







 本文详细阐述了Transformer模型中注意力机制的关键组成部分,如编码器自注意力、解码器自注意力和编码器-解码器注意力,以及多头注意力如何增强模型处理序列间复杂关系的能力。通过实例和参数解析,深入解析了Transformer在翻译任务中的工作原理。
本文详细阐述了Transformer模型中注意力机制的关键组成部分,如编码器自注意力、解码器自注意力和编码器-解码器注意力,以及多头注意力如何增强模型处理序列间复杂关系的能力。通过实例和参数解析,深入解析了Transformer在翻译任务中的工作原理。
Transformer的大脑
多头注意力是Transformer的大脑,请先记住这句话并耐心看完本篇文章,希望看完后你会理解这句话。
Transformer 中如何使用 Attention
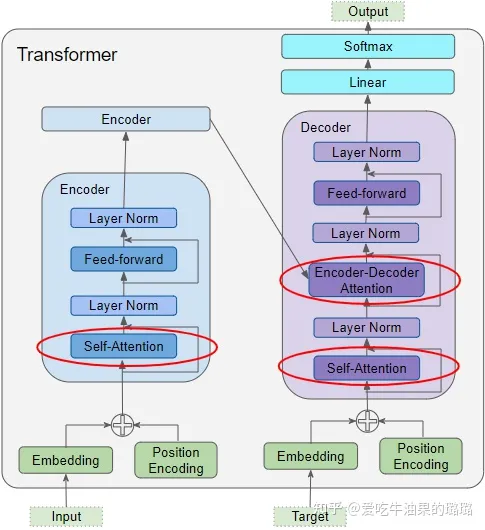
注意力机制在 Transformer 中的三个地方发挥作用:
- 编码器中的自注意力——输入序列关注自身
- 解码器中的自注意力——目标序列关注自身
- Decoder中的Encoder-Decoder-attention——目标序列关注输入序列
注意力输入参数
查询、键和值
注意力层以三个参数的形式获取输入,即查询、键和值。三个参数在结构上都很相似,序列中的每个单词都由一个固定维度的向量表示。
编码器自注意力
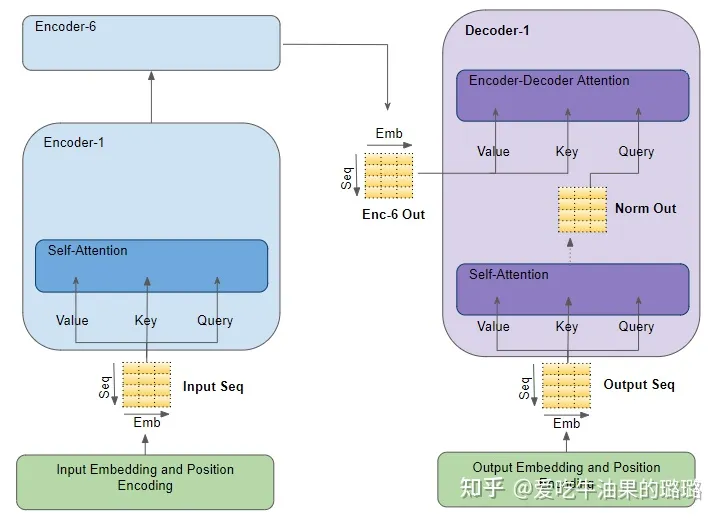
输入序列先经过输入嵌入和位置编码,它为输入序列中的每个单词生成编码表示(第一次被编码),捕获每个单词的含义和位置。然后经过第一个编码器中的自注意力中的所有参数:查询、键和值,编码器为输入序列中的每个单词生成编码表示(第二次被编码),现在已经包含每个单词的注意力分数。当它通过堆栈中的所有编码器时,每个自注意力模块也会将自己的注意力分数添加到每个单词的表示中。
解码器自注意力
到达解码器堆栈时,目标序列先经过输出嵌入和位置编码,为目标序列中的每个单词生成编码表示(第一次被编码),以捕获每个单词的含义和位置。然后经过第一个解码器中的自注意力中的所有参数:查询、键和值,然后解码器为目标序列中的每个单词生成编码表示(第二次被编码),现在已经包含输出序列中每个单词的注意力分数。
通过 Layer Norm 后,将经过第一个 Decoder 中 Encoder-Decoder Attention 中的 Query 参数矩阵。
编码器-解码器注意力
堆栈中最终编码器的输出被传递给编码器-解码器注意力中的值和键参数。
编码器-解码器注意力同时获得目标序列的表示(来自解码器自注意力)和输入序列的表示(来自编码器堆栈)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4657
4657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









