







 这篇文章介绍了一种名为DCTNet的技术,通过在图像预处理后进行YCbCr空间的DCT变换,将大分辨率图像压缩到小尺寸输入神经网络。文章探讨了频频道选择策略,包括基于学习的频率通道选择,以及固定和动态保留频率的效果。尽管高频信息对于某些低级任务可能重要,但实验显示动态选择与固定策略性能相近。
这篇文章介绍了一种名为DCTNet的技术,通过在图像预处理后进行YCbCr空间的DCT变换,将大分辨率图像压缩到小尺寸输入神经网络。文章探讨了频频道选择策略,包括基于学习的频率通道选择,以及固定和动态保留频率的效果。尽管高频信息对于某些低级任务可能重要,但实验显示动态选择与固定策略性能相近。
DCTNet
http://giantpandacv.com/academic/%E7%AE%97%E6%B3%95%E7%A7%91%E6%99%AE/%E9%A2%91%E5%9F%9F%E4%B8%AD%E7%9A%84CNN/CVPR%202020%20%E5%9C%A8%E9%A2%91%E5%9F%9F%E4%B8%AD%E5%AD%A6%E4%B9%A0%E7%9A%84DCTNet/
一个对输入图像进行频域转换和选择的方法,达到压缩的目的,主要应用大分辨率图像压缩为小的输入图像,输入到神经网络。
1.首先对图像进行正常的预处理: resize, croping, flip等.
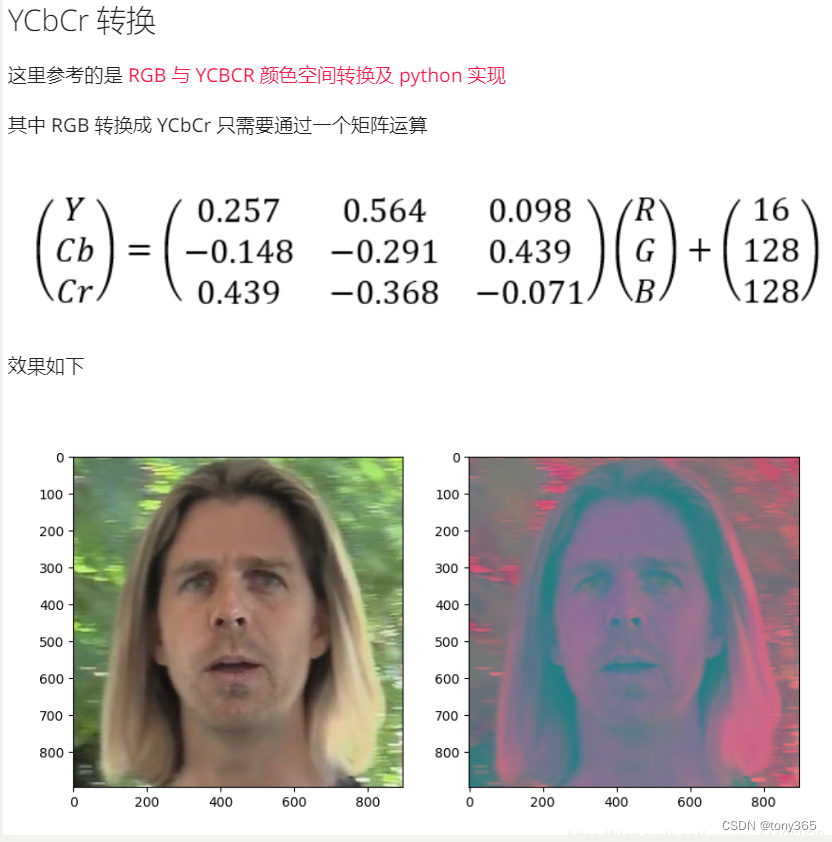
2.然后转换到YCbCr空间:
参考:https://zhuanlan.zhihu.com/p/88933905
0.564应该是0.504
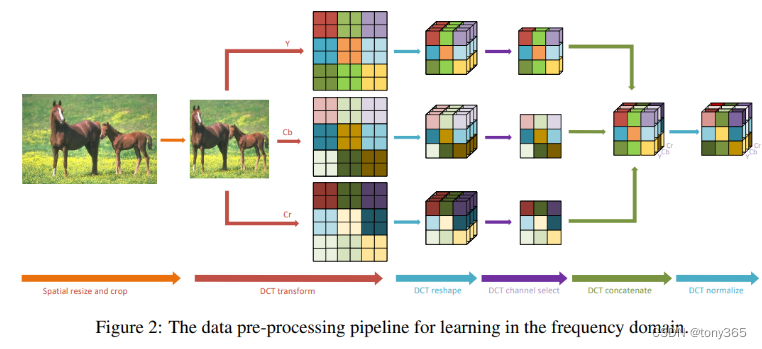
3.dct转换
https://blog.csdn.net/tywwwww/article/details/126464132
分别对 Y, Cb, Cr处理
假如 224 224 1 的图像,进行patchsize= 8的DCT变换后
得到(56x8) (56x8) 1的图像
然后 每个8x8 patch相同的频率的 group在一起,什么意思呢?就是pixelshuffle的逆操作,这样 变为 56x56x64的 大小, YCbCr一共 192个channel
注意此时每个通道的含义:每个通道表示相同的频率。
如下图所示:只是下图的patch size=2
4.dct channel prune:Learning-based Frequency Channel Selection
虽然以上 图像h,w降下来了,但是channel 变大,整体数据量是没有变的。这个时候可以应用通道剪枝的方法,对channel进行筛选。
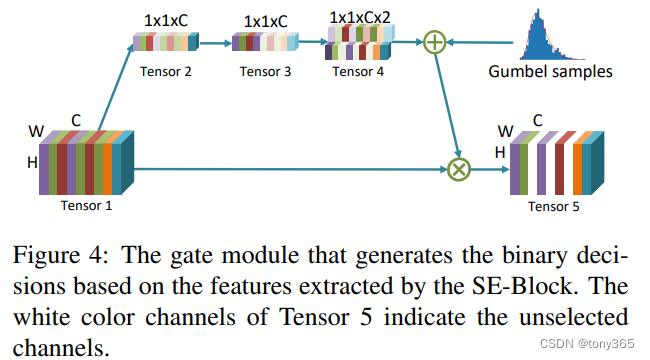
论文中先 vagpool , 再 1x1卷积 得到tensor3。 剩下的不懂也感觉麻烦。tensor3后面跟softmax 不是就可以 select了吗 转化为 0,1
具体选择了哪些频率,作者画出来了:
8x8 patch 共有64个频率,下图的数字就是表示各个频率。 颜色深浅表示保留的概率。
可以看出低频更容易被保留。因此作者还实验了 固定保留左上角的频率,左上角的方块Square或者三角Triangle。 和动态选择 的性能差不多。因此是不是就没必要动态select channel了
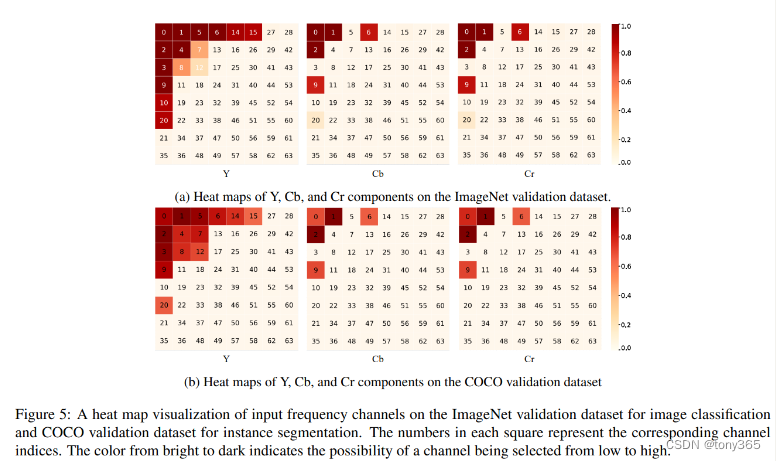
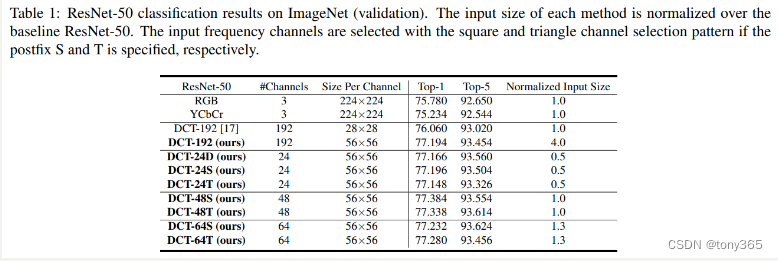
在 high level任务上这样做或许可以,但是low level任务高频信息一般也比较重要。















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









