







Python 机器学习 基础 之 监督学习 【分类器的不确定度估计】 的简单说明
目录
Python 机器学习 基础 之 监督学习 【分类器的不确定度估计】 的简单说明
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
二、监督学习 算法 说明前的 数据集 说明
相关说明可见如下链接的 < 二、监督学习 算法 说明前的 数据集 说明 >,这里不在赘述:
数据集 说明:Python 机器学习 基础 之 监督学习 K-NN (K-邻近)算法 的简单说明
三、监督学习 之 分类器的不确定度估计
我们还没有谈到 scikit-learn 接口的另一个有用之处,就是分类器能够给出预测的不确定度估计。一般来说,你感兴趣的不仅是分类器会预测一个测试点属于哪个类别,还包括它对这个预测的置信程度。在实践中,不同类型的错误会在现实应用中导致非常不同的结果。想象一个用于测试癌症的医疗应用。假阳性预测可能只会让患者接受额外的测试,但假阴性预测却可能导致重病没有得到治疗。
在监督学习中,分类器的不确定度估计是指分类器对于自己的预测有多大程度的不确定性。这在实际应用中非常重要,因为它可以帮助我们更好地理解模型的预测能力,提高模型在决策边界附近的可靠性,并且有助于对模型的性能进行评估。
以下是一些常见的分类器不确定度估计方法:
置信度评分(Confidence Score):对于概率分类器(如逻辑回归、朴素贝叶斯、支持向量机的概率版本等),可以使用预测概率的最大值或其他置信度评分来表示分类器对于每个类别的预测置信度。通常情况下,较高的置信度表示模型对于预测的准确性更有信心。
不确定度估计器(Uncertainty Estimation):一些分类器提供了内置的不确定度估计器,例如随机森林的 Out-of-Bag 估计、支持向量机的决策函数距离、基于置信度的 K 最近邻分类器等。这些估计器可以用来度量模型对于每个样本的不确定性,例如基于样本与决策边界的距离或在集成中的不一致性。
交叉验证(Cross-Validation):通过交叉验证技术,可以对模型在不同数据集上的稳定性进行评估,从而间接地了解模型的不确定性。例如,在 k 折交叉验证中,我们可以观察模型在不同折上的表现差异,以及在整个数据集上的平均性能,从而推断模型的不确定度。
包外估计(Out-of-Bag Estimation):对于基于决策树的集成方法(如随机森林),可以使用包外估计方法来评估模型的性能和不确定性。在构建每棵决策树时,有部分样本没有被用于训练,这些未被使用的样本可以用于评估模型的泛化性能和不确定度。
Bootstrap 方法:通过重复采样原始数据集来构建多个训练数据集,并在每个训练数据集上训练模型,然后利用这些模型的预测结果的方差或置信区间来估计分类器的不确定性。
这些方法可以帮助我们更好地理解分类器的预测不确定性,从而提高模型的可解释性和可靠性。
scikit-learn 中有两个函数可用于获取分类器的不确定度估计:decision_function 和 predict_proba 。大多数分类器(但不是全部)都至少有其中一个函数,很多分类器两个都有。我们来构建一个 GradientBoostingClassifier 分类器(同时拥有 decision_function 和 predict_proba 两个方法),看一下这两个函数对一个模拟的二维数据集的作用:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import make_circles
import numpy as np
from sklearn.model_selection import train_test_split
X, y = make_circles(noise=0.25, factor=0.5, random_state=1)
# 为了便于说明,我们将两个类别重命名为"blue"和"red"
y_named = np.array(["blue", "red"])[y]
# 我们可以对任意个数组调用train_test_split
# 所有数组的划分方式都是一致的
X_train, X_test, y_train_named, y_test_named, y_train, y_test = \
train_test_split(X, y_named, y, random_state=0)
# 构建梯度提升模型
gbrt = GradientBoostingClassifier(random_state=0)
gbrt.fit(X_train, y_train_named)
1、决策函数
对于二分类的情况,decision_function 返回值的形状是 (n_samples,) ,为每个样本都返回一个浮点数:
print("X_test.shape: {}".format(X_test.shape))
print("Decision function shape: {}".format(
gbrt.decision_function(X_test).shape))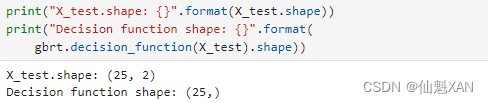
对于类别 1 来说,这个值表示模型对该数据点属于“正”类的置信程度。正值表示对正类的偏好,负值表示对“反类”(其他类)的偏好:
# 显示decision_function的前几个元素
print("Decision function:\n{}".format(gbrt.decision_function(X_test)[:6]))
我们可以通过仅查看决策函数的正负号来再现预测值:
print("Thresholded decision function:\n{}".format(
gbrt.decision_function(X_test) > 0))
print("Predictions:\n{}".format(gbrt.predict(X_test)))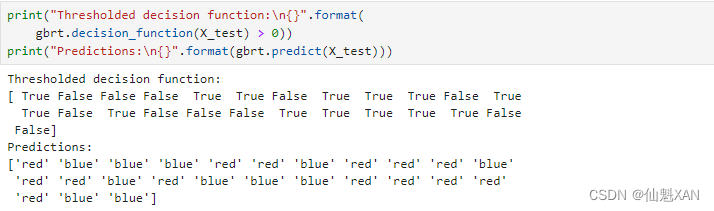
对于二分类问题,“反”类始终是 classes_ 属性的第一个元素,“正”类是 classes_ 的第二个元素。因此,如果你想要完全再现 predict 的输出,需要利用 classes_ 属性:
# 将布尔值True/False转换成0和1
greater_zero = (gbrt.decision_function(X_test) > 0).astype(int)
# 利用0和1作为classes_的索引
pred = gbrt.classes_[greater_zero]
# pred与gbrt.predict的输出完全相同
print("pred is equal to predictions: {}".format(
np.all(pred == gbrt.predict(X_test))))

decision_function 可以在任意范围取值,这取决于数据与模型参数:
decision_function = gbrt.decision_function(X_test)
print("Decision function minimum: {:.2f} maximum: {:.2f}".format(
np.min(decision_function), np.max(decision_function))) 
由于可以任意缩放,因此 decision_function 的输出往往很难解释。
在下面的例子中,我们利用颜色编码在二维平面中画出所有点的 decision_function ,还有决策边界,后者我们之间见过。我们将训练点画成圆,将测试数据画成三角(如下图):
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
mglearn.tools.plot_2d_separator(gbrt, X, ax=axes[0], alpha=.4,
fill=True, cm=mglearn.cm2)
scores_image = mglearn.tools.plot_2d_scores(gbrt, X, ax=axes[1],
alpha=.4, cm=mglearn.ReBl)
for ax in axes:
# 画出训练点和测试点
mglearn.discrete_scatter(X_test[:, 0], X_test[:, 1], y_test,
markers='^', ax=ax)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train,
markers='o', ax=ax)
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
cbar = plt.colorbar(scores_image, ax=axes.tolist())
axes[0].legend(["Test class 0", "Test class 1", "Train class 0",
"Train class 1"], ncol=4, loc=(.1, 1.1))
plt.savefig('Images/08UncertaintyEstimationForClassifier-01.png', bbox_inches='tight')
plt.show()
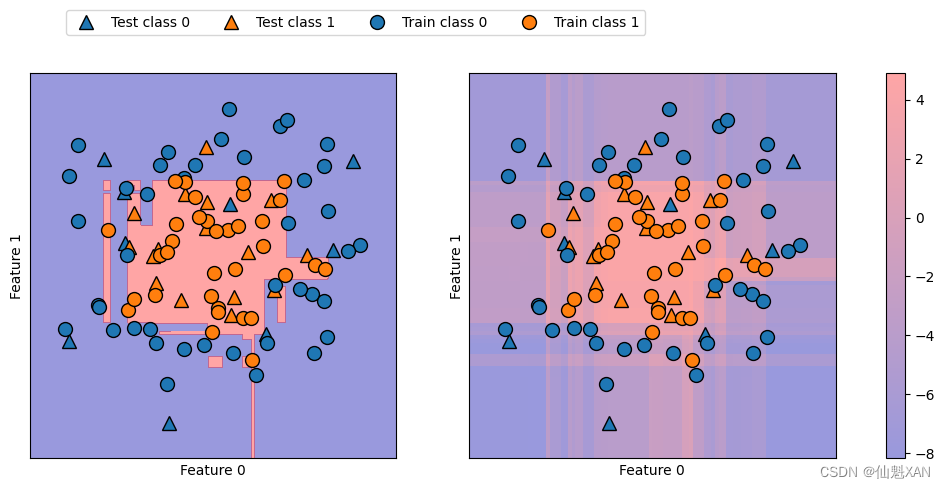
既给出预测结果,又给出分类器的置信程度,这样给出的信息量更大。但在上面的图像中,很难分辨出两个类别之间的边界。
2、预测概率
predict_proba 的输出是每个类别的概率,通常比 decision_function 的输出更容易理解。对于二分类问题,它的形状始终是 (n_samples, 2) :
print("Shape of probabilities: {}".format(gbrt.predict_proba(X_test).shape))
每行的第一个元素是第一个类别的估计概率,第二个元素是第二个类别的估计概率。由于 predict_proba 的输出是一个概率,因此总是在 0 和 1 之间,两个类别的元素之和始终为 1:
# 显示predict_proba的前几个元素
print("Predicted probabilities:\n{}".format(
gbrt.predict_proba(X_test[:6])))
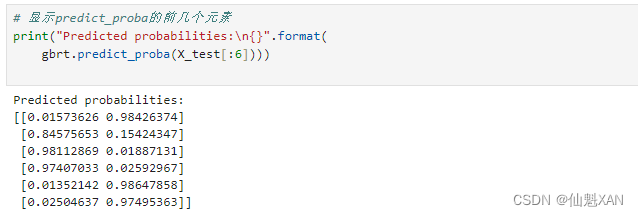
由于两个类别的概率之和为 1,因此只有一个类别的概率超过 50%。这个类别就是模型的预测结果。
在上一个输出中可以看到,分类器对大部分点的置信程度都是相对较高的。不确定度大小实际上反映了数据依赖于模型和参数的不确定度。过拟合更强的模型可能会做出置信程度更高的预测,即使可能是错的。复杂度越低的模型通常对预测的不确定度越大。如果模型给出的不确定度符合实际情况,那么这个模型被称为校正 (calibrated)模型。在校正模型中,如果预测有 70% 的确定度,那么它在 70% 的情况下正确。
在下面的例子中(下图),我们再次给出该数据集的决策边界,以及类别 1 的类别概率:
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
mglearn.tools.plot_2d_separator(
gbrt, X, ax=axes[0], alpha=.4, fill=True, cm=mglearn.cm2)
scores_image = mglearn.tools.plot_2d_scores(
gbrt, X, ax=axes[1], alpha=.5, cm=mglearn.ReBl, function='predict_proba')
for ax in axes:
# 画出训练点和测试点
mglearn.discrete_scatter(X_test[:, 0], X_test[:, 1], y_test,
markers='^', ax=ax)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train,
markers='o', ax=ax)
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
cbar = plt.colorbar(scores_image, ax=axes.tolist())
axes[0].legend(["Test class 0", "Test class 1", "Train class 0",
"Train class 1"], ncol=4, loc=(.1, 1.1))
plt.savefig('Images/08UncertaintyEstimationForClassifier-02.png', bbox_inches='tight')
plt.show()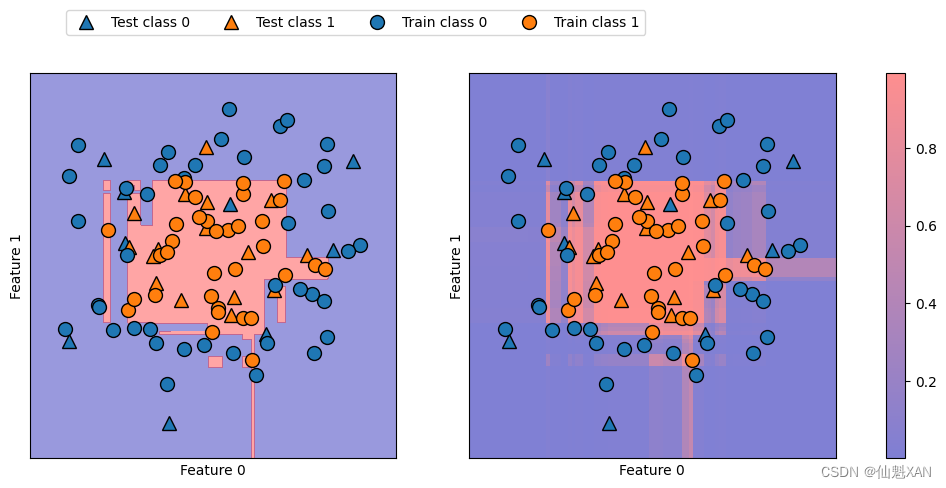
上图中的边界更加明确,不确定的小块区域清晰可见。
scikit-learn 网站(Classifier comparison — scikit-learn 1.4.2 documentation )给出了许多模型的对比,以及不确定度估计的形状。我们在下图中复制了这一结果,我们也建议你去网站查看那些示例。
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_circles, make_classification, make_moons
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
names = [
"Nearest Neighbors",
"Linear SVM",
"RBF SVM",
"Gaussian Process",
"Decision Tree",
"Random Forest",
"Neural Net",
"AdaBoost",
"Naive Bayes",
"QDA",
]
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="linear", C=0.025, random_state=42),
SVC(gamma=2, C=1, random_state=42),
GaussianProcessClassifier(1.0 * RBF(1.0), random_state=42),
DecisionTreeClassifier(max_depth=5, random_state=42),
RandomForestClassifier(
max_depth=5, n_estimators=10, max_features=1, random_state=42
),
MLPClassifier(alpha=1, max_iter=1000, random_state=42),
AdaBoostClassifier(algorithm="SAMME", random_state=42),
GaussianNB(),
QuadraticDiscriminantAnalysis(),
]
X, y = make_classification(
n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1
)
rng = np.random.RandomState(2)
X += 2 * rng.uniform(size=X.shape)
linearly_separable = (X, y)
datasets = [
make_moons(noise=0.3, random_state=0),
make_circles(noise=0.2, factor=0.5, random_state=1),
linearly_separable,
]
figure = plt.figure(figsize=(27, 9))
i = 1
# iterate over datasets
for ds_cnt, ds in enumerate(datasets):
# preprocess dataset, split into training and test part
X, y = ds
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=42
)
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
# just plot the dataset first
cm = plt.cm.RdBu
cm_bright = ListedColormap(["#FF0000", "#0000FF"])
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
if ds_cnt == 0:
ax.set_title("Input data")
# Plot the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k")
# Plot the testing points
ax.scatter(
X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6, edgecolors="k"
)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_xticks(())
ax.set_yticks(())
i += 1
# iterate over classifiers
for name, clf in zip(names, classifiers):
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
clf = make_pipeline(StandardScaler(), clf)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
DecisionBoundaryDisplay.from_estimator(
clf, X, cmap=cm, alpha=0.8, ax=ax, eps=0.5
)
# Plot the training points
ax.scatter(
X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k"
)
# Plot the testing points
ax.scatter(
X_test[:, 0],
X_test[:, 1],
c=y_test,
cmap=cm_bright,
edgecolors="k",
alpha=0.6,
)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_xticks(())
ax.set_yticks(())
if ds_cnt == 0:
ax.set_title(name)
ax.text(
x_max - 0.3,
y_min + 0.3,
("%.2f" % score).lstrip("0"),
size=15,
horizontalalignment="right",
)
i += 1
plt.tight_layout()
plt.savefig('Images/08UncertaintyEstimationForClassifier-03.png', bbox_inches='tight')
plt.show()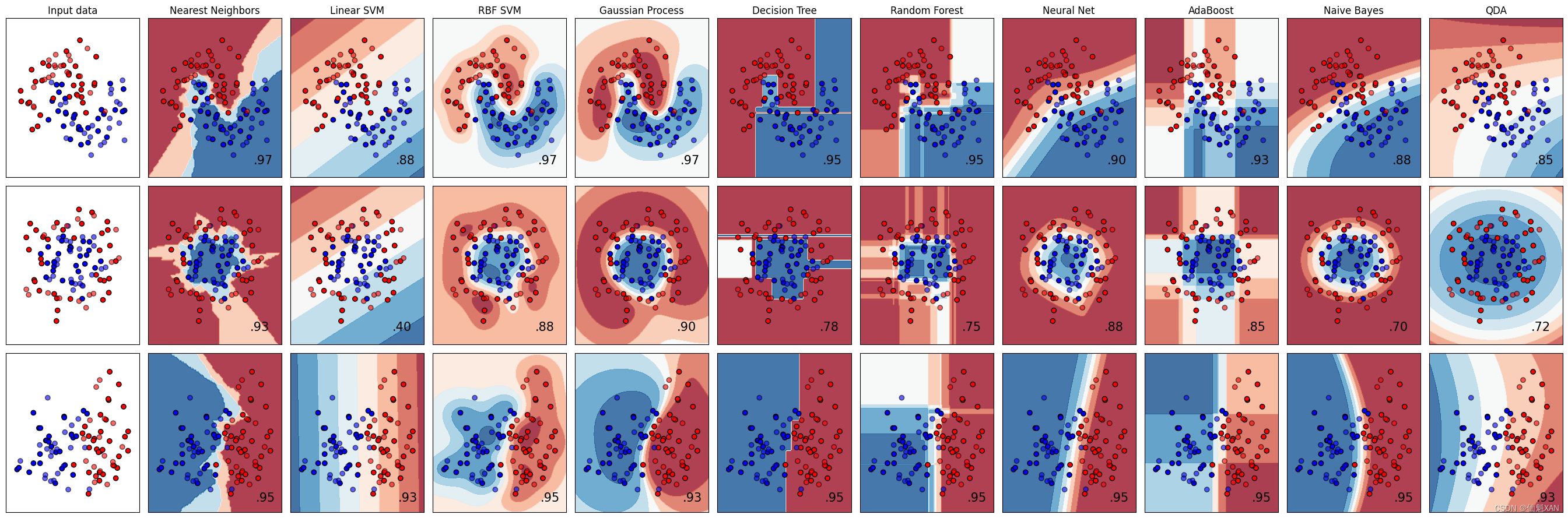
3、多分类问题的不确定度
到目前为止,我们只讨论了二分类问题中的不确定度估计。但 decision_function 和 predict_proba 也适用于多分类问题。我们将这两个函数应用于鸢尾花(Iris)数据集,这是一个三分类数据集:
from sklearn.datasets import load_iris
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, random_state=42)
gbrt = GradientBoostingClassifier(learning_rate=0.01, random_state=0)
gbrt.fit(X_train, y_train)print("Decision function shape: {}".format(gbrt.decision_function(X_test).shape))
# 显示决策函数的前几个元素
print("Decision function:\n{}".format(gbrt.decision_function(X_test)[:6, :]))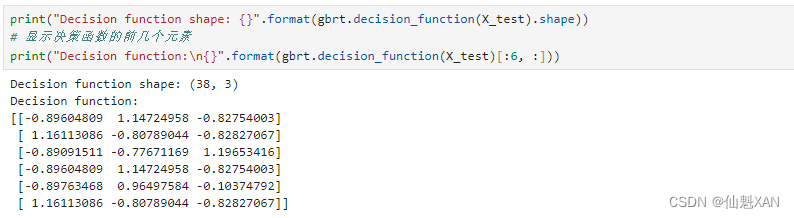
对于多分类的情况,decision_function 的形状为 (n_samples, n_classes) ,每一列对应每个类别的“确定度分数”,分数较高的类别可能性更大,得分较低的类别可能性较小。你可以找出每个数据点的最大元素,从而利用这些分数再现预测结果:
print("Argmax of decision function:\n{}".format(
np.argmax(gbrt.decision_function(X_test), axis=1)))
print("Predictions:\n{}".format(gbrt.predict(X_test)))
predict_proba 输出的形状相同,也是 (n_samples, n_classes) 。同样,每个数据点所有可能类别的概率之和为 1:
# 显示predict_proba的前几个元素
print("Predicted probabilities:\n{}".format(gbrt.predict_proba(X_test)[:6]))
# 显示每行的和都是1
print("Sums: {}".format(gbrt.predict_proba(X_test)[:6].sum(axis=1)))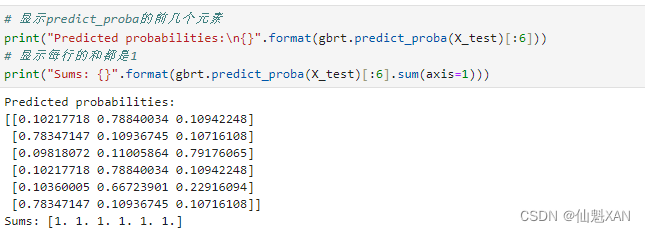
同样,我们可以通过计算 predict_proba 的 argmax 来再现预测结果:
print("Argmax of predicted probabilities:\n{}".format(
np.argmax(gbrt.predict_proba(X_test), axis=1)))
print("Predictions:\n{}".format(gbrt.predict(X_test)))
总之,predict_proba 和 decision_function 的形状始终相同,都是 (n_samples, n_classes) ——除了二分类特殊情况下的 decision_function 。对于二分类的情况,decision_function 只有一列,对应“正”类 classes_[1] 。这主要是由于历史原因。
如果有 n_classes 列,你可以通过计算每一列的 argmax 来再现预测结果。但如果类别是字符串,或者是整数,但不是从 0 开始的连续整数的话,一定要小心。如果你想要对比 predict 的结果与 decision_function 或 predict_proba 的结果,一定要用分类器的 classes_ 属性来获取真实的属性名称:
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
# 用Iris数据集的类别名称来表示每一个目标值
named_target = iris.target_names[y_train]
logreg.fit(X_train, named_target)
print("unique classes in training data: {}".format(logreg.classes_))
print("predictions: {}".format(logreg.predict(X_test)[:10]))
argmax_dec_func = np.argmax(logreg.decision_function(X_test), axis=1)
print("argmax of decision function: {}".format(argmax_dec_func[:10]))
print("argmax combined with classes_: {}".format(
logreg.classes_[argmax_dec_func][:10]))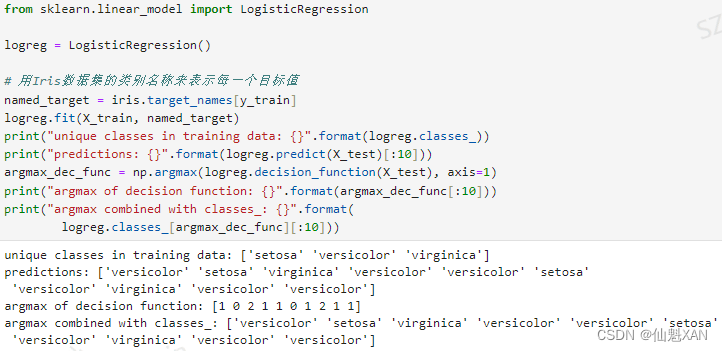
附录
一、参考文献
参考文献:[德] Andreas C. Müller [美] Sarah Guido 《Python Machine Learning Basics Tutorial》















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











