







本文是对论文《Deep Reinforcement Learning for Joint Spectrum and Power Allocation in Cellular Networks》的分析,若需下载原文请依据前方标题搜索,第一作者为Yasar Sinan Nasir。
一、研究内容概述
本文作者联合使用DQN和DDPG强化学习方法,用于下行功率控制中的频带选择与能量分配。结果表明,该方法具有很好的收敛速度和泛化性能。
二、系统目标与约束
1.系统描述

如上图所示,整个功率分配系统有两部分组成,我们将其描述为顶层与底层。顶层是一个DQN网络,用于子带的选择。底层是一个DDPG网络,以顶层选择的子带作为输出,输出对应的功率分配值。
2.系统目标

系统的目标为最大化信道容量,信道容量由下式定义

其中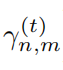 是频带所对应的SINR值,公式如下
是频带所对应的SINR值,公式如下

公式中,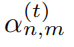 表示在t时刻发射机n的子带选择m(取值为0或1)。
表示在t时刻发射机n的子带选择m(取值为0或1)。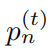 表示在t时刻发射机n的发射功率。
表示在t时刻发射机n的发射功率。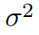 表示高斯噪声功率值。
表示高斯噪声功率值。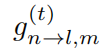 表示t时刻,在子带m上,发射机n到接收机l的信道增益。其具体展开如下
表示t时刻,在子带m上,发射机n到接收机l的信道增益。其具体展开如下

其中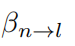 为大尺度衰落,包含路径损耗和阴影衰落。
为大尺度衰落,包含路径损耗和阴影衰落。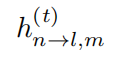 为小尺度瑞利衰落。本文假设大尺度衰落在所有时隙中保持不变。小尺度衰落继续展开为
为小尺度瑞利衰落。本文假设大尺度衰落在所有时隙中保持不变。小尺度衰落继续展开为

其中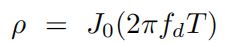 ,
,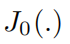 是依赖于最大多普勒频率fd的第一类零阶贝塞尔函数。
是依赖于最大多普勒频率fd的第一类零阶贝塞尔函数。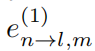 是具有单位方差的独立同分布的圆对称复高斯随机变量。
是具有单位方差的独立同分布的圆对称复高斯随机变量。
三、DQN、DDPG网络设计
四、性能表征

本文所提出的基于DQN与DDPG联合子带选择与功率分配模型,相较于传统的FP算法,具有更高的信道容量和值。随着系统链路规模的增大,本文所提出的算法仍能保持很好的收敛性和收敛速度。

















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











