







大型语言模型的低秩自适应 (LoRA) 用于解决微调大型语言模型 (LLM) 的挑战。GPT 和 Llama 等模型拥有数十亿个参数,通常对于特定任务或领域进行微调的成本过高。LoRA 保留了预训练的模型权重,并在每个模型块中加入了可训练层。这显著减少了需要微调的参数数量,并大大降低了 GPU 内存需求。LoRA 的主要优势在于,它大幅减少了可训练参数的数量——有时最多可减少 10,000 倍——从而大大降低了 GPU 资源需求。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、LoRA 为何有效
预训练的 LLM 在适应新任务时具有较低的“固有维度”,这意味着数据可以通过低维空间有效地表示或近似,同时保留其大部分基本信息或结构。我们可以将适应任务的新权重矩阵分解为低维(较小)矩阵,而不会丢失大量重要信息。我们通过低秩近似实现这一点。
矩阵的秩是一个可以让你了解矩阵复杂度的值。矩阵的低秩近似旨在尽可能接近原始矩阵,但秩较低。低秩矩阵降低了计算复杂度,从而提高了矩阵乘法的效率。低秩分解是指通过推导矩阵 A 的低秩近似来有效近似矩阵 A 的过程。奇异值分解 (SVD) 是一种常用的低秩分解方法。
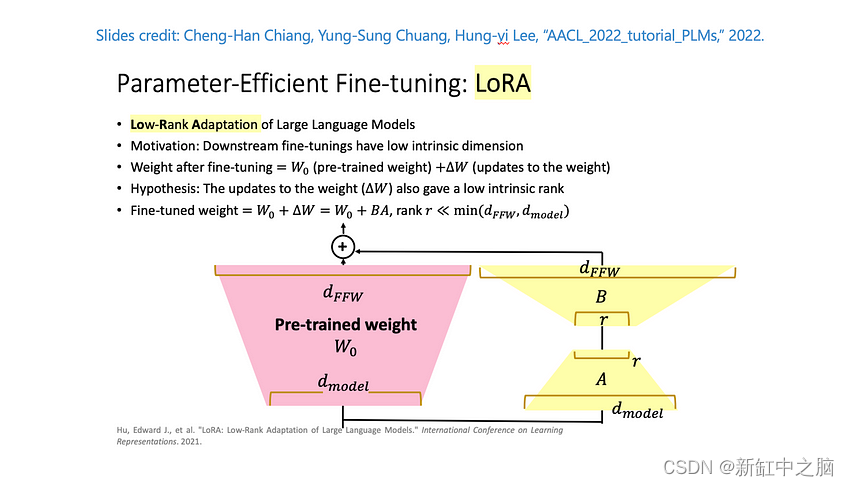
假设 W 表示给定神经网络层中的权重矩阵,假设 ΔW 是经过完全微调后 W 的权重更新。然后,我们可以将权重更新矩阵 ΔW 分解为两个较小的矩阵:ΔW = WA*WB,其中 WA 是 A × r 维矩阵,WB 是 r × B 维矩阵。在这里,我们保持原始权重 W 不变,只训练新矩阵 WA 和 WB。这总结了 LoRA 方法,如下图所示。
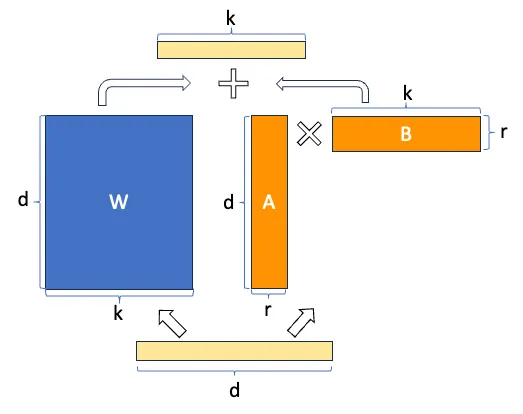
LoRA 的优势如下:
- 减少资源消耗。对深度学习模型进行微调通常需要大量计算资源,这可能既昂贵又耗时。LoRA 可在保持高性能的同时减少对资源的需求。
- 更快的迭代。LoRA 可实现快速迭代,从而更轻松地尝试不同的微调任务并快速调整模型。
- 改进迁移学习。LoRA 提高了迁移学习的有效性,因为带有 LoRA 适配器的模型可以用更少的数据进行微调。这在标记数据稀缺的情况下尤其有价值。
- 广泛适用。LoRA 用途广泛,可应用于自然语言处理、计算机视觉和语音识别等不同领域。
- 降低碳排放。通过减少计算要求,LoRA 有助于实现更环保、更可持续的深度学习方法。
2、使用 LoRA 技术训练神经网络
在此博客中,我们利用 CIFAR-10 数据集,使用几个epoch从头开始训练基本图像分类器。之后,我们进一步使用 LoRA 训练模型,说明将 LoRA 纳入训练过程的优势。
2.1 设置
此演示使用以下设置创建。有关全面的支持详细信息,请参阅 ROCm 文档。
硬件和操作系统:
- AMD Instinct GPU
- Ubuntu 22.04.3 LTS
软件:
- ROCm 5.7.0+
- Pytorch 2.0+
2.2 训练初始模型
导入软件包:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7499
7499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









