






当救援机器人冲进坍塌废墟时,传统导航系统还在像"近视眼找钥匙"——依赖预存地图或简单图像匹配。而最新研发的「VL-Nav」导航系统,让机器人在完全陌生环境中化身"福尔摩斯":仅凭一句"寻找穿黑衣服的人",就能实时解析像素级语义信息,像人类般边探索边推理。
这项技术的革命性在于"视觉+语言+直觉"的三维智慧。研究团队创造性地将AI绘画的像素级理解能力与生物好奇心机制结合,使机器人在扫描环境时,既能识别"黑色衣角闪过窗边"的细节,又能自主判断"该向左绕开倒塌书架还是向右探查门廊"。搭载在四轮机器人上的实测显示,面对仓库、公园等复杂场景,其成功率飙升至86.3%,比传统算法提升44%,更惊人的是整套系统仅需一块车载芯片就能30帧/秒实时运算。这意味着未来救灾机器人可以像训练有素的搜救犬,仅凭一句指令就穿透浓烟毒雾,精准锁定幸存者位置。
©️【深蓝AI】编译
论文标题:VL-Nav: Real-time Vision-Language Navigation with Spatial Reasoning
论文作者:Yi Du, Taimeng Fu, Zhuoqun Chen, Bowen Li, Shaoshu Su, Zhipeng Zhao, Chen Wang
论文地址:https://arxiv.org/abs/2502.00931
项目地址:https://sairlab.org/vlnav/
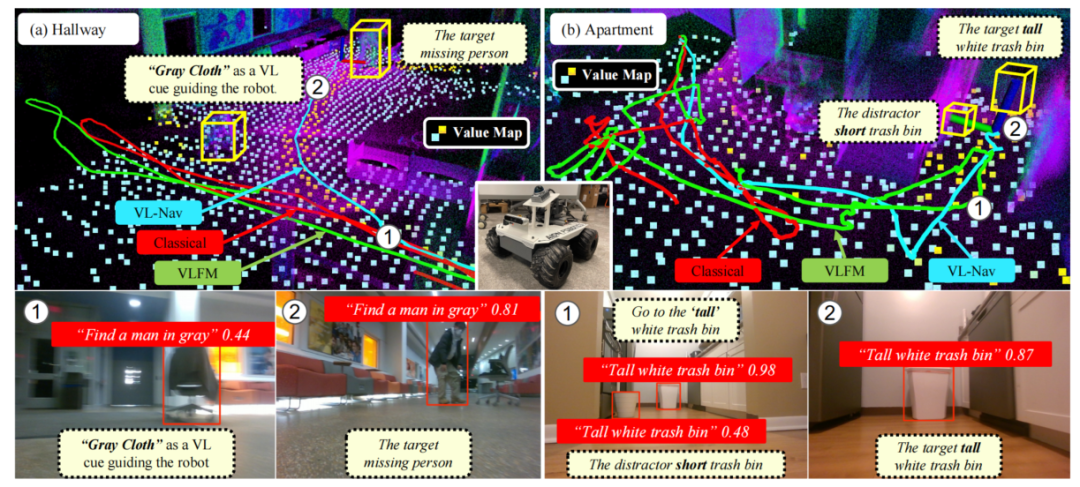
▲图1| VL-Nav,这是一种具有空间推理能力的实时零样本视觉 - 语言导航方法,它将像素级视觉 - 语言特征和基于好奇心的探索相结合,用于移动机器人。(a)走廊场景:轮式机器人在走廊中执行 “找到一个穿灰色衣服的人” 的任务。与经典基于前沿的方法(红线)和 VLFM(绿线)不同,VL-Nav(蓝线)利用 “
01 引入
在未见过的环境中,按照人类指令进行高效导航对于自主机器人至关重要,应用范围从家庭助手到行星探索等都有涉及。在这种场景下,机器人任务是探索并识别由人类指示的目标,该研究将这一挑战定义为视觉语言导航(VLN)。假设有一名穿灰色衣服的人失踪,给出指令“找一个穿灰色衣服的人”,机器人不应进行随机探索。相反,它应该优先选择与语言线索有更强相关性的视觉特征方向,例如在视野中检测到“灰色衣物”。现实世界中的VLN要求导航系统能够:(1)解释逐像素的视觉语言特征;(2)在不同环境中适应并稳定执行;(3)在低功耗平台上实时运行。
然而,目前还没有VLN系统能够完全解决这三项能力。现有的方法可以大致分为经典方法、端到端学习方法和模块化学习方法。经典方法虽然高效,但难以整合视觉语言特征。端到端学习方法虽然有潜力,但计算开销大,容易在仿真中过拟合,并且在分布外场景中的泛化能力差。模块化学习方法则展示了在现实世界中的强大表现,但它们通常依赖大量的现实世界机器人训练数据,且缺乏类人推理能力。视觉语言模型(VLM)和大规模语言模型(LLM)的出现进一步增强了模块化导航方法。例如,Vision-Language Frontier Maps(VLFM)利用VLM从RGB图像中直接提取语言驱动的特征。这使得能够创建一个语义地图,引导基于人类语义知识的探索。然而,它们对计算密集型模型的依赖限制了其在低功耗平台上的可部署性。此外,VLFM在目标选择时过度依赖单一的图像级特征相似性,限制了其利用细粒度视觉语言线索的能力。
为了解决这一问题,该研究提出了视觉语言导航(VL-Nav),这是一种新型的导航框架,优化了低功耗机器人,能够在搭载计算机的情况下以30 Hz的频率实现零样本VLN。VL-Nav在基于前沿和基于实例的目标点上应用空间推理。VL-Nav首先通过部分前沿检测从动态占用地图中生成基于前沿的目标点。它将搜索限制在可管理的视野范围内,从而减少计算开销。此外,结合了基于实例的目标点以模拟人类搜索模式,使机器人能够接近并验证潜在的目标物体,从而提高成功率。为了选择最有信息量的目标点,该研究引入了CVL空间推理技术。该技术首先使用高斯混合模型将逐像素视觉语言特征转换为空间评分分布。然后,根据此分布为每个目标点分配一个视觉语言语义分数。随后,应用好奇心驱动的加权,鼓励机器人探索未知区域,将这些分数调整为CVL分数。最终,具有最高CVL分数的目标点被选为目标点。此CVL空间推理过程确保所选目标点不仅与人类描述紧密对齐,还能引导机器人探索未知区域。
一旦目标被选定,VL-Nav利用经典规划器进行实时避障路径规划,从而实现对部分已知环境的无缝适应。通过将逐像素的视觉语言特征与通过新颖的CVL空间推理进行的好奇心驱动探索相结合,VL-Nav超越了所有基准方法,实现了智能导航,同时保持了在现实部署中的计算可行性。
该研究的主要贡献如下:
-
该研究提出了VL-Nav,一种为低功耗机器人优化的高效VLN系统,在搭载计算机的情况下以30 Hz的频率实现稳健的实时性能。
-
该研究通过整合逐像素的视觉语言特征和好奇心驱动的探索,赋予VL-Nav空间推理能力,从而使VLN更加高效。
-
该研究在四个现实环境中进行了全面评估,结果表明,VL-Nav在多种环境下的表现比以前的方法提高了44.15%。
02 具体方法与实现
如图1 展示了VL-Nav 流程的概览,VL-Nav 处理的输入包括提示信息、RGB 图像、里程计位姿和激光雷达扫描数据。视觉 - 语言(VL)模块进行开放词汇表的像素级检测,以识别与提示信息相关的区域和物体,生成基于实例的目标点。同时,地图模块进行地形分析并管理动态占用地图。然后,基于该占用地图识别出基于前沿的目标点,连同基于实例的点一起,形成候选点池。VL-Nav 利用空间推理从该候选点池中选择最有效的目标点用于路径规划。
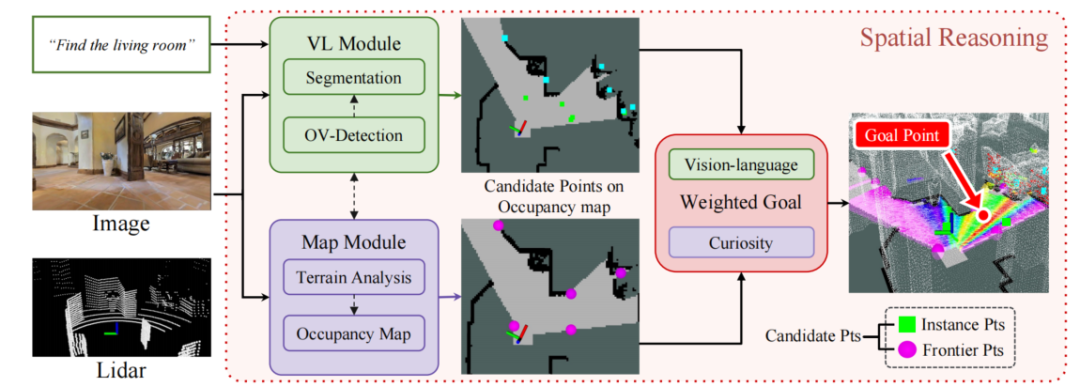
▲图2| 全文方法总览©️【深蓝AI】编译
2.1. 滚动占用栅格地图
作者将环境表示为一个2D占用网格G,其中每个单元格可以是自由(0)、未知(−1)或占用(100)。在接收到新的传感器数据(合并的障碍物和地形云P)后,作者使用以下步骤更新
-
扩展地图:如有需要,若任何新观察到的点位于当前地图边界之外,则扩展网格以保存历史数据。
-
清除过时障碍物:对于机器人前方视野(FOV)内标记为占用的每个单元格,检查它是否仍对应于P中的某个点。任何“过时”的障碍物单元格将被重新标记为自由。
-
膨胀新的障碍物:对于P中位于传感器范围R内的每个点,将相应的单元格标记为占用,并根据膨胀半径标记一个局部邻域。
这一步的主要目的是为后续的流程提供一张先验的地图,同时能够找到一些值的探索的区域,这个过程非常类似于SLAM的后端建图过程,如果有SLAM基础的读者小伙伴可以将其直接当成一个高频率更新地图的Mapping进程去理解即可,这个部分作为全文的前端对精度的要求是非常高的,作者在后续的实验部分也验证了该部分的精度。
2.2. 基于实例的目标点
在完成前期的建图之后,下一步是看看当前的机器人观测中,是否存在想要找到的目标点,这一步实际上就是一个搜索的过程,而这里就是视觉语言模型大展身手的地方。视觉-语言探测器定期报告候选实例中心,形式为 (qx, qy, confidence),其中 qx, qy 表示潜在目标实例的估计全局坐标,confidence 量化了该探测匹配目标实例的可能性。如果 confidence 大于检测阈值 τdet,则保留该候选;否则,认为其不确定而丢弃。如果多个候选位于较近位置,则通过体素网格滤波器对保留的点进行下采样。
这种基于实例的方法模仿了人类搜索物体的行为:当看到可能匹配目标的东西时,人们自然会走近确认。VL-Nav 同样不会忽视中间检测。相反,任何超过置信度阈值的候选都被视为有效目标候选,允许机器人接近并验证其是否真的是一个感兴趣的实例。如果检测结果证明不正确,机器人将继续通过前沿或其他实例线索进行探索,从而产生一个准确且稳健的零样本导航策略,朝着目标实例前进。
2.3. 目标点评分策略
一旦收集到前沿质心和基于实例的目标,系统会为每个候选目标计算一个 CVL 评分。这里的前沿即Frontier,指的是可见区域和不可见区域的交接点,是机器人探索的首要目标。
这个评分是通过多个加权高斯分布的组合来计算的,其中每个分布的均值和标准差通过目标的角度偏移与每个高斯分布的参数对比得出。与该目标相关的视觉-语言语义分数则通过考虑该目标的方向和角度偏差来调整,以此给出相应的权重。

▲图3| CVL的评分算法流程©️【深蓝AI】编译
好奇心线索:作者添加了两个好奇心项来引导导航向更大的未探索区域移动,并防止系统重复选择远距离目标,这些目标仅提供了VL得分的微小增加,从而减少不必要的来回移动,这在像走廊和户外环境等大规模环境中尤为重要。
-
距离加权:作者定义距离加权分数,使得较近的目标得到稍高的分数。这个因素在真实机器人中尤其重要,因为较短的旅行距离可以显著减少能源消耗,并防止不必要的漫游。虽然单独的距离项不能保证最优路径,但它有助于优先选择可以更快到达的目标。
-
未知区域加权:作者进一步通过测量 g 周围有多少未知单元格来鼓励好奇心驱动的探索。作者计算从目标 g 开始的局部广度优先搜索(BFS)中,未知单元格与可达单元格的比例。较大的未知比例表示移动到 g 可能会揭示显著的未知空间并获得更多信息。为了将这个原始比率转换为归一化的加权分数,作者应用指数映射,调整分数的增加速度。
-
综合 CVL 评分:基于前沿的目标最终分数组合了这三部分:距离加权、视觉-语言语义分数和未知区域加权。
其中,距离加权和视觉-语言分数的组合确定了目标的初步评分,而好奇心线索(包括距离和未知区域加权)则在目标选择时进行评估,确保选择的目标既符合语言描述,又能引导机器人探索未知区域。
03 实验
在实验部分,比较亮眼的一点是作者在大量的真实环境做了许多测试,这是当前同期工作很难做到的,因为VLN的部署需要花费大量的时间成本,但是本文的出色部署工作展示了作者在硬件方面极大的工作量,下面展示的是一些实验的环境。

▲图4| 实验环境展示©️【深蓝AI】编译
首先作者展示了本文的算法在图4中四个场景中的数值化实验结果,如下图所示,可以看到本文的结果能够取得较出色的领先(平均的数值能够提升25%左右)
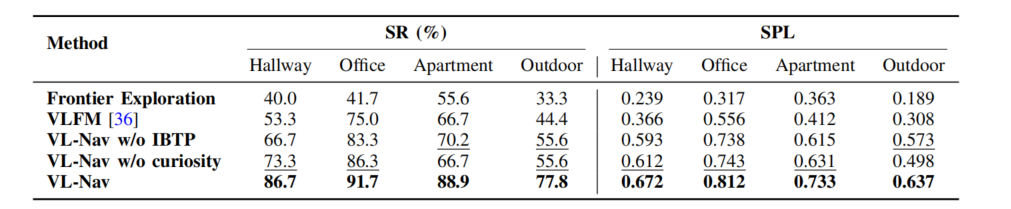
▲图5| 真实场景实验数值数据结果©️【深蓝AI】编译 ▲图6| 系统导航流程可视化©️【深蓝AI】编译
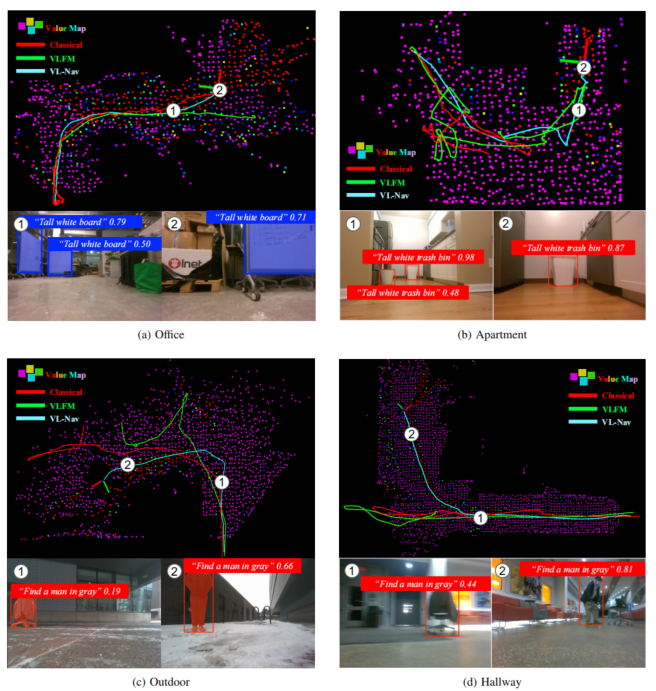
图6作者提供了导航系统角度的可视化,可以看到在导航系统中,本文算法会优先建立一个稠密的地图,随后再选择值的探索的方向和区域,并引导机器人前往,在探索的过程中会实时寻找目标,一旦目标被找到则会规划路径前往,从轨迹上来看,本文算法的轨迹能够取得最优的结果!
随后作者还对比了本文方法在不同的环境尺度和不同的语义复杂度的条件下的实验表现,能够看到在环境尺度变化时,本文的方法体现出了更强的鲁棒性,在语义复杂度提升时,本文方法也展示了很好的适应性。
▲图7| 环境尺度和语义复杂度实验©️【深蓝AI】编译
04 总结
在本文中,作者介绍了 VL-Nav,这是一种视觉 - 语言导航框架,能够在资源受限的平台上实现实时高效运行。通过将像素级视觉 - 语言特征与基于好奇心的探索策略相结合,作者的 CVL 空间推理方法在多种室内和室外环境中展现了稳健的性能。在实际测试中,VL-Nav 不仅在 Jetson Orin NX 上实现了 30 赫兹的实时导航,而且比现有方法提高了 44.15%,总体成功率达到 86.3%。这些进步的关键在于有效利用视觉 - 语言嵌入的语义线索来优先考虑前沿和潜在物体实例,从而使导航决策更接近人类的推理方式。
未来的工作将探索扩展 VL-Nav 以处理更复杂的指令,这些指令涉及多步骤任务、时间推理(例如跟踪移动目标)和动态环境。此外,与大型语言模型的进一步整合可以使命令解析更加细腻,并实现开放词汇表的物体检测,从而具有更广泛的应用性。作者相信这些方向将有助于提升 VLN 系统的能力,并使作者更接近于在现实世界环境中部署多功能、稳健的机器人助手。

















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









