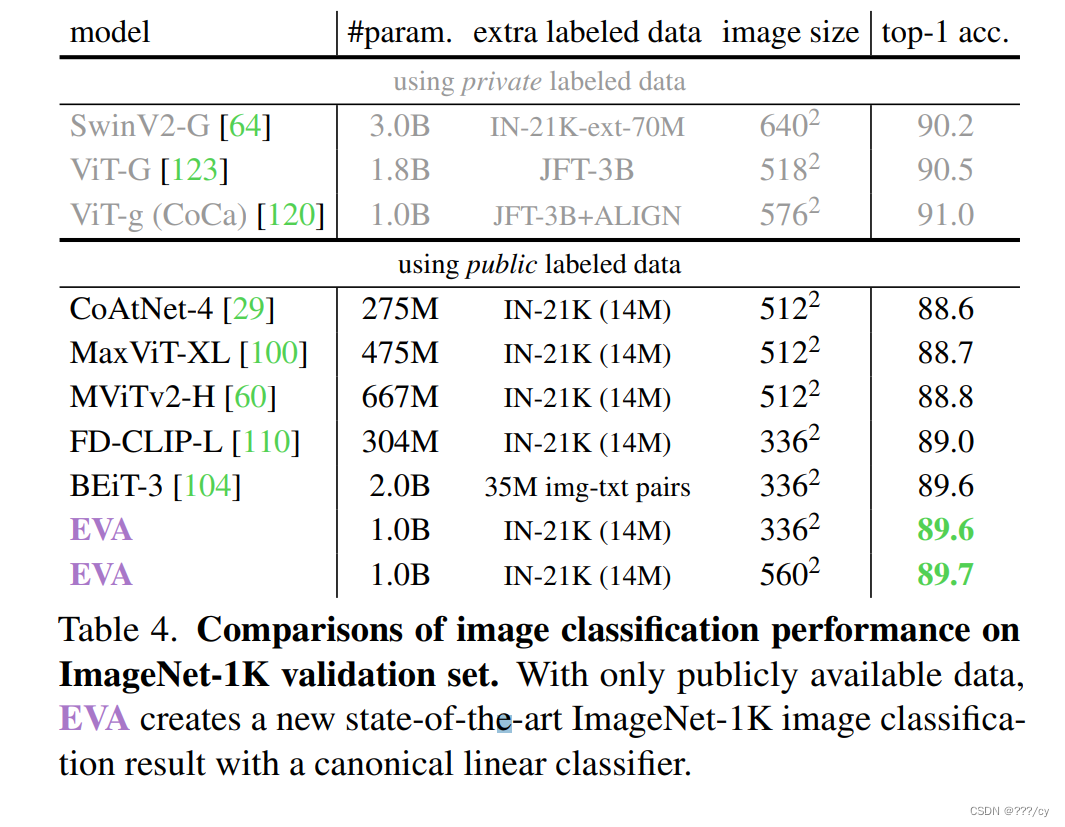
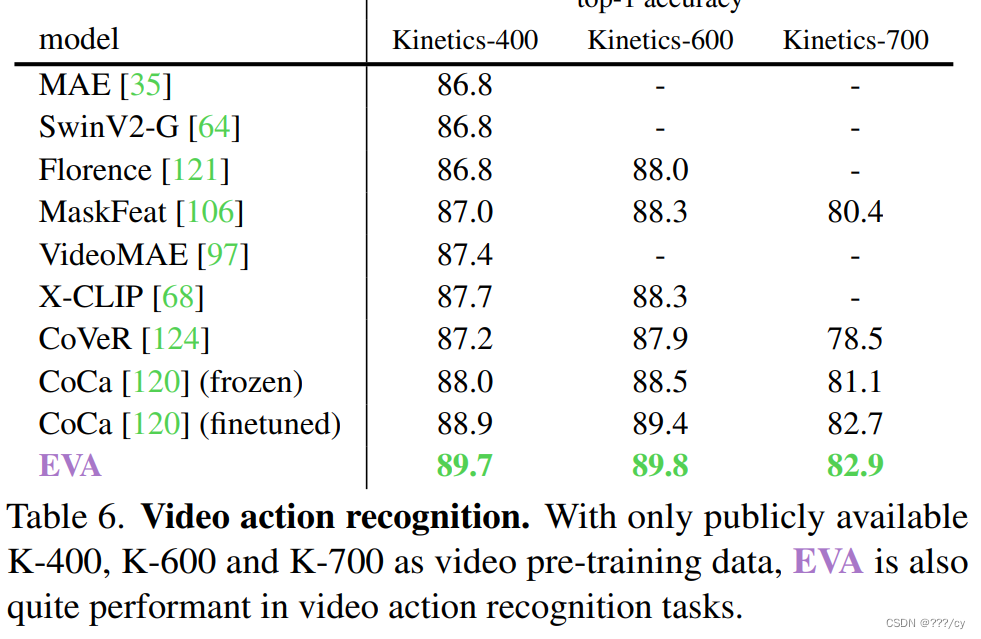
EVA arxiv
EVA这篇论文翻译写的很好















 5318
5318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









