







NeuRAD: Neural Rendering for Autonomous Driving
非常值得学习的一篇文章,几乎把自动驾驶场景下所有的优化都加上了,并且也开源了。
和Unisim做了对比,指出Unisim使用lidar指导采样的问题是lidar的垂直FOV有限,高处的东西打不到,使得lidar FOV外的效果不好。
1 整体框架
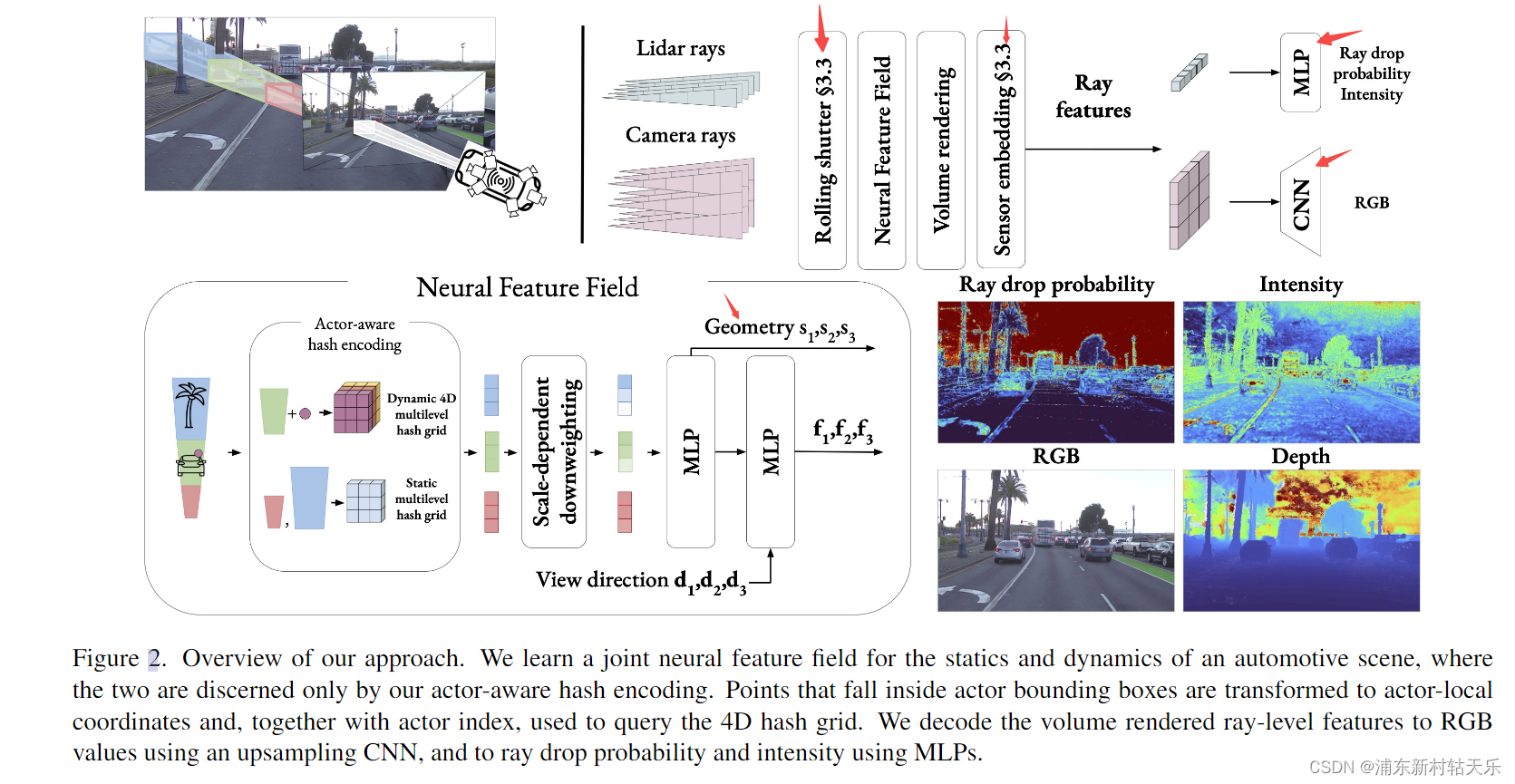
2 各项优化
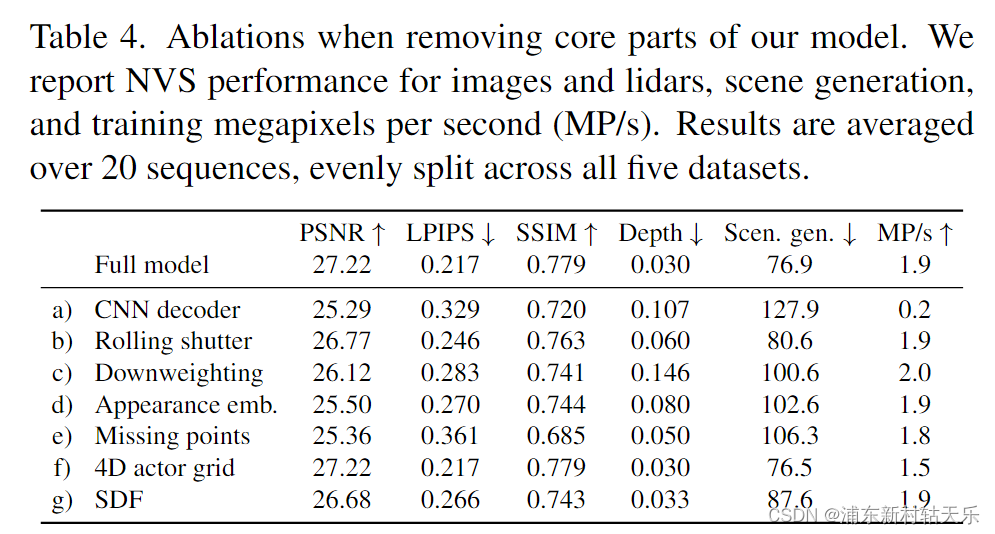
-
CNN decoder
该方法最先是Unisim中提到的,主要优点是减少计算量,另外对于外插比较好。从该图消融实验的Scen. gen.为FID,表示新视角的和原视角的相似性,可以看出确实CNN对外插的影响最大。
采样时是基于patch的采样,假设一个pacht的大小是32x32个像素,降采样是。随机采样一个像素点作为中心点,以该点为中心采样96x32个像素,渲染得到的feature,经过反卷积上采样为原来的3倍,即96x96。
推理时,先把图片大小resize为原来的1/3,渲染得到1/3大小的feature,经过反卷积得到原图。
-
Rolling shutter
这是自动驾驶场景特殊的地方。
对相机和ldiar的扫描时间建模。相机的第一行和最后一行不是一个时间,lidar也是如此。相机高速运动的时候,一幅图里的每行像素的时间是不一样的,其相机原点也不一样。但是我们建模的时候,却认为一张图片里所有的像素都是同一个时间,也就是这一帧的位姿和时间戳。
所以作者为每条射线都额外加了时间t的预测,对每条Ray加入一个t,根据ego_motion,调整它们的原点。动态元素的位姿插值到每条ray的时间。
此处可看issue,需要注意,相机扫描也分为横向和纵向。
-
Apperance embedding
最早是在NeRF in wild里提到的,因为不同相机的曝光程度不同,每个相机通过一个mlp获得一个embeding。每个sensor学习一个embedding,渲染新视角时使用这些embedding。
-
ray drop probability and intensity using
返回点云是否击中的概率,以此来丢弃这束光线,如打到天空、玻璃上的,没有返回值。
-
SDF
SDF的方法最早是在NeuS被应用。什么是SDF,sign distance field,它可以刻画一个表面。他的好处是什么?
其用法是NeRF的MLP原本是预测每个点的density的,现在不直接预测density了,而是预测一个该点的sdf,然后通过一个计算公式转换成不透明度α,这里的β就是预测的该点的SDF值,初始值设成20,它是一个可学习的参数。
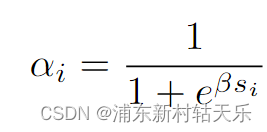
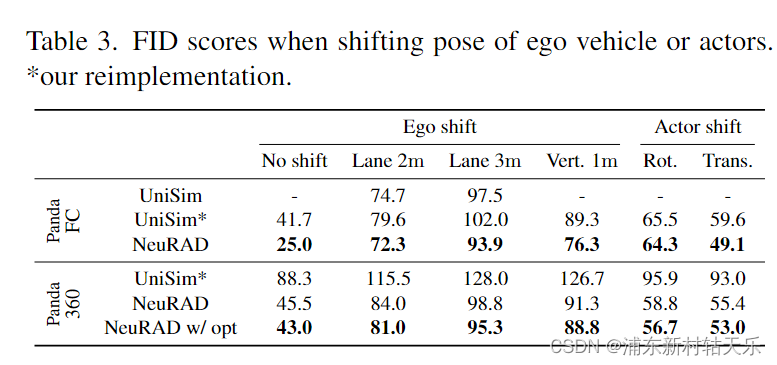
3 对比Unisim新视角下的效果
使用FID作为量化指标
4 其他
- 采样分为三种,背景、Acotr和天空。
在静态场末端和3公里外之间的视差(到传感器原点的距离上的一个)中对这些进行线性采样。也就是说原本每条射线采样32个点,最后一个点(也是最远的一个点)扩展到3000m,实际代码中这个距离是20000m
- 位姿优化:
加了位姿优化后psnr等值变低,这是因为位姿优化后位姿发生了变化,和ground truth的pose已经不一样,但是还要跟ground truth的图像做对比。本来就不是一个时刻的图片了,也就自然没有了可比性。
- 挑战性的场景:
- 夜晚。夜晚产生炫光,这些本不代表真正的geometroy。
- 刹车灯,信号灯,这些是随时间变化的,Nerf可能可以学习出这个关联关系。















 3623
3623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









