









nuScenes数据集使用
(一)官方提供的开发者工具:
pip install nuscenes-devkit
使用nuscenes-devkit需要使用的文件结构:
/data/sets/nuscenes
samples - Sensor data for keyframes.
sweeps - Sensor data for intermediate frames.
maps - Folder for all map files: rasterized .png images and vectorized .json files.
v1.0-* - JSON tables that include all the meta data and annotations. Each split (trainval, test, mini) is provided in a separate folder.
如果使用自己的文件结构,需要修改源码/Users/wennie/anaconda3/lib/python3.6/site-packages/nuscenes。
(二)下载数据集的结构:
2020年10月5日补充

- Metadata包含v1.0-trainval文件夹,该文件夹中包含所有850个场景的配置文件
- 所有的图像和点云数据被分成十个部分。每个File blobs包含samples和sweeps两个文件夹,samples表示各传感器时间轴对应时的数据,sweeps表示其他剩余数据。samples和sweeps两个文件夹下,各有12个文件夹,分别为6路摄像头数据,1路激光雷达数据,5路毫米波雷达数据。
- 实际使用时,可以只下载keyframe数据,此时仅包括samples数据。因为实际训练预测,基本上都是基于samples内的数据。
- 也可只下载某一传感器数据,例如只下载Lidar blobs,此时下载内容也包括samples和sweeps两个文件夹,但这两个文件夹下只包含激光雷达数据。
- Radar blobs和Camera blobs同上一条同理。
(三)部分功能:
主要参考官方的应用示例
一、 结合各表,获取信息
# 参数1:各个表名
# 参数2:token
nusc.get('sample', first_sample_token)
举例:sample
data中根据各传感器token,可以得到传感器文件的存放位置。
anns表示该sample中存在的所有Ground Truth,其token可以得到物体的标注信息。

举例:sample_data

举例:sample_annotation

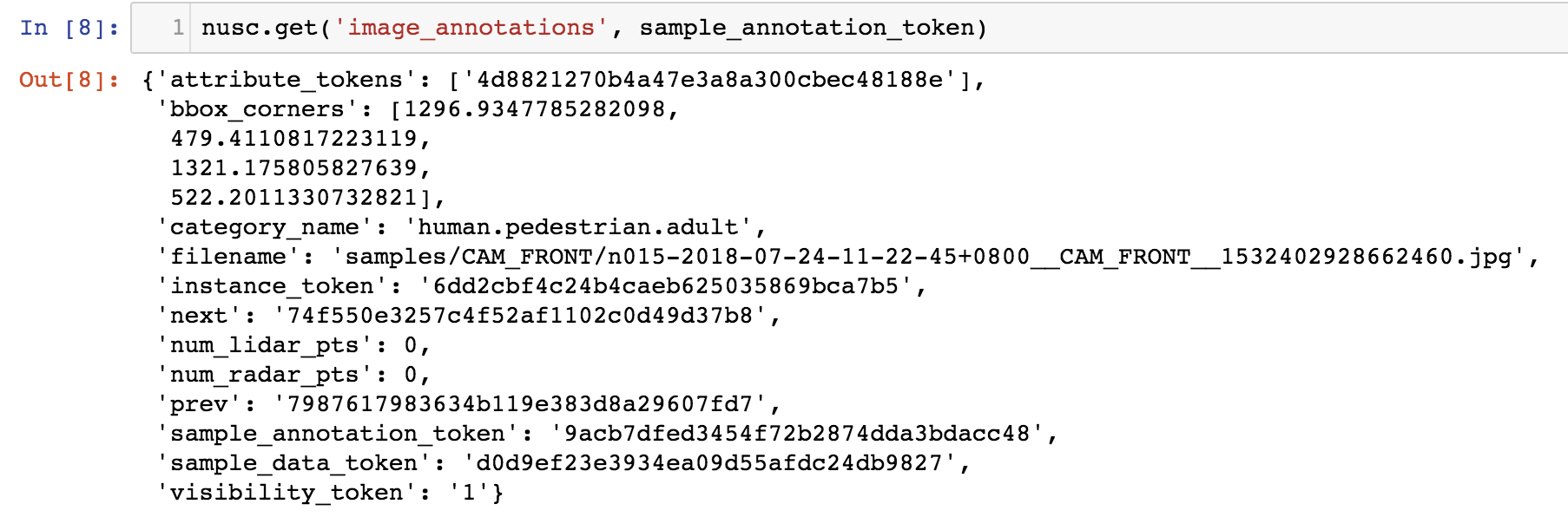
拓展:读取image_annotations
image_annotations 文件获得方法:
跑一下/nuscenes/scripts/export_2d_annotations_as_json.py,即可获得。
源码接口不支持使用nusc.get('image_annotation', sample_annotation_token)。需要稍微修改一下源码 /anaconda3/lib/python3.6/site-packages/nuscenes/nuscenes.py,即可获得:
二、 各坐标系间的转换
(1)转换Ground Truth坐标,使其与像素坐标系一致
- 转换为像素坐标系下的二维坐标,即image_annotations.json里的值
- 转换为像素坐标系下的三维坐标:
render_sample_data函数中有具体实现步骤。

(2)转换Ground Truth坐标,使其与雷达坐标系一致
- 得到一个三维的box坐标
# Returns the data path as well as all annotations related to that sample_data.
# Note that the boxes are transformed into the current sensor's coordinate frame.
_, boxes, _ = nusc.get_sample_data(sensor_token)
- 都映射到二维后,查看Ground Truth(即图中的框)与点云:


(3)转换点云坐标,使其与像素坐标系一致
- 得到坐标
已经筛去超出图像大小1600*900的点。
# 需使用NuScenesExplorer类方法
from nuscenes.nuscenes import NuScenesExplorer
nusc_exp = NuScenesExplorer(nusc)
nusc_exp.map_pointcloud_to_image(my_sample['data']['RADAR_FRONT'],my_sample['data']['CAM_FRONT'])
- 查看图像

三、毫米波雷达点云数据
源码在nuscenes/utils/data_classes.py RadarPointCloud类中
point_sensor = nusc.get('sample_data', sensor_token)
pcl_path = osp.join(DATAROOT, point_sensor['filename'])
pc = RadarPointCloud.from_file(pcl_path)
pc.points
内容:
# FIELDS x y z dyn_prop id rcs vx vy vx_comp vy_comp is_quality_valid ambig_state x_rms y_rms invalid_state pdh0 vx_rms vy_rms
# Below some of the fields are explained in more detail:
# x is front, y is left
# vx, vy are the velocities in m/s.
# vx_comp, vy_comp are the velocities in m/s compensated by the ego motion.
# We recommend using the compensated velocities.















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









