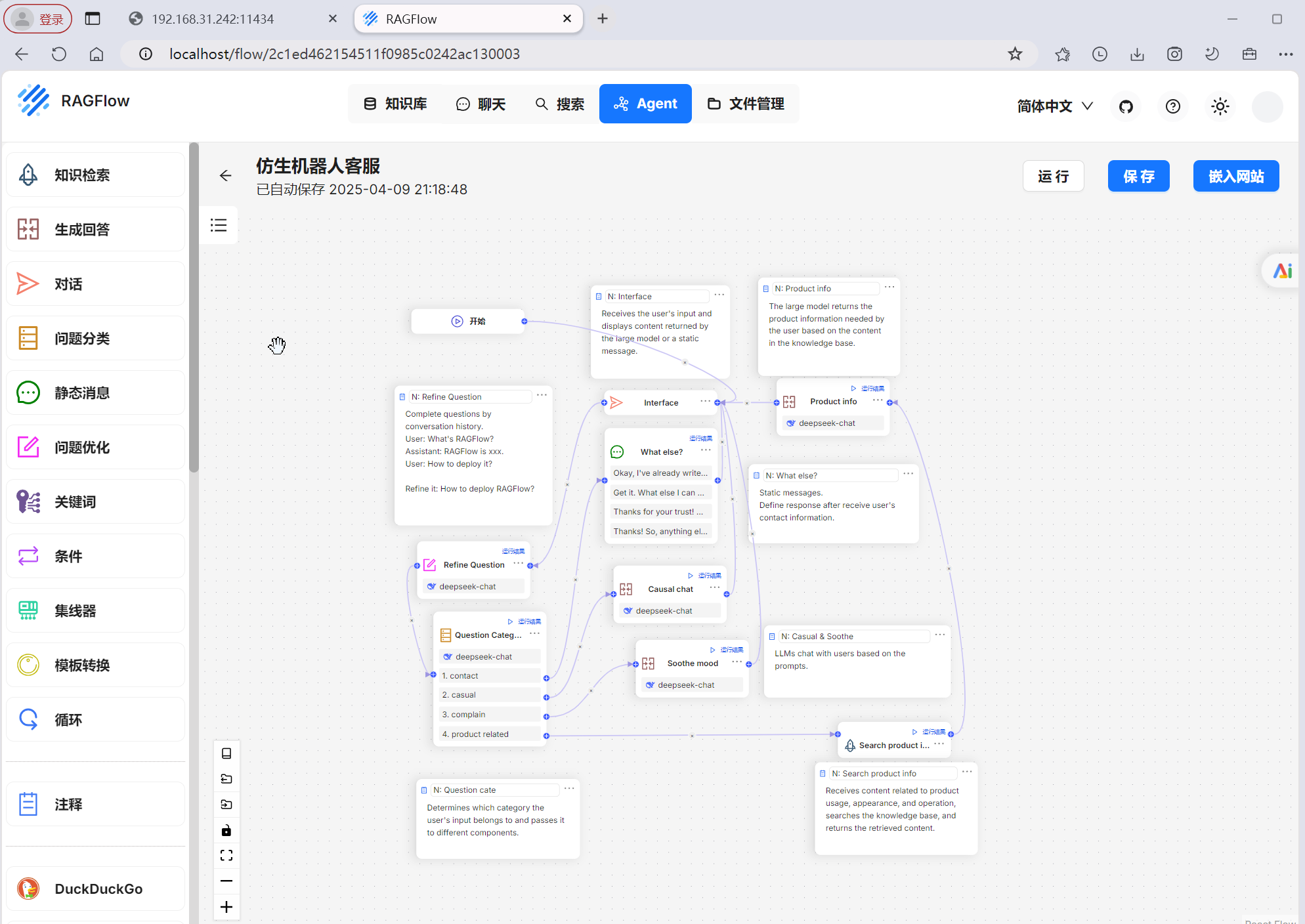
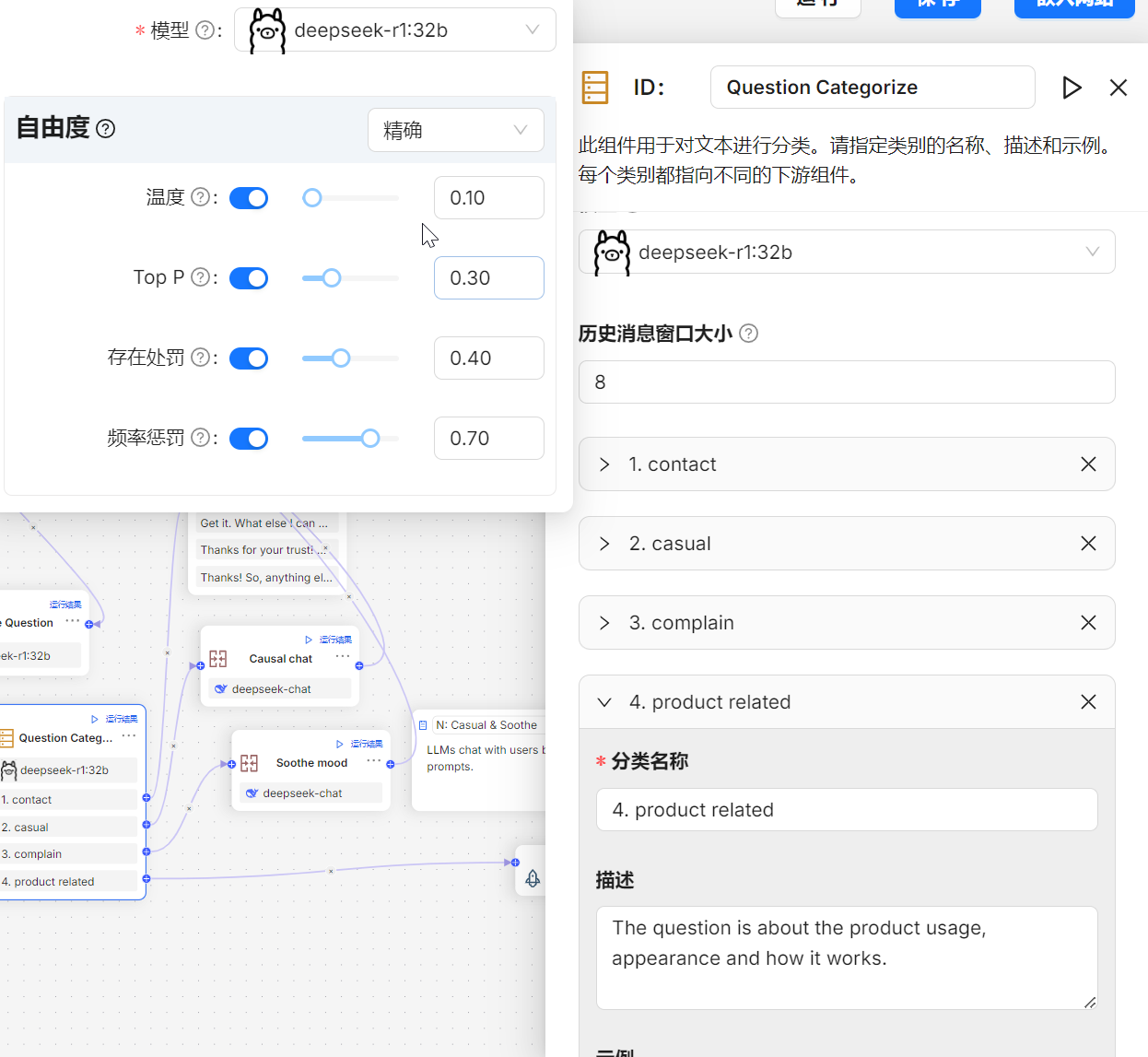
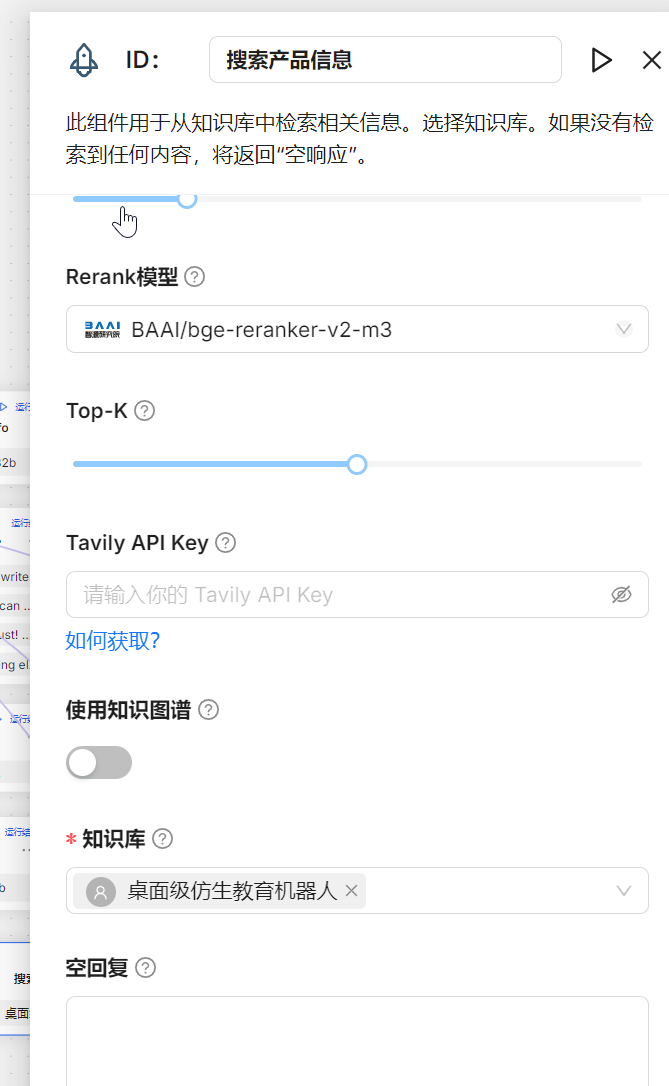
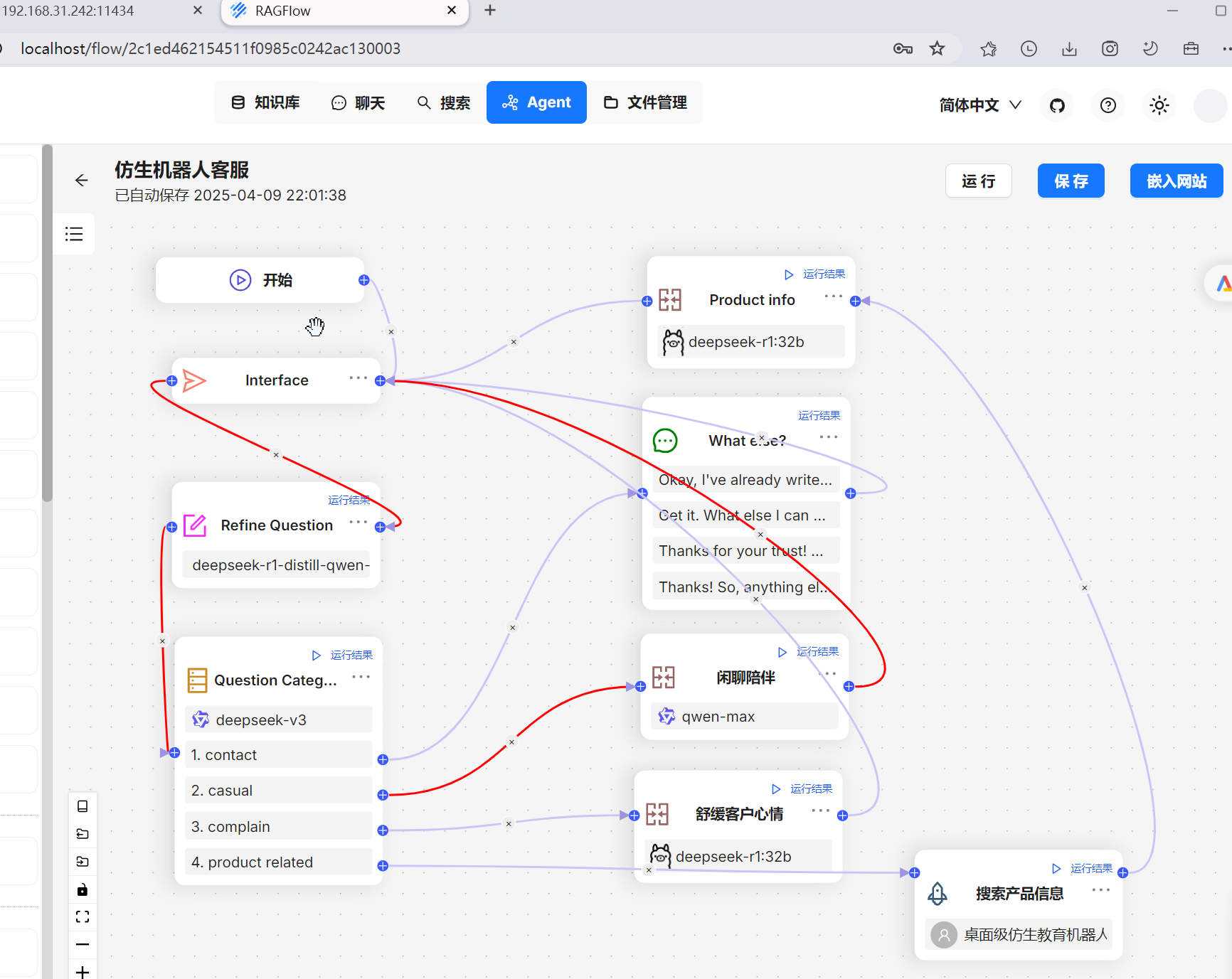
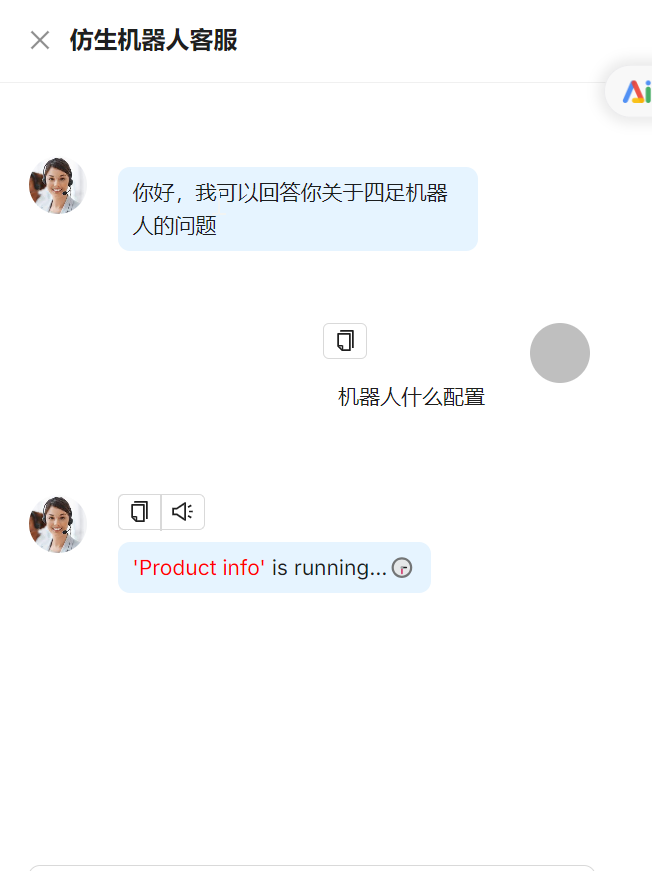
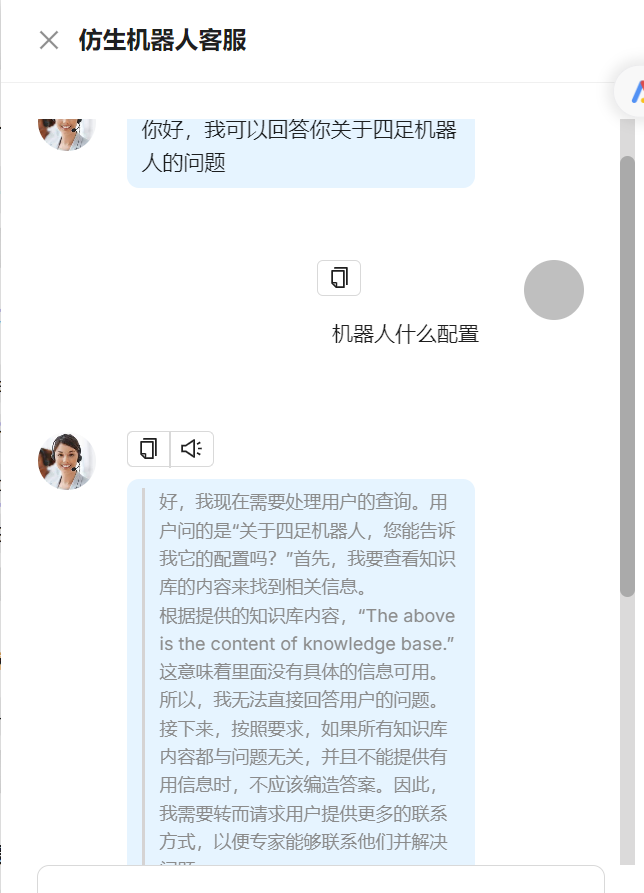
从零实现Agent智能体配置使用(Ragflow) 1. 创建智能体2. 配置智能体2.1 配置问题识别2.2 配置问题分类2.3 不同问题进行单独配置2.4 保存Agent 3. 体验效果 1. 创建智能体 2. 配置智能体 2.1 配置问题识别 2.2 配置问题分类 2.3 不同问题进行单独配置 当前模板默认带了四类问题:搜索产品信息、客户抱怨、闲聊、咨询,分别配置大模型,尤其关于产品信息的配置,除了大模型还需要配置对应知识库 2.4 保存Agent 3. 体验效果 运行智能体





























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 4377
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
4377
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








