






PSNPE简介
目的
在异构计算资源(例如 HVX、HMX)上并行执行多个 SNPE 实例被称为并行 SNPE(PSNPE),可以显著加快批量输入处理任务的速度。
结构
一个 PSNPE 实例包含一个或多个 SNPE 实例,这些实例具有三种可选的执行模式:同步、异步输出和异步输入/输出。创建多个 SNPE 实例有助于创建多个工作线程。工作线程允许将多个执行调用排队,以便在硬件准备就绪时进行调度,从而提高吞吐量。
-
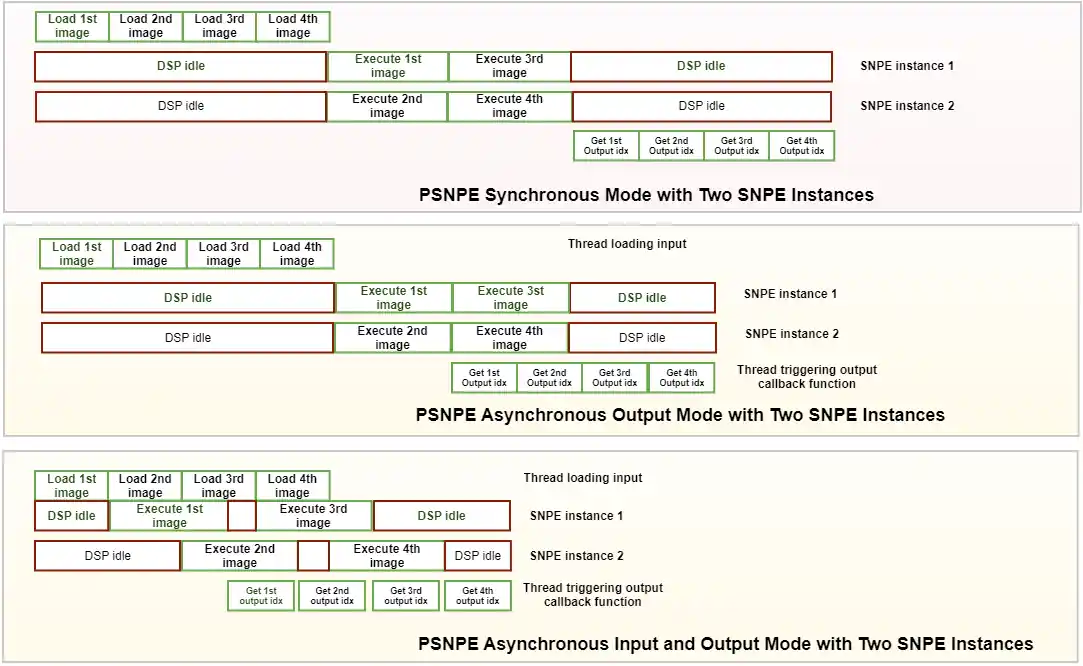
在同步模式下,处理步骤是按顺序进行的。首先加载批量输入数据,然后并行执行多个 SNPE 实例,最后获取输出数据。
-
在输出异步模式下,加载输入数据是同步的,但执行 SNPE 实例并获取输出是异步的。回调函数用于实现异步。
-
在输入/输出异步模式下,加载输入数据、执行 SNPE 实例以及获取输出数据都是异步的。目前此模式不支持用户缓冲区内存映射。
特征
-
同步模式
-
输出异步模式
-
输入/输出异步模式
下图显示了三种不同的模式。
PSNPE C 教程
先决条件
-
高通神经处理 SDK 已按照|Qualcomm(R)| Neural Processing SDK 设置高通神经处理|Qualcomm(R)| Neural Processing SDK 设置进行设置。
-
教程设置已完成。
-
本页中使用的 API 可以在C 教程 - 构建示例章节中找到。
介绍
本教程演示如何使用 PSNPE C API 构建其 C 示例应用程序,该应用程序可在目标设备上执行具有多个运行时的神经网络模型。虽然此示例代码未进行任何错误检查,但强烈建议用户在使用 PSNPE API 时检查错误。此外,由于示例代码基于 C 语言,因此最终需要释放所有相关句柄。
以同步模式为例,PSNPE集成应用程序在使用神经网络时将遵循以下模式:
auto runtimeConfigListHandle = Snpe_RuntimeConfigList_Create();
auto bcHandle = Snpe_BuildConfig_Create();
buildStatus = (Snpe_PSNPE_Build(psnpeHandle, bcHandle) == SNPE_SUCCESS);
exeStatus = SNPE_SUCCESS == Snpe_PSNPE_Execute(psnpeHandle, inputMapList2, outputMapList2);
PSNPE 默认使用同步模式,如需选择异步模式,请参考 异步模式的 BuildConfig。输出异步模式中,加载输入数据和执行 PSNPE 与同步模式类似,但需要通过在 OutputAsync 模式的 Callback中定义 outputCallback 函数来获取输出数据。输入/输出异步模式中,加载输入数据和获取输出数据都需要回调函数,具体可参考 InputOutputAsync 模式的 Execution 和 Callback。
以下部分描述了如何实现上述每个步骤。
获取可用运行时的配置
以下代码摘录说明了如何使用给定参数为每个可用运行时设置配置。可以通过向运行时配置列表添加多个运行时配置句柄来为同一运行时创建多个实例。即使是同一运行时的多个实例,也会创建多个工作线程来将工作排队等待执行,从而提高吞吐量。
auto runtimeConfigListHandle = Snpe_RuntimeConfigList_Create();
for (size_t j = 0; j < numRequestedInstances; j++)
{
auto runtimeConfigHandle = Snpe_RuntimeConfig_Create();
Snpe_RuntimeConfig_SetRuntimeList(runtimeConfigHandle, RuntimesListVector[j]);
Snpe_RuntimeConfig_SetPerformanceProfile(runtimeConfigHandle, PerfProfile[j]);
Snpe_RuntimeConfigList_PushBack(runtimeConfigListHandle, runtimeConfigHandle);
Snpe_RuntimeConfig_Delete(runtimeConfigHandle);
numCreatedInstances++;
}
获取构建器配置
下面的代码摘录说明了如何使用给定的参数(包括 DLC、runtimeConfigList、输出层、传输模式等)设置 PSNPE 构建器的配置。
auto containerHandle = Snpe_DlContainer_Open(ContainerPath.c_str());
auto bcHandle = Snpe_BuildConfig_Create();
Snpe_BuildConfig_SetContainer(bcHandle, containerHandle);
Snpe_BuildConfig_SetRuntimeConfigList(bcHandle, runtimeConfigListHandle);
Snpe_BuildConfig_SetOutputBufferNames(bcHandle, outputLayers);
Snpe_BuildConfig_SetInputOutputTransmissionMode(bcHandle, static_cast<Snpe_PSNPE_InputOutputTransmissionMode_t>(inputOutputTransmissionMode));
Snpe_BuildConfig_SetEncode(bcHandle, input_encode[0], input_encode[1]);
Snpe_BuildConfig_SetEnableInitCache(bcHandle, usingInitCache);
Snpe_BuildConfig_SetProfilingLevel(bcHandle, profilingLevel);
Snpe_BuildConfig_SetPlatformOptions(bcHandle, platformOptions.c_str());
Snpe_BuildConfig_SetOutputTensors(bcHandle, outputTensors);
构建PSNPE实例
以下代码演示了如何实例化用于执行网络的 PSNPE Builder 对象。
buildStatus = (Snpe_PSNPE_Build(psnpeHandle, bcHandle) == SNPE_SUCCESS);
使用用户缓冲区列表加载网络输入
此输入加载方法用于同步模式和输出异步模式,类似于 高通神经处理 SDK 用于从用户支持的缓冲区创建输入和输出的方法。
std::vector<std::unordered_map <std::string, std::vector<uint8_t>>> outputBuffersVec(nums);
std::vector<std::unordered_map <std::string, std::vector<uint8_t>>> inputBuffersVec(nums);
std::vector<Snpe_IUserBuffer_Handle_t> snpeUserBackedInputBuffers;
std::vector<Snpe_IUserBuffer_Handle_t> snpeUserBackedOutputBuffers;
Snpe_UserBufferList_Handle_t inputMapList = Snpe_UserBufferList_CreateSize(BufferNum);
Snpe_UserBufferList_Handle_t outputMapList = Snpe_UserBufferList_CreateSize(BufferNum);
if(inputOutputTransmissionMode != zdl::PSNPE::InputOutputTransmissionMode::inputOutputAsync)
{
for (size_t i = 0; i < inputs.size(); ++i) {
for (size_t j = 0; j < Snpe_StringList_Size(inputTensorNamesList[0]); ++j) {
const char* name = Snpe_StringList_At(inputTensorNamesList[0], j);
uint8_t bufferBitWidth = bitWidthMap[bufferDataTypeMap[name]];
uint8_t nativeBitWidth = usingNativeInputDataType ? bitWidthMap[nativeDataTypeMap[name]]: 32;
std::string nativeDataType = usingNativeInputDataType ? nativeDataTypeMap[name] : "float32";
if(bufferDataTypeMap[name] == "float16" || bufferDataTypeMap[name] == "float32"){
if(!LoadInputBufferMapsFloatN(inputs[i][j], name, {psnpeHandle, true},
Snpe_UserBufferList_At_Ref(inputMapList, i),
snpeUserBackedInputBuffers, inputBuffersVec[i],numFilesCopied, batchSize, dynamicQuantization,
bufferBitWidth,10, rpcMemAllocFnHandle, false, ionBufferMapHandle,
usingNativeInputDataType, nativeDataType, nativeBitWidth))
{
return EXIT_FAILURE;
}
}
}
Snpe_StringList_Handle_t outputBufferNamesHandle = Snpe_PSNPE_GetOutputTensorNames(psnpeHandle);
for (size_t j = 0; j < Snpe_StringList_Size(outputBufferNamesHandle); ++j) {
const char* name = Snpe_StringList_At(outputBufferNamesHandle, j);
if(bufferDataTypeMap.find(name) == bufferDataTypeMap.end()){
std::cerr << "DataType not specified for buffer " << name << std::endl;
}
uint8_t bitWidth = bitWidthMap[bufferDataTypeMap[name]];
if(bufferDataTypeMap[name] == "float16" || bufferDataTypeMap[name] == "float32"){
PopulateOutputBufferMapsFloatN({psnpeHandle, true}, name,
Snpe_UserBufferList_At_Ref(outputMapList, i),
snpeUserBackedOutputBuffers, outputBuffersVec[i], bitWidth, 10,
rpcMemAllocFnHandle, usingIonBuffer, ionBufferMapHandle);
}
}
}
}
执行同步模式的网络和流程输出
以下代码使用原生 API 以同步模式执行网络。saveOutput 函数可以参考PSNPE C++ 教程
exeStatus = SNPE_SUCCESS == Snpe_PSNPE_Execute(psnpeHandle, inputMapList, outputMapList);
for (size_t i = 0; i < inputs.size(); i++) {
saveOutput(Snpe_UserBufferList_At_Ref(outputMapList, i), outputBuffersVec[i], ionBufferMapReg, OutputDir, i * batchSize, batchSize, false);
}
异步模式的 BuildConfig
如果要运行outputAsync模式或者inputOutputAsync模式,需要在buildConfig中设置回调函数。
if (inputOutputTransmissionMode == SNPE_PSNPE_INPUTOUTPUTTRANSMISSIONMODE_OUTPUTASYNC) {
Snpe_BuildConfig_SetOutputThreadNumbers(bcHandle, outputNum);
Snpe_BuildConfig_SetOutputCallback(bcHandle, OCallback);
}
if (inputOutputTransmissionMode == SNPE_PSNPE_INPUTOUTPUTTRANSMISSIONMODE_INPUTOUTPUTASYNC) {
Snpe_BuildConfig_SetInputThreadNumbers(bcHandle, inputNum);
Snpe_BuildConfig_SetOutputThreadNumbers(bcHandle, outputNum);
Snpe_BuildConfig_SetInputOutputCallback(bcHandle, IOCallback);
Snpe_BuildConfig_SetInputOutputInputCallback(bcHandle, inputCallback);
}
OutputAsync 模式的回调
输出异步模式通过调用回调函数提供实时输出。
void OCallback(Snpe_PSNPE_OutputAsyncCallbackParam_Handle_t oacpHandle) {
if(!Snpe_PSNPE_OutputAsyncCallbackParam_GetExecuteStatus(oacpHandle)) {
std::cerr << "excute fail ,index: " << Snpe_PSNPE_OutputAsyncCallbackParam_GetDataIdx(oacpHandle) << std::endl;
}
}
InputOutputAsync 模式的执行和回调
异步执行可以提供实时的输出结果,同步执行则在执行完成后才提供输出。
for (size_t i = 0; i < inputs.size(); ++i) {
std::vector< std::string > filePaths;
std::vector<std::queue<std::string>> temp = inputs[i];
for(size_t j=0;j<temp.size();j++)
{
while(temp[j].size()!= 0){
filePaths.push_back(temp[j].front());
temp[j].pop();
}
numLines++;
Snpe_StringList_Handle_t filePathsHandle = toStringList(filePaths);
exeStatus = SNPE_SUCCESS == Snpe_PSNPE_ExecuteInputOutputAsync(psnpeHandle, filePathsHandle, i, usingTf8UserBuffer, usingTf8UserBuffer);
}
}
//In input/output asynchronous mode, loading input data through callback function with TF8 vector.
Snpe_ApplicationBufferMap_Handle_t inputCallback(Snpe_StringList_Handle_t inputs, Snpe_StringList_Handle_t inputNames) {
Snpe_ApplicationBufferMap_Handle_t inputMap = Snpe_ApplicationBufferMap_Create();
for (size_t j = 0; j < Snpe_StringList_Size(inputNames); j++) {
std::vector<uint8_t> loadVector;
... //load input data
Snpe_ApplicationBufferMap_Add(inputMap, Snpe_StringList_At(inputNames, j), loadVector.data(), loadVector.size());
}
return inputMap;
}
// In input/output asynchronous mode, the index and data of output can be obtained through a callback function
void IOCallback(Snpe_PSNPE_InputOutputAsyncCallbackParam_Handle_t ioacpHandle)
{
Snpe_StringList_Handle_t names = Snpe_PSNPE_InputOutputAsyncCallbackParam_GetUserBufferNames(ioacpHandle);
std::vector<std::pair<const char*, Snpe_UserBufferData_t>> vec;
const auto end = Snpe_StringList_End(names);
for(auto it = Snpe_StringList_Begin(names); it != end; ++it){
vec.emplace_back(*it, Snpe_PSNPE_InputOutputAsyncCallbackParam_GetUserBuffer(ioacpHandle, *it));
}
saveOutput(vec, OutputDir, Snpe_PSNPE_InputOutputAsyncCallbackParam_GetDataIdx(ioacpHandle));
}
// The below shows parts of the function.
void saveOutput(const std::vector<std::pair<const char*, Snpe_UserBufferData_t>>& applicationOutputBuffers, const std::string& outputDir, int num){
std::for_each(applicationOutputBuffers.begin(),
applicationOutputBuffers.end(),
[&](std::pair<std::string, Snpe_UserBufferData_t> a) {
std::ostringstream path;
path << outputDir << "/"
<< "Result_" << num << "/" << pal::FileOp::toLegalFilename(a.first) << ".raw";
std::string outputPath = path.str();
std::string::size_type pos = outputPath.find(":");
if (pos != std::string::npos) outputPath = outputPath.replace(pos, 1, "_");
SaveUserBuffer(outputPath, a.second.data, a.second.size);
});
}
C 应用程序示例
本教程中与 PSNPE 集成的 C 应用程序名为snpe-parallel-run 。它是一个命令行可执行文件,使用 Qualcomm® Neural Processing SDK SDK API 执行 DLC 模型。它的用法与在 Android 目标上运行高通神经处理snpe-parallel-run 。它是一个命令行可执行文件,使用 Qualcomm® Neural Processing SDK SDK API 执行 DLC 模型。它的用法与在 Android 目标上运行Inception v3 模型中的 snpe-net-run 示例相同 。
-
将模型数据推送至 Android 目标。
-
选择目标架构。
-
将二进制文件推送至目标。
-
设置环境变量。
adb shell
export ADSP_LIBRARY_PATH="/data/local/tmp/snpeexample/dsp/lib;/system/lib/rfsa/adsp;/system/vendor/lib/rfsa/adsp;/dsp"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data/local/tmp/snpeexample/aarch64-android/lib
export PATH=$PATH:/data/local/tmp/snpeexample/aarch64-android/bin/
cd /data/local/tmp/inception_v3
snpe-parallel-run --container inception_v3_quantized.dlc --input_list target_raw_list.txt --use_dsp --perf_profile burst --cpu_fallback false --use_dsp --perf_profile burst --cpu_fallback false --runtime_mode output_async
exit
PSNPE C++ 教程
先决条件
-
高通神经处理 SDK 已按照|Qualcomm(R)| Neural Processing SDK 设置高通神经处理|Qualcomm(R)| Neural Processing SDK 设置进行设置。
-
教程设置已完成。
-
本页中使用的 API 可以在C++ 教程 - 构建示例中找到。
介绍
本教程演示如何使用 PSNPE C++ API 构建其 C++ 示例应用程序,该应用程序可在目标设备上执行具有多个运行时的神经网络模型。虽然此示例代码未进行任何错误检查,但强烈建议用户在使用 PSNPE API 时检查错误。
以同步模式为例,PSNPE集成应用程序在使用神经网络时将遵循以下模式:
zdl::PSNPE::RuntimeConfigList runtimeconfigs;
zdl::PSNPE::BuildConfig buildConfig;
buildStatus = psnpe->build(buildConfig);
exeStatus = psnpe->execute(inputMapList, outputMapList);
PSNPE 默认使用同步模式,如需选择异步模式,请参考 异步模式的 BuildConfig。输出异步模式中,加载输入数据和执行 PSNPE 与同步模式类似,但需要通过在 OutputAsync 模式的 Callback中定义 outputCallback 函数来获取输出数据。输入/输出异步模式中,加载输入数据和获取输出数据都需要回调函数,具体可参考 InputOutputAsync 模式的 Execution 和 Callback。
以下部分描述了如何实现上述每个步骤。
获取可用运行时的配置
下面的代码摘录说明了如何使用给定的参数为每个可用的运行时设置配置。
zdl::PSNPE::RuntimeConfigList runtimeconfigs;
for (size_t j = 0; j < numRequestedInstances; j++)
{
zdl::PSNPE::RuntimeConfig runtimeConfig;
zdl::SNPE::SNPEFactory::isRuntimeAvailable(Runtimes[j]);
runtimeConfig.runtime = Runtimes[j];
runtimeConfig.enableCPUFallback = cpuFallBacks[j];
runtimeConfig.perfProfile = PerfProfile[j];
runtimeconfigs.push_back(runtimeConfig);
}
获取构建器配置
下面的代码摘录说明了如何使用给定的参数(包括 DLC、runtimeConfigList、输出层、传输模式等)设置 PSNPE 构建器的配置。
zdl::PSNPE::BuildConfig buildConfig;
std::unique_ptr<zdl::DlContainer::IDlContainer> container = zdl::DlContainer::IDlContainer::open(ContainerPath);
buildConfig.container = container.get();
buildConfig.runtimeConfigList = runtimeconfigs;
buildConfig.outputBufferNames = outputLayers;
buildConfig.inputOutputTransmissionMode = inputOutputTransmissionMode;
buildConfig.enableInitCache = usingInitCache;
buildConfig.profilingLevel = profilingLevel;
buildConfig.platformOptions = platformOptions;
buildConfig.outputTensors = outputTensors;
构建PSNPE实例
以下代码演示了如何实例化用于执行网络的 PSNPE Builder 对象。
bool buildStatus = psnpe->build(buildConfig);
使用用户缓冲区列表加载网络输入
此输入加载方法适用于同步模式和异步输出模式,与 高通神经处理 SDK 从用户支持的缓冲区创建输入和输出的方法类似。函数 createUserBuffer() 和 loadInputUserBuffer() 可参考C++ 教程 - 示例构建。
std::vector<std::unordered_map <std::string, std::vector<uint8_t>>> outputBuffersVec(nums);
std::vector<std::unordered_map <std::string, std::vector<uint8_t>>> inputBuffersVec(nums);
std::vector <std::unique_ptr<zdl::DlSystem::IUserBuffer>> snpeUserBackedInputBuffers, snpeUserBackedOutputBuffers;
zdl::PSNPE::UserBufferList inputMapList(nums), outputMapList(nums);
const zdl::DlSystem::StringList innames = psnpe->getInputTensorNames();
const zdl::DlSystem::StringList outnames = psnpe->getOutputTensorNames();
if(inputOutputTransmissionMode != zdl::PSNPE::InputOutputTransmissionMode::inputOutputAsync)
{
for (size_t i = 0; i < inputs.size(); ++i)
{
for (const char* name : innames)
{
createUserBuffer(inputMapList[i],
inputBuffersVec[i],
snpeUserBackedInputBuffers,
psnpe,
name,
usingTf8UserBuffer);
}
for (const char* name : outnames)
{
createUserBuffer(outputMapList[i],
outputBuffersVec[i],
snpeUserBackedOutputBuffers,
psnpe,
name,
usingTf8UserBuffer);
}
loadInputUserBuffer(inputBuffersVec[i], psnpe, inputs[i], inputMapList[i], usingTf8UserBuffer)
}
}
执行同步模式的网络和流程输出
以下代码使用本机 API 以同步模式执行网络。
bool exeStatus = psnpe->execute(inputMapList, outputMapList);
saveOutput(outputMapList[i], outputBuffersVec[i], OutputDir, i * batchSize, batchSize, true);
// The below shows parts of the function.
void saveOutput (zdl::DlSystem::UserBufferMap& outputMap,
std::unordered_map<std::string,std::vector<uint8_t>>& applicationOutputBuffers,
const std::string& outputDir,
int num,
size_t batchSize,
bool isTf8Buffer)
{
const zdl::DlSystem::StringList& outputBufferNames = outputMap.getUserBufferNames();
for(auto & name : outputBufferNames )
{
... //get output data
}
}
异步模式的 BuildConfig
如果要运行outputAsync模式或者inputOutputAsync模式,需要在buildConfig中设置回调函数。
if (inputOutputTransmissionMode == zdl::PSNPE::InputOutputTransmissionMode::outputAsync) {
buildConfig.outputThreadNumbers = outputNum;
buildConfig.outputCallback = OCallback;
}
if (inputOutputTransmissionMode == zdl::PSNPE::InputOutputTransmissionMode::inputOutputAsync) {
buildConfig.inputThreadNumbers = inputNum;
buildConfig.outputThreadNumbers = outputNum;
buildConfig.inputOutputCallback = IOCallback;
buildConfig.inputOutputInputCallback = inputCallback;
}
OutputAsync 模式的回调
输出异步模式通过调用回调函数提供实时输出。
void OCallback(zdl::PSNPE::OutputAsyncCallbackParam p) {
if (!p.executeStatus) {
std::cerr << "excute fail ,index: " << p.dataIndex << std::endl;
}
}
InputOutputAsync 模式的执行和回调
异步执行可以提供实时的输出结果,同步执行则在执行完成后才提供输出。
bool exeStatus = psnpe->executeInputOutputAsync(zdl::PSNPE::ApplicationBufferMap(inputMap),i,usingTf8UserBuffer);
//In input/output asynchronous mode, loading input data through callback function with TF8 vector.
std::shared_ptr<zdl::PSNPE::ApplicationBufferMap> inputCallback(
std::vector<std::string> inputs, const zdl::DlSystem::StringList& inputNames) {
std::shared_ptr<zdl::PSNPE::ApplicationBufferMap> inputMap(new zdl::PSNPE::ApplicationBufferMap);
for (std::string fileLine : inputs) {
for (size_t j = 0; j < inputNames.size(); j++) {
... //load input data
}
inputMap->add(inputNames.at(j), loadVector);
}
}
return inputMap;
}
// In input/output asynchronous mode, the index and data of output can be obtained through a callback function
void IOCallback(zdl::PSNPE::InputOutputAsyncCallbackParam p)
{
saveOutput(p.outputMap.getUserBuffer(), OutputDir, p.dataIndex);
}
// The below shows parts of the function.
void saveOutput(const std::unordered_map<std::string, std::vector<uint8_t>>& applicationOutputBuffers, const std::string& outputDir, int num)
{
std::for_each(applicationOutputBuffers.begin(), applicationOutputBuffers.end(), [&](std::pair<std::string, std::vector<uint8_t>> a) {
std::ostringstream path;
path << outputDir << "/" << "Result_" << num << "/" <<a.first.data()<< ".raw";
std::string outputPath = path.str();
std::string::size_type pos = outputPath.find(":");
if(pos != std::string::npos) outputPath = outputPath.replace(pos, 1, "_");
SaveUserBuffer(outputPath,a.second.data(),a.second.size());
});
C++ 应用程序示例
本教程中与 PSNPE 集成的 C++ 应用程序名为snpe-parallel-run 。它是一个命令行可执行文件,使用 Qualcomm® Neural Processing SDK API 执行 DLC 模型。它的用法与在 Android 目标上运行高通神经处理snpe-parallel-run 。它是一个命令行可执行文件,使用 Qualcomm® Neural Processing SDK API 执行 DLC 模型。它的用法与在 Android 目标上运行Inception v3 模型中的 snpe-net-run 示例相同 。
-
将模型数据推送至 Android 目标。
-
选择目标架构。
-
将二进制文件推送至目标。
-
设置环境变量。
adb shell
export ADSP_LIBRARY_PATH="/data/local/tmp/snpeexample/dsp/lib;/system/lib/rfsa/adsp;/system/vendor/lib/rfsa/adsp;/dsp"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data/local/tmp/snpeexample/aarch64-android/lib
export PATH=$PATH:/data/local/tmp/snpeexample/aarch64-android/bin/
cd /data/local/tmp/inception_v3
snpe-parallel-run --container inception_v3_quantized.dlc --input_list target_raw_list.txt --use_dsp --perf_profile burst --cpu_fallback false --use_dsp --perf_profile burst --cpu_fallback false --runtime_mode output_async
exit

















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









