






有人认为,在软件开发领域,不够理想的创新,加上不够理想的开发人员采用和社区,都会逐渐变得无关紧要。在当今狂热而混乱的生成式人工智能世界中,每天都会出现更好的“做事方式”,每种方式的支持者都以极具感染力的热情宣扬它们优于其他创新的优点。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
DSPy(发音为 dee-s-pie)是斯坦福 NLP 编程语言模型的新框架,它不是一个理想的创新吗?它是否如其一些支持者所言,是对提示工程技术的替代?最后,框架的目标是否可以通过用系统、模块化和可组合的程序取代巧妙而熟练但繁琐而脆弱的提示构造来实现?
在本文中,我将研究 DSPy 的前景和困惑之处、不足之处和需要改进之处;以及它如何构建模块化管道以与 LLM 交互。通过几个端到端的提示示例,我将把现有的提示技术转换为等效的 DSPy 模块化版本,并在此过程中评估其优点。你可以在 Google Colab 和 GitHub 上的 Python 应用程序上仔细阅读这些 IPython 笔记本。
图 1a. Python DSPy 笔记本展示如何使用 DSPy 模块

图 1b. Python DSPy 应用程序展示如何使用 DSPy 模块
1、DSPy 编程模型
ML 社区正在快速发展提示语言模型 (LM) 的技术,并将其集成到管道中以处理复杂的任务。然而,当前的 LM 管道通常依赖于硬编码的“提示模板”,这些模板是通过反复试验开发的冗长、脆弱、易碎且手工制作的提示 [1]。
斯坦福大学 NLP 小组的研究人员 Omar Khatab 和 Arnav Singhvi 等人认为,这种方法虽然很常见,但可能很脆弱、易碎且不可扩展,类似于手动调整分类器权重。此外,特定或复杂的字符串提示可能无法很好地推广到不同的管道、语言模型、数据域或输入 [2]。
因此,他们提出了一种更具声明性、系统性和程序性的方法来与语言模型交互——这是 PyTorch 和 Python 开发人员在开发机器学习 (ML) 程序和 ML 相关概念时习惯的方法。
DSPy 编程模型包含三个高级抽象:签名、模块和提词器(又称优化器)。签名抽象并规定模块的输入/输出行为;模块取代现有的手动提示技术,可以组合成任意管道;提词器通过编译优化管道中的所有模块以最大化指标 [3]。
我们先从签名开始。
2、签名抽象了提示
DSPy 签名是一种自然语言类型的函数声明:简洁的规范,描述文本转换应实现的目标(例如,“处理问题并返回答案”),而不是详细说明应如何提示特定 LM 执行该任务。
因此,它们比提示有两个优势。首先,它们可以编译成自我改进、管道自适应的提示,或者通过为每个签名引导有用的示例进行微调。其次,它们管理结构化的格式和解析逻辑,减少或理想情况下消除用户程序中的脆弱字符串操作 [4]。
“签名是 DSPy 模块输入/输出行为的声明性规范。签名允许你告诉 LM 它需要做什么,而不是指定我们应该如何要求 LM 去做,”文档指出。[5]
例如,你可以使用简写字符串符号作为参数来声明性地定义 DSPy 签名对象。实际上,这个签名现在将任务声明为一个简洁的提示:给出一个问题,返回一个答案。简而言之,这个简写符号是你对简单任务的提示的声明性替换。以下是一些简写符号的示例:
import dspy
sig_1 = dspy.Signature(“question -> answer”)
sig_2 = dspy.Signature(“document -> summary”)
sig_3 = dspy.Signature(“question, context -> answer”)除了使用内联简写符号来声明任务之外,你还可以定义基于类的签名,从而更好地控制输入/输出字段格式、样式和描述性任务描述。任务描述是类定义中的 Python 文档字符串。输出的格式、样式或行为可以是 dspy.OutputField 的描述性和声明性参数,从而更容易对其进行调整,而不是将其作为较大提示的一部分。
class BasicQA(dspy.Signature):
“””Answer questions with short factoid answers”””
question = dspy.InputField()
answer = dspy.OutputField(desc=”often between 1 and 5 words”,
prefix=”Question’s Answer:”)在内部,DSPy 将上述两种声明格式转换为底层 LLM 的提示,如图 2 所示。或者,使用 DSPy 提词器(优化器),可以编译这些提示以迭代生成优化的 LLM 提示(请参阅下面关于优化器的部分),类似于如何在 PyTorch 等 ML 框架中使用学习优化器(例如 SGD)优化 ML 模型。
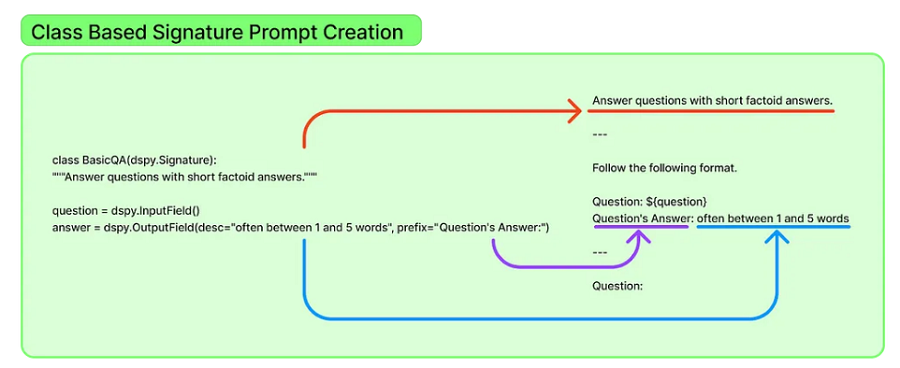
图 2. 基于类的声明式签名转换为 LLM 提示
使用上述基于类的签名简单且直观。
generate_response = dspy.Predict(BasicQA)
pred = generate_resonse(question=”When was the last Solar Eclipse in the United States, and what states were covered in total darkness?”
print(f”Answer: {pred.answer}”)👍👍👍:使用任务描述作为 Python 类文档字符串或简写符号来生成 LLM 提示,而无需手工制作提示,这与 DSPy 框架的一个关键断言一致。感觉就像 Python 编程,而不是手工制作精细的提示。转换图 1(a) 和 1(b) 中的一些提示技术示例让我产生了这种感觉。
虽然 dspy.Signature 类是核心构建块,但 DSPy 还包括内置模块,可以有效地转换为提示技术,如思路链、ReAct、RAG、思维程序和复杂推理。
所有这些模块的核心是 dspy.Predict 模块,包括 Signature 在内的所有模块都通过其 forward() 函数调用来调用该模块。在内部,Predict 存储 Signature 并使用它来构造提示。
接下来让我们探索这些模块。
3、模块构建复杂管道
根据 DSPy 文档,DSPy 模块是构建使用语言模型的 DSPy 管道或程序的基本构建块。每个模块都抽象出一种提示技术,例如思路链或 ReAct,并被推广到处理任何 DSPy 签名。
模块可以具有可学习的参数,包括提示组件和 LM 权重。作为可调用类,它们可以通过输入和返回输出进行调用。由于它们是构建块,因此可以将多个模块组合成更大的可组合程序作为管道。受 PyTorch 中 NN 模块的启发,DSPy 模块专为 LLM 程序而设计 [6]。
作为可调用类,模块可以通过输入和返回输出进行调用。由于它们是构建块,因此可以将多个模块组合成更大的程序作为管道。受 PyTorch 中 NN 模块的启发,DSPy 模块专为 LLM 程序而设计。
将模块视为简化复杂提示技术的智能捷径。它们就像预制块,你可以将它们拼合在一起来构建程序。我们鼓励你创建自己的模块,这也是在 DSPy 中构建复杂数据管道程序的核心方法。这些模块可以独立运行,也可以组合成管道以完成更复杂的任务,并且可以用于各种应用程序 [7]。
例如,我可以使用简写签名符号定义一个独立的 ChainOfThought 模块。
class ChainOfThought(dspy.Module):
def __init__( self, signature):
super().__init__()
self.predict = dspy.Signature(signature)
# overwrite the forward function
def forward(self, **kwargs):
return self.predict(**kwargs)
# create an instance of class with shorthand Signature notation
# as argument
cot_generate = ChainOfThought(“context, question → answer”)
# call the instance with input parameters specified in the
# signature
response = cot_generate(“context=....”,
“question=How to compute area of a triangle with height 5 feet and width 3 feet.”
print(f”Area of triangle: {response.answer}”)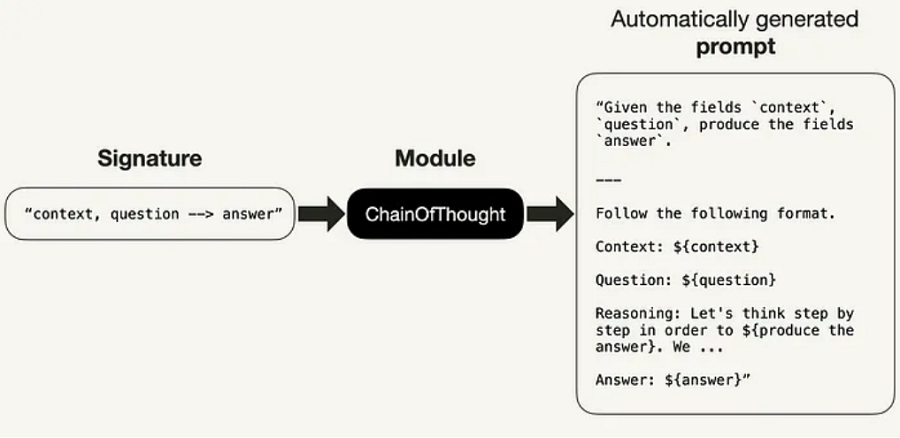
图 3. 作为 LLM 提示生成的带有简写签名的模块 [8]
让我们更进一步地理解这个概念,并使用我们上面定义的构建块以及内置的 dspy.Retriever 模块构建一个可组合管道,以说明如何创建可组合管道作为 RAG DSPy 程序。
class RAGSignature(dspy.Signature):
"""
Given a context and question, answer the question.
"""
context = dspy.InputField()
question = dspy.InputField()
answer = dspy.OutputField()
class RAG(dspy.Module) :
def __init__ ( self , num_passages=3) :
super().__init__()
# Retrieve will use the user’s default retrieval settings
# unless overridden .
self.retrieve = dspy.Retrieve(k=num_passages)
# ChainOfThought with signature that generates
# answers given retrieval context & question .
self.generate_answer = dspy.ChainOfThought(RAGSignature)
def forward (self, question) :
context = self.retrieve (question).passages
return self.generate_answer(context=context, question=question)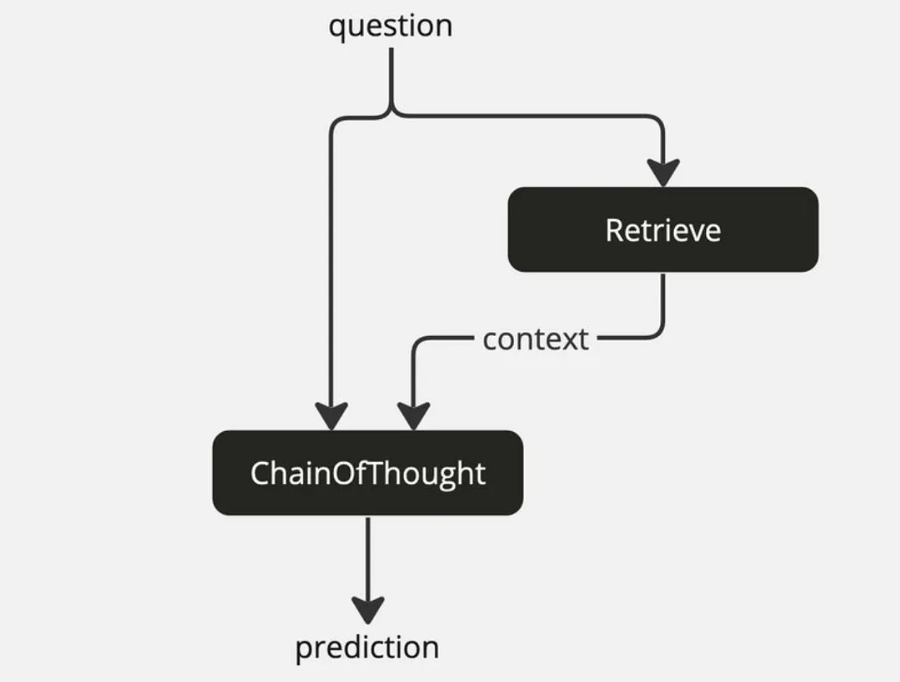
图 4:带有 Retrieve 和 ChainOfThought 的可组合 DSPy RAG 程序模块管道
要查看带有 DSPy 模块的 Naive RAG 的完整实现,请仔细阅读图 1(a) 和 1(b) 中的链接。
👍👍👍:DSPy 模块是 Python 声明性代码,封装了您的任务逻辑(做什么而不是怎么做)、行为、输入/输出格式、样式和任何自定义代码。无需编写小说作为复杂的提示,无需反复试验提示。相反,将您的流程构建为可组合块的管道。我更喜欢编写 Python 代码而不是英语,尽管我确实喜欢写作。让 DSPy 完成生成提示和与语言模型交互的工作。
内置模块(列于下表)可以很好地映射到常见的提示技术,并且可扩展和可定制。在撰写本文时,以下 DSPy 模块可用:
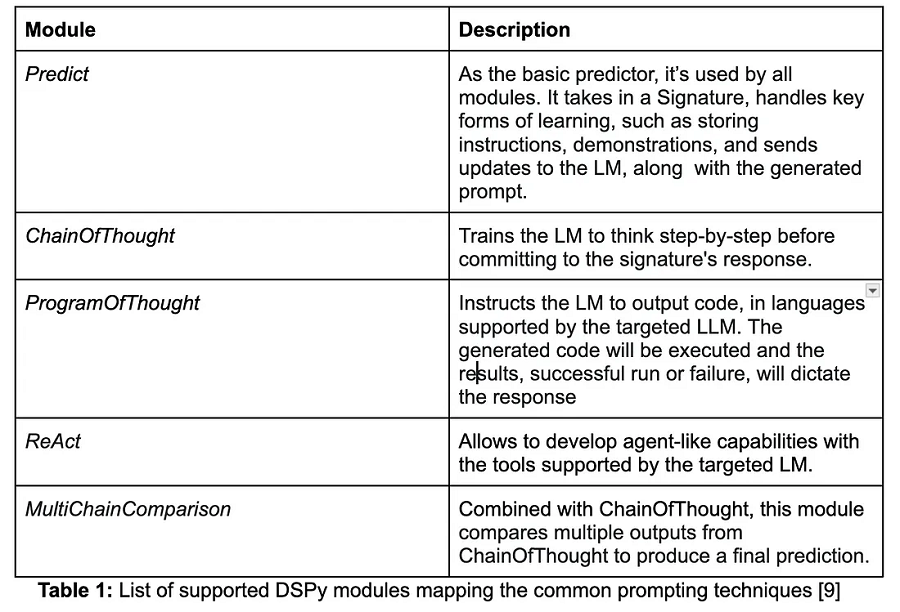
更好的是,与 ML 模型一样,您可以通过编译使用 DSPy 优化器优化这些模块,以实现高效的提示生成和响应评估。接下来让我们看看如何实现这一点。
4、优化和编译模块
就像 PyTorch 优化器(如 SGD)一样,为了最大限度地减少损失并最大限度地提高 ML 中的准确性,DSPy 优化器 API 允许你提供训练示例和评估指标来衡量准确性。如果你熟悉 PyTorch,这个概念会引起你的共鸣。
优化器接受一个训练集(引导一些选择性示例来学习如何生成提示)和一个指标(测量接近度或匹配正确响应);它们生成一个优化程序的实例,可用于编译 DSPy 程序模块。目前,DSPy 支持许多内置优化器,每个优化器都具有一定程度的严谨性,可以最大限度地提高你的指标。
最好用一些示例代码来说明。考虑一个小型训练集,其中包含一些示例,你想要用它来训练 DSPy 模块进行情绪分析。在提示工程中,这类似于作为更大的上下文提示的一部分的少量学习技术。
在与目标语言模型交互后,模块的响应要么是积极的,要么是消极的,要么是中性的。然后,你的指标可以检查返回的答案是否是这些类别情绪类别之一——或者是虚假的。
让我们创建一个简短的训练集、指标和模块。请注意,指标可以简单到返回数字分数(如 0 或 1)、精确匹配(EM)或 F1,以及平衡和衡量预测中多个关注点的整个 DSPy 程序。
# Evaluate a metric for the right response category
def evaluate_sentiment(example, pred, trace=None)->bool:
return pred in [“positive”, “negative”, “neutral”]
def get_examples() -> List[dspy.Example]:
trainset = [dspy.Example(sentence=”””This movie is a true cinematic gem,
blending an engaging plot with superb performances and stunning visuals. A masterpiece that leaves a lasting impression”””,
sentiment=”positive”).with_inputs(“sentence”),
dspy.Example(sentence=”””Regrettably, the film failed to live
up to expectations, with a convoluted
storyline, lackluster acting, and
uninspiring cinematography.
disappointment overall.”””
sentiment=”negative”).with_inputs(“sentence”)
dspy.Example(sentence=”””The movie had its moments, offering
a decent storyline and average
performances. While not groundbreaking,
it provided an enjoyable viewing
experience.”””,
sentiment=”neutral”).with_inputs(“sentence”)
...
]
return trainset
# define our DSPy module that you want to optimize and compile
class ClassifyEmotion(dspy.Signature):
“”” classify emotion based on the input sentence and provide the sentiment as output”""
sentence = dspy.InputField()
sentiment = dspy.OutputField(desc=”generate sentiment as
positive, negative or neutral”)from dspy.teleprompt import BootstrapFewShot
# Create an optimizer
optimizer = BootstrapFewShot(metric=evaluate_sentiment,
trainset=get_examples())
compiled_classifier = optimizer.compile(ClassifyEmotion(),
trainset=get_examples()
# Use our compiled classifier that has learned through bootstrapping
# a few examples how to generate the response
response = compiled_classifier(sentence="I can't believe how beautiful the sunset was tonight! The colors were breathtaking and it really made my day"
print(response.sentiment).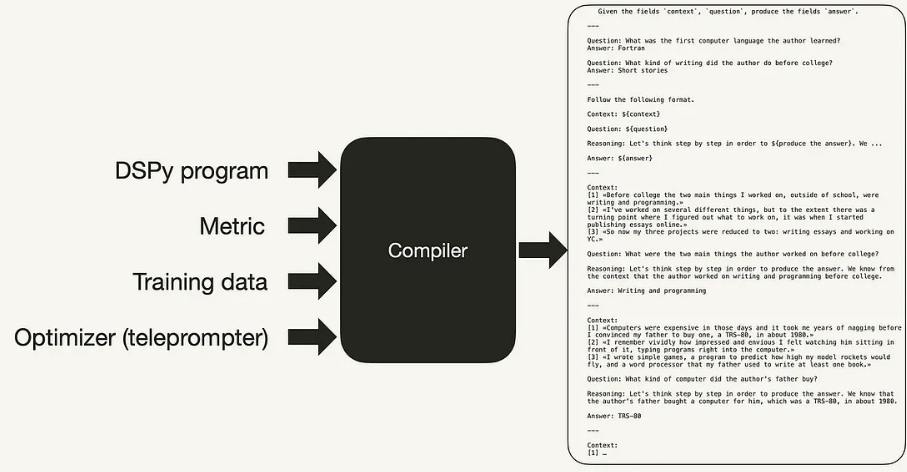
图 5:编译器生成优化提示的工件集[12]
在内部,以上所有内容都实现了以下目标:
- 使用少量上下文提示引导我们的训练集进行学习
- 使用度量来评估输出是否预测了三种情绪类别之一
- 编译 DSPy 模块
- 生成提示
- 使用编译后的分类器对我们的句子进行分类,以获得最佳提示
Omar Khattab 和 Arnav Singhvi 等人描述了上述优化和编译过程,分为三个阶段 [13]:
- 候选生成:选择候选预测器模块(如果有多个)。
- 参数优化:在提示中选择候选的说明或演示,然后使用不同的 LM 权重进行优化以获得最佳响应。
- 高阶程序优化:将其视为语言编译器代码优化,其中代码被重新排列以获得更好的执行效果。在 DSPy 中,复杂的管道被简化为集合并重新排列以改变控制流。
要查看 DSPy 框架如何优化和调整您的提示,只需使用此命令打印所有生成的提示的历史记录,其中 n > 0。
your_model.inpspect_history(n=3)这将打印出为 LLM 生成的三个不同的优化提示。要查看带有优化器和编译的少样本示例的完整示例,请仔细阅读图 1(a) 和 1(b) 中 ReAct 任务的笔记本或 Python 应用程序。
Frederick Ros 的另一场讨论探讨了 DSPy 模块的调整和优化 [14]。最后,Omar Khattab 等人提供了几个带有经验数据的案例研究,表明优化和编译的模块在复杂推理任务的可量化测量方面比未优化的模块提供了切实的效率、性能和准确性 [15]。
👎👎:DSPy 框架中的优化器和编译器的概念可能难以理解,看起来不直观,像黑匣子一样神秘。虽然它们实现了目标,但它们的清晰度和简单性不足:为什么不将优化和编译合并为单个 API 调用,而不是两个独立的阶段。此外,文档很少,没有明确的例子或插图来照亮黑暗并使其更加清晰。
到目前为止,我检查过的所有资产——文档和已发布的博客——都不足以清晰地解释这个强大的概念。因为这个概念是框架自我改进和优化方面的核心。由于缺乏明确的例子和实际用例,这个概念让我无法引起惊叹🤯。
5、DSPy 端到端示例程序
Omar Khattab 和 Arnav Singhvi 等人写道,编程框架可以从多个维度进行评估,包括计算效率、开发人员效率、代码和概念的直观性等。作者根据三个假设评估了 DSPy 编程框架 [15]:
- H1:使用 DSPy,我们可以用简洁且定义明确的模块替换手工制作的提示字符串,而不会降低质量或表达能力。
- H2:参数化模块并将提示视为优化问题使 DSPy 能够更好地适应不同的 LM,并且可能胜过专家编写的提示。
- H3:由此产生的模块化使得更彻底地探索具有有用性能特征或符合细微指标的复杂管道成为可能。
我使用 DSPy 框架将我之前发布的 Prompt Engineering 博客中的所有示例转换为明确而详尽的提示技术。使用本地 OLama 语言模型和 DSPy 的内置工具(如 Retrievers),我能够模块化和构建复杂管道以完成复杂的推理任务。
5.1 NLP 任务
我使用 DSPy 声明式签名来表达通用 LLM 的常见自然语言理解功能的操作方法代码示例,例如 ChatGPT、OLlama、Mistral 和 Llama 3 系列:
- 文本生成或完成
- 文本摘要
- 文本提取
- 文本分类或情感分析
- 文本分类
- 文本转换和翻译
- 简单和复杂推理
为此,DSPy 模块可以胜任这项任务。代码是模块化的、声明性的,没有带提示的故事叙述;不需要 CO-STAR 提示框架来手工制作复杂的提示。请参阅 GenAI Cookbook GitHub 存储库中图 1(a) 和 1(b) 中的笔记本和 Python 应用程序。
5.2 思维程序任务
LLM 的思维程序提示,如思维链,涉及在提示中提供一系列推理步骤来引导模型找到解决方案。这种技术有助于模型通过将复杂问题分解为中间步骤来处理它们,就像人类一样。通过模仿类似人类的推理,思维链提示提高了模型处理需要逻辑、推理和编程的任务的能力。
使用 DSPy 思维程序 (PoT) 模块 dspy.ProgramOfThought,大多数这些示例都会生成 Python 代码来解决问题。几乎不需要指定详细的提示,只需简洁的任务描述即可。
请参阅 GenAI Cookbook GitHub 存储库中图 1(a) 和 1(b) 中的笔记本和 Python 应用程序。
5.3 朴素 RAG
DSPy 模块非常简单且模块化,可以链接或堆叠以创建管道。在我们的案例中,构建朴素 RAG 包括使用 dspy.Signature 和 dspy.ChainOfThought 以及模块类 RAG(参见 dspy_utils 中的实现)。
开箱即用,DSPy 支持一组 Retrievers 客户端。对于此示例,我使用了受支持的 dspy.ColBERTv2 工具。
参见 GenAI Cookbook GitHub 存储库中图 1(a) 和 1(b) 中的笔记本和 Python 应用程序。
5.4 ReAct 任务
ReAct 最早在 Yao 等人于 2022 年发表的一篇论文中提出,是一种推理和行动范式,可指导 LLM 以结构化的方式响应复杂查询。推理和行动以思路链的方式交错和渐进,因此 LLM 使用前一个答案从一个结果进展到另一个结果。
结果表明,ReAct 在语言和决策任务中的表现优于其他领先方法,增强了人类对大型语言模型 (LLM) 的理解和信任。最好将其与思路链 (CoT) 步骤结合作为单独的任务,并将结果用于下一步,在推理过程中同时利用内部知识和外部信息。
此任务是 LLM ReAct 提示笔记本的 DSPy 转换。
请参阅 GenAI Cookbook GitHub 存储库中图 1(a) 和 1(b) 中的笔记本和 Python 应用程序。
👍👍👍:在上述所有提示工程任务中,DSPy 创建者的假设 H1 和 H3 似乎都得到了很好的支持并满足了我的期望。然而,H2 有点不清楚和不直观,我无法理解它,正如我在上文优化和编译部分所哀叹的那样。在某种程度上,将 DSPy 模块映射到常见的提示任务是有效的,为 H1 和 H2 提供了支持。
6、结束语
在本文中,我们介绍了 DSPy 框架和编程模型,这是一种创新、声明性、系统性和模块化的编程和与语言模型交互的方式,而不是使用显式和复杂的提示。通过我在之前的博客中探讨的提示工程技术的详细示例,我将提示技术转换为其等效的 DSPy 程序。
在此过程中,我赞扬了 DSPy 的许多方面,这些方面吸引了我,也可能吸引习惯于声明式编程方法的 Python 开发人员。我指出了它在概念、记录示例和缺乏用例方面的一些缺点。原始论文中探讨的三个假设中有两个似乎在我的编程努力中得到了很好的支持:转换复杂和显式的提示工程技术并构建模块化和声明性的 DSPy 程序。
斯坦福 NLP 的新框架对于编程语言模型来说不是一个理想的创新吗?它会逐渐变得无关紧要吗?
我不这么认为。虽然它没有像 LangChain 和 LLamaIndex 等其他 LLM 框架那样迅速流行起来,但它拥有一个不断扩大的社区,在 GitHub 上的影响力日益增强(拥有 924 个 fork、150 个贡献者和超过 12K 个星星),并在 Reddit 和 discord 论坛上引起了热烈的讨论,因此也不太可能变得无关紧要。
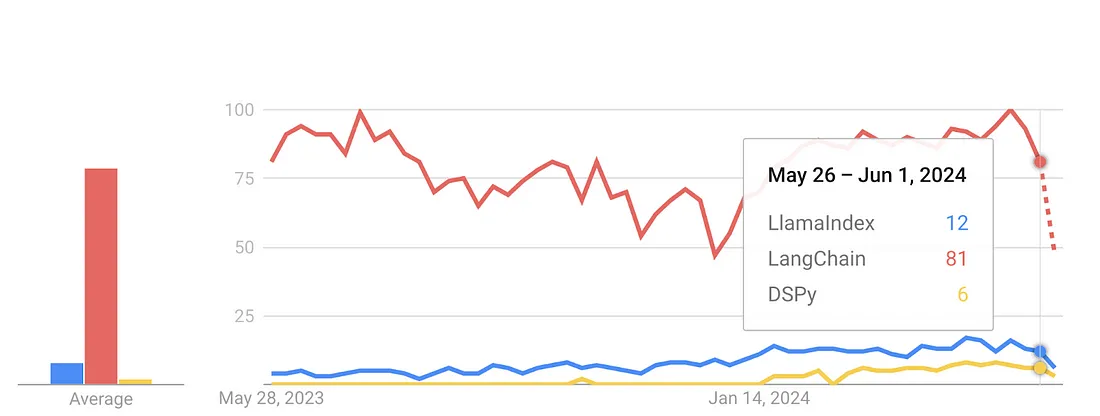
图6 DSPy与LlamaIndex、LangChain的搜索对比
正如一些支持者所言,它是否是提示工程技术的替代品?如果适用,它可能是一种可选的偏好,有实际的用例可以证明其有效性和用途。如果更多的 GenAI、Data、AI 先驱公司(如 Databricks)在其生态系统中展示其用途,或者出现资金雄厚的 DSPy 背后初创公司,我们很可能会看到更广泛的使用。
完全取代任何技术创新都是夸张的说法;完全取代只能随着时间的推移才能实现,而不是一夜之间。DSPy 不太可能立即取代或取代熟练和手工制作的提示和提示模板工程。















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









