






Meta分析一对一指导,符合学术规范,结课直接投稿,+tjzgBL哟!
meta分析森林图里长长短短的横线和形状分别代表了什么?这就是我们本期需要解决的问题:meta分析森林图解读。
本文我以《胰岛素联合低分子肝素治疗高脂血症性急性胰腺炎有效性和安全性的 meta分析》中的森林图为例,进行meta分析森林图解读,解析每一部分所代表的研究意义。
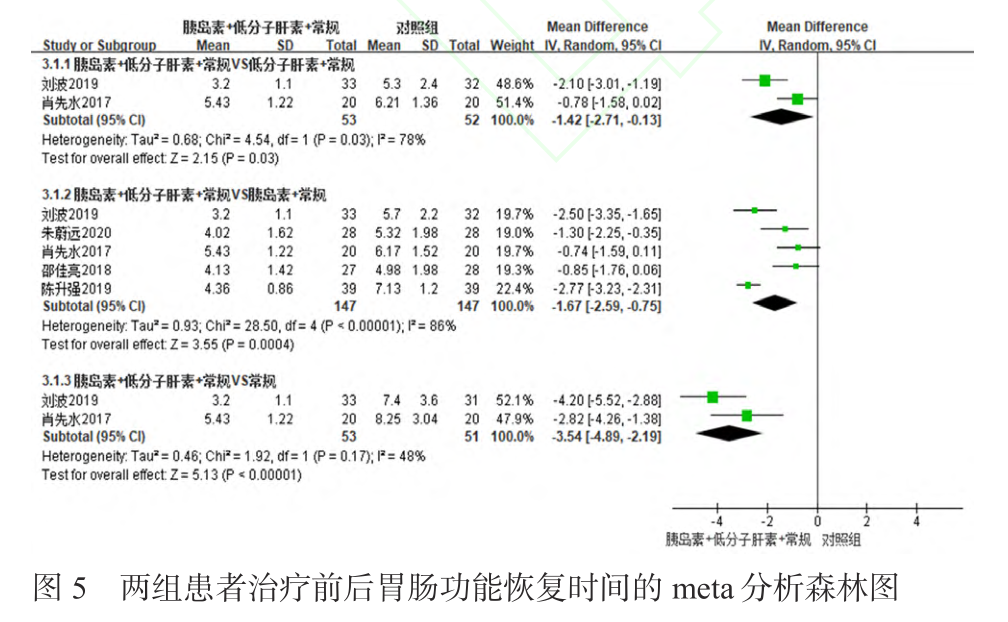
一、各部分具体含义
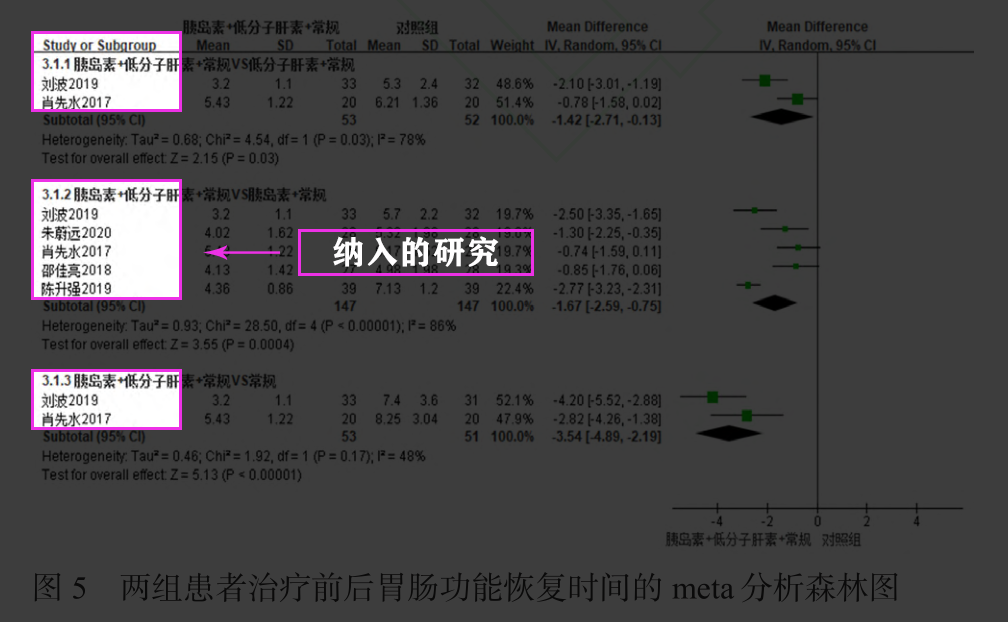
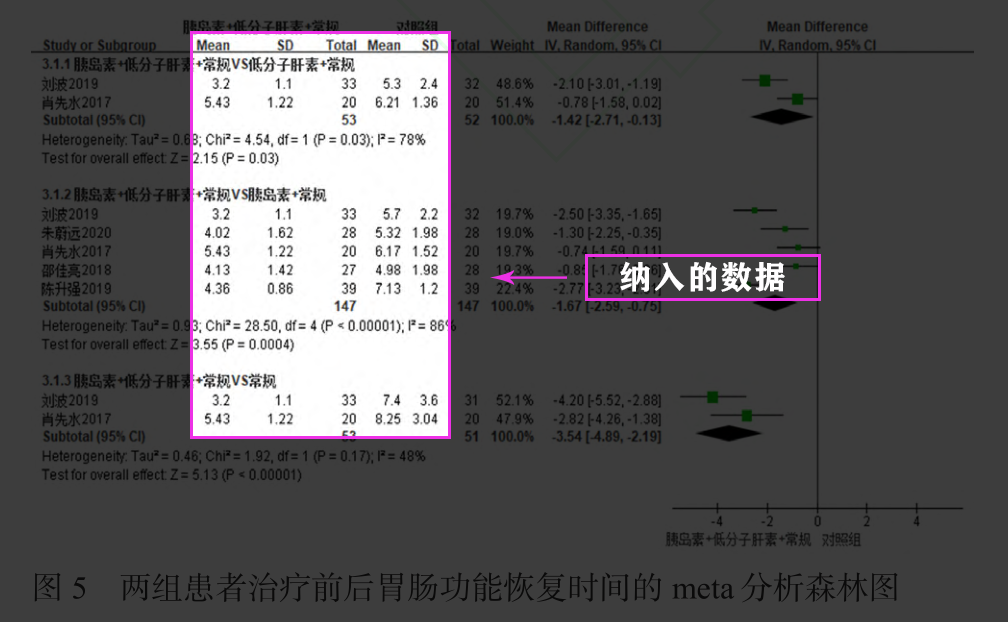
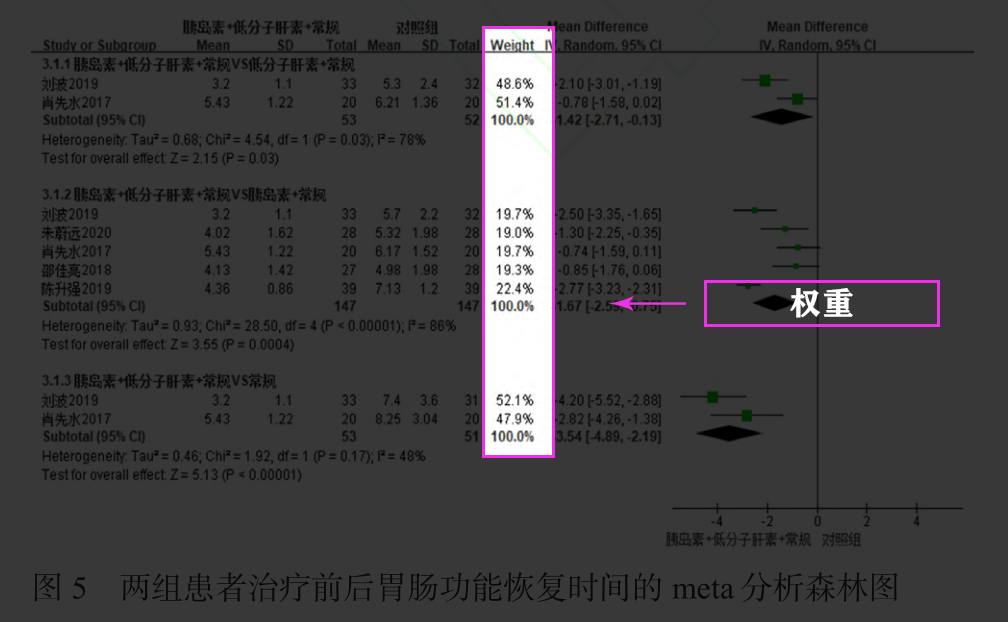
 </
</

Meta分析一对一指导,符合学术规范,结课直接投稿,+tjzgBL哟!
meta分析森林图里长长短短的横线和形状分别代表了什么?这就是我们本期需要解决的问题:meta分析森林图解读。
本文我以《胰岛素联合低分子肝素治疗高脂血症性急性胰腺炎有效性和安全性的 meta分析》中的森林图为例,进行meta分析森林图解读,解析每一部分所代表的研究意义。
一、各部分具体含义
</
 307
9287
1305
5481
307
9287
1305
5481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























