







说起语音识别,大家的第一反应就是那些看起来眼熟却总也搞不清楚的概念和公式,比如MFCC、HMM、GMM、Viterbi图、解码对齐等等,再往下深入,哪个是哪个,具体用途是什么,就都说不清楚了,总觉得那得是业内大牛才能搞懂的。去网上搜索,各种说法又五花八门,看到最后越来越乱。那么,语音识别到底是怎么一回事?学习门槛真的那么高么?让我们暂时把公式抛开,先来理解一下这些概念,没基础别怕,你一定能看懂。
语音识别的基本流程
语音的识别对于人类来说是很自然的一个过程,但要让机器“听懂”却十分困难。一段音频文件,机器怎么才能知道它代表的是什么意思呢?
语音识别要做的事,就是组CP:根据音频文件来判断对应的文本。当然,要让机器真正的“听懂”和“理解”,还涉及到很多其他的知识,语音识别只是其中一个环节。

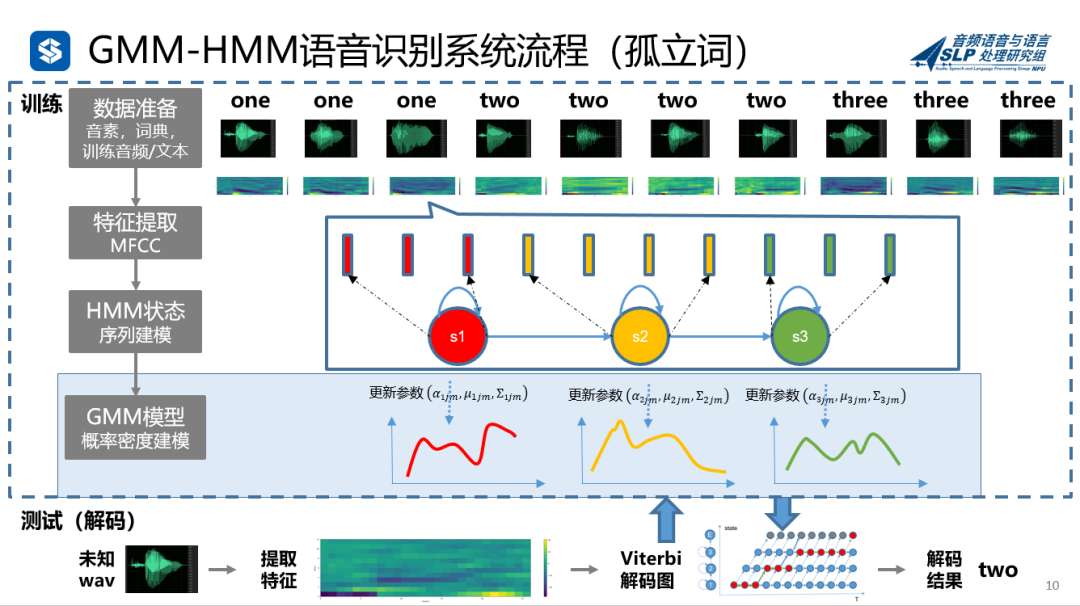
那么机器接收到左边这段语音之后,是怎么把它一口口吞下去,最后吐出来一个“two”呢?下图中,我们以最经典的基于GMM-HMM的语音识别框架为例,可以看到,经过数据准备、特征提取、训练、再到解码,就可以获取最终的结果。
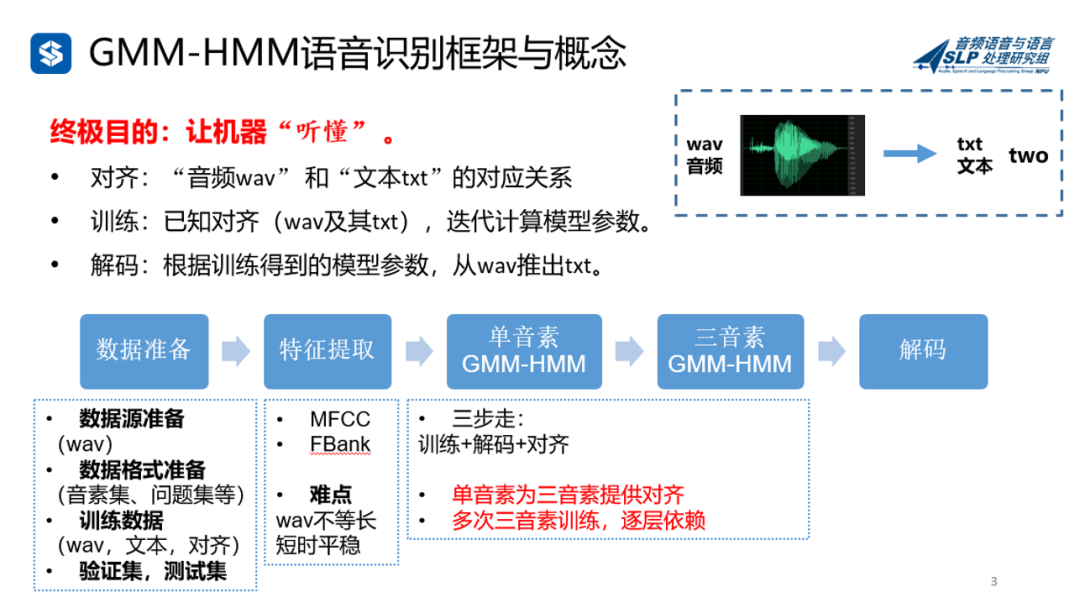
流程看完,是不是有人要问了:我知道你有道理,但是为什么有道理呢?我不想听你说理论,就想知道,你这每一个步骤用来干嘛的?
下面我们举一个例子,形象化理解GMM和HMM怎么用到语音识别里面来,这流程的每一块到底都有什么作用。
假设有如下两段音频,“我爱你”和“我恨你”,波形为:

我们首先要对音频文件进行特征提取,这里使用的特征是MFCC/Fbank。提取以后就变成下面这些类似扑克牌的方块,让我们跟着发音顺序来想象,这两段音频前面一部分的特征序列,代表的是“我”,中间是“爱/恨”,末尾是“你”。
从图中也可以看到,这两部分音频提取特征后头尾部分的相似性很强(都是“我”和“你”)。
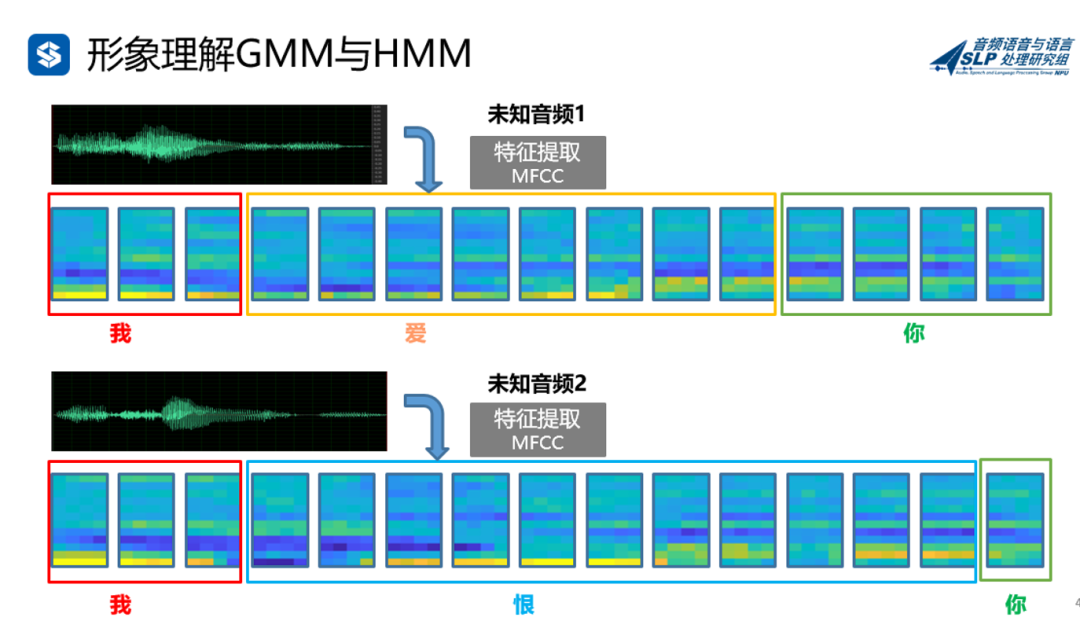
对于机器来说,开始并不知道这两句话对应的具体文本是什么,于是我们使用GMM进行聚类,分成ABCD四类(当然我们从上帝视角知道,ABCD依次对应我,爱,恨,你)。
再使用HMM对序列进行建模,得到A+B+D=“我爱你”,A+C+D=“我恨你”。二者结合,就能知道未知音频1是“我爱你”,音频2是“我恨你”。是不是看起来还没有那么难?
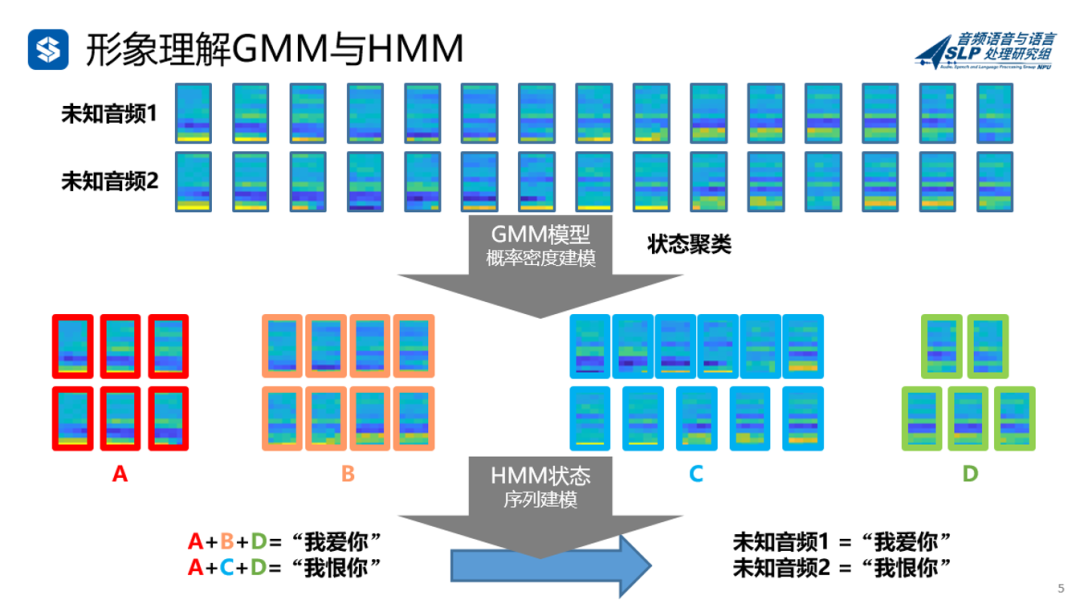
当然实际的训练和解码比这个例子要复杂,每个音频语料都需要用HCLG进行处理,每个音素也要用多个状态来代表,并且需要多次迭代更新,这里先不细说。
好了,大概了解之后,我们来稍微具体地介绍一下各部分的概念。
特征提取(MFCC/Fbank)
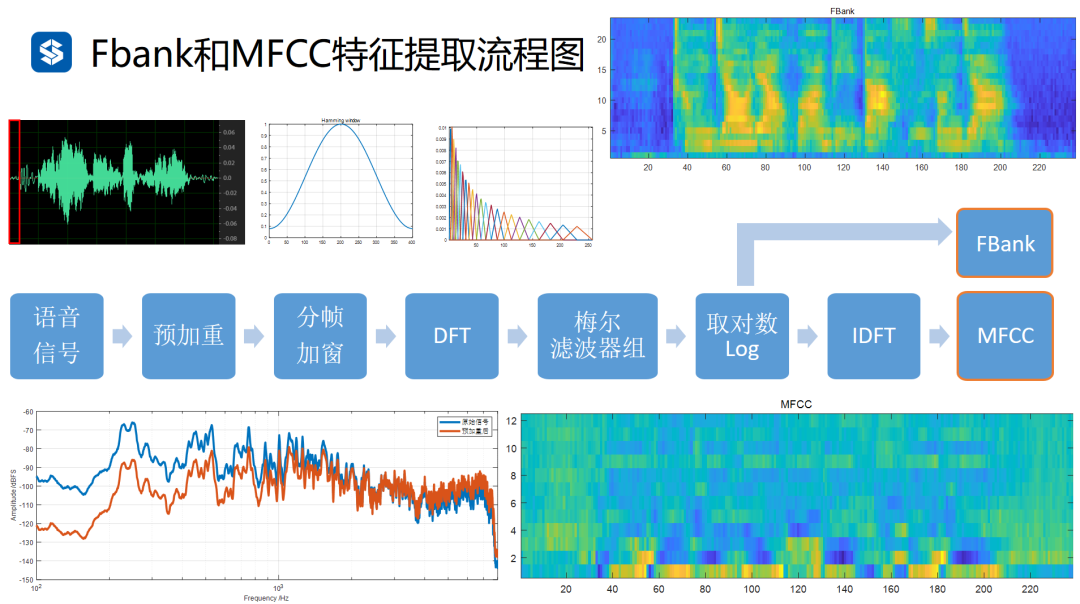
上面说到从音频文件变到“扑克牌”,这就是特征提取。我们播放音乐时一般看到的是时域的波形(横轴是时间,纵轴是幅度),就像上面绿色的那个音频文件。
但是时域波形并不能很好地表示语音的特征,例如男声低沉,女声尖锐,要怎样才能很方便地区分这些特征呢?
“横看成岭侧成峰”,有个叫傅里叶的大神上场了,他搞了一个公式,能将信号从时域变换到频域。我们常听到的MFCC和Fbank就是语音识别的经典频域特征。
GMM和HMM
虽然都是MM,但这两个MM其实没啥关系。
GMM(Gaussian Mixture Model)混合高斯模型,就是一堆不同分布的高斯模型按一定比例组合在一起,用来对特征进行分类;
HMM(Hidden Markov Model)是隐马尔可夫模型,用来对序列进行建模,从一个观测序列,推出对应的状态序列,也就是“由果找因”。这里的“因”一般是隐藏的,无法简单的看出来的(除非你有透视眼),所以叫Hidden,潜变量、隐变量也都是这个意思。
训练和解码
以孤立词为例(单独的one,two这种),不涉及上下文。训练是干嘛?建模型啊。先来一堆已经配对好的CP(训练数据),用它来建立模型(HMM-GMM模型)。
参数定下来以后,收到未知的音频,扔到刚才这个模型里面,算算算,最后就吐出来一个结果“two”,这就是解码。这就是一个迷你的语音识别的系统,简单吧?
单音素和三音素
理解了孤立词训练和解码,我们再稍微加点难度。世界上有那么多词,一个个训练,那模型该有多大啊,肯定不实用。小时候我们是怎么学语文英语的?对了,先学拼音和音标啊,学好了发音才能准啊。
这时候音素就派上用场了。比如one,分成W--AA--N,这样每个音素(Phone)再去单独建模,就更好用了。训练好了模型,丢进去解码,和上面孤立词也是类似的。
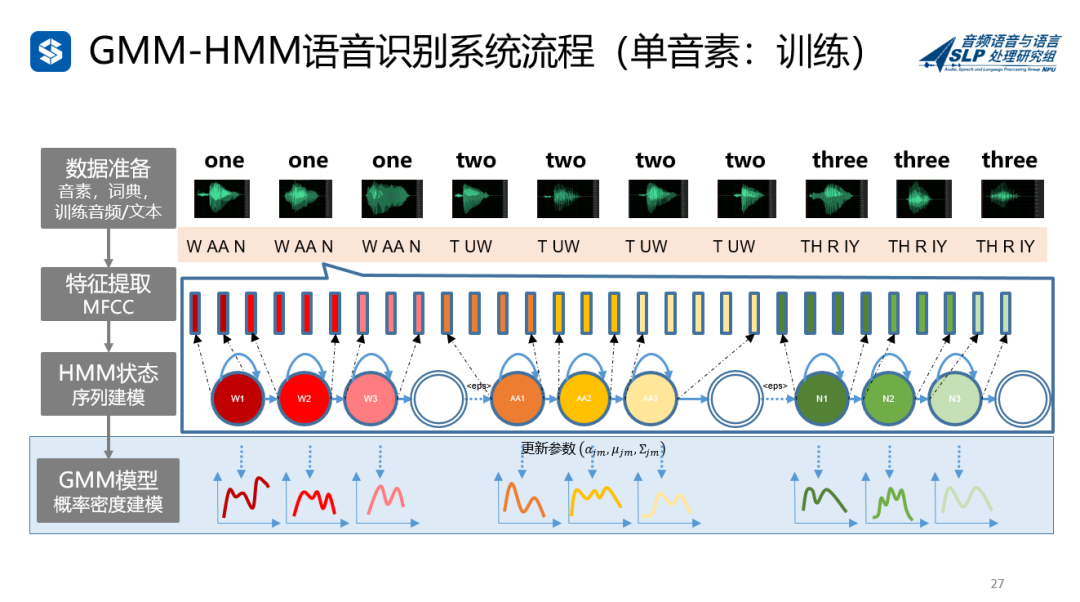
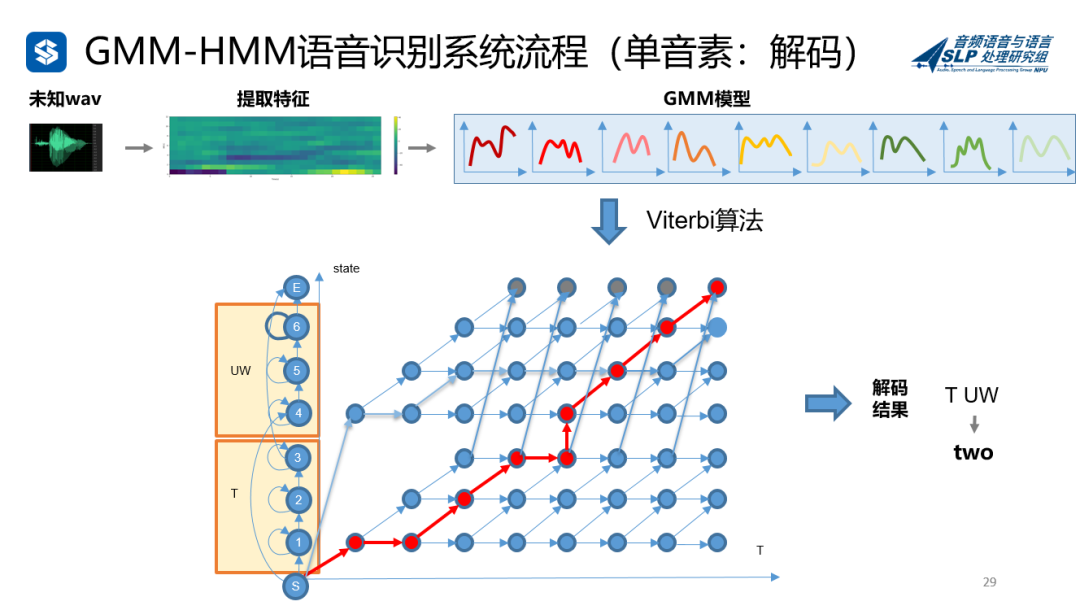
但是发音不是这么简单的一个字一个字吐的,还和上下文(Context)有关系,每个音素要考虑前一个和后一个的影响,所以就有了三音素(Triphone)。
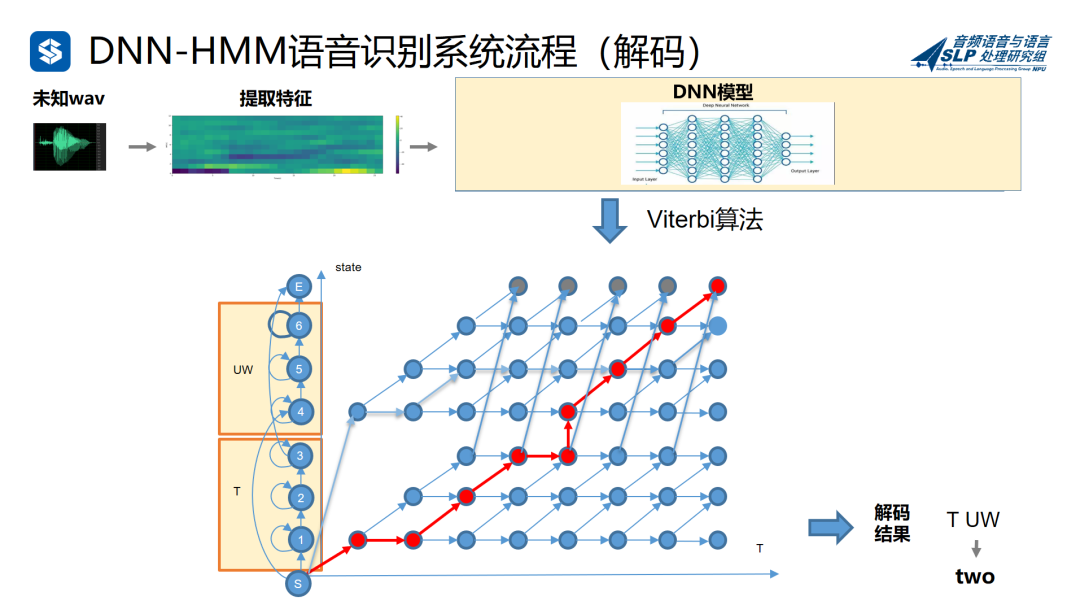
DNN-HMM
上面提到分类,那我们自然就想到DNN(Deep Neural Networks)深度神经网络。它也是一个功能十分强大的分类神器,我们完全可以用它来替换前面用来分类的GMM。于是就有了DNN-HMM。看起来也没有那么难,对吧?

整理一下
好了,感觉涉及到的术语有点多有点乱?我们来用一个简单的例子串起来,梳理一下:词、音素、三音素、词典、语言模型、HMM、GMM、DNN等。
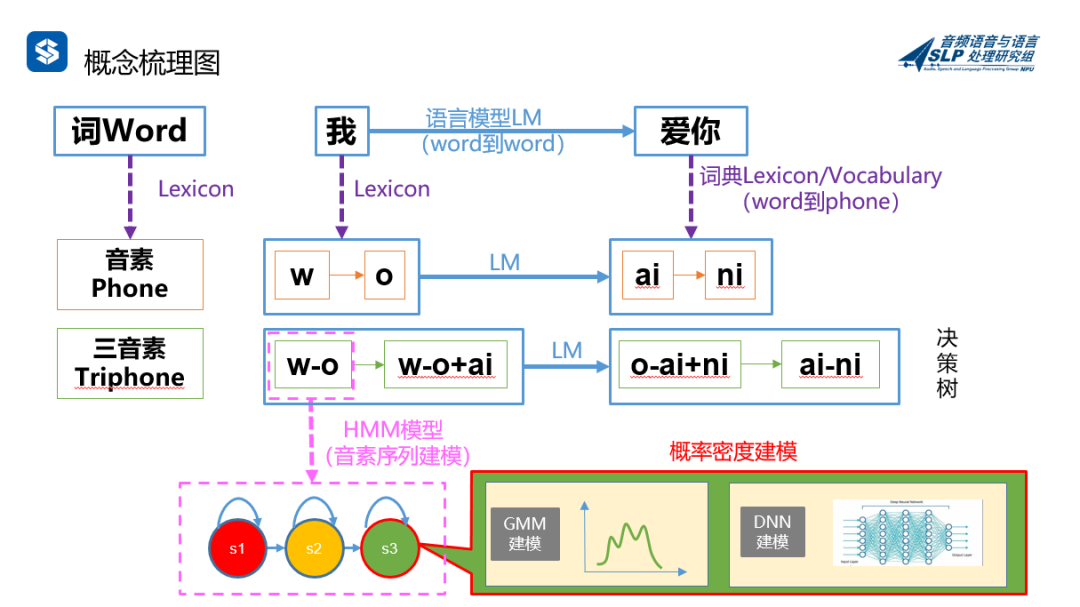
我们发现,上面图里还有一部分没见过的,那就是语言模型(Language Model,LM)。为什么要引入语言模型呢?
语言模型LM
语言模型的本质,是一种约束。前面讲的都是声学模型,对序列进行HMM建模,对每个音素用GMM或者DNN进行概率密度建模。
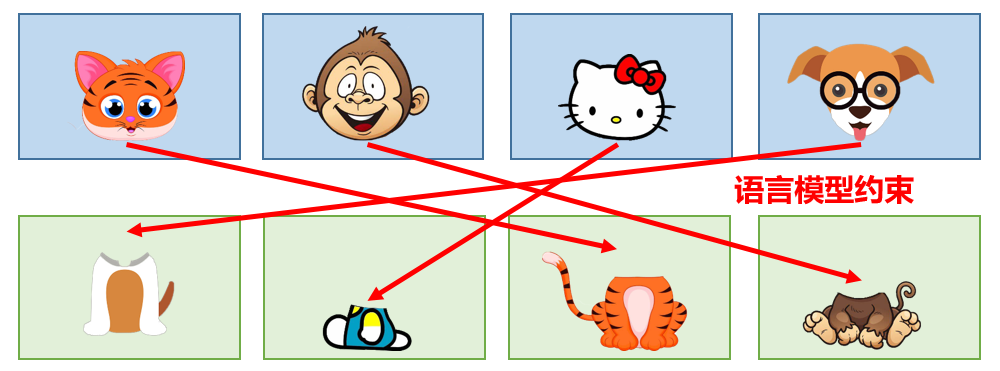
我们用下面的图来表示,可以理解成用声学模型可以对动物的“头”和“身体”进行建模,后面还需要把“头”和“身体”搭配起来才是完整的动物。

但是只使用声学模型的话,会导致什么缺陷呢?猫头配虎身,狗头配猴身,不符合实际情况(无法发音)。我们需要增加一种约束,保证“猫头”配“猫身”,“狗头”配“狗身”。这就是语言模型。

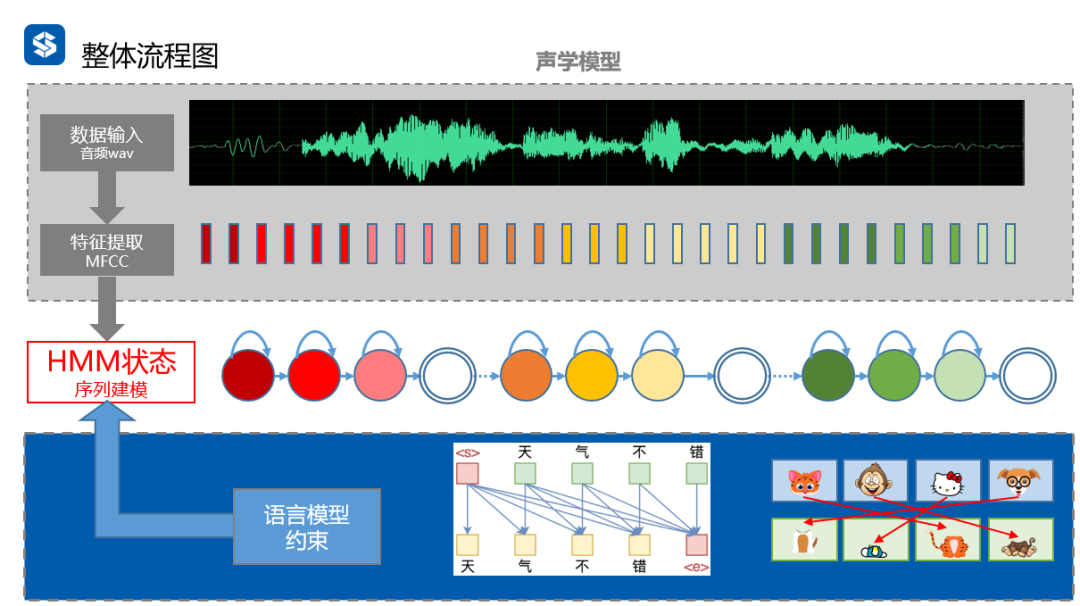
声学模型搭配语言模型,最后才能获取正确的结果。我们知道从一段音频,经过提取特征,HMM,GMM或DNN等,可以获取状态。
之的声学模型,也就是流程图的上半部分。现在我们加入了下半部分的语言模型约束,双管齐下,最终转换为对应文本。
感觉意犹未尽?好吧,再来说说常提的两个算法:EM算法和Viterbi
两个算法
EM算法
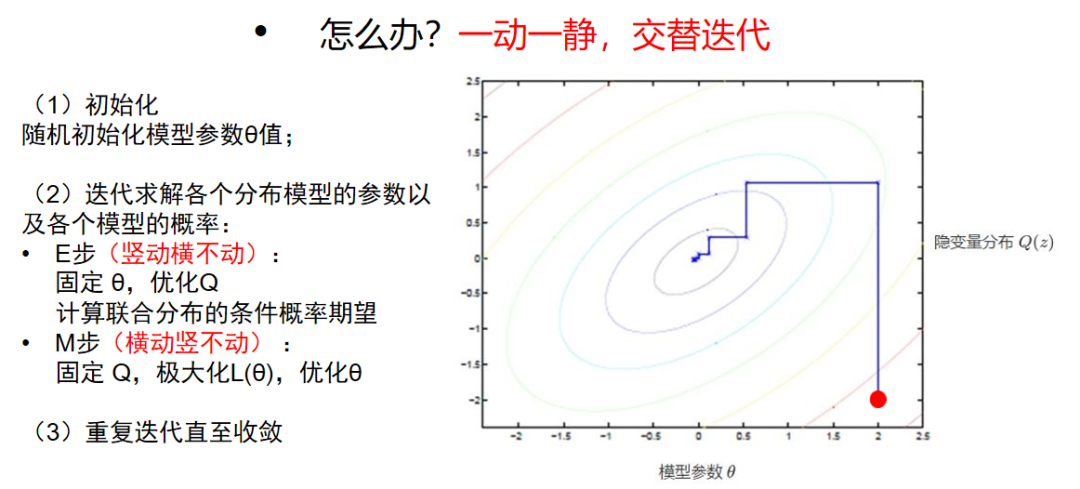
像HMM和GMM都是隐变量模型,这种模型麻烦在哪里呢,一般都会有很多的变量,而且隐变量和模型参数互相影响,扯不清,缠缠绵绵到天涯牵。不要紧,我们有神器啊,EM(Expectation Maximization)算法来了。
举个例子:有一堆人,现在只有他们的身高数值,但是不知道男女具体各多少人,也不知道某个身高对应的人是男是女,需要算出男生的平均身高该怎么办?
分成两步走,一个是E步,另外一个自然就是M步了(为什么叫这个,其实是有对应含义的,我们先不管)。一堆变量不用怕,只要按规矩来,不要瞎动搞乱了就行。原则就是:一动一静,交替迭代,最后就收敛到最佳的状态。
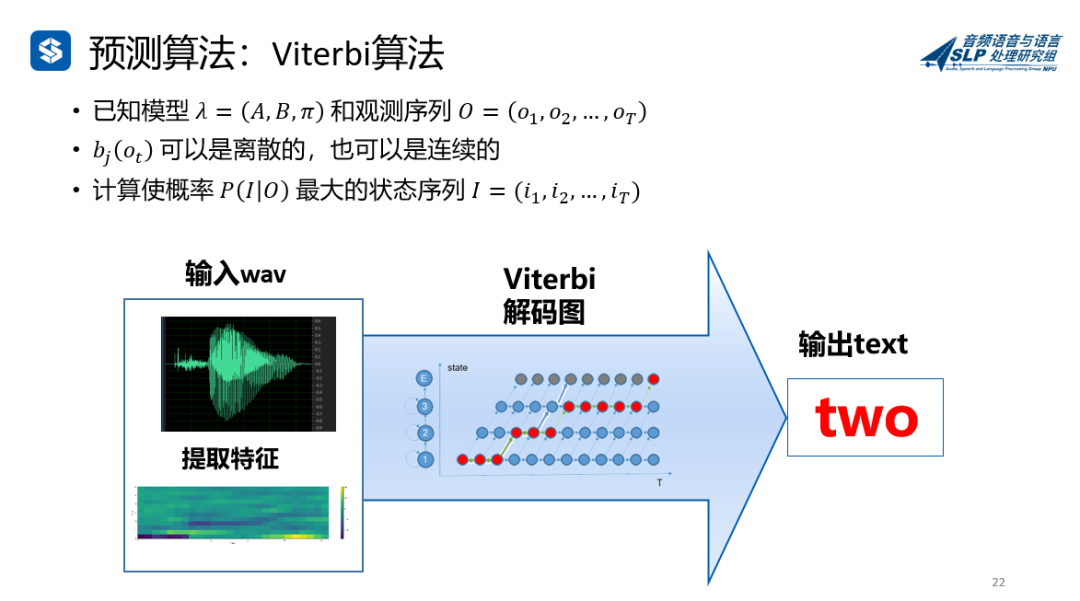
Viterbi算法
训练,解码,对齐等时候,总是提到维特比(Viterbi)这个词。Viterbi算法,Viterbi对齐,Viterbi图,那维特比是什么呢?
看下图,维特比就是最优路径。比如从教室去食堂,有12345条路,你可以直接过去,也可以越过高山跨过河流绕一大圈过去,殊途同归,最后都能到食堂。
Viterbi算法,就是算出概率最大的最优的路径(正常人赶时间都会走最短的直线,对吧?就是这条),也就是下图红圈的那些,其他的都舍去。有个这个图,正着算,反着回溯,也就都可以了。
作者:深蓝学院语音教研组

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









