







 本文详细介绍了QualcommCloudAISDK的云AI术语、PythonAPI中的推理API,包括如何创建会话、运行推理、基准测试和设置选项。重点讲解了Session类的功能和使用方法,以及当前的局限性和支持的平台。
本文详细介绍了QualcommCloudAISDK的云AI术语、PythonAPI中的推理API,包括如何创建会话、运行推理、基准测试和设置选项。重点讲解了Session类的功能和使用方法,以及当前的局限性和支持的平台。
Qualcomm Cloud AI SDK 用户指南(12)
6 云 AI 术语表
云人工智能术语
| 学期 | 描述 |
|---|---|
| AI 核心 / AI 计算核心 / NSP | 这些术语可互换使用,指代云 AI 平台中的神经信号处理器核心。NSP 核心运行推理。 |
| 实例/激活 | 单个实例或激活是指在一组 AI 核心上执行的 QPC。 |
| QAIC / AIC / 云人工智能/ AIC100 | 这些术语可互换使用来指代云 AI。这些术语通常后面跟着正在讨论的主题(如编译器/SDK/库等)。 |
| QPC | (Qaic 程序容器)/模型二进制文件/网络二进制文件 |
| 中医/VTCM | (传染媒介)紧密耦合的存储器。ARM 规范中的片上或 NSP 内存。 |
| ECC | 纠错码。TCM 中的纠错作为 ARM 规范中的功能。 |
| 虚拟机/KVM | (基于内核的)虚拟机。 |
| ONNX | 打开神经网络交换文件格式。 |
7 Api
7.1 Python API
7.1.1 推理 API
qaic包
qaic- qaic 包提供了一种在 Qualcomm Cloud AI 100 卡上运行推理的方法。
描述
用户可以通过传入创建一个session对象
-
与一个.onnx文件。
-
使用预编译的 qpc 作为 model_path,以防用户已经编译了 qpc。使用预编译的二进制文件时,应传递 qpc.bin 的完整路径。
笔记
QPC:高通程序容器
有关如何运行推理的示例
选项 1:编译 onnx 文件以生成 QPC 并设置用于推理的会话
import qaic
import numpy as np
sess = qaic.Session('/path/to/model/model.onnx')
input_dict = {'input_name': input_data}
output = sess.run(input_dict)
选项 2:使用生成 QPC 并设置会话进行推理
import qaic
import numpy as np
sess = qaic.Session('/path/to/model/qpc.bin') # option 2 : Session uses compiled QPC file to
input_dict = {'input_name': input_data}
output = sess.run(input_dict)
基准测试示例
import qaic
sess = qaic.Session(model_path='/path/to/model', backend='aic', options_path = '/path/to/yaml') # model_path can be either onnx or precompiled qpc
inf_completed, inf_rate, inf_time, batch_size = sess.run_benchmark()
局限性
目前仅支持 QAic 后端。我们计划在未来版本中支持 QNN 后端。
API 仅与 Python 3.8 兼容
这些 API 仅在 x86-64 平台上受支持
班级会议
Session 是这些 API 的入口点。Session 是一个工厂方法,用户需要调用它来创建会话实例。创建会话时默认会编译模型。
Session(model_path, **kwargs)
Session 根据提供的 qpc 创建会话对象。
参数

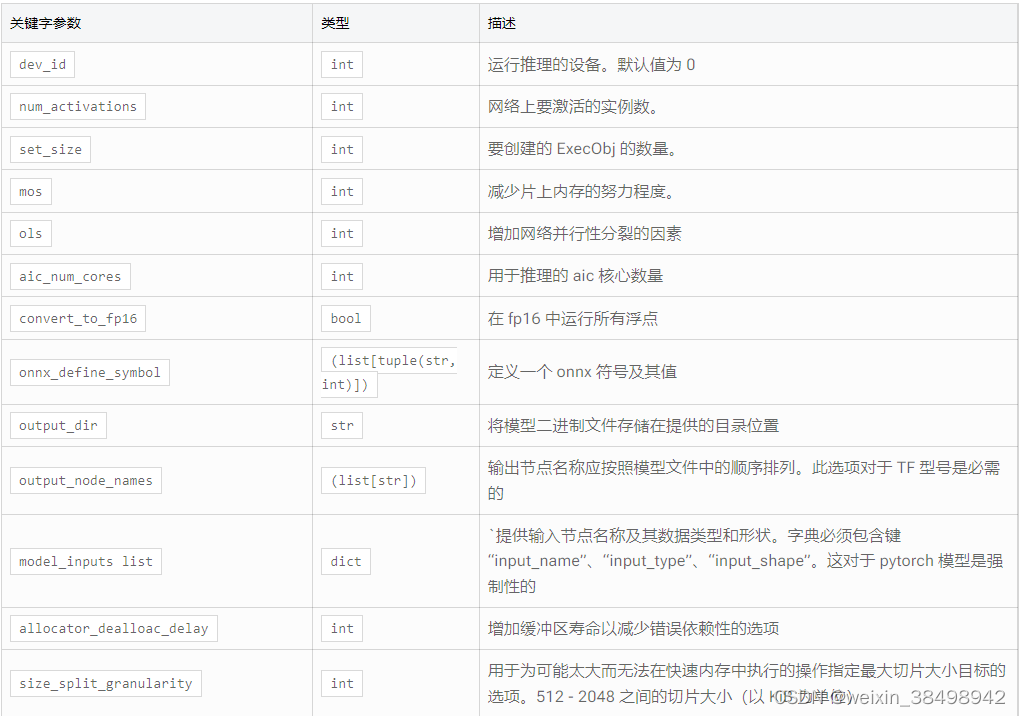
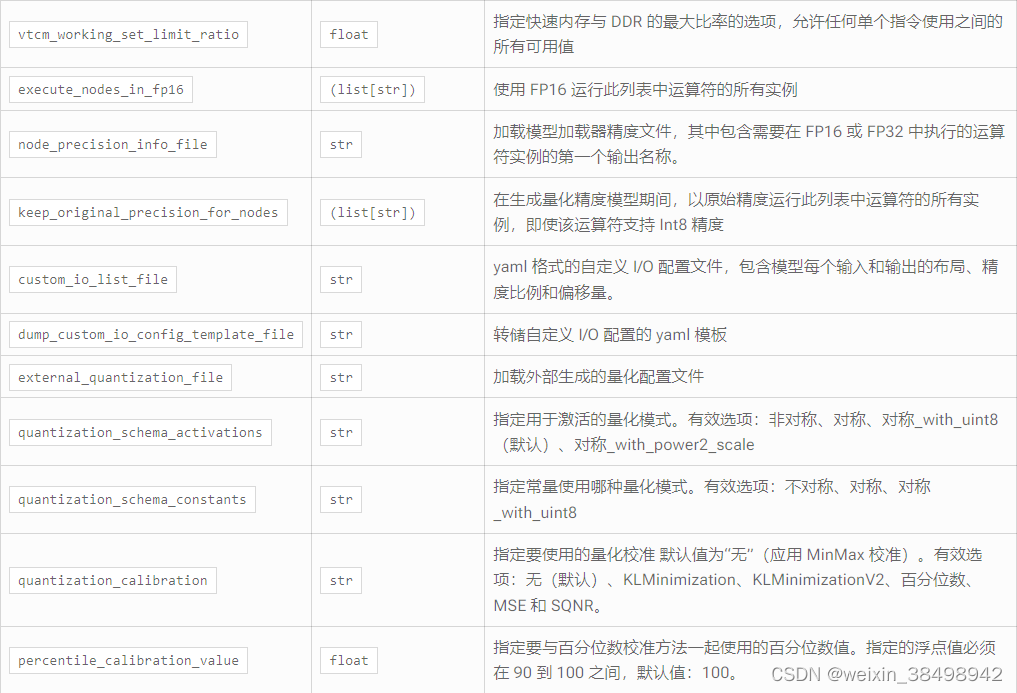
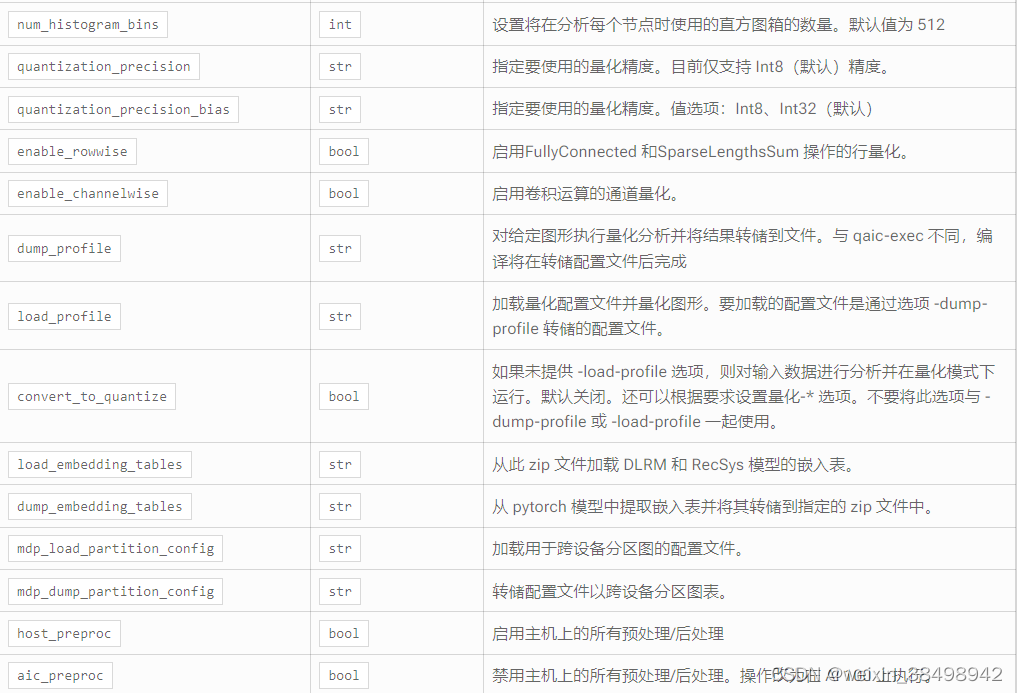
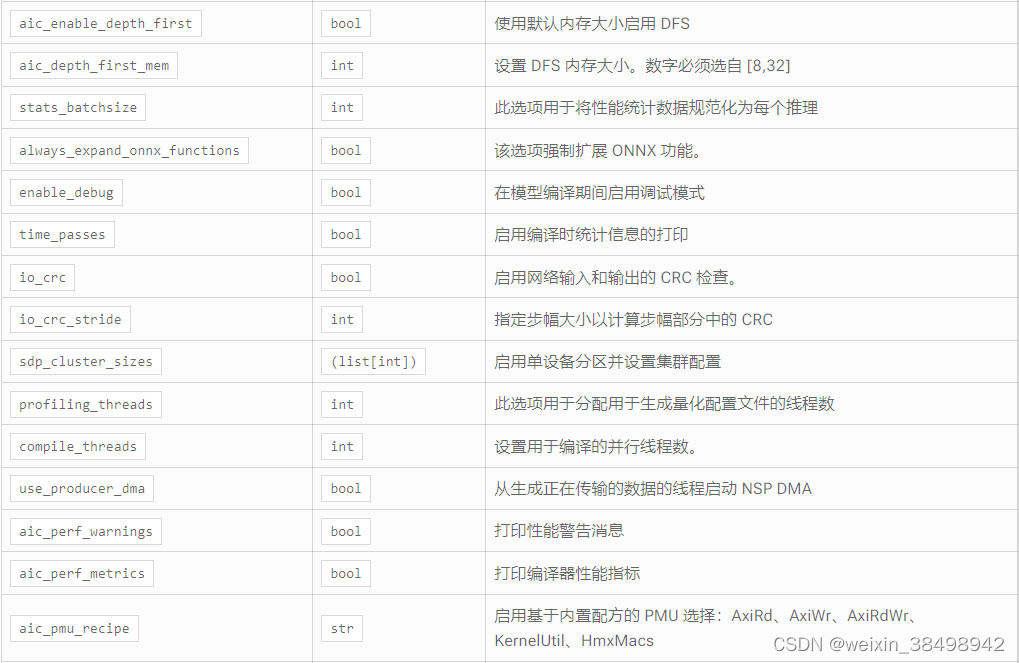
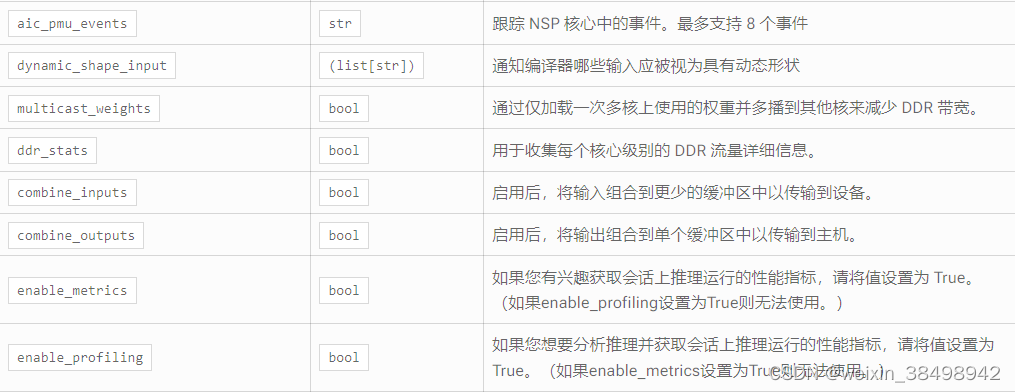
返回
会话对象。
例子
使用 options_path yaml 文件
sess = qaic.Session('/path/to/model', options_path = '/path/to/options.yaml')
input_dict = {'input_name': input_data}
output = sess.run(input_dict)
yaml 文件的示例内容
aic_num_cores: 4
num_activations: 1
convert_to_fp16: true
onnx_define_symbol:
batch: 1
output_dir: './resnet_qpc'
使用关键字参数
sess = qaic.Session('/path/to/model_qpc/*.bin', num_activations=4, set_size=10)
input_dict = {'input_name': input_data}
output = sess.run(input_dict)
API列表(会话对象的函数变量)
Session 类有以下方法。
后端选项()
返回
创建会话后可以配置的选项字典
使用示例
backend_options_dict = session.backend_options()
获取指标()
返回
包含以下指标的字典:
- num_of_inferences (int): The number of inferences.
- min_latency (float): The minimum inference time.
- max_latency (float): The maximum inference time.
- P25 (float): The 25th percentile latency.
- P50 (float): The 50th percentile latency (median).
- P75 (float): The 75th percentile latency.
- P90 (float): The 90th percentile latency.
- P99 (float): The 99th percentile latency.
- P999 (float): The 99.9th percentile latency.
- total_inference_time (float): The sum of individual insference times.
- avg_latency (float): The average latency.
使用示例
metrics_dict = session.get_metrics()
model_input_shape_dict()
返回
以 input_name 作为键,以 input_shape、input_type 作为值的字典
使用示例
input_shape_dict = session.model_input_shape_dict()
model_output_shape_dict()
返回
以output_name为键,以output_shape、output_type为值的字典
使用示例
output_shape_dict = session.model_output_shape_dict()
打印指标()
返回
None
使用示例
session.print_metrics()
笔记
此方法假设“enable_profiling”或“enable_metrics”属性设置为 True。
示例输出:
Number of inferences utilized for calculation are 999
Minimum latency observed 0.0009578340000000001 s
Maximum latency observed 0.002209001 s
Average latency / inference time observed is 0.0012380756316316324 s
P25 / 25% of inferences observed latency less than 0.001095435 s
P50 / 50% of inferences observed latency less than 0.0012522870000000001 s
P75 / 75% of inferences observed latency less than 0.001299786 s
P90 / 90% of inferences observed latency less than 0.002209001 s
P99 / 99% of inferences observed latency less than 0.0016082370000000002 s
Sum of all the inference times 1.2368375560000007 s
Average latency / inference time observed is 0.0012380756316316324 s
打印配置文件数据
返回
none
使用示例
session.print_profile_data(n)
打印前 n 次迭代的分析数据
笔记
仅当会话的“enable_profiling”设置为 True 时,此函数才有效。
- 此方法假设“enable_profiling”属性设置为 True,并且“profiling_results”属性包含每次迭代的分析数据。
- 该方法以表格格式打印分析数据,包括文件、行、函数、调用次数、函数时间(秒)以及每个函数的总时间(秒)。
示例输出:
| File-Line-Function | | num calls | | func time | | tot time |
('~', 0, "<method 'astype' of 'numpy.ndarray' objects>") 1 0.000149101 0.000149101
('~', 0, '<built-in method numpy.empty>') 1 2.38e-06 2.38e-06
('~', 0, '<built-in method numpy.frombuffer>') 1 4.22e-06 4.22e-06
重置()
返回
None
使用示例
session.reset()
释放会话获取的所有设备资源
设置()
返回
None
使用示例
session.setup()
将网络加载到设备。
网络通常在第一次调用运行时加载。如果在此之前调用此函数,则在调用第一次运行时网络将已加载。
运行(输入字典)
返回
具有推理的输出名称和输出值的字典
使用示例
output = session.run(input_dict)
input_dict 应该以 input_name 作为键,值应该是 numpy 数组
运行基准测试()
返回
inf_completed:运行推理的总数 inf_rate:模型的 Inf/Sec inf_time:运行推理所需的总时间 batch_size:模型使用的批量大小
使用示例
inf_completed, inf_rate, inf_time, batch_size = session.run_benchmark()
它接受以下参数:
num_inferences:在基准测试中运行的推理数量。默认 40 inf_time:推理运行的持续时间(以秒为单位)。默认无 input_dict:推理中使用的输入。默认随机
笔记
num_inferences 和 time 不能一起使用。
此 API 使用 C++ 基准测试 API,不考虑 python 开销
update_backend_options(**kwargs)
返回
None
使用示例
session.update_backend_options(num_activations = 2)
更新 kwargs 中指定的选项
例如:
num_activation, dev_id,set_size可以通过该API进行配置。

















 5657
5657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









