









OpenCL 通用编程与优化(20)
10.3 Epsilon 过滤器
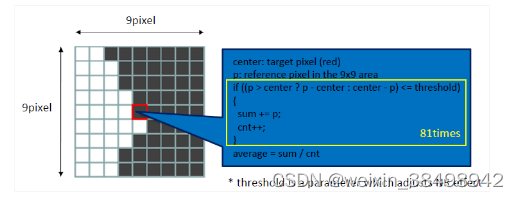
Epsilon滤波器在图像处理中广泛使用,以减少mosquito噪声,这是一种在高频区域(例如图像中边缘)发生的一种损伤。这个滤波器本质上是一个支持空间变化的非线性逐点低通滤波器,只过滤具有一定阈值的像素。
在此实现中,Epsilon 过滤器仅应用于 YUV 图像的强度 (Y) 分量,因为噪声主要是可见的。此外,它假设 Y 分量是连续存储的(NV12 格式),与 UV 分量分开。有两个基本步骤,如图 10-1 所示。
- 给定一个要过滤的像素,请计算中央像素和其相邻9x9区域中每个像素之间的绝对差值。
- 如果绝对差值低于阈值,则使用相邻像素值进行平均。阈值通常是应用程序中预定义的常数。
10.3.1 初步实施
此应用程序针对分辨率为 3264x2448(宽度 = 3264,高度 =2448)且每像素 8 位的 YUV 图像。此处报告的性能数据来自性能模式下的骁龙 810(MSM8994、Adreno 430)。
这是最初的实施参数和策略:
- 使用 OpenCL 图像对象而不是缓冲区。
- 在缓冲区上使用图像可以避免一些边界检查并利用 Adreno GPU 中的 L1 缓存。
- 使用 CL_R|CL_UNORM_INT8 图像格式/数据类型。
- 单个通道仅适用于y组件,并且通过Adreno GPU中的内置纹理管将读入SP的像素读为[0,1]。
- 每个工作项产生一个输出像素。
- 使用2D内核和全球工作规模设置为[3264,2448]。
在实现中,每个工作项必须访问 81 个浮点像素。 Adreno A430 GPU 的性能被用作进一步优化的基线。
10.3.2 数据包优化
通过比较计算和数据负载的量,很容易得出结论,这是一种内存的用例。因此,领先的优化应该是如何提高数据负荷效率。
首先要注意的是,使用 32 位浮点数(fp32)来表示像素值是一种内存浪费。对于许多图像处理算法,8 位或 16 位数据类型就足够了。由于 Adreno GPU 具有对 16 位浮点数据类型(即 half 或 fp16)的本机硬件支持,因此可以应用以下优化选项:
- 使用 16 位半数据类型而不是 32 位浮点数。
- 每个工作项现在访问 81 个半数据。
- 使用 CL_RGBA|CL_UNORM_INT8 图像格式/数据类型。
- 使用 CL_RGBA 加载四个通道以更好地利用 TP 带宽。
- 将 read_imagef 替换为 read_imageh。 TP 自动将数据转换为 16 位半。
- 每个工作项:
- 每行读取三个 half4 向量。
- 输出一个处理过的像素。
- 每个输出像素的内存访问次数:3x9=27(half4)。
- 性能提升:1.4 倍。
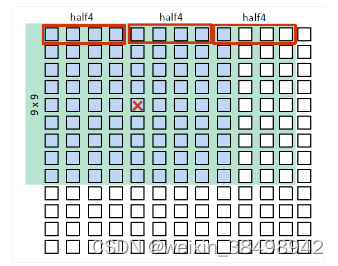
10.3.3 矢量化加载/存储优化
在上一步中,仅输出一个像素,并加载了许多相邻像素。加载一些额外的像素后,可以按如下方式过滤更多像素:
- 每个工作项。
- 每行读取三个 half4 向量。
- 输出四个像素。
- 每个输出像素的内存访问次数:3x9/4 = 6.75 (half4)。
- 全局工作尺寸:(宽度/4)x 高度。
- 为每一行循环展开。
- 在每一行内部,使用滑动窗口方法。
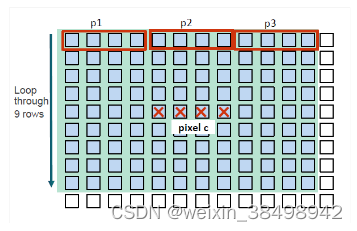
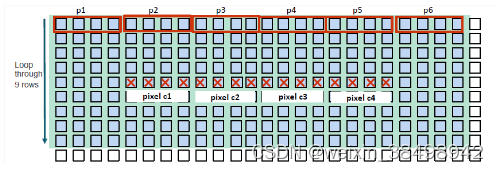
图10-3说明了如何处理多个像素的多个像素的基本图。这是步骤:
Read center pixel c;
For row = 1 to 9, do:
read data p1;
Perform 1 computation with pixel c;
read data p2;
Perform 4 computations with pixel c;
read data p3;
Perform 4 computations with pixel c;
end for
write results back to pixel c.
在这一步之后,性能比基线提高了 3.4 倍。
10.3.4 进一步增加每个工作项的工作量
通过增加每个工作项目的工作量,人们可能会期望提高性能。这是选项:
- 再读取一个 half4 向量并将输出像素数增加到 8。
- 全局工作尺寸:宽度/8 x 高度。
- 每个工作项。
- 每行读取四个 half4 向量。
- 输出八个像素。
- 每个输出像素的内存访问数量:4x9/8 = 4.5(Half4)。
- 每个输出像素的内存访问数量:4x9/8 = 4.5(Half4)。
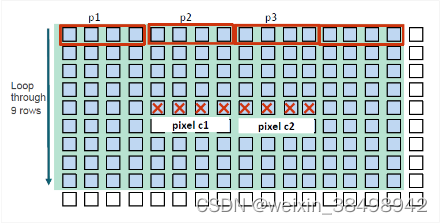
这些更改导致性能略有提高 0.1 倍。以下是它不能正常工作的原因:
- 缓存命中率变化不大,在上一步已经很优秀了。
- 需要更多的寄存器,导致更少的波,这会损害并行性和延迟的隐藏。
出于实验目的,可以按如下方式加载更多像素:
- 读取更多 half4 向量并将输出像素数增加到 16。
- 全局工作大小:宽度/16 x 高度。
图 10-5 显示每个工作项执行以下操作:
- 每行读取 6 个 half4 向量。
- 输出 16 个像素。
- 每个输出像素的内存访问次数为 6x9/16 = 3.375 (half4)。
这些变化后,性能从基线的3.4倍到0.5倍恶化。将更多像素装入一个内核会导致登记溢出,从而严重伤害了性能。
10.3.5 使用本地内存优化
本地内存的延迟比全局内存短得多,因为它是片上内存。一种选择是将像素加载到本地内存中,避免从全局内存中重复加载。除了中心像素外,用于 9x9 过滤的周围像素也被加载到本地内存中,如图 10-6 所示。
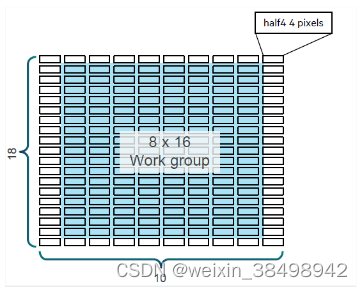
表 10-2 列出了两种情况的设置及其性能。整体性能比原来的要好得多。然而,他们没有击败第 10.4.4 节中的最佳数字。
表 10-2 使用本地内存的性能
| case1 | case2 | |
|---|---|---|
| Workgroup | 8x16 | 8x24 |
| Local memory size (byte) | 10x18x8 =1440 | 10x26x8 = 2080 |
| Performance | 2.4x | 2.8x |
如第 7.1.1 节所述,本地内存通常需要工作组内部的屏障同步,并且不一定会产生比全局内存更好的性能。相反,如果开销太大,它的性能可能会更差。在这种情况下,如果全局内存具有高缓存命中率,它可能会更好。















 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









