







到今天(2024年12月25日)YOLO模型的发展过程
我找到一篇论文,大家可以去看一下,YOLOv11 An Overview of the Key Architectural Enhancements
还有一篇Evaluating the Evolution of YOLO (You Only Look Once) Models: A Comprehensive Benchmark Study
of YOLO11 and Its Predecessors
YOLO 系列版本改进总览
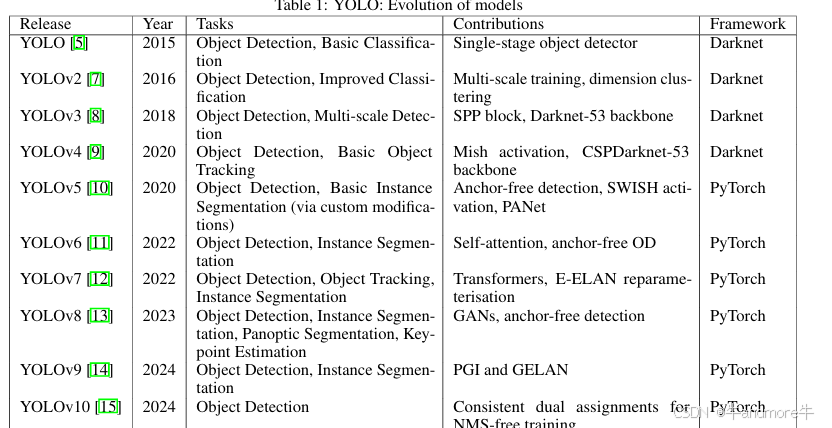
YOLOv1 (2015)
- 首次提出 one-stage 检测架构:直接在图像上预测边界框和类别,无需先生成候选区域。
- 将图像分为 S×S 网格进行预测:每个网格负责预测包含目标的边界框和类别。
- 速度快但准确率较低:由于简化了流程,速度很快,但定位和分类精度相对较低。
- 总结: YOLO 系列的开山之作,奠定了 one-stage 检测的基础,注重速度,但精度有待提高。
YOLOv2 (2016)
- 引入 anchor boxes:预先定义一组不同尺寸和比例的框,帮助模型更好地预测目标。
- 添加 batch normalization:加速训练,提高模型稳定性。
- 使用 k-means 聚类生成 anchor 尺寸:自动确定最佳 anchor 尺寸,更适应数据集。
- 引入多尺度训练:在不同分辨率的图像上训练,提高模型对不同大小目标的适应性。
- 总结: 引入 anchor boxes 和多尺度训练,精度得到显著提升,训练更加稳定。
YOLOv3 (2018)
- 使用 Darknet-53 骨干网络:一个更深层次的卷积神经网络,能够提取更丰富的特征。
- 多尺度特征图预测 (FPN 结构):融合不同层级的特征,更好地检测不同大小的目标。
- 引入残差连接:缓解深层网络训练中的梯度消失问题。
- 每个类别独立的逻辑回归:每个类别使用独立的回归器,提高分类精度。
- 总结: 引入多尺度特征和残差连接,进一步提升了精度,使其更加适应不同大小的目标。
YOLOv4 (2020)
- 引入 CSPDarknet53 骨干网络:进一步提升了骨干网络的特征提取能力,并减少计算量。
- 数据增强: Mosaic、CutMix:更复杂的增强方法,增加训练数据的多样性,提高模型鲁棒性。
- 引入 ASFF、SAM 注意力机制:增强模型对重要特征的关注,提高检测精度。
- 添加 BoF 和 BoS 策略:使用更好的技巧提高模型性能。
- 总结: 使用了更强大的骨干网络,结合更有效的数据增强和注意力机制,性能大幅提升。
YOLOv5 (2020)
- 改进 CSP 结构:进一步优化 CSP 网络结构,使其效率更高。
- Focus 层替代原有 stem 层:更高效地提取初始特征。
- 自适应 anchor boxes 计算:自动适应数据集的 anchor 尺寸。
- 自适应图像缩放:根据数据集动态调整图像缩放比例,提高模型适应性。
- 总结: 在 YOLOv4 的基础上,更加注重工程实现和部署,简化了设计并提高灵活性。
YOLOv6 (2022)
- RepVGG 风格设计:使用重参数化技术,加速模型训练和推理。
- 去 anchor 设计:减少了超参数调整,简化了模型设计。
- TAL 分配策略:更加智能的标签分配,更好地匹配目标和预测。
- 引入 SimOTA 标签分配:一种动态标签分配策略,提升训练效果。
- 总结: 采用 RepVGG 风格设计,提升模型训练和推理效率,并探索了无 anchor 的检测方式。
YOLOX (2021)
- 解耦头部设计:分别进行分类和回归预测,提高预测精度。
- 去 anchor 设计:简化模型,减少超参数。
- SimOTA 标签分配:动态匹配目标和预测,提升训练效果。
- 引入 strong augmentation:使用更强的数据增强,提高模型鲁棒性。
- 总结: 进一步简化模型,采用解耦头和 SimOTA,并注重数据增强,提升了性能和训练效率。
YOLOv7 (2022)
- E-ELAN 扩展网络结构:进一步提升网络特征提取能力。
- 辅助头设计:帮助模型更好地学习目标特征。
- 重新参数化模块:提升模型训练速度和性能。
- 动态标签分配策略:更灵活的标签分配策略,提高模型学习效率。
- 总结: 通过更复杂的网络结构和重新参数化模块,进一步提升精度,并探索了动态标签分配。
YOLOv8 (2023)
- 改进骨干网络:使用更高效的骨干网络进行特征提取。
- 优化头部设计:提升预测性能和训练效率。
- C2f 模块替换 C3:一种更高效的网络模块,提升模型性能。
- 统一的头部结构:简化模型设计,使其更易于使用和部署。
- 总结: 优化了整体结构,使用了更高效的模块,并统一了头部设计,使其更易用。
PPYOLOE (2022)
- 改进 CSP 骨干网络:使用更高效的 CSP 网络结构进行特征提取。
- Task Alignment Learning:一种学习目标和预测对齐的方法,提高检测精度。
- Varifocal Loss:一种更有效的损失函数,提升模型学习效率。
- 去 anchor 设计:简化了模型设计。
- 总结: 采用了更高效的骨干网络,优化了损失函数,进一步提升精度。
PPYOLOE+ (2022)
- ET-Head 设计:一种新的头部设计,提高预测性能。
- TAL 改进版本:进一步提升标签分配策略的效率。
- 更高效的骨干网络:提升特征提取效率。
- 改进的数据增强策略:提升模型鲁棒性和泛化能力。
- 总结: 进一步改进了头部设计和标签分配,优化了数据增强策略,性能进一步提升。
YOLOv9 (2024)
- 可编程梯度信息 (PGI):控制梯度信息在网络中的流动,避免信息丢失。
- 广义高效层聚合网络 (GELAN):一种高效的网络结构,在保持性能的同时减少计算量。
- 轻量化设计:注重模型大小和效率,使其更适合移动设备和嵌入式系统。
- 动态模块:根据输入数据调整网络结构,提高适应性。
- 总结: 引入 PGI 技术来有效控制梯度信息,采用了更高效的 GELAN 骨干网络,更注重轻量化。
YOLOv10 (2024)
- NMS Free:摒弃传统的非极大值抑制后处理步骤,提高推理速度。
- 端到端训练:使模型学习数据中的特征,减少人为干预。
- 新型注意力机制:在网络中更高效地捕获目标信息,提升模型精度。
- 更高效的骨干网络:在保证性能的同时,计算效率更高。
- 动态匹配策略:根据目标特征灵活匹配标签,提高学习效率。
- 总结: 摒弃 NMS 后处理,采用了新型注意力机制和动态匹配策略,注重模型的端到端训练和推理效率。
YOLOv11
根据最新的资料,YOLOv11 引入了多项改进,以提升模型的性能和效率。以下是主要的改进点:
-
C3K2 块:在网络架构中增加了 C3K2 块,旨在增强特征提取能力,提高模型的表达性能。
-
SPFF 模块:引入了 SPFF(Spatial Pyramid Feature Fusion)模块,用于多尺度特征融合,提升对不同大小目标的检测能力。
-
C2PSA 块:增加了 C2PSA(Channel-wise and Point-wise Spatial Attention)块,旨在提高模型对重要特征的关注度,提升检测精度。
-
LSKA 模块:引入了大核分离卷积注意力模块(LSKA),通过将 2D 卷积核分解为水平和垂直的 1D 卷积核,降低计算复杂度的同时,提高模型对对象形状的学习能力。
-
SE 注意力机制:集成了 SE(Squeeze-and-Excitation)模块,提升网络的表达能力,使其能够更好地区分有用和无用的特征,从而提高分类精度。
-
MHSA 模块:采用多头自注意力机制(MHSA),增强模型对全局信息的捕获能力,提高对复杂场景的适应性。
-
Re-CalibrationFPN:为了加强浅层和深层特征的交互能力,推出了重校准特征金字塔网络(Re-CalibrationFPN),通过自适应的注意力机制,提升多尺度特征融合效果。
-
轻量化设计:通过优化网络结构,减少模型参数量,使其在边缘设备上运行更加高效。
-
端到端优化:进一步实现端到端的训练和推理,减少手动设计的中间步骤,提高模型的自动化程度。
这些改进使得 YOLOv11 在保持高速检测的同时,进一步提升了精度和适应性,满足了更广泛的应用需求。
此外,您可能对以下视频感兴趣,它深入剖析了 YOLOv11 的原理和训练方法:
主要改进方向总结
1. 网络结构优化
- 骨干网络、颈部网络、头部网络持续优化,引入动态模块,提升特征提取和融合能力。
- 总结: 不断寻求更高效、更强大的网络结构,以提高模型性能。
2. 标签分配策略
- 从静态到动态,使标签分配更灵活,适应不同大小和复杂性的目标。
- 总结: 更加智能化的标签分配,提高模型训练效率和精度。
3. 损失函数设计
- 引入更适合目标检测任务的损失函数,提高模型学习效率。
- 总结: 更加合理的损失函数设计,帮助模型更好地学习目标特征。
4. 数据增强方法
- 从简单的变换到更复杂的增强方法,提高模型鲁棒性。
- 总结: 更强大的数据增强方法,提升模型的泛化能力。
5. 推理速度优化
- 从 NMS 到 NMS Free,以及模型压缩、量化等技术,提升推理速度。
- 总结: 更加注重模型的推理效率,使其更适合实际应用。
6. 梯度信息控制
- 通过 PGI 等技术控制梯度信息,避免信息损失,提高模型泛化能力。
- 总结: 更加精细的梯度控制,提升模型的学习能力。
7. 注意力机制
- 引入 ASFF、SAM 等注意力机制,更高效地捕获目标信息。
- 总结: 引入注意力机制,帮助模型更好地关注重要特征。
8. 自监督学习和多模态
- 探索自监督学习,利用未标注数据提高模型泛化能力。
- 探索多模态数据融合,提升模型鲁棒性。
- 总结: 未来的探索方向,致力于利用更多数据和信息,进一步提升模型性能。
总结
YOLO 系列的演进是不断寻求速度、精度和效率平衡的过程。每一次改进都致力于优化网络结构、标签分配、损失函数、数据增强、推理效率以及探索新的学习方法。 YOLO 系列的持续发展推动着目标检测领域的进步,不断满足着不同场景下对高性能目标检测的需求。
希望这个版本在各项改进后都加上了简单的解释,更方便理解!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









