








11月25日,媒体报道,特斯拉已开始向员工推出全自动驾驶(FSD)V12版本,更新版本号为 2023.38.10。很快,特斯拉CEO马斯克也在X上确认了这一消息。
本月早些时候,马斯克宣布特斯拉FSD V12自动驾驶将在2周内上线试用,但市场普遍对这一时间点表示怀疑。
现在看来,FSD V12版本正步入面向客户前的最后一步,或许能够在今年问世。

99%决策由神经网络给出
为何大家会如此期待特斯拉的FSD V12?
最为重要的原因便是,特斯拉反复强调的,FSD V12将实现全新的“端到端自动驾驶”,第一次开始使用神经网络进行车辆控制,包括控制转向、加速和制动,不再需要此前超过30万行的代码,而是进一步依赖神经网络,减少了对硬编码编程的依赖。
马斯克在此前的试驾直播中表示,FSD Beta V12是有史以来第一个端到端AI自动驾驶系统(Full AI End-to-End),从头到尾都是通过AI实现。我们没有编程,没有程序员写一行代码来识别道路、行人等概念,全部交给了神经网络自己思考。V12的C++代码只有2000行,而V11有30万行。
简单理解就是,V12把摄像头获取的图像数据输入到神经网络,网络能够直接输出车辆控制指令(如转向、加速、制动等),更像是一个人类的大脑,99%的决策都是由神经网络给出的,不需要高精地图、不需要激光雷达,仅仅依靠车身的摄像头视觉输入,就能分析思考,输出控制策略。
媒体分析认为,FSD V12版本的推出将成为特斯拉在AI和自动驾驶方面的关键时刻。这不仅仅是技术实力,还关乎将AI与人类行为如何更好融合。
对于新架构的技术细节和潜在影响,市场仍有较多疑惑和分歧。
根据特斯拉对外披露的信息及马斯克在X上发布的信息,中信证券认为,特斯拉内部目前有两条“端到端”路线同步在研:
1)级联式端到端神经网络;
2)World Model
而FSD V12是前者的可能性较大,有望于明年初落地,以更好地实现L3能力。

“端到端自动驾驶”有何不同?
在FSD V12之前,特斯拉的自动驾驶系统一直依赖于规则判断。
靠着汽车的摄像头识别车道、行人、车辆、标志和交通信号灯等,然后通过特斯拉工程师们手动编写的数十万行C++代码来应对各种情况,比如红灯停、绿灯行、在没有足够快的车辆冲撞时才通过十字路口等等。
但现在,作为特斯拉自动驾驶系统最重要的一次升级,FSD v12只是通过给神经网络“喂”视频,让它不断学习,优化参数,在分析数十亿帧人类如何驾驶汽车的视频自学了驾驶。
中信证券指出,从技术本质来看,级联式端到端神经网络,系统从输入到输出,全程使用神经网络算法,无需任何人工规则介入。当前,自动驾驶模型多为模块化架构,感知预测、规划、控制等不同任务分属于多个不同的小模型,且下游规控环节普遍仍以规则为主。
而“端到端”神经网络在输入图像后,可直接输出转向、刹车、加速等控制指令。为提升训练效果,“端到端”的大神经网络可能由多个小的子神经网络级联而成。
但与传统模块化架构用“规则”连接模块不同,级联式神经网络的子模块是以“神经网络”的方式自行训练堆叠,因此可通过数据驱动优化整个端到端模型,避免“局部最优,而非全局最优”的困境。
端到端/神经网络的核心好处在于模型迭代的关键由“工程师”变为了更易于规模化的“数据和算力”,因而训练效率和性能上限有望得到显著提升。落到实处,中信证券认为,端到端方案所展示出的性能潜力有望大幅提升自动驾驶系统的接管水平,从而实现真正无可争议的L3能力(例如达到每周接管1次)。
但端到端模型的“黑盒”问题目前产业界尚未有十分成熟的解决方案,因此中信证券认为,其最终能否迈向追求极致安全性的L4全无人驾驶仍待观望。
深度剖析特斯拉自动驾驶技术:从模块化深度学习过渡至端到端深度学习的全过程 - 知乎 (zhihu.com)
端到端深度学习意味着什么?它需要对架构做出哪些“改变”?
如果我们用谷歌搜索“端到端学习的定义”,得到的结果是这样的:“端对端学习是指通过对整个系统进行基于梯度的学习来训练一个可能很复杂的学习系统。端到端学习系统经过专门设计,所有模块都是可微分的”。
简而言之,特斯拉有两件事要做:
●每个模块都使用深度神经网络;
●将这些神经网络组装在一起的端到端模型。
目前,特斯拉的自动驾驶系统架构中部分模块已经被深度学习模块所替代,但仍不是一个端到端训练模式的自动驾驶系统,相比而言,主要差异如下:
●感知模块使用深度学习 ----满足条件;
●规划模块使用深度学习模型+传统树形搜索的组合----不满足条件。
这就是他们需要将「规划」部分转变为「深度学习」部分。他们必须去掉轨迹评分、手动规则、“如果你在停车标志前,请等待 3 秒”的代码,以及“如果你看到红灯,请减速并停车”的代码:
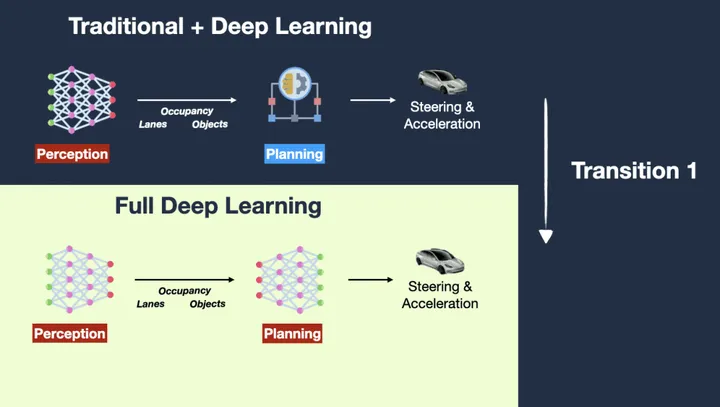
▲图13|全深度学习的规划模块 ©️【深蓝AI】原创
然而,这还不够,因为即使我们有 2 个深度学习模块(目标识别A模块和轨迹预测B模块),但仍然需要端到端的训练流程。在非端到端的深度学习系统中:
●在数据集上独立训练 A 模块,来识别物体;
●然后,使用目标识别模块 A 的输出特征对轨迹预测模块 B 进行独立训练,来预测目标轨迹。
其中关键点在于,训练过程中,A 模块对 B 模块的目标轨迹一无所知,而 B 模块也不知道 A 模块所要识别的目标。他们是两个独立的个体,各自接受训练,他们各自的训练损失函数并没有得到共同优化,也就不是从头到尾的端到端训练流程。
现在,我们来考虑一个端到端训练流程,其中包含上述场景相同的目标识别模块 A 和轨迹预测模块 B:
●用一个单一的目标函数,既要考虑识别图像中的物体(A 模块的任务),又要考虑预测轨迹(B 模块的任务);
●需要同时训练 A 模块和 B 模块,以最小化这种联合损失函数。
其中要点为,信息(以及反向传播过程中的梯度)从最终输出一直流回初始输入。模块 A 的学习直接受模块 B 完成任务情况的影响,反之亦然。它们是为了一个统一的目标而共同优化的。
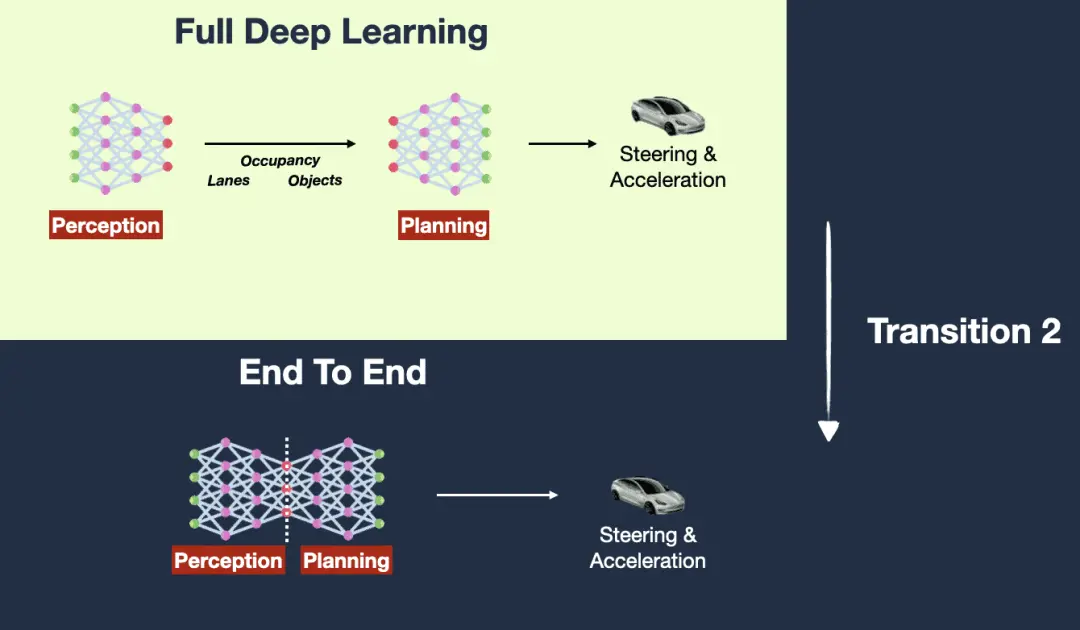
▲图14|从全深度学习过渡到端到端 ©️【深蓝AI】原创
因此,主要区别不在于模块本身,而在于如何对其进行训练和优化。在端到端系统中,模块被联合优化,以实现单一的总体目标。而在非端到端系统中,每个模块都是单独优化的,不考虑更大的系统目标。

目前为止,特斯拉采用的是模块化自动驾驶方法,其中有两个主要模块可以相互通信: 感知与规划。2021 年,他们推出了 HydraNet,这是一种多任务学习架构,能够同时解决多项感知任务。他们还宣布其规划系统是蒙特卡洛树搜索和神经网络的组合。2022 年,他们又增加了一个「占据网络」,有助于更好地理解3D空间。
HydraNet 还扩展了车道线检测功能。要从目前的系统过渡到端到端系统,他们需要将 Planner 转变为深度学习系统,并且使用联合损失函数对其进行训练。该系统看起来像一个黑盒子,但实际上是现有模块的组装,也就是说他们不会丢弃已经构建的所有模块,只是将它们粘合在一起。©️【深蓝AI】原创
引用参考:
[1] https://twitter.com/i/broadcasts/1djxXlVLaLOxZ
[2] https://www.thinkautonomous.ai/blog/occupancy-networks/
[3] https://www.thinkautonomous.ai/blog/how-tesla-autopilot-works/
[4] https://www.youtube.com/watch?v=j0z4FweCy4M&t=4897s
[5] https://www.youtube.com/watch?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









