







摘要
关键词
1. Introduction
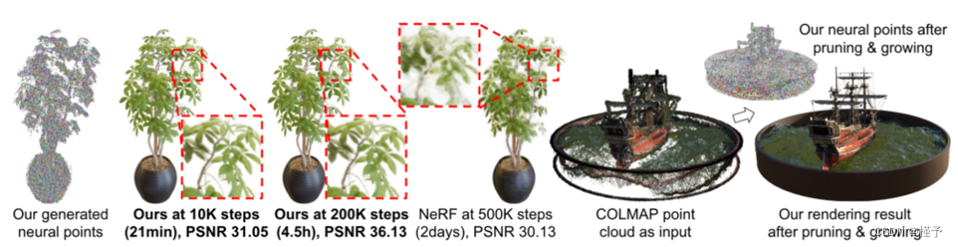
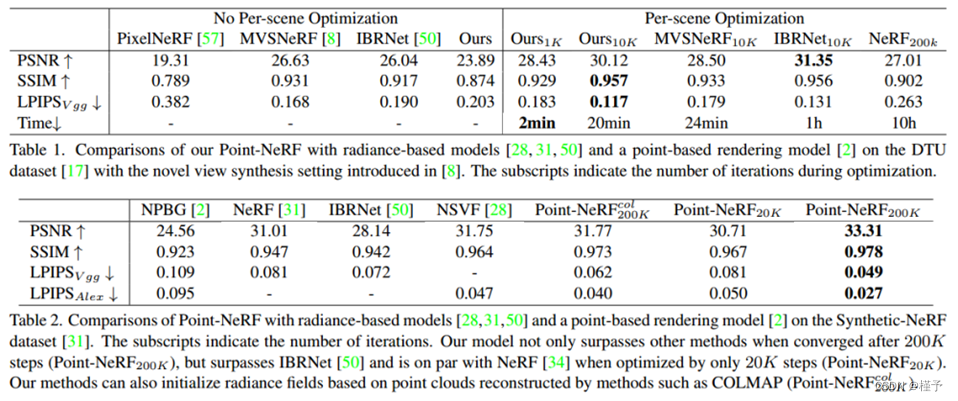
表1.比较我们的Point-NeRF与基于辐射的模型[28,31,50]和DTU数据集[17]上基于点的渲染模型[2],并在[8]中引入新的视图合成设置。下标表示优化期间的迭代次数。
2. Related Work
场景表示。传统方法和神经方法已经在各种视觉和图形应用中研究了许多三维场景表示,包括体[18, 24, 40, 44, 52]、点云[1, 39, 48]、网格[19, 49]、深度图[16, 27]和隐函数[9, 32, 36, 55]。最近,各种神经场景表征已被应用于不同的视觉和图形应用中 [4, 29, 45, 61] 。体积神经辐射场(NeRFs)[34] 可产生高保真效果,推动了新颖视图合成和逼真渲染技术的发展。NeRF 通常以全局 MLP 的形式重建[34, 37, 58],对整个场景空间进行编码;在重建复杂和大规模场景时,这种方法效率低下,成本高昂。相反,Point-NeRF 是一种局部神经表示法,它将体积辐射场与点云相结合,而点云通常用于近似场景几何图形。我们分布细粒度的神经点来模拟复杂的局部场景几何和外观,从而获得比 NeRF 更好的渲染质量(见图 6、图 7)。
多视图重建和渲染。多视角三维重建已得到广泛研究,并通过一系列从运动到结构[41, 46, 47]和多视角立体技术[10, 14, 24, 42, 54]得到解决。点云通常是 MVS 或深度传感器的直接输出,不过通常会转换成网格[20,30],用于渲染和可视化。网格化会带来误差,可能需要基于图像的渲染[6,12,60]才能实现高质量的渲染。相反,我们直接使用来自深度 MVS 的点云来实现逼真的渲染。
神经辐射场。NeRFs [34] 已在新颖的视图合成方面取得了显著的高质量效果。 它们已被扩展用于实现动态场景捕捉 [26, 38]、重新照明 [3, 5]、外观编辑 [53]、快速渲染 [15, 56] 和生成模型 [7, 35, 43]。不过,大多数方法 [3, 26, 38, 53] 仍沿用最初的 NeRF 框架,并训练每个场景的 MLP 来表示辐射场。我们利用场景中具有空间变化神经特征的神经点来编码其辐射场。与网络容量有限的纯 MLP 相比,这种局部表示法可以模拟更复杂的场景内容。更重要的是,我们展示了基于点的神经场可以通过预训练的深度神经网络进行高效初始化,从而实现跨场景泛化和高效的辐射场重建。
3. Point-Nerf Representation
我们提出了新颖的基于点的辐射场表示法,旨在实现高效的重建和渲染(见图 2 (b))。我们从一些前言开始。
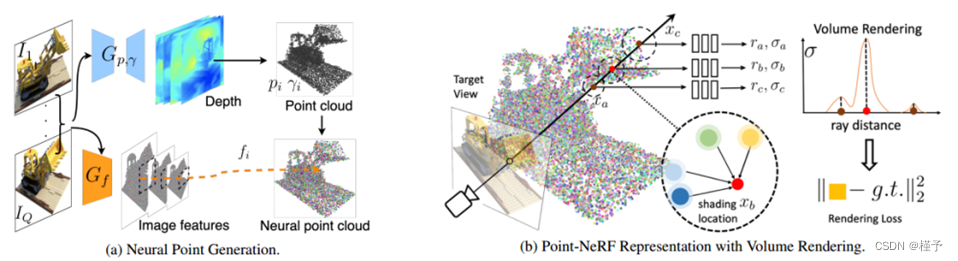
图2.Point-NeRF概述(a)从多视图图像中,我们的模型通过使用基于成本体的3D CNN Gp,γ来生成每个视图的深度,并通过2D CNN Gf从输入图像中提取2D特征。在对深度图进行聚合后,我们得到了一个基于点的辐射场,其中每个点具有空间位置pi、置信度γi和未投影图像特征fi。(b)为了合成一个新的视图,我们只在神经点云(例如xa, xb, xc)附近进行可微射线行进和计算阴影。在每个遮阳位置,point - nerf从它的K个神经点邻居中聚集特征,计算亮度r和体积密度σ,然后使用σ累积r。整个过程是端到端可训练的,基于点的亮度场可以优化渲染损失。
体积渲染和辐射场。基于物理的体渲染可以通过可微光线行进进行数值评估。具体来说,可以通过使光线穿过像素、在 {xj | 处采样 M 个着色点来计算像素的辐射亮度。 j = 1, ..., M} 沿射线,并使用体积密度累积辐射率,如下:
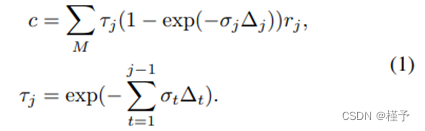
这里,τ 代表体积透射率;σj 和 rj 是 xj 处每个遮光点 j 的体积密度和辐射率,Δt 是相邻遮光样本之间的距离。
辐射场表示任意三维位置的体积密度 σ 和视图辐射率 r。NeRF [34] 建议使用多层感知器 (MLP) 来回归此类辐射场。我们提出的 Point-NeRF 则利用神经点云来计算体积属性,从而实现更快、更高质量的渲染。
基于点的辐射场。我们用P = {(pi, fi, γi)|i = 1,…, N},其中每个点i位于pi,并与编码局部场景内容的神经特征向量fi相关联。我们还为每个点分配一个比例置信度值γi∈[0,1],表示该点位于实际场景表面附近的可能性。我们从这个点云回归辐射场。
给定任何3D位置x,我们在一定半径r内查询其周围的K个相邻神经点。我们的基于点的亮度场可以抽象为一个神经模块,该模块可以在任何阴影位置回归体积密度σ和视图相关的亮度r(沿着任何观看方向d)从相邻的神经点得到x:
我们使用类似于pointnet的[39]神经网络,具有多个子mlp,来进行这种回归。总的来说,我们首先对每个神经点进行神经处理,然后将多点信息聚合得到最终的估计。
每点处理。我们使用MLP F处理每个相邻的神经点,通过以下方法预测阴影位置x的新特征向量:
本质上,原始特征fi编码了pi周围的局部3D场景内容。该MLP网络表示一个局部3D函数,该函数输出特定的神经场景描述fi,x在x处,由其局部帧中的神经点建模。相对位置x−p的使用使得网络对点平移具有不变性,从而更好地泛化。
视相关的亮度回归。我们使用标准的逆距离加权来聚合从这K个相邻点回归的神经特征fi,x,以获得描述x处场景外观的单个特征fx:
然后一个MLP R,根据给定的观察方向d,从该特征回归与视图相关的辐射:
反距离权值wi广泛应用于离散数据插值;我们利用它来聚合神经特征,使更接近的神经点对着色计算贡献更多。此外,我们在此过程中使用了逐点置信度γ;这在最后的重构中进行了优化,并减少了稀疏性损失,使网络能够灵活地拒绝不必要的点。
密度回归。为了计算x点处的体积密度σ,我们采用了类似的多点聚合。然而,我们首先使用MLP T回归每个点的密度σi,然后进行基于距离的逆加权,给出如下:
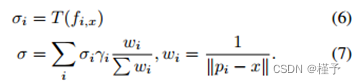
因此,每个神经点直接贡献体积密度,点置信度γi与此贡献显式相关。我们在点移除过程中利用了这一点(参见第4.2节)。
讨论。与之前基于神经点的方法[2,33]不同,我们的方法是栅格化点特征,然后用2D cnn渲染它们,我们的表示和渲染完全是3D的。通过使用近似的点云场景几何,我们的表示自然有效地适应场景表面,避免采样阴影位置在空场景空间。对于沿每条光线的阴影点,我们实现了一种高效的算法来查询相邻的神经点;细节见补充材料。
4. Point-Nerf Reconstruction
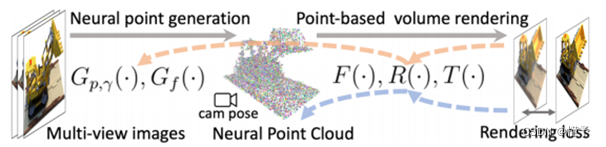
图3.虚线表示梯度更新的辐射场初始化和每个场景的优化。
4.1. 生成初始的基于点的亮度场
给定一组已知图像I1,…,IQ和一个点云,我们的point -NeRF表示可以通过优化随机初始化的每点神经特征和具有渲染损失(类似于NeRF)的mlp来重建。然而,这种纯粹的逐场景优化依赖于现有的点云,并且可能会非常慢。因此,我们提出了一个神经生成模块,通过前馈神经网络预测所有神经点属性,包括点位置pi,神经特征fi和点置信度γi,以实现高效重建。直接进入网络的参考输出一个良好的初始基于点的亮度场。然后可以对初始字段进行微调,以实现高质量的呈现。在很短的时间内,渲染质量更好或与NeRF相当,需要更长的时间来优化(见表1和表2)。
点位置和置信度。我们利用深度MVS方法使用基于成本体积的3D cnn生成3D点位置[10,54]。这样的网络产生高质量的密集几何结构,并且跨域泛化得很好。对于每个在视点q上具有相机参数Φq的输入图像Iq,我们遵循MVSNet[16],首先通过对相邻视点的2D图像特征进行扭曲来构建平面扫描的代价体积,然后使用深度3D cnn回归深度概率体积。深度图通过线性组合按概率加权的每平面深度值来计算。我们将深度图解投影到3D空间,得到一个点云{p1,…, pNq}每个视图q。
由于深度概率描述了点在表面上的可能性,我们对深度概率体积进行三线性采样,以获得每个点pi处的点置信度γi。上述过程可表示为:
其中Gp,γ为基于mvsnet的网络。Iq1, Φq1,…是MVS重建中使用的附加相邻视图;在大多数情况下,我们使用两个附加视图。
点的特性。我们使用2D CNN Gf从每个图像Iq中提取神经2D图像特征映射。这些特征映射与Gp,γ的点(深度)预测对齐,并用于直接预测每个点的特征fi:
特别地,我们为Gf使用了一个有三个下采样层的VGG网络架构。我们将不同分辨率的中间特征组合为fi,提供了一个有意义的点描述来模拟多尺度场景的外观。(见图2(a))
端到端重建。我们将多个视点的点云组合在一起,得到最终的神经点云。我们与表示网络一起训练点生成网络,从端到端具有渲染损失(见图3)。这允许我们的生成模块产生合理的初始辐射场。它还用合理的权重初始化我们的Point-NeRF表示中的mlp,显著节省了每个场景的拟合时间。
此外,除了使用完整的生成模块,我们的管道还支持使用从其他方法(如COLMAP[42])重建的点云,其中我们的模型(不包括MVS网络)仍然可以为每个点提供有意义的初始神经特征。具体请参考我们的补充材料。
4.2. 优化基于点的辐射场
上面的管道可以为一个新的场景输出一个合理的初始基于点的亮度场。通过可微射线推进,我们可以通过优化我们的表示中的神经点云(点特征fi和点置信度γi)和mlp来进一步改善特定场景的辐射场(见图3)。
修剪。如第3节所述,我们设计了点置信度值γi来描述神经点是否靠近场景表面。我们利用这些置信度值来修剪不必要的异常点。请注意,点置信度与体积密度回归中每个点的贡献直接相关(Eqn. 7);因此,低置信度反映了点局部区域的低体积密度,表明它是空的。因此,我们每10K次迭代就修剪γi < 0.1的点。
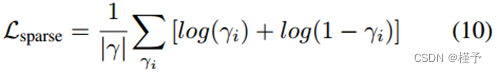
这迫使置信度值接近于零或1。如图4所示,这种修剪技术可以去除离群点,减少相应的伪影。
特别是,我们利用在光线行进中采样的每射线着色位置(Eqn. 1中的xj)来识别新的候选点。具体来说,我们确定沿光线不透明度最高的阴影位置xjg:
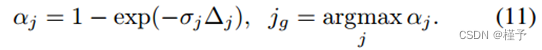
我们计算ϵjg为xjj到它最近的神经点的距离。
对于行进射线,如果αjg > Topacity, ϵjg > Tdist,我们在xjg处生长一个神经点。这意味着该位置位于表面附近,但远离其他神经点。通过重复这种增长策略,我们的亮度场可以扩展到覆盖初始点云中的缺失区域。点增长尤其有利于通过COLMAP等方法重建的点云,这些方法不密集(见图4)。我们表明,即使在只有1000个初始点的极端情况下,我们的技术也能够逐步增长新的点并合理地覆盖物体表面(见图5)。
5. Implementation details
网络的细节。我们对每点处理网络Gf的相对位置和每点特征以及网络r的观看方向进行频率位置编码,并在网络Gf中以不同分辨率从三层提取多尺度图像特征,从而得到具有56(8+16+32)个通道的矢量。我们还从每个输入视点附加相应的观看方向,以处理与视图相关的效果。因此,我们最终的逐点神经特征是一个59通道向量。请参考我们的补充资料,了解网络架构和遮阳时的神经点查询的细节。
训练和优化细节。我们在DTU数据集上训练我们的完整管道,使用与PixelNeRF和MVSNeRF相同的训练和测试分割。我们首先使用类似于原始MVSNet论文[54]的地面真值深度对基于MVSNet的深度生成网络进行预训练。然后,我们纯粹使用L2渲染损失Lrender从端到端训练我们的完整管道,用ground truth监督我们从光线行进(通过Eqn. 1)中渲染的像素,以获得我们的Point-NeRF重建网络。我们使用Adam[21]优化器训练整个管道,初始学习率为5e−4。我们的前馈网络从三个输入视图生成一个点云需要0.2s。
在逐场景优化阶段,我们采用了一种结合了渲染和稀疏度损失的损失函数![]()
我们用a = 2e - 3来做所有的实验。我们每10K次迭代执行点生长和修剪,以实现最终的高质量重建。
6. Experiments
6.1. DTU测试集的评估
6.2. 对NeRF合成数据集的评估
与一般化方法的比较。我们与IBRNet进行比较,据我们所知,IBRNet是之前最好的基于nerf的一般化模型,它可以处理任意数字的自由视点渲染。请注意,该数据集具有360度相机分布,比DTU数据集宽得多。在这种情况下,像MVSNeRF的方法不能应用,因为它从三个输入图像中恢复局部视角截锥体体积,不能覆盖整个360度观看范围。因此,在本实验中,我们将与IBRNet进行比较,并关注逐场景优化后的最终结果。我们使用他们发布的模型来产生结果。我们在20k次迭代(Point-NeRF20K)的结果已经优于IBRNet的聚合结果,具有更好的PSNR, SSIM和LIP-IPS;我们还通过更好的几何和纹理细节实现了渲染质量,如图7所示。
与纯逐场景方法的比较。我们在20K次迭代后的结果在数量上非常接近NeRF在200K次迭代训练后的结果。从视觉上看,我们的模型在20K次迭代下,在某些情况下已经有了更好的渲染效果,例如Fig. 7中的Ficus场景(第四行)。Point-NeRF20K的优化时间仅为40分钟,比NeRF的20多个小时优化时间至少快30倍。NSVF[28]的结果也是基于非常长的每场景优化,但只比我们的40分钟的结果稍微好一点。将我们的模型优化到200K,直到收敛,可以获得比NeRF, nsf和所有其他比较方法更好的结果。如图7所示,我们的200K结果包含了最多的几何和纹理细节。由于点生长技术,我们的方法是唯一一个可以完全恢复细节的方法,比如船场景(第二行)中的细绳结构。
与基于点的渲染的比较。我们的结果明显优于以前最先进的基于点的渲染方法。我们使用基于mvsnet的网络生成的相同点云来运行NPBG[2]。然而,NPBG的栅格化和2D CNN框架只能产生模糊的渲染结果。相比之下,我们利用体积渲染技术与神经辐射场,导致照片逼真的结果。
6.3. 对Tanks & Temples和ScanNet数据集的评估
我们在表3中比较了坦克与神庙和ScanNet数据集上的Point-NeRF与nssvf。更多的对比请参考补充材料。

表3.对Tanks & Temples和ScanNet数据集的定量结果(PSNR / SSIM / LPIPSAlex)。
6.4. 额外的实验
将COLMAP点云转换为point - nerf。除了使用我们的完整管道外,point- nerf还可以用于将其他技术重建的标准点云转换为基于点的辐射场。我们在完整的NeRF合成数据集上运行实验,使用COLMAP重建的点云[42]。定量结果如表2中的Point-NeRFcol所示。由于COLMAP点云可能包含大量的洞(如图1所示)和噪声,我们在初始化后将模型优化为200K,用我们的点生长和修剪技术来解决点云问题。请注意,即使从这个低质量的点云,我们的最终结果仍然与所有其他方法相比,具有非常高的SSIM和LPIPS数。这表明我们的技术可以潜在地与任何现有的点云重建技术相结合,以实现逼真的渲染,同时改善点云几何。
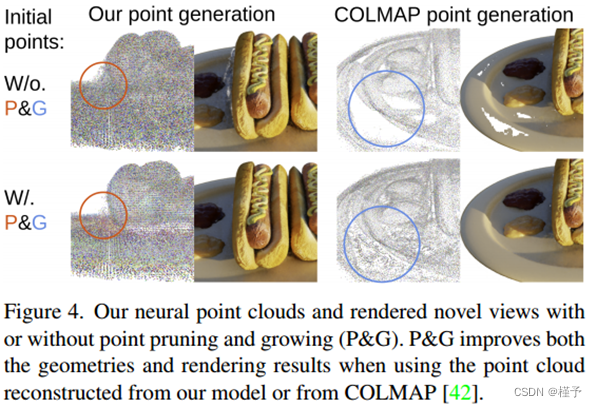
图4.我们的神经点云和渲染新颖的观点有或没有点修剪和生长(宝洁)。P&G在使用从我们的模型或COLMAP[42]重建的点云时,改进了几何形状和渲染结果。

图5.从椅子场景的1000个随机采样的COLMAP点开始,我们的点生长机制可以帮助完成几何图形,并在仅由RGB图像监督的情况下生成高质量的新视图。
点生长和修剪。为了进一步证明我们的点生长和剪枝模块的有效性,我们展示了在逐场景优化中有和没有点生长和剪枝的消融研究结果。我们在热狗和轮船场景上进行了这个实验,使用我们的完整模型和我们的带有COLMAP点云的模型。定量结果见表4;我们的点生长和修剪技术非常有效,显著改善了这两种情况的重建结果。我们还在图4中展示了热狗场景的视觉结果。我们可以清楚地看到,我们的模型能够在原始COLMAP点云中对左侧的点异常点进行修剪,并成功填充右侧的严重空洞。
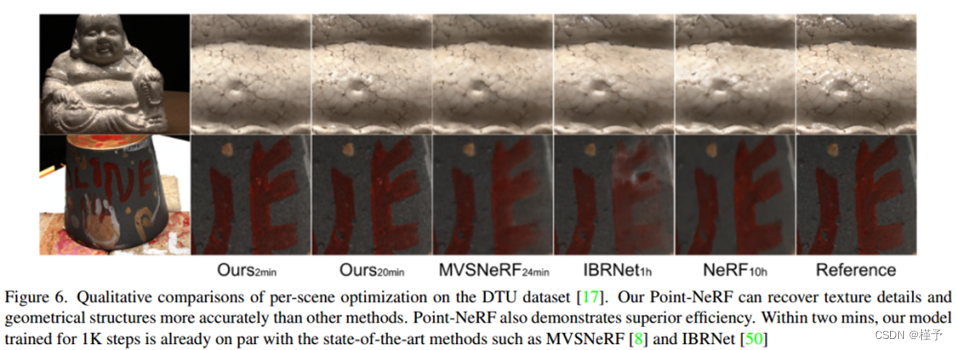

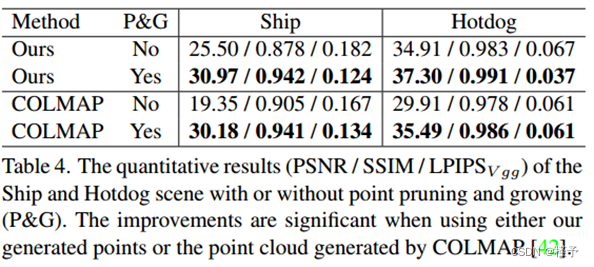
表4.船舶和热狗场景有或没有点修剪和生长(P&G)的定量结果(PSNR / SSIM / LPIPSV gg)。无论是使用我们生成的点还是使用COLMAP生成的点云[42],这些改进都是显著的。
7. 结论
在本文中,我们提出了一种高质量神经场景重建和渲染的新方法。我们提出了一种新的神经场景表示- point - nerf -用神经点云对体积辐射场进行建模。我们通过直接网络推理直接从输入图像中重建了一个良好的Point-NeRF初始化,并表明我们可以有效地对场景的初始化进行微调。这使得每个场景优化只需20 - 40分钟即可实现高效的Point-NeRF重建,从而导致渲染质量与需要更长的训练时间(20+小时)的NeRF相当甚至超过NeRF。我们还提出了新的有效的生长和修剪技术,用于我们的逐场景优化,显著改善了我们的结果,并使我们的方法在不同的点云质量下具有鲁棒性。我们的point - nerf成功地结合了经典点云表示和神经辐射场表示的优点,朝着高效、逼真的实际场景重建解决方案迈出了重要的一步。

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









