









高通 AI Stack 稳定扩散Demo指南(3)
1.2.2 Linux 上的 Qualcomm AI Engine 直接模型准备
Qualcomm AI Engine Direct SDK 允许客户在 HTP 硬件上运行机器学习模型。以下步骤描述了如何在具有 HTP 功能的 Linux 平台上准备和执行稳定扩散模型。
本文档交替使用术语 Qualcomm 神经网络 (QNN) 和 Qualcomm AI Engine Direct SDK。
先决条件
- Qualcomm AI Engine Direct SDK(支持 Ubuntu Linux)
- Ubuntu 20.04 安装以及 QNN 工具所需的软件包
- Android 平台工具版本 31 或更高版本
- 该笔记本可以使用 Anaconda(使用提供的environment.yaml)或虚拟环境(venv)执行
- 稳定的扩散.onnx文件及其相应的 AIMET 编码(通过 AIMET 工作流程生成)
此工作流程假设您已按照 AIMET 稳定扩散工作流程生成了稳定扩散模型工件:
- 稳定扩散文本编码器模型及其 AIMET 编码
- 稳定扩散 U-Net 模型及其 AIMET 编码
- 稳定扩散变分自动编码器 (VAE) 模型及其 AIMET 编码
- fp32.npyfile - 保存为 Python pickle 的 numpy 对象数组,其中包含模型转换步骤所需的数据。
测试环境
Linux x86 电脑
- 发行商 ID:Ubuntu
- 说明:Ubuntu 20.04.5 LTS
- 发布时间:20.04
- 平台:x86_64 AMD
工作流程
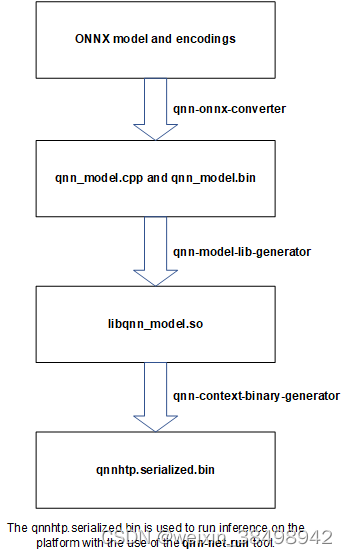
这三个模型和编码通过 Qualcomm AI Engine Direct SDK 中提供的不同可执行 QNN 实用程序独立处理。
要准备用于推理的稳定扩散模型,QNN 可执行实用程序需要 Ubuntu 20.04 环境
- 将文件转换.onnx为等效的 QNN 表示形式A16W8(16 位激活和 8 位权重)
- 生成 QNN 模型库
- 为 QNN HTP 后端生成 QNN 上下文二进制文件
准备好用于推理的稳定扩散模型后,下一步是在 Snapdragon Android 设备上执行 QNN 上下文二进制文件以进行推理。请参阅 qnn_model_execution_on_android.ipynb。
可以使用 Anaconda 或 Python 虚拟环境 (venv) 设置 Python 环境。
注意:在执行笔记本之前,必须执行以下两个设置 Python 环境的步骤之一。
如果您已经启动了 jupyer 笔记本,请先配置 Python 环境,然后再继续。配置Python环境后,重新启动笔记本服务器并选择正确的内核。
设置
在 Ubuntu 20.04 终端中设置 Anaconda
-
从以下位置安装 Anaconda:https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh。
-
使用以下命令执行安装脚本。
chmod a+x Anaconda3-2023.03-1-Linux-x86_64.sh && bash Anaconda3-2023.03-1-Linux-x86_64.sh
-
在 Ubuntu 20.04 终端中使用以下命令配置 Anaconda 环境。
conda create --name stable_diffusion_env python=3.8
conda activate stable_diffusion_env
conda install ipykernel
ipython kernel install --user --name=stable_diffusion_env
在 Ubuntu 20.04 终端中设置 venv(非 Anaconda)
以下步骤安装在 Ubuntu 20.04 环境(Ubuntu 终端窗口)中使用 QNN 工具所需的软件包。
-
更新包索引文件。
sudo apt-get update
-
安装Python3.8和必要的包。
默认情况下,Ubuntu 20.04 应该附带 Python 3.8,您无需再次安装。但是要重新安装它,请运行以下命令。
sudo bash -c ‘apt-get update && apt-get install software-properties-common && add-apt-repository ppa:deadsnakes/ppa && apt-get install python3.8 python3.8-distutils libpython3.8’
-
安装 python3-pip。
sudo apt-get install python3-pip
-
安装python3虚拟环境支持。
sudo apt install python3-virtualenv
-
通过执行以下命令创建并激活Python 3.8虚拟环境。
virtualenv -p /usr/bin/python3.8 venv_stable_diffusion source venv_stable_diffusion/bin/activate
安装所需的Python包
pip install --quiet -r requirements.txt
设置 Qualcomm AI Engine Direct SDK
以下步骤配置 Qualcomm AI Engine Direct SDK,以便在设备上运行 Stable Diffusion。在 Ubuntu 20.04 终端上执行以下命令。
注意:这些步骤需要 sudo 或 root 权限。
- 在Ubuntu中设置Python和pip后,检查QNN工具依赖关系;看/docs/QNN/general/setup.html 了解有关 QNN 设置和 ML 框架依赖项的更多信息。
- 将QNN_SDK_ROOT环境变量设置为 Qualcomm AI Engine 目录的位置。对于Linux,export QNN_SDK_ROOT=“./assets/qnn_assets/unzipped_qnn_sdk_linux/”
- 检查并安装 Linux 依赖项。
source $QNN_SDK_ROOT/bin/check-linux-dependency.sh
sudo apt-get install -y libtinfo5
为 Qualcomm AI Engine 设置 Python 依赖项
import os
#Check and install Python dependencies
QNN_SDK_ROOT=os.getcwd() + "/assets/qnn_assets/unzipped_qnn_sdk_linux/"
!python $QNN_SDK_ROOT/bin/check-python-dependency
准备用于推理的稳定扩散模型
以下部分使用 Qualcomm AI Engine Direct SDK 为目标推理准备稳定的扩散模型。
# Set up environment variable to reference STABLE_DIFFUSION_MODELS
STABLE_DIFFUSION_MODELS = os.getcwd() + "/assets/stable_diffusion/"
将模型从 ONNX 表示转换为 QNN 表示
Qualcomm AI Engine Direct SDKqnn-onnx-conerter工具可将模型从 ONNX 表示精确转换为等效的 QNN 表示A16W8。从 AIMET 工作流程生成的编码文件通过选项提供作为此步骤的输入–quantization_overrides model.encodings。
此步骤生成一个.cpp文件,该文件将模型表示为一系列 QNN API 调用,以及一个.bin包含静态数据的文件,静态数据通常是模型权重并由.cpp文件引用。
对于所有三个模型,此步骤必须独立完成。
生成模型输入列表/数据
inputs_pickle_path=STABLE_DIFFUSION_MODELS + '/fp32.npy'
!python3 generate_inputs.py --pickle_path $inputs_pickle_path --working_dir $STABLE_DIFFUSION_MODELS
为 Qualcomm AI Direct SDK 工具设置环境变量
env = os.environ.copy()
env["QNN_SDK_ROOT"] = QNN_SDK_ROOT
env["PYTHONPATH"] = QNN_SDK_ROOT + "/benchmarks/QNN/:" + QNN_SDK_ROOT + "/lib/python"
env["PATH"] = QNN_SDK_ROOT + "/bin/x86_64-linux-clang:" + env["PATH"]
env["LD_LIBRARY_PATH"] = QNN_SDK_ROOT + "/lib/x86_64-linux-clang"
env["HEXAGON_TOOLS_DIR"] = QNN_SDK_ROOT + "/bin/x86_64-linux-clang"
转换文本编码器
mport subprocess
!mkdir $STABLE_DIFFUSION_MODELS/converted_text_encoder
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-onnx-converter",
"-o", STABLE_DIFFUSION_MODELS + "/converted_text_encoder/qnn_model.cpp",
"-i",STABLE_DIFFUSION_MODELS + "/text_encoder_onnx/text_encoder.onnx",
"--input_list", STABLE_DIFFUSION_MODELS + "/text_encoder_onnx/text_encoder_input_list.txt",
"--act_bw", "16",
"--bias_bw", "32",
"--quantization_overrides", STABLE_DIFFUSION_MODELS + "/text_encoder_onnx/text_encoder.encodings"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
# Rename the model files to make them unique and helpful for subsequent stages
!mv $STABLE_DIFFUSION_MODELS/converted_text_encoder/qnn_model.cpp $STABLE_DIFFUSION_MODELS/converted_text_encoder/text_encoder.cpp
!mv $STABLE_DIFFUSION_MODELS/converted_text_encoder/qnn_model.bin $STABLE_DIFFUSION_MODELS/converted_text_encoder/text_encoder.bin
!mv $STABLE_DIFFUSION_MODELS/converted_text_encoder/qnn_model_net.json $STABLE_DIFFUSION_MODELS/converted_text_encoder/text_encoder_net.json
转换U-Net
预计执行时间:~ 1.5 小时
!mkdir $STABLE_DIFFUSION_MODELS/converted_unet
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-onnx-converter",
"-o", STABLE_DIFFUSION_MODELS + "/converted_unet/qnn_model.cpp",
"-i",STABLE_DIFFUSION_MODELS + "/unet_onnx/unet.onnx",
"--input_list", STABLE_DIFFUSION_MODELS + "/unet_onnx/unet_input_list.txt",
"--act_bw", "16",
"--bias_bw", "32",
"--quantization_overrides", STABLE_DIFFUSION_MODELS + "/unet_onnx/unet.encodings",
"-l", "input_3", "NONTRIVIAL"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
# Rename the model files to make them unique and helpful for subsequent stages
!mv $STABLE_DIFFUSION_MODELS/converted_unet/qnn_model.cpp $STABLE_DIFFUSION_MODELS/converted_unet/unet.cpp
!mv $STABLE_DIFFUSION_MODELS/converted_unet/qnn_model.bin $STABLE_DIFFUSION_MODELS/converted_unet/unet.bin
!mv $STABLE_DIFFUSION_MODELS/converted_unet/qnn_model_net.json $STABLE_DIFFUSION_MODELS/converted_unet/unet_net.json
转换VAE解码器
预计执行时间:~25 分钟
!mkdir $STABLE_DIFFUSION_MODELS/converted_vae_decoder
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-onnx-converter",
"-o", STABLE_DIFFUSION_MODELS + "/converted_vae_decoder/qnn_model.cpp",
"-i",STABLE_DIFFUSION_MODELS + "/vae_decoder_onnx/vae_decoder.onnx",
"--input_list", STABLE_DIFFUSION_MODELS + "/vae_decoder_onnx/vae_decoder_input_list.txt",
"--act_bw", "16",
"--bias_bw", "32",
"--quantization_overrides", STABLE_DIFFUSION_MODELS + "/vae_decoder_onnx/vae_decoder.encodings"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
# Rename for uniqueness
!mv $STABLE_DIFFUSION_MODELS/converted_vae_decoder/qnn_model.cpp $STABLE_DIFFUSION_MODELS/converted_vae_decoder/vae_decoder.cpp
!mv $STABLE_DIFFUSION_MODELS/converted_vae_decoder/qnn_model.bin $STABLE_DIFFUSION_MODELS/converted_vae_decoder/vae_decoder.bin
!mv $STABLE_DIFFUSION_MODELS/converted_vae_decoder/qnn_model_net.json $STABLE_DIFFUSION_MODELS/converted_vae_decoder/vae_decoder_net.json
QNN模型库
Qualcomm AI Engine Direct SDKqnn-model-lib-generator将模型.cpp和.bin文件编译为特定目标的共享对象库。此示例为 x86_64-linux 目标生成共享对象库。
此阶段的输入是上一步中生成的model.cpp和文件。model.bin
生成文本编码器模型库
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-model-lib-generator",
"-c", STABLE_DIFFUSION_MODELS + "/converted_text_encoder/text_encoder.cpp",
"-b", STABLE_DIFFUSION_MODELS + "/converted_text_encoder/text_encoder.bin",
"-t", "x86_64-linux-clang",
"-o", STABLE_DIFFUSION_MODELS + "/converted_text_encoder"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
生成U-Net模型库
预计执行时间:~25 分钟
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-model-lib-generator",
"-c", STABLE_DIFFUSION_MODELS + "/converted_unet/unet.cpp",
"-b", STABLE_DIFFUSION_MODELS + "/converted_unet/unet.bin",
"-t", "x86_64-linux-clang",
"-o", STABLE_DIFFUSION_MODELS + "/converted_unet"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
生成VAE解码器模型库
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-model-lib-generator",
"-c", STABLE_DIFFUSION_MODELS + "/converted_vae_decoder/vae_decoder.cpp",
"-b", STABLE_DIFFUSION_MODELS + "/converted_vae_decoder/vae_decoder.bin",
"-t", "x86_64-linux-clang",
"-o", STABLE_DIFFUSION_MODELS + "/converted_vae_decoder"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
QNN HTP 上下文二进制文件
Qualcomm AI Engine Direct SDKqnn-context-binary-generator工具创建适用于 QNN HTP 后端的 QNN 上下文二进制文件。该二进制文件可以部署在运行 Android 的 Snapdragon Gen2 设备上运行。此步骤需要上一步中的模型共享对象库以及libQnnHtp.soQualcomm AI Engine Direct SDK 中提供的库。
通过传递为 QNN HTP 后端libQnnHtpBackendExtensions.so实现扩展的库,提供与 QNN HTP 后端相关的其他选项。该库可在 Qualcomm AI Engine Direct SDK 中找到。库和配置.json以如下所示的格式提供。有关后端扩展和配置参数的文档可在 Qualcomm AI Engine Direct SDK 文档中找到。
# HTP backend extensions config file (htp_backend_extensions.json) example
htp_backend_extensions_data = '''
{
"backend_extensions": {
"shared_library_path": "libQnnHtpNetRunExtensions.so",
"config_file_path": "/tmp/htp_config.json"
}
}
'''
# HTP backend config file (htp_config.json) example
htp_backend_config_data = '''
{
"graphs": {
"vtcm_mb":8,
"graph_names":["qnn_model"]
},
"devices": [
{
"soc_id": 57,
"dsp_arch": "v73",
"cores":[{
"core_id": 0,
"perf_profile": "burst",
"rpc_control_latency":100
}]
}
]
}
'''
#write the config files to a temporary location
with open('/tmp/htp_backend_extensions.json','w') as f:
f.write(htp_backend_extensions_data)
with open('/tmp/htp_config.json','w') as f:
f.write(htp_backend_config_data)
# Create a path under the models directory for serialized binaries
!mkdir $STABLE_DIFFUSION_MODELS/serialized_binaries
为文本编码器生成 QNN 上下文二进制文件
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-context-binary-generator",
"--model", STABLE_DIFFUSION_MODELS + "/converted_text_encoder/x86_64-linux-clang/libtext_encoder.so",
"--backend", "libQnnHtp.so",
"--output_dir", STABLE_DIFFUSION_MODELS + "/serialized_binaries",
"--binary_file", "text_encoder.serialized",
"--config_file", "/tmp/htp_backend_extensions.json",
"--log_level", "verbose"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
为 U-Net 生成 QNN 上下文二进制文件
预计执行时间:~2 分钟
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-context-binary-generator",
"--model", STABLE_DIFFUSION_MODELS + "/converted_unet/x86_64-linux-clang/libunet.so",
"--backend", "libQnnHtp.so",
"--output_dir", STABLE_DIFFUSION_MODELS + "/serialized_binaries",
"--binary_file", "unet.serialized",
"--config_file", "/tmp/htp_backend_extensions.json"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
为 VAE 解码器生成 QNN 上下文二进制文件
预计执行时间:~1.5 分钟
proc = subprocess.Popen([QNN_SDK_ROOT + "/bin/x86_64-linux-clang/qnn-context-binary-generator",
"--model", STABLE_DIFFUSION_MODELS + "/converted_vae_decoder/x86_64-linux-clang/libvae_decoder.so",
"--backend", "libQnnHtp.so",
"--output_dir", STABLE_DIFFUSION_MODELS + "/serialized_binaries",
"--binary_file", "vae_decoder.serialized",
"--config_file", "/tmp/htp_backend_extensions.json"
],stdout=subprocess.PIPE, stderr=subprocess.PIPE,env=env)
output, error = proc.communicate()
print(output.decode(),error.decode())
完成这些准备用于推理的稳定扩散模型的步骤后,这三个模型的 QNN 上下文二进制文件可在$STABLE_DIFFUSION_MODELS/serialized_binaries/
下一步是使用 Qualcomm AI Engine Direct SDK 中提供的可执行实用程序在 Snapdragon Gen2 Android 设备上执行准备好的模型(现在表示为序列化上下文二进制文件)。














 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









