









简介
在人工智能领域,大模型的竞赛从未停歇,而Meta公司于2025年4月6日发布的Llama 4模型系列无疑为这场竞赛注入了新的活力。
作为Meta首个基于混合专家(MoE)架构的模型系列,Llama 4以其卓越的性能、创新的设计和极高的性价比,迅速在开源模型领域崭露头角,甚至在某些方面超越了当前行业内的顶尖模型。这一系列的发布不仅标志着Llama生态系统进入了一个新的时代,也引发了整个AI行业对多模态模型和高效计算架构的广泛关注。
Llama 4系列共有三个版本,分别是Llama 4 Scout(中杯)、Llama 4 Maverick(大杯)和尚未推出的Llama 4 Behemoth(超大杯)。
- Llama 4 Scout是一款拥有16位专家和170亿激活参数的多模态模型,能够在单个H100 GPU上运行,达到了同类模型的最佳水平(SOTA),并且具备1000万的上下文窗口。
- Llama 4 Maverick则更为强大,它拥有128位专家和170亿激活参数,不仅在性能上超越了GPT-4o和Gemini 2.0 Flash,还以一半的参数量实现了与DeepSeek-V3相当的代码能力,主打高性价比,同样可以在单个H100主机上运行。
- Llama 4 Behemoth是一个正在训练中的2万亿参数的超大超强模型,前两者均由此模型蒸馏而来,它在多个基准测试中已经超过了GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro。
Llama 4模型的特点
-
基于MoE架构:这是Llama系列首次使用混合专家模型(MoE)架构,提高了计算效率。
-
长上下文窗口:Llama 4 Scout拥有100万的上下文窗口,经过预训练和后训练,长度为256K,具备高级长度泛化能力。
-
原生多模态设计:Llama 4系列支持多模态输入,用户可以上传图片并提问,模型能够直接在对话框中回答相关问题。
-
多语言支持:Llama 4掌握全球12种语言,方便全球开发者部署。
-
性价比高:与DeepSeek-V3相比,Llama 4 Maverick在同等代码能力下,参数减少一半,且单个H100 GPU即可运行。

官方博客:https://ai.meta.com/blog/llama-4-multimodal-intelligence/
模型权重:https://huggingface.co/meta-llama
-
-
表现
首先来看和Llama系列前作、Gemma 3、Mistral 3.1、Gemini 2.0 Flash-Lite的对比结果
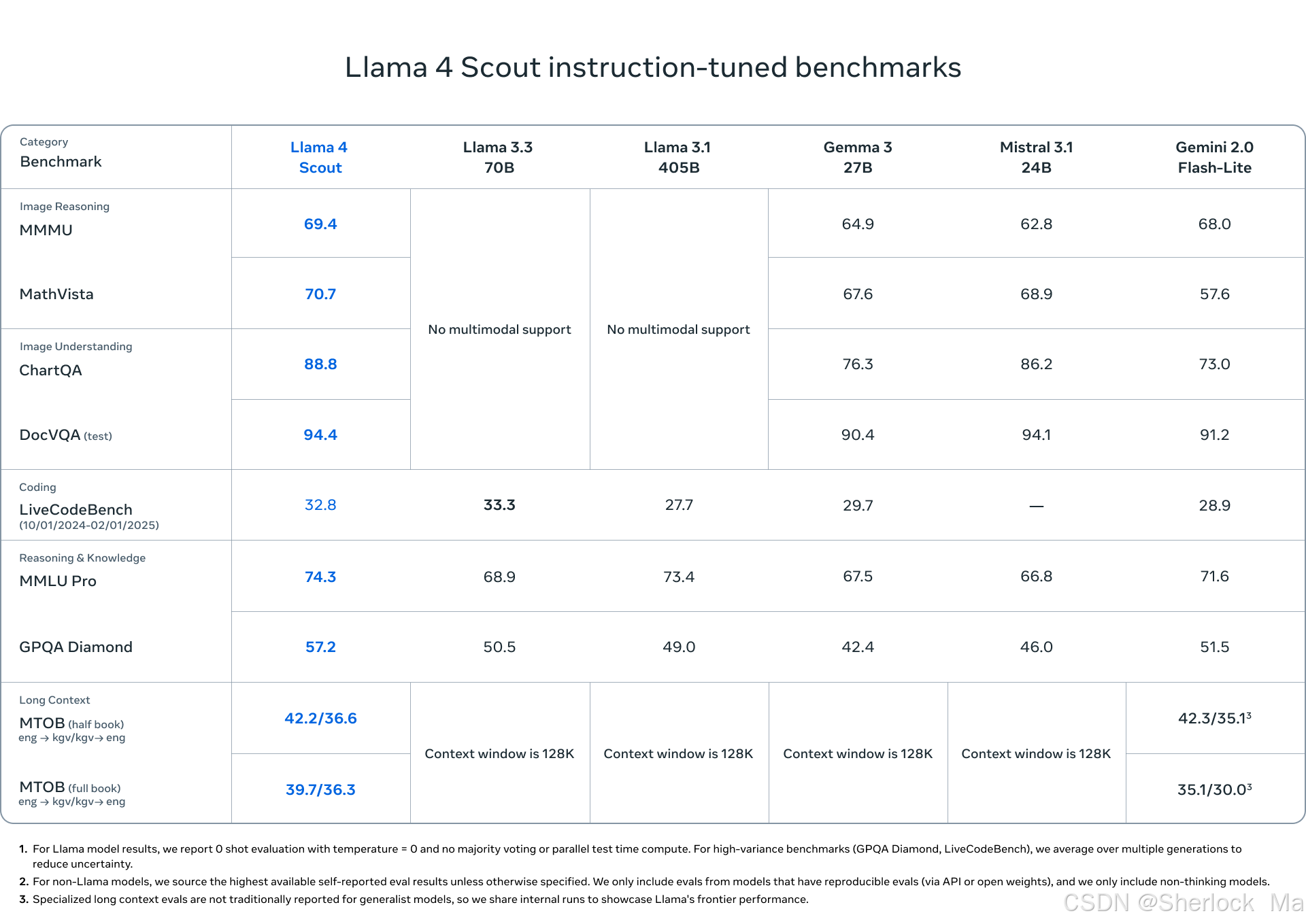
Llama 4 Maverick在推理成本、图像理解、数学能力、图像推理和多模态支持等方面表现出色,尤其是在推理成本上,其每百万输入和输出标记的成本在$0.19到$0.49之间,低于其他模型。在图像理解方面,Llama 4 Maverick在MMOR和ChartQA测试中分别取得了73.4和90.0的高分。在数学能力测试MathVista中,它也以73.7的分数领先。在多模态支持方面,Llama 4 Maverick在DocVQA测试中得分94.4,而在LiveCodeBench编码测试中得分43.4。在推理和知识测试MMLU Pro中,它以80.5的分数领先,而在GPQA Diamond多语言测试中得分69.8。在长上下文测试MTOB中,Llama 4 Maverick的得分为50.8/46.7,显示了其在长上下文理解方面的能力。整体来看,Llama 4 Maverick在多个测试中都展现出了强大的性能和竞争力。
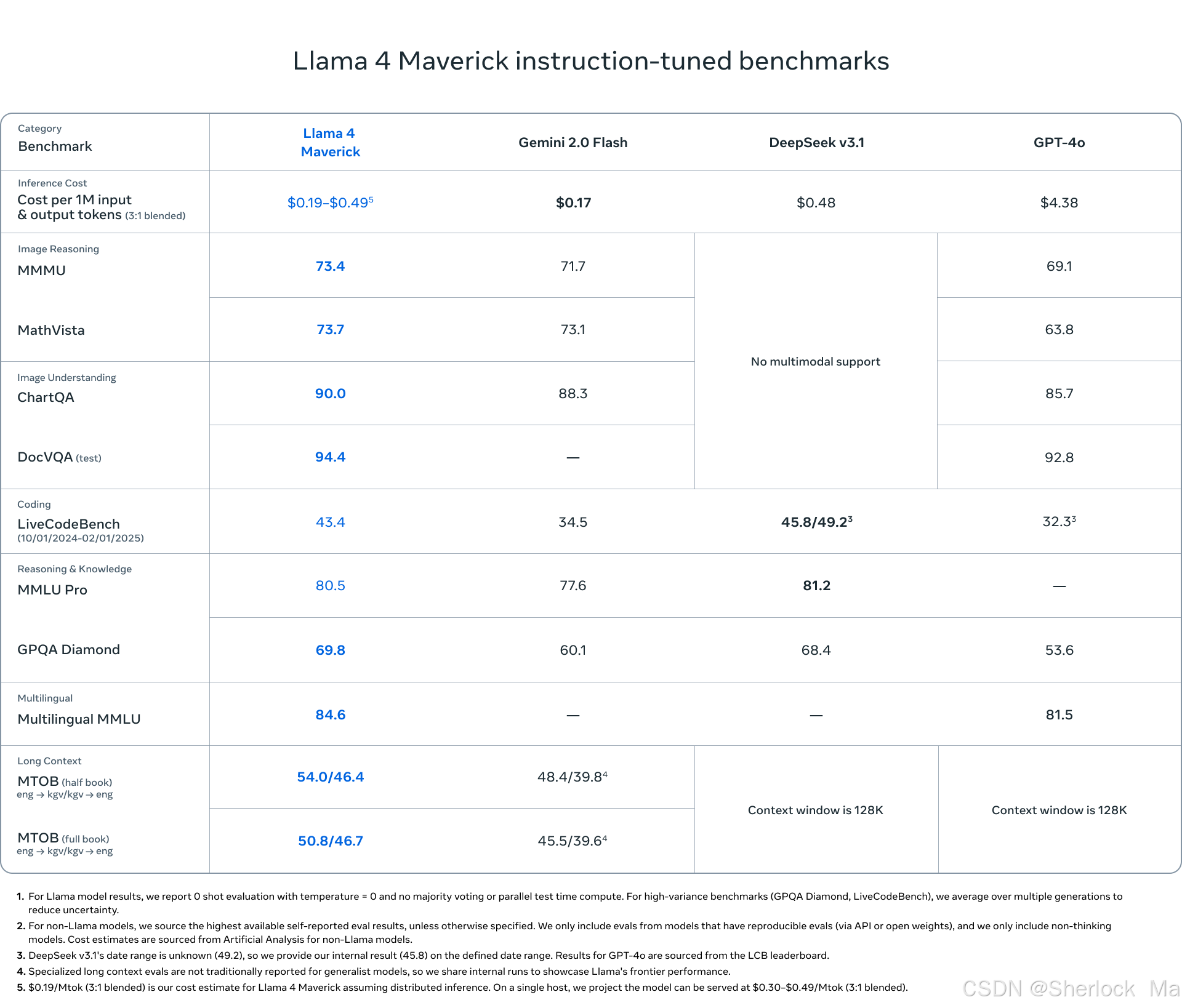
Llama 4 Scout在多个测试中表现出色,尤其是在图像推理和数学能力方面,其在MMOR测试中得分69.4,MathVista测试中得分70.7,ChartQA图像理解测试中得分88.8,显示出其在这些领域的强劲能力。在DocVQA测试中,Llama 4 Scout得分94.4,领先于其他模型。在编码能力方面,尽管其LiveCodeBench得分32.8不是最高,但仍然表现良好。在推理和知识测试MMLU Pro中,Llama 4 Scout得分74.3,略低于Llama 3.3的68.9。在多语言测试GPQA Diamond中,Llama 4 Scout得分57.2,显示出其在多语言处理上的能力。在长上下文测试MTOB中,Llama 4 Scout得分42.2/36.6,表现中等。整体来看,Llama 4 Scout在多个测试中都展现出了竞争力,特别是在图像理解和数学能力方面。
这张图展示了不同AI模型在LMArena ELO评分与成本之间的关系。图中,Llama 4 Maverick 03-26 Experimental模型在ELO评分上表现突出,同时其成本相对较低,显示出高性价比。相比之下,GPT-4o和GPT-4.5 Preview的ELO评分也很高,但成本明显更高。其他模型如DeepSeek V3.1、Gemini 2.0 Flash和Qwen 2.5 Max等则在ELO评分和成本上各有不同表现。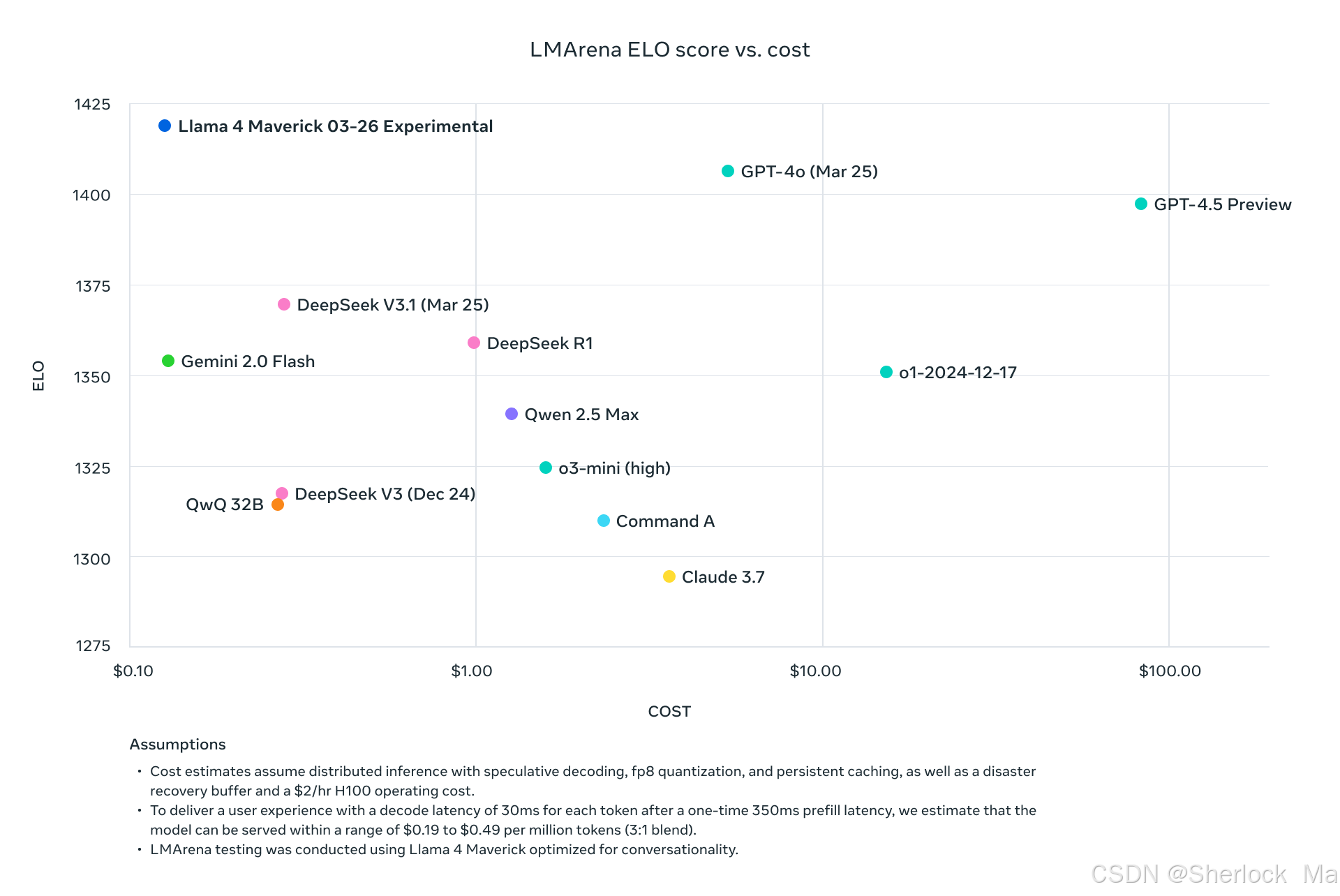
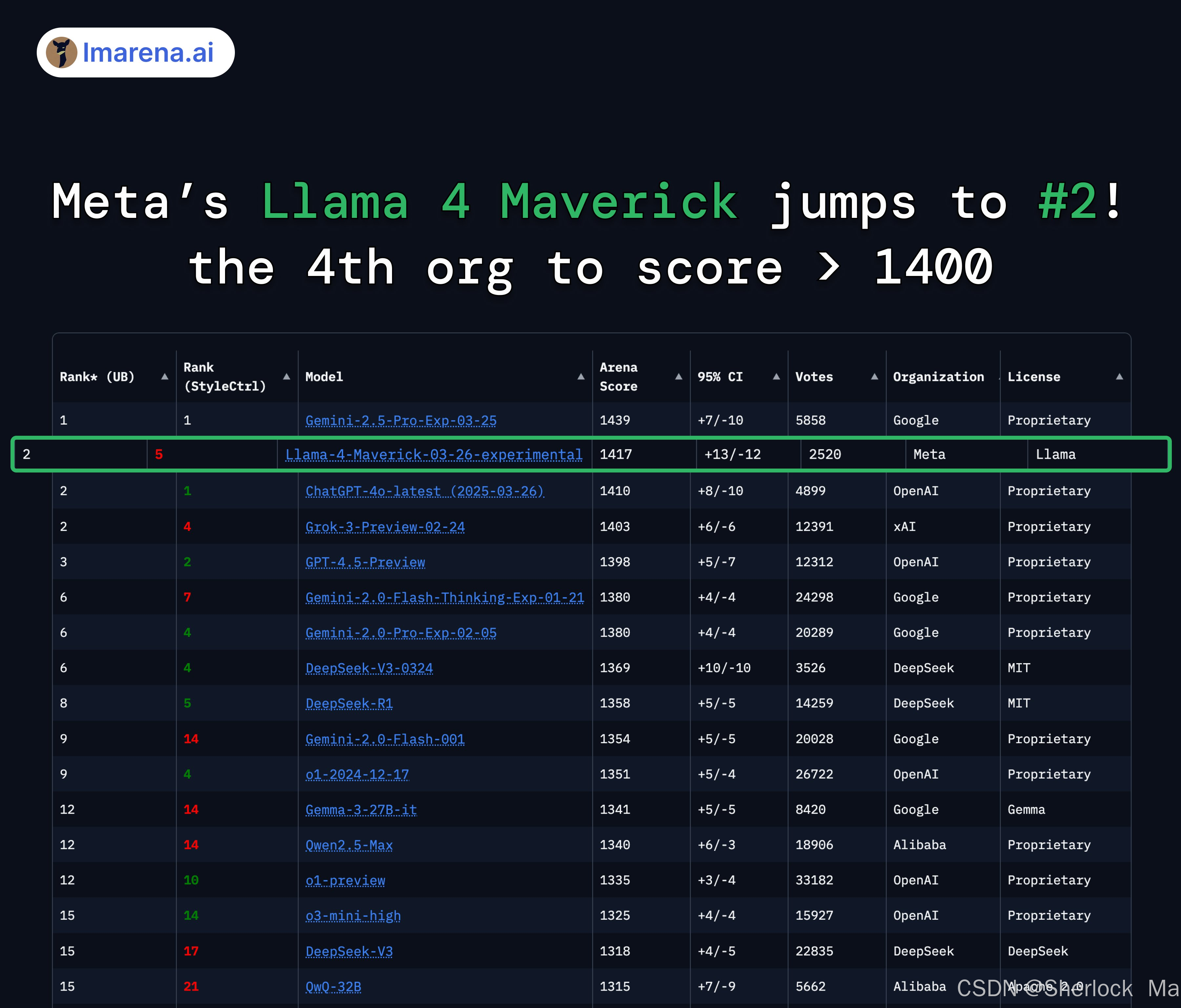
同时,Meta公司的Llama 4 Maverick模型在Arena取得了显著的成绩,排名第二,成为第四个得分超过1400分的组织,也是目前排名第一的开放模型,超越 DeepSeek。Llama 4 Maverick的Arena得分为1417分,比前一个版本提高了13分,显示出其在性能上的显著提升。该模型在多个基准测试中表现出色,包括困难提示、编码、数学和创意写作等方面,均取得了优异的成绩。
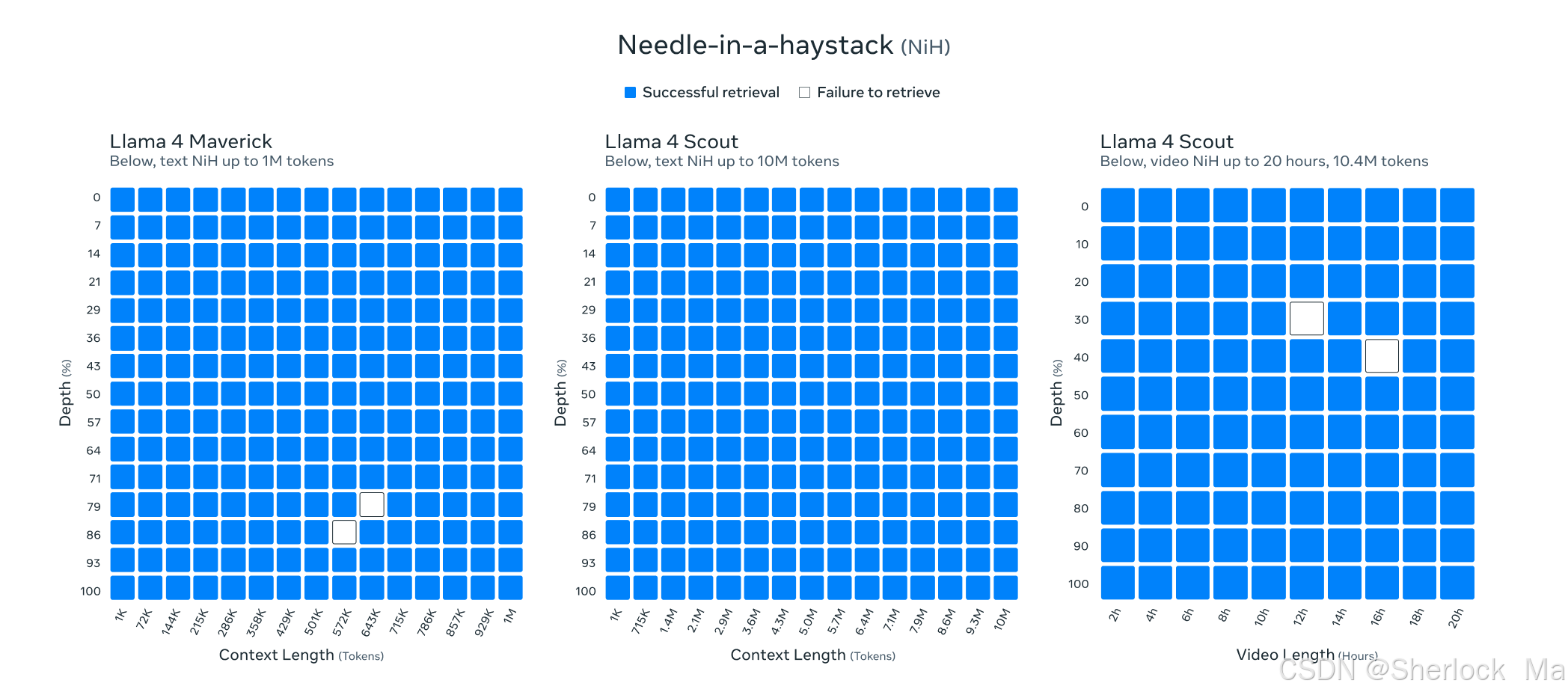
这张图展示了Llama 4 Maverick、Llama 4 Scout和Llama 4 Scout在处理不同长度的文本和视频内容时的“Needle-in-a-haystack”检索成功率。图中蓝色方块代表成功检索,白色方块代表检索失败。对于Llama 4 Maverick,其在处理长达1M tokens的文本内容时表现出极高的检索成功率,几乎在所有深度和上下文长度上都能成功检索。Llama 4 Scout在处理长达10M tokens的文本内容时也显示出很高的成功率,尽管在某些较长的上下文长度和较大深度时成功率有所下降。而对于处理视频内容的Llama 4 Scout,其在视频长度达到20小时,约10.4M tokens时,检索成功率仍然很高,但在某些特定的深度和视频长度组合下出现了检索失败的情况。整体来看,这些模型在大多数情况下都能有效地进行NiH检索,尤其是在处理文本内容时表现更为出色。
Needle-in-a-haystack(NiH)是一种评估大型语言模型(LLMs)处理长文本能力的方法。这种方法的核心思想是在一段长文本中插入一个特定的事实或陈述(即“针”),然后要求模型从这段长文本中检索出这一特定信息。这种方法模拟了现实世界中的许多应用场景,例如从长篇文档中提取关键信息、在大量背景知识中定位特定事实等。测试的具体步骤包括准备一段长文本作为背景上下文(“干草堆”),在这段文本的某个位置插入一个特定的事实或陈述(“针”),向模型提供整段文本,并要求其回答一个与插入信息相关的问题,通过改变文本长度和插入位置,系统地评估模型的表现。此外,这种方法还可能涉及在长文本中随机插入关键信息,形成大型语言模型的Prompt,旨在检测大型模型是否能从长文本中提取出这些关键信息,从而评估模型处理长文本信息提取的能力。
 -
-
-
训练过程
Pre-training
构建下一代 Llama 模型必须在预训练过程中采用多种新方法。
新的 Llama 4 模型是LLaMA系列第一个使用专家混合(MoE)架构的模型。在 MoE 模型中,单个标记只激活总参数的一小部分。MoE 架构在训练和推理方面具有更高的计算效率,在固定的训练 FLOPs 预算下,与密集模型相比,MoE 架构能提供更高的质量。
例如,Llama 4 Maverick 模型有 17B 个活动参数和 400B 个总参数。为了提高推理效率,Meta团队交替使用密集层和专家混合层(MoE)。MoE 层使用 128 个路由专家和一个共享专家。每个token都会发送给共享专家,同时也会发送给 128 个路由专家中的一个。因此,虽然所有参数都存储在内存中,但在为这些模型提供服务时,只有总参数的一个子集被激活。Llama 4 Maverick 可在单台英伟达 H100 DGX 主机上运行,便于部署,也可通过分布式推理实现最高效率。
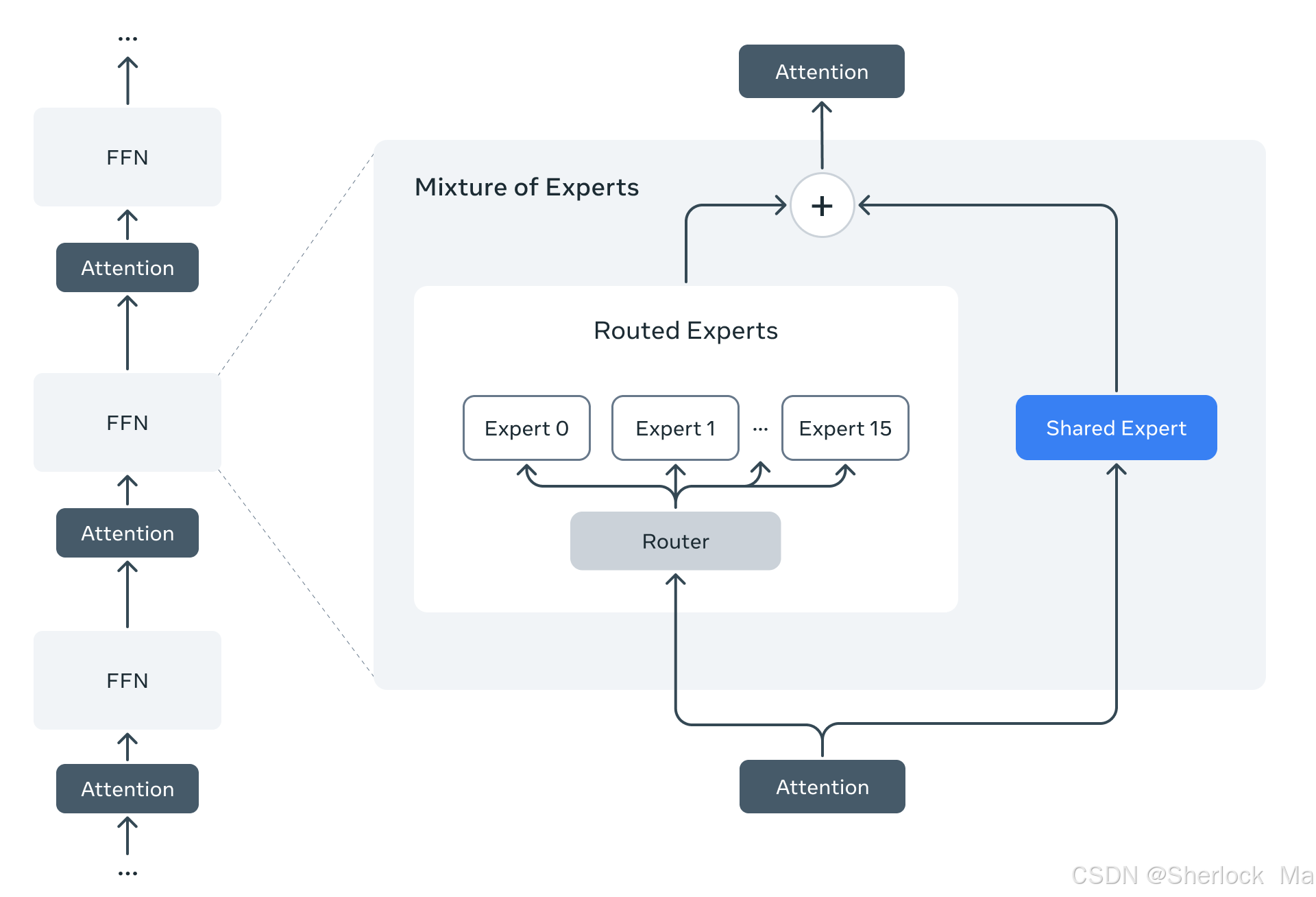
Llama 4 模型采用原生多模态设计,结合早期融合技术,将文本和视觉标记无缝整合到统一的模型骨干中。早期融合是向前迈出的重要一步,因为它能够利用大量未标记的文本、图像和视频数据对模型进行联合预训练。
Meta团队还改进了 Llama 4 中的视觉编码器。它以 MetaCLIP 为基础,但结合冻结的 Llama 模型进行了单独训练,以便使编码器更好地适应 LLM。
Meta团队还开发了一种新的训练技术,他们称之为 MetaP,它允许可靠地设置关键模型超参数,如每层学习率和初始化规模。团队发现,所选的超参数在不同的批量大小、模型宽度、深度和训练代币值之间都能很好地转移。
此外,Meta团队还注重通过使用 FP8 精度进行高效模型训练,同时不牺牲质量并确保高模型 FLOPs 利用率--在使用 FP8 和 32K GPU 预训练 Llama 4 Behemoth 模型时,Meta团队实现了 390 TFLOPs/GPU。
Llama 4 通过在 200 种语言(包括 100 多种语言,每种语言有超过 10 亿个词库)上进行预训练,实现了开源微调工作,其多语言词库总量是 Llama 3 的 10 倍。
其用于训练的整体数据混合物包括 30 多万亿个tokens,是 Llama 3 预训练混合物的两倍多,其中包括各种文本、图像和视频数据集。
接下来,Meta团队在所谓的 “中期训练 ”中继续训练模型,通过新的训练方法(包括使用专业数据集进行长语境扩展)来提高核心能力。这使能够在提高模型质量的同时,为 Llama 4 Scout 提供同类最佳的 10M 输入上下文长度。
-
Post-training
LLaMA的最新型号包括更小和更大的选择,以满足各种使用案例和开发人员的需求。Llama 4 Maverick 在图像和文本理解方面具有无与伦比、行业领先的性能,能够创建复杂的人工智能应用,消除语言障碍。作为通用助理和聊天用例的主力机型,Llama 4 Maverick 非常适合精确图像理解和创意写作。
在对 Llama 4 Maverick 模型进行后训练时,最大的挑战在于如何在多种输入模式、推理和对话能力之间保持平衡。为了混合模式,Meta团队精心策划了一种课程策略,与单个模式专家模型相比,这种策略不会牺牲性能。在 Llama 4 中,团队采用了一种不同的方法来改造后训练管道:轻量级监督微调(SFT) > 在线强化学习(RL) > 轻量级直接偏好优化(DPO)。
一个关键的教训是,SFT 和 DPO 可能会过度约束模型,限制在线强化学习阶段的探索,并导致次优精度,尤其是在推理、编码和数学领域。为了解决这个问题,团队使用 Llama 模型作为评判标准,删除了 50% 以上被标记为简单的数据,并对剩余的较难数据集进行了轻量级 SFT。在随后的多模态online RL 阶段,通过仔细选择较难的提示,模型实现了性能上的飞跃。
此外,团队还实施了一种连续的online RL 策略,即交替训练模型,然后利用模型不断过滤并只保留中等难度到较高难度的提示。事实证明,这种策略在计算量和准确性的权衡方面非常有利。然后,团队采用了轻量级 DPO 来处理与模型响应质量相关的拐角情况(corner cases),从而有效地在模型的智能性和对话能力之间实现了良好的平衡。
在机器学习和软件开发中,“corner cases”指的是那些罕见的、边缘的或特殊情况,这些情况可能由输入参数的罕见组合引起,或者是由于机器学习模型的错误、故障或不正确行为导致的。这些情况在开发过程中可能已经被考虑并解决,因此在运行系统中它们不再被视为边缘情况。在机器学习模型训练和测试中,识别和处理这些“corner cases”对于提高模型的鲁棒性和性能至关重要。
流水线架构和带有自适应数据过滤功能的连续在线 RL 策略最终造就了业界领先的通用聊天模型,该模型具有最先进的智能和图像理解能力。
-
-
代码
首先确保transformers版本为4.51.0,否则请更新最新版本
pip install -U transformers然后下载权重,接着运行下面的代码
单模态
from transformers import AutoTokenizer, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8"
tokenizer = AutoTokenizer.from_pretrained(model_id) # 加载与模型ID对应的分词器。
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True) # 将用户的消息转换为模型可以理解的格式。这个方法将文本转换为模型的输入格式,并添加了生成提示。设置add_generation_prompt=True以添加生成提示,return_tensors="pt"以返回PyTorch张量,return_dict=True以获得一个包含所有输入信息的字典。
model = Llama4ForConditionalGeneration.from_pretrained( # 加载Llama 4 Maverick模型,并设置一些特定的参数,如自动选择张量计划和数据类型。
model_id,
tp_plan="auto",
torch_dtype="auto",
)
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100) # 生成响应。这个方法使用模型的输入张量来生成文本,max_new_tokens=100限制了生成文本的最大长度。
outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:]) # 将生成的张量解码为人类可读的文本。
print(outputs[0])
多模态
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id) # 加载与模型ID对应的分词器。
model = Llama4ForConditionalGeneration.from_pretrained( # 加载Llama 4 Maverick模型,并设置一些特定的参数,如注意力实现、设备映射和数据类型。
model_id,
attn_implementation="flex_attention",
device_map="auto",
torch_dtype=torch.bfloat16,
)
url1 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
url2 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/cat_style_layout.png"
messages = [
{
"role": "user",
"content": [ # 创建一个包含用户消息的列表,其中包含两个图像和一个文本问题,询问这两个图像的相似之处和不同之处。
{"type": "image", "url": url1},
{"type": "image", "url": url2},
{"type": "text", "text": "Can you describe how these two images are similar, and how they differ?"},
]
},
]
inputs = processor.apply_chat_template( # 将用户的消息转换为模型可以理解的格式。这个方法将文本和图像转换为模型的输入格式,并添加了生成提示。
messages,
add_generation_prompt=True,
tokenize=True, # 确保输入被分词
return_dict=True, # 获得一个包含所有输入信息的字典
return_tensors="pt", # 返回PyTorch张量
).to(model.device)
outputs = model.generate( # 生成响应。这个方法使用模型的输入张量来生成文本。
**inputs,
max_new_tokens=256, # max_new_tokens=256限制了生成文本的最大长度
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0] # 将生成的张量解码为人类可读的文本。
print(response)
print(outputs[0])
pipeline
也可以以pipeline的方式运行
from transformers import pipeline
import torch
model_id = "meta-llama/Llama-4-Maverick-17B-16E"
pipe = pipeline( # 创建一个文本生成的管道。这个管道封装了模型的加载和文本生成的整个过程。
"text-generation", # 指定管道的任务类型,这里是文本生成。
model=model_id,
device_map="auto", # 让管道自动决定如何将模型分配到可用的设备(如CPU或GPU)上。
torch_dtype=torch.bfloat16, # 设置模型使用的PyTorch数据类型为bfloat16,这是一种半精度浮点数格式,可以在保持合理精度的同时减少内存使用和加速计算。
)
output = pipe("Roses are red,", max_new_tokens=200) # 用管道生成文本。这里给定了一个初始的文本提示"Roses are red,",并指定max_new_tokens=200,意味着模型将尝试生成最多200个新令牌(tokens)的文本。
-
-
🌟 亲爱的读者们,如果您喜欢我们的内容,我们真诚地希望得到您的支持和鼓励!👏
👍 点赞:您的每一个点赞都是对我们工作的认可,也是激励我们继续创作优质内容的动力源泉。
🔔 关注:点击关注,您将不会错过我们未来的任何精彩更新。让我们一起在知识的海洋中航行,探索更多的可能。
💼 收藏:将这篇文章收藏起来,无论是为了日后回顾,还是与朋友分享,都是对我们最大的支持。
我们致力于提供有价值、有深度的内容,您的每一次互动都是我们前进路上的宝贵财富。感谢您的陪伴,让我们携手共创更加美好的未来!

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









