






引言:语义导航是机器人实现复杂环境中自主探索的一项关键能力。在陌生环境中,机器人需要像人类一样,利用语义知识来推断空间布局,包括特定物体的位置和几何属性。例如,我们知道厕所和淋浴通常一起出现在浴室中,且通常靠近卧室。通过自然语言可以增强这种先验语义知识,从而更有效地指导机器人在未知环境中的探索。目前,传统的导航方法往往依赖于预构建的地图和特定任务的训练,这极大限制了机器人在新环境中的适应能力。此论文提出了一种零样本语义导航方法——视觉-语言前沿地图(VLFM),该方法受人类推理过程启发,能够在没有任务特定训练、预构建地图或环境先验知识的情况下,导航至期望目标。
【基本信息】
论文标题:VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
发表期刊:ICRA,Best paper in Cognitive Robotics
发表时间:2024年5月
【访问链接】
论文链接: https://openreview.net/pdf?id=gdw1zUTABk
代码仓库:https://github.com/bdaiinstitute/vlfm
【背景简介】
在机器人导航领域,目标导向导航(ObjectNav)是一个重要的研究方向。ObjectNav 任务要求机器人在未知环境中导航到特定的目标。这一任务的性能主要通过机器人路径的效率来衡量,即机器人能否高效地找到目标对象。对良好的语义先验知识的利用可以显著提高机器人定位目标对象的效率。传统的训练方法通常依赖于强化学习、模仿学习或预测语义俯视图,这些方法在模拟环境中表现出色,但在真实世界中的部署面临挑战,因为它们通常只在训练时使用的封闭对象集上有效,且往往仅在模拟数据上进行训练。
近年来,零样本目标导向导航(Zero-shot ObjectNav)方法逐渐兴起。这些方法旨在适应开放集的对象类别,通过大量真实世界数据上训练的模型实现在真实世界中的语义导航。与传统的任务特定训练方法不同,零样本方法不需要预构建的地图或特定任务的训练数据。
目前,基于前沿/边界的探索方法( frontier-based exploration method)有:
经典方法:基于前沿的探索方法涉及访问地图上已探索和未探索区域之间的边界,这些边界是机器人在探索过程中逐步构建的。经典/传统的方法通过接收预定义将要感知到的信息进行边界判断。
CLIP on Wheels (CoW):CoW 采用了一种直接粗暴的方法,即机器人不断探索最近的前沿边界,直到使用 CLIP 特征或开放词汇对象检测器检测到目标对象。
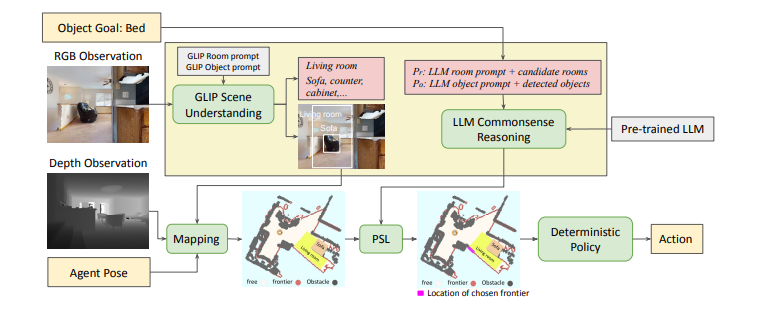
LGX 和 ESC:LGX 和 ESC 使用大型语言模型(LLM)处理以文本形式呈现的对象检测结果,以识别最有可能包含目标对象实例的前沿边界。
SemUtil:SemUtil 方法使用 BERT(Bidirectional Encoder Representations from Transformers)模型来处理在机器人探索过程中检测到的对象类别标签。具体来说,它将这些标签嵌入到一个高维向量空间中,然后将这些嵌入向量与目标对象的文本嵌入/向量进行比较,以确定哪个前沿边界最有可能包含目标对象,从而选择下一个要探索的前沿边界。
然而,这些方法存在一个瓶颈,即环境中的视觉线索必须先由对象检测器转换为文本,然后才能用于语义评估前沿边界。此外,依赖 LLM 需要大量的计算资源,可能需要机器人连接到远程服务器。
【核心科学问题】
1. 如何在未知环境中实现高效的目标导向导航:传统的导航方法通常依赖于预构建的地图和特定任务的训练数据,这限制了机器人在新环境中的适应能力。
2. 如何高效地评估和选择前沿边界:在基于前沿边界的探索方法中,如何选择下一个要探索的前沿边界是一个关键问题。许多方法依赖于对象检测器将视觉线索转换为文本,然后使用大型语言模型(LLM)进行语义评估,这不仅增加了计算资源的需求,还引入了转换过程中的误差。
3. 如何提高导航的语义理解能力:机器人在导航过程中需要基于高级语义概念(如房间类型或物体类型)来理解和导航环境,而不仅仅依赖于几何线索。这要求机器人能够有效地利用语义先验知识,以更高效地定位目标对象。
4. 如何在真实世界中部署和应用:尽管许多导航方法在模拟环境中表现出色,但在真实世界中的部署面临诸多挑战,如地图精度低、定位精度低频率慢等。
【核心研究思路】
此论文主要解决的问题是如何在未知环境中实现零样本语义导航,即智能体/机器人在没有任务特定训练、预构建地图或环境先验知识的情况下,能够导航到目标语义对象。这一问题的难点在于如何高效地评估和选择前沿边界,以及如何在真实世界中成功部署和应用这些方法
VLFM 方法的核心研究思路可以概括为图示几个步骤:
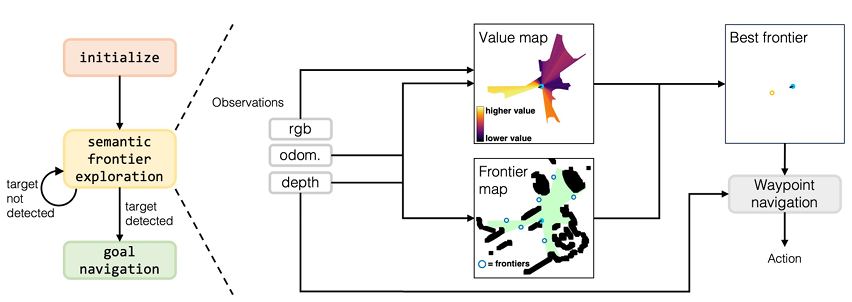
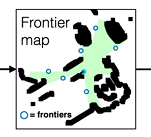
1.前沿边界生成:
利用深度观测数据构建一个2D俯视地图,识别出已探索区域的边界作为前沿边界。具体来说,将当前深度图像转换为点云,过滤掉过短或过高的点,转换到全局坐标系后投影到2D网格上,识别每个边界的中点作为潜在的前沿边界点(frontiers)。
2.价值地图生成:
利用预训练的视觉-语言模型(VLM)直接从RGB图像中提取语义值,生成一个语言感知的价值图。这个价值图为已探索区域内的每个像素分配一个值,量化其在定位目标对象方面的语义相关性。具体来说,VLFM 使用预训练的视觉-语言模型(如CLIP)从RGB图像中提取特征,并将这些特征与目标对象的文本嵌入/向量进行比较,生成语义价值分数。
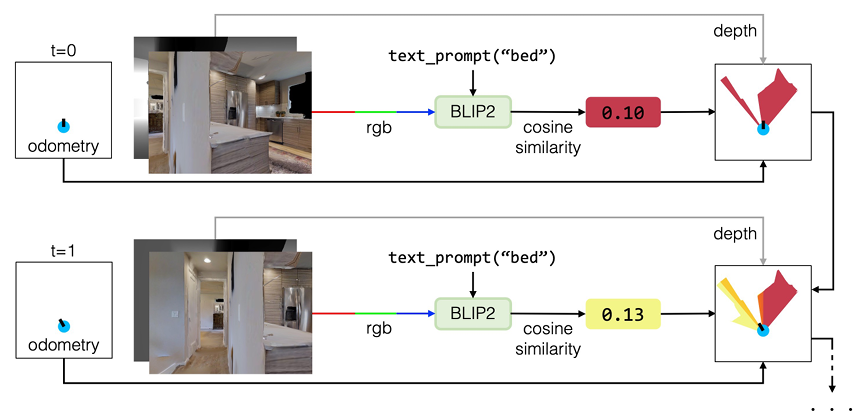
3. 前沿边界选择
使用生成的价值图识别最有希望探索的前沿边界。即,VLFM 通过计算每个前沿边界的价值分数,选择价值分数最高的前沿边界作为下一个探索目标。这种方法避免了将环境中的视觉线索转换为文本的复杂步骤,提高了效率和准确性。
4. 导航和路径规划
从当前位置到下一个前沿边界采用点导航(PointNav)技术进行导航。如果在探索过程中检测到目标对象,VLFM 会使用点导航技术导航到目标对象附近,并调用停止动作。
【实验结果】
论文提出的方法在多个公开数据集上进行了测试,并与SOTA方法进行了对比分析。
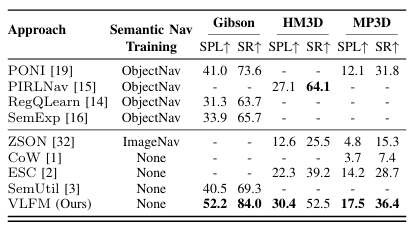
1. VLFM 在所有基准测试中均显著优于其他零样本方法
Gibson 数据集上,VLFM 的效率分数SPL(Success weighted by inverse Path Length)比 SemUtil方法 高 11.7%,成功率SR(success rate) 高 14.7%。
HM3D 数据集上,VLFM 的 SPL 比 ESC方法 高 8.1%,SR 高 13.3%。
MP3D 数据集上,VLFM 的 SPL 比 ESC方法 高 3.3%,SR 高 7.7%。
2. VLFM 甚至超越了那些直接在Gibson 和 MP3D 数据集上训练的方法
Gibson 数据集上,VLFM 的 SPL 比 SemExp方法 高 19.2%,SR 高 19.0%。
MP3D 数据集上,VLFM 的 SPL 比 PONI方法 高 5.4%,SR 高 4.6%。
HM3D 数据集上,VLFM 仅在成功率上略低于 PIRLNav方法(-11.6% SR,但 +3.3% SPL)。但PIRLNav 是在 HM3D 数据集的 77k 个人类示例上训练的,而 VLFM 是零样本方法。
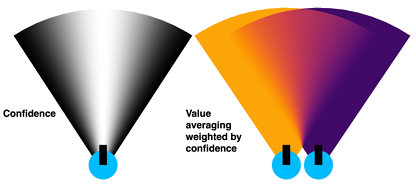
3. 消融实验结果
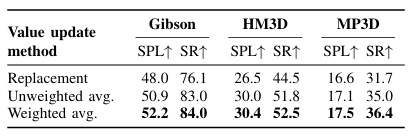
Gibson数据集上,加权平均方法的SPL为52.2%,比替换方法高4.2%,比未加权平均方法高1.3%。
HM3D数据集上,加权平均方法的SPL为30.4%,比替换方法高3.9%,比未加权平均方法高0.4%。
MP3D数据集上,加权平均方法的SPL为17.5%,比替换方法高0.9%,比未加权平均方法高0.4%。
消融实验(Ablation Study)是一种用于评估模型中各个组件或设计选择对整体性能影响的实验方法。通过逐步移除或修改某些组件,观察性能的变化,从而了解每个组件的重要性。此论文中,消融实验用于评估机器人在看到与先前相同的场景时不同值更新方法对模型性能的影响。论文中比较了三种值更新方法:1.替换(Replace):直接用新的值替换旧的值。2.未加权平均(Unweighted Average):将新值和旧值进行简单的平均。3.加权平均(Weighted Average):将新值和旧值进行加权平均,新值的权重更高。
4. 真实世界部署
VLFM 方法在波士顿动力公司的 Spot 移动机器人上进行了部署,成功展示了其在真实世界中导航到目标对象的能力。尽管 Spot 的深度感知范围有限(团队使用 ZoeDepth 深度估计模型来近似检测目标的航点),但 VLFM 仍能有效地导航到目标对象。所有模型,包括 BLIP-2、GroundingDINO、MobileSAM 和 ZoeDepth,都在配备了RTX 4090 MaxQ Mobile GPU 和 16 GB VRAM 的笔记本电脑上实时加载和运行。
论文视频:
更多的视频详见:https://naoki.io/portfolio/vlfm
结论:VLFM 方法在多个数据集上显著优于其他零样本方法,甚至在 Gibson 和 MP3D 数据集上超越了直接在这些数据集上训练的方法。此外,VLFM 在真实世界中的部署也取得了成功,证明了其在实际应用中的可行性。


















 5221
5221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











