









Windows on Snapdragon 使用指南(5)
4 适用于人工智能的高通® 神经处理 SDK
适用于人工智能的高通® 神经处理 SDK 简化了开发人员在骁龙设备上运行优化神经网络的流程,无需云连接。 高通神经处理 SDK 利用高通® 人工智能引擎直接支持针对每个加速器后端。
作为高通® 人工智能栈的一部分,该 SDK 有助于在设备上集成神经网络。 它支持 PyTorch、ONNX 或 TensorFlow/TensorFlow Lite 中的多个经过训练的神经网络模型,并且可以在高通® 骁龙 CPU 或 DSP 处理器上运行。 该 SDK 包括用于模型转换和执行的工具、用于核心定位的 API,并支持卷积神经网络和自定义运算符。 通过减轻在高通® 骁龙设备上运行神经网络的负担,高通® 神经处理 SDK 使开发人员能够专注于创造新的创新用户体验。
主要特征
该 SDK 是为希望直接在边缘设备上执行 AI/ML 推理的开发人员提供的解决方案。 通过利用高通® 骁龙移动平台的计算能力,高通® 神经处理 SDK 可实现设备上处理,从而提供以下主要优势:
- 减少延迟:通过设备上处理,消除了与将数据发送到云和接收结果相关的时间和延迟,使其成为实时应用程序的理想选择。
- 提高隐私性:通过将计算保持在本地,用户数据保留在设备上,不会传输到云端,从而提供更高级别的隐私和安全性。
- 节省成本:设备上处理无需云连接,这可以降低部署人工智能/机器学习 应用程序的成本,特别是在云连接有限或昂贵的区域。
- 提高可靠性:通过减少对云的依赖,设备上处理提供了更可靠的解决方案,因为它不易受到网络中断或连接问题的影响。
- 优化的推理性能:该 SDK 可帮助开发人员通过以下方式优化高通骁龙平台上的人工智能/机器学习工作负载的性能:
- 异构计算:SDK利用骁龙平台强大的计算能力,包括CPU和DSP,为人工智能/机器学习工作负载提供最佳性能。
- 优化的模型转换:开发人员可以将在 PyTorch、ONNX、TensorFlow 和 TensorFlow Lite 等流行框架中训练的深度学习模型转换为针对高通® 骁龙平台优化的格式。这有助于提高模型在推理过程中的性能和效率。
- 低精度校准:SDK支持低精度推理,即减少推理过程中用于表示模型参数的位数。这可以在保持高精度的同时提高性能,使开发人员能够根据需要灵活地在精度和性能之间进行权衡。
- 自定义运算符支持:该 SDK 提供可实现自定义层的 API,允许开发人员扩展其模型的功能,以满足其应用程序的特定需求。
- 高效执行:该 SDK 提供针对高通® 骁龙核心的 API,最符合所需的用户体验,使开发人员能够为其人工智能/机器学习工作负载实现最佳性能。
使用高通® 神经处理 SDK 开发人工智能应用程序
要在骁龙 (WoS) 或 Linux 上构建并运行适用于 Windows 的人工智能应用程序,请使用高通® 神经处理 SDK 生成深度学习容器 (DLC)。
设置神经处理 SDK
高通神经处理 SDK 需要安装在主机(x86 64 位机器)上。
构建人工智能应用程序
构建适用于 Windows 或 Linux 平台的应用程序。
4.1 使用高通® 神经处理 SDK 开发人工智能应用程序
要在骁龙(WoS) 或 Linux 上构建并运行适用于 Windows 的人工智能应用程序,请使用 高通® 神经处理 SDK 生成深度学习容器 (DLC)。
| 推荐 | 资源 |
|---|---|
| 请参阅高通® 神经处理引擎 SDK 文档,了解如何将 ONNX、PyTorch、TensorFlow 和 TensorFlow Lite 模型转换为 DLC 文件,将 DLC 量化为 8 位或 16 位定点以在高通® Hexagon™ DSP 上运行,分析性能并将网络集成到应用程序中。 | 高通® 神经处理引擎 SDK 高通® 神经处理引擎 SDK 参考手册 |

4.1.1 工作站要求
- 用于 DLC 准备、生成和量化的 x86_64 Linux 工作站
- Ubuntu 20.04
- Python 3.8
- 以下框架之一
4.1.2 支持高通® 神经处理 SDK 的设备要求
- Windows ARM64 设备构建应用程序并运行编译后的模型二进制文件
- Windows 11
- Visual Studio 2022 17.6.4
- Windows 11 SDK (10.0.22621.0)
- MSBuild 对 LLVM (clang-cl) 工具集的支持
- 适用于 Windows 的 C++ Clang 编译器 (15.0.1)
- MSVC v143 – VS 2022 C++ ARM64/ARM64EC 构建工具 –(最新)
- 适用于 Windows 的 C++ CMake 工具

4.2 设置神经处理 SDK
高通神经处理 SDK 需要安装在主机(x86 64 位机器)上。
在生成 DLC 之前,请在 Ubuntu 20.04 Linux 计算机上设置高通® 神经处理 SDK。
- 从 Windows 控制面板启用适用于 Linux 的 Windows 子系统。
a. 在控制面板中,搜索打开或关闭 Windows 功能。
b. 在“Windows 功能”对话框中,选择适用于 Linux 的 Windows 子系统。 单击确定。

c. 单击立即重新启动以重新启动计算机。 - 选择以下选项之一在 x86_64 设备上安装 WSL 或本机 Linux Ubuntu 20.04.6。 这使得 SDK 能够与 ONNX 框架配合使用。
- 在 Microsoft Store 中,单击“获取”以安装 Ubuntu 20.04 WSL。

- 单击“打开”并在出现提示时创建 ID 和密码。

- 在 Microsoft Store 中,单击“获取”以安装 Ubuntu 20.04 WSL。
Installing, this may take a few minutes...
Please create a default UNIX user account. The username does not need to match your Windows username.
For more information visit: https://aka.ms/wslusers
Enter new UNIX username: %UserName%
New password:
Retype new password:
passwd: password updated successfully
Installation successful!
Windows Subsystem for Linux is now available in the Microsoft Store!
You can upgrade by running 'wsl.exe --update' or by visiting https://aka.ms/wslstorepage
Installing WSL from the Microsoft Store will give you the latest WSL updates, faster.
For more information please visit https://aka.ms/wslstoreinfo
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 4.4.0-19041-Microsoft x86_64)
- 从高通® 包管理器安装最新版本的高通® 神经处理 SDK。
注意
如果尚未安装,系统将提示您安装高通® 包管理器3。
神经处理 SDK 将安装在 C:\Qualcomm\AIStack\SNPE<build_version> 文件夹中。 其中 <build_version> 对应于特定的神经处理 SDK 发行版本。 例如,C:\Qualcomm\AIStack\SNPE\2.13.0.230730。
注意
每个 SDK 版本的安装路径都会有所不同。 上述路径和下面的图片仅供参考,并不代表您机器上安装的 SDK 版本。
- 将安装的 SDK 复制到 X86_64 主机设备上的 \wsl 文件夹。
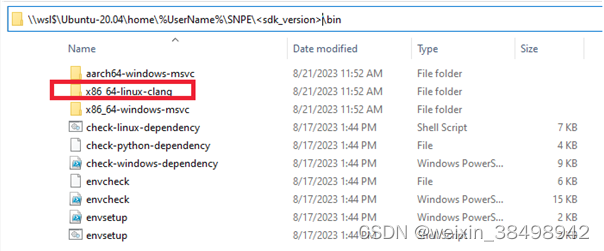
注意
x86_64-linux-clang 二进制文件适用于 WSL 或 Linux 的 X86_64 主机设备。 它不适用于 ARM64 设备上的 WSL。
如果遇到snpe-sdk权限问题,请使用以下命令授予权限:
sudo chown -R $USER:$USER snpe-sdk && sudo chmod -R 777 snpe-sdk
a. 完成 SDK 依赖项的设置,使用:高通神经处理引擎SDK。
b. 对于本指南的其余部分,安装 SDK 依赖项、DNN 框架和其他要求非常重要,如上述 SDK 文档中所述。
-
通过使用 ML 模型进行模型准备、转换和量化,验证主机 x86_64 上的 SNPE 工具链。
高通® 人工智能神经处理 SDK 不捆绑任何模型文件,但包含用于下载某些模型并将其转换为高通深度学习容器 (.dlc) 格式的脚本。a. 准备预训练的模型和输入文件。 (使用 Resnet50 Onnx 模型进行测试。)
wget --no-check-certificate -c https://github.com/onnx/models/raw/main/vision/classification/resnet/model/resnet50-v1-7.onnx python3 ~/snpe-sdk/examples/Models/inception_v3/scripts/create_inceptionv3_raws.py -i ~/snpe-sdk/examples/Models/inception_v3/data -d . -s 224 python3 ~/snpe-sdk/examples/Models/inception_v3/scripts/create_file_list.py -e "*.raw"b. 运行以下命令将预训练的 Resnet50 示例转换为 DLC 格式:
snpe-onnx-to-dlc -i resnet50-v1-7.onnx --input_dim data 1,3,224,224例如,将显示类似于以下内容的消息。
ce@dev:~$ snpe-onnx-to-dlc -i resnet50-v1-7.onnx --input_dim data 1,3,224,224 WARNING: The argument 'input_shapes' is deprecated. Please use 'overwrite_input_shapes' and/or 'test_input_shapes' instead. An error will be raised in the future. 2023-04-25 00:29:48,893 - 214 - INFO - Successfully simplified the onnx model in child process 2023-04-25 00:31:56,557 - 214 - INFO - Successfully receive the simplified onnx model in main process 2023-04-25 00:34:07,156 - 219 - WARNING - WARNING_GEMM: GEMM operation is not supported in the general case, attempting to interpret as FC 2023-04-25 00:34:07,696 - 214 - INFO - INFO_INITIALIZATION_SUCCESS: 2023-04-25 00:34:08,464 - 214 - INFO - INFO_CONVERSION_SUCCESS: Conversion completed successfully 2023-04-25 00:34:09,320 - 214 - INFO - INFO_WRITE_SUCCESS:c. 量化 DSP/HTP 图形并将其添加到 DLC 以用于运行时 DSP。 默认 SoC 值为 SM8550。 使用 --htp_socs 匹配目标设备上的 HTP SoC 版本
snpe-dlc-quantize --input_dlc=resnet50-v1-7.dlc --input_list=file_list.txt --enable_htp --htp_socs=sm8350 --silent例如,将显示类似于以下内容的消息。
[WARN] verbose coredump is not supported [ERROR] Failed to enable verbose core dump. [INFO] DebugLog shutting down. 1.3ms [ INFO ] Initializing logging in the backend. Callback: [0xc42410], Log Level: [3] 1.9ms [ INFO ] No BackendExtensions lib provided;initializing NetRunBackend Interface 472.7ms [ INFO ] cleaning up resources for input tensors 473.2ms [ INFO ] cleaning up resources for output tensors 677.5ms [ INFO ] cleaning up resources for input tensors 678.2ms [ INFO ] cleaning up resources for output tensors 877.9ms [ INFO ] cleaning up resources for input tensors 878.6ms [ INFO ] cleaning up resources for output tensors 1075.2ms [ INFO ] cleaning up resources for input tensors 1075.9ms [ INFO ] cleaning up resources for output tensors [WARN] verbose coredump is not supported [ERROR] Failed to enable verbose core dump. [INFO] DebugLog shutting down.d. 在 CPU 运行时的 ./output/Result_0/ 下生成输出 (OP_NAME.raw) 文件。
snpe-net-run --container resnet50-v1-7_quantized.dlc --input_list file_list.txt例如,将显示类似于以下内容的消息。
------------------------------------------------------------------------------- Model String: N/A SNPE v2.12.1.230626174329_59328 ------------------------------------------------------------------------------- Processing DNN input(s): /home/%UserName%/model/chairs.raw Processing DNN input(s): /home/%UserName%/model/notice_sign.raw Processing DNN input(s): /home/%UserName%/model/plastic_cup.raw Processing DNN input(s): /home/%UserName%/model/trash_bin.raw Successfully executed!















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









