







基于yolov5训练自己的数据集
之前的环境配置篇已经配置好yolov5的环境,本篇将介绍如何基于yolov5训练自己的数据集。
获取数据集图片
想要制作数据集,就得获取一定数量的图片。
方法一就是从网上爬取你想要的图片,这边推荐使用古月学院《移动机器人目标检测YOLOv5 》课程的资料中的图片爬虫脚本
# -*- coding: utf-8 -*-
import re
import requests
from urllib import error
from bs4 import BeautifulSoup
num = 0
numPicture = 0
file = ''
List = []
def Find(url, A):
global List
print('正在检测图片总数,请稍等.....')
t = 0
i = 1
s = 0
while t < 1000:
Url = url + str(t)
try:
# 这里搞了下
Result = A.get(Url, timeout=7, allow_redirects=False)
except BaseException:
t = t + 60
continue
else:
result = Result.text
pic_url = re.findall('"objURL":"(.*?)",', result, re.S) # 先利用正则表达式找到图片url
s += len(pic_url)
if len(pic_url) == 0:
break
else:
List.append(pic_url)
t = t + 60
return s
def recommend(url):
Re = []
try:
html = requests.get(url, allow_redirects=False)
except error.HTTPError as e:
return
else:
html.encoding = 'utf-8'
bsObj = BeautifulSoup(html.text, 'html.parser')
div = bsObj.find('div', id='topRS')
if div is not None:
listA = div.findAll('a')
for i in listA:
if i is not None:
Re.append(i.get_text())
return Re
def dowmloadPicture(html, keyword):
global num
# t =0
pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 先利用正则表达式找到图片url
print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
for each in pic_url:
print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
try:
if each is not None:
pic = requests.get(each, timeout=7)
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
else:
string = file + r'/' + keyword + '/' + keyword + str(num) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
num += 1
if num >= numPicture:
return
if __name__ == '__main__':
# 这里加了点
headers = {
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Upgrade-Insecure-Requests': '1'
}
A = requests.Session()
A.headers = headers
word = input("请输入搜索关键词:")
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
# 这里搞了下
tot = Find(url, A)
print(tot)
Recommend = recommend(url) # 记录相关推荐
numPicture = int(input('请输入想要下载的图片数量:'))
file = 'data'
t = 0
tmp = url
while t < numPicture:
try:
url = tmp + str(t)
# 这里搞了下
result = A.get(url, timeout=10, allow_redirects=False)
except error.HTTPError as e:
print('网络错误,请调整网络后重试')
t = t + 60
else:
dowmloadPicture(result.text, word)
t = t + 60
for re in Recommend:
print(re, end=' ')
接着对扒下的图片进行命名和统一后缀处理
# -*- coding:utf8 -*-
import os
class BatchRename():
def __init__(self):
self.path = 'data/all/' #表示需要命名处理的文件夹目录,复制地址后注意反斜杠
def rename(self):
filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) #获取文件长度(文件夹下图片个数)
i = 0 #表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg') or item.endswith('.png'): #初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可,我习惯转成.jpg)
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), 'all' + format(str(i), '0>4s') + '.jpg')#处理后的格式也为jpg格式的,当然这里可以改成png格式
# 这种情况下的命名格式为000xxxx.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
那如果你想要的图片网上搜不到咋办?方法二就需要自己拍照进行图片收集,以本次项目的gazebo中检测多边形块为例,我数据集中用的图片都是在gazebo中一张张截图截出来的,该方法比较笨,但是似乎没有更好的办法,对于特定场景的识别,这种方法也比较快。截了大概有个230张图片,样本比较少,截图的时候环境中的光线充足无遮挡,因此在后续的识别过程中出现阴影遮挡,就会对识别的结果产生影响。这块儿的数据集我就不放出来了。

安装以及使用图像标注工具labelImg
标注工具有好几种,常用的有labelImg和标注精灵,本篇主要介绍labelImg的安装以及使用。
labelImg的安装
源码下载labelImg的代码包
git clone https://github.com/tzutalin/labelImg.git
最新的labelImg需要在python3环境下运行,因此我们需要在anaconda环境搭建一个python3的虚拟环境,具体搭建教程详见环境搭建篇。
首先新建终端进入配置的虚拟环境,并进行运行labelImg的环境搭建。
cd labelImg
conda install pyqt=5
pip install lxml
pyrcc5 -o libs/resources.py resources.qrc
修改文件labelImg/data/predefined_classes.txt
将其中原有的类型名全部删除,换成自己的类型名
trangle
cube
star
运行labelImg
python labelImg.py
出现如下界面。
此时我们可以下载一个yolov5-6.1版本的代码包,并将其命名为yolov5-6.1-grapper-model,并在打开该代码包新建grippers文件夹,并在grappers文件夹路径下创建images与label文件夹
cd yolov5-6.1-grapper-model
mkdir grappers
cd grappers
mkdir images label
labelImg的使用
images文件夹用于放置图片集,labels文件夹用于放置标注集
将图片放进yolov5-6.1-grapper-model/grappers/images路径下,此时回到labelImg标注工具,点击Open dir,选择yolov5-6.1-grapper-model/grappers/images路径,接着点击Change Save Dir,选择yolov5-6.1-grapper-model/grappers/labels路径,进行标注集的存放,标注集的类型选择yolo。
接下去开始标注,如上述操作打开图片集,以一张图片为例进行标注,点击Create RectBox,之后对所需标注物体进行框选,框选出物体后会弹出选项框对进行选择,这样一张图片便标注好了。之后点击 Next Image选择下一张图进行标注,直至这200多张图片标注完成。
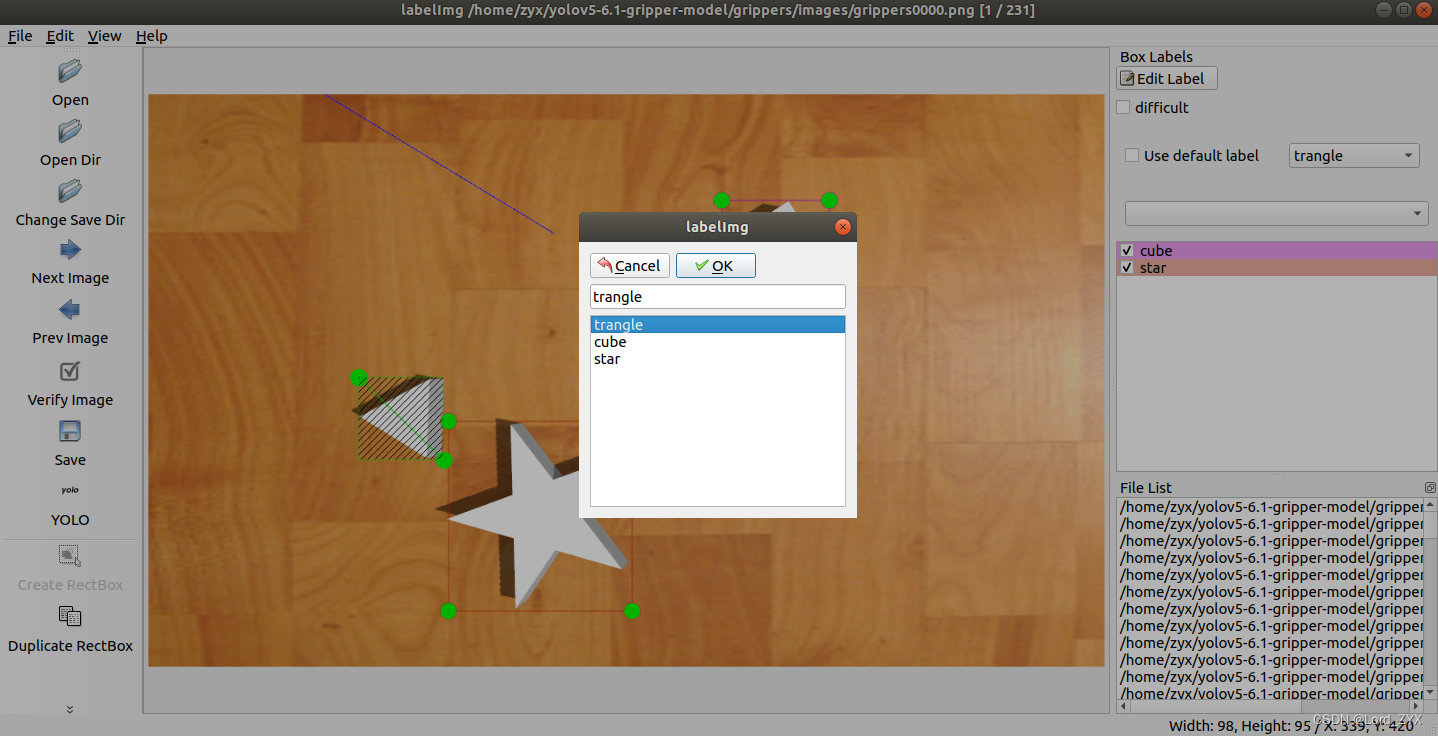
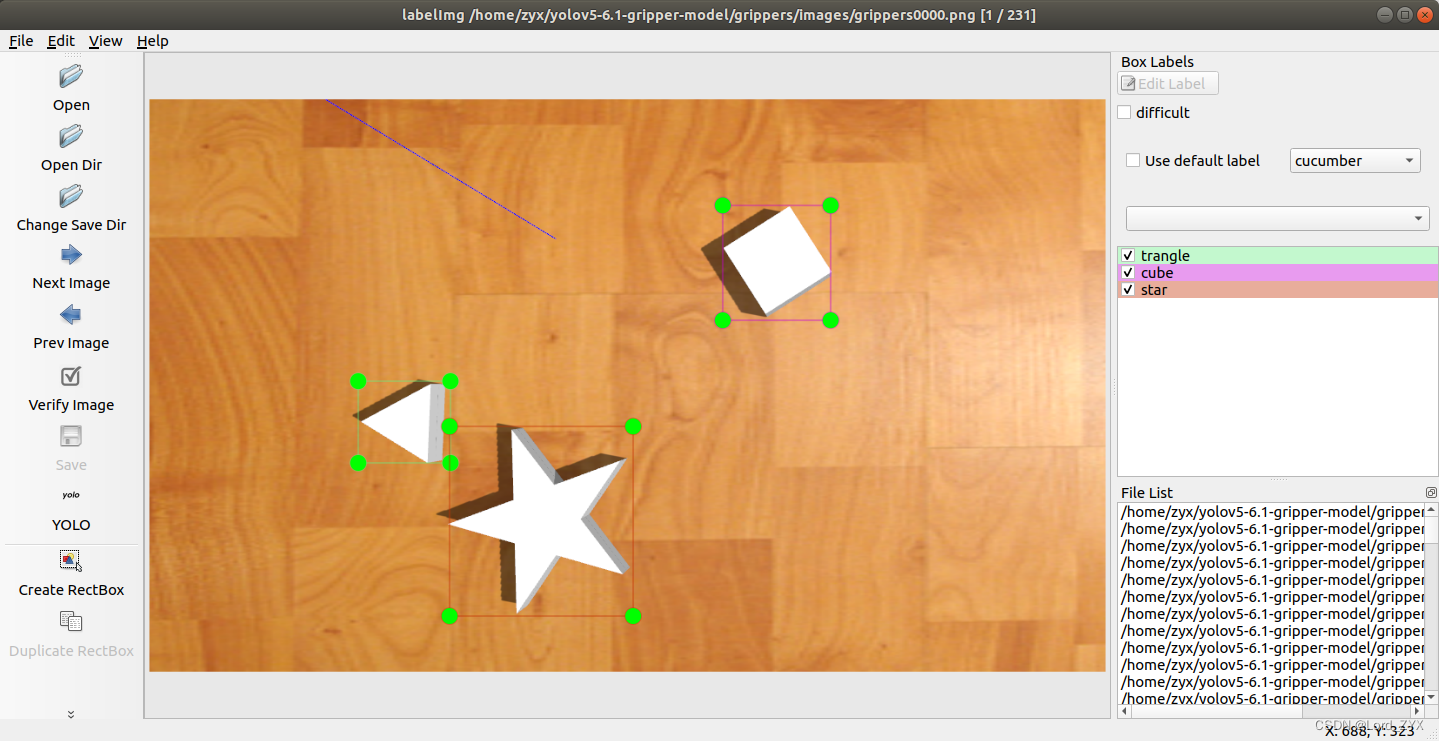
开始训练数据集
接着需要基于yolov5训练数据集,首先需要修改代码包中的一些文件
新建文件models_gripper.yaml
新建yolov5-6.1-grapper-model/data/models_gripper.yaml文件,该文件主要复制同路径下的coco128.yaml并进行修改,该文件加载了图像集以及标注集的路径,并将种类修改为自定义的种类。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# path: ../datasets/coco128 # dataset root dir
train: /home/zyx/yolov5-6.1-gripper-model/grippers/images # train images (relative to 'path') 128 images
val: /home/zyx/yolov5-6.1-gripper-model/grippers/images # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 3 # number of classes
names: ['star', 'cube', 'trangle'] # class names
# Download script/URL (optional)
# download: https://ultralytics.com/assets/coco128.zip
新建文件yolov5s_models.yaml
新建yolov5-6.1-grapper-model/models/yolov5s_models.yaml文件,该文件主要复制同路径下的yolov5s.yaml并进行修改,数量修改为对应识别classes的数量。
# Parameters
nc: 3 # number of classes
开始训练
在训练之前之前需要在yolov5-6.1-grapper-model/models路径下放置yolov5s.pt 预训练权重文件。
#进入conda环境
conda activate xxx
python train.py --data data/models_gripper.yaml --cfg models/yolov5s_models.yaml --weights weights/yolov5s.pt --batch-size 16 --epochs 50 --workers 4 --name gm-yolov5s2
#显存溢出时,可减小batch-size
可以看到模型正在训练了。
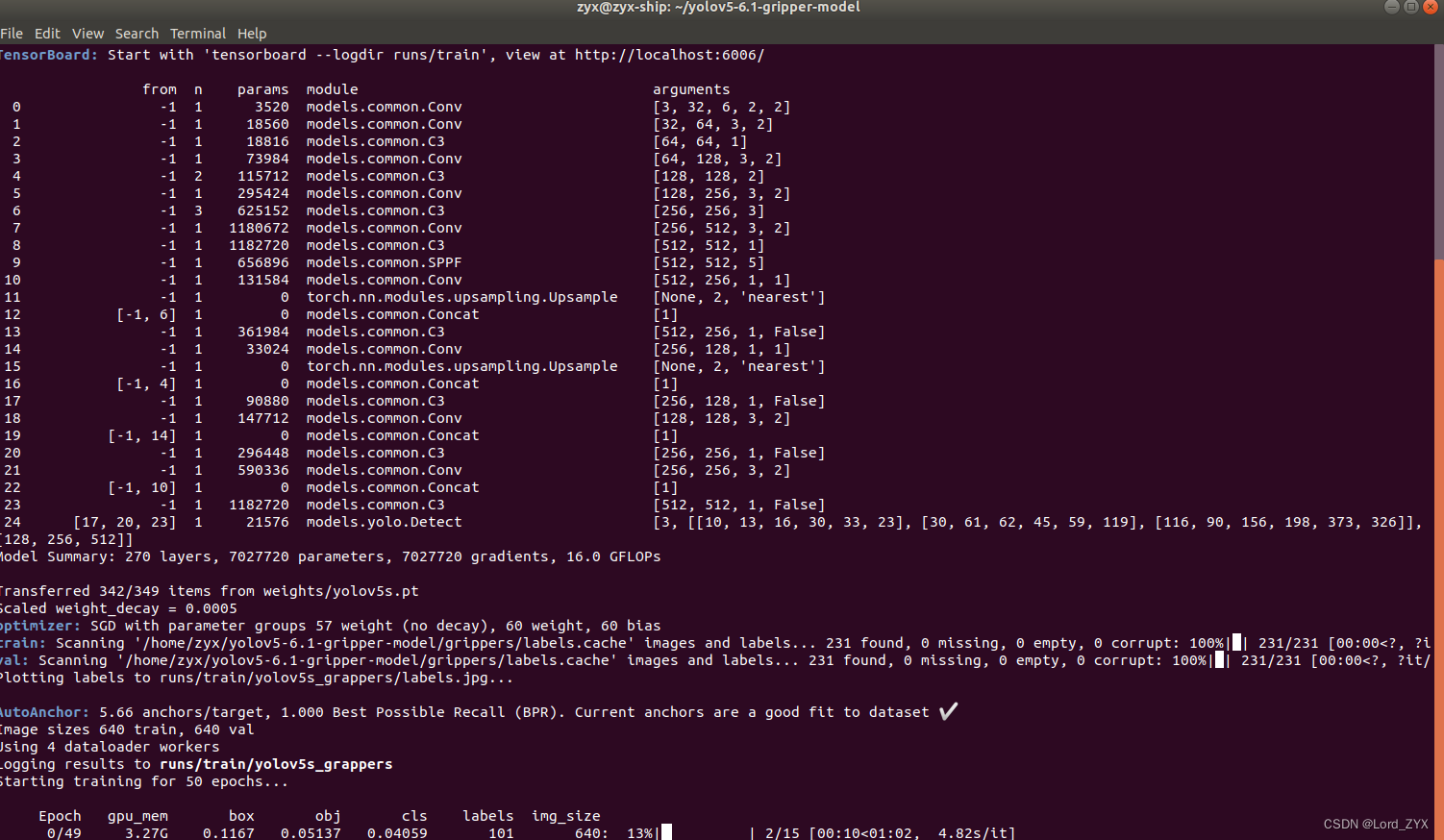
训练过程可视化:
yolov5路径下执行:
tensorboard --logdir=./runs
查看训练结果
在yolov5-6.1-grapper-model/runs/gm-yolov5s2路径下可看到训练结果。并且在yolov5-6.1-grapper-model/runs/gm-yolov5s2/weights路径下得到bsest.pt权重文件。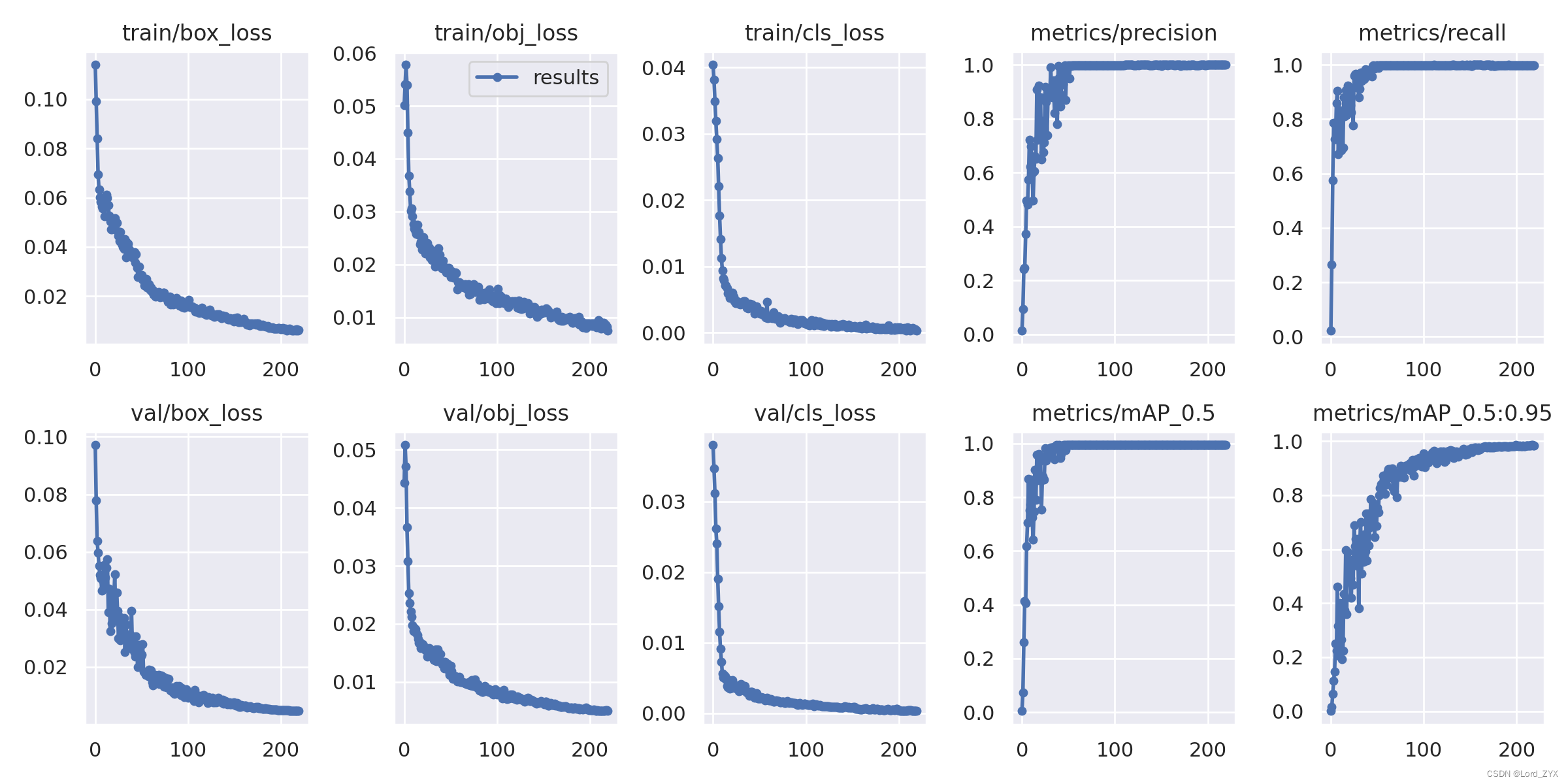
小结
本篇主要讲述使用yolov5训练自己创建数据集的过程,由于篇幅过长,原理部分不展开概述。


















 2014
2014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









