







YOLOv8的颈部(Neck)网络是其目标检测架构中的关键组成部分,主要负责多尺度特征融合和特征增强,以提升模型对不同尺度目标的检测能力。以下是其主要作用及技术细节:
1. 多尺度特征融合
-
问题背景:Backbone(如CSPDarknet)提取的特征图包含不同层次的信息(浅层特征分辨率高、细节丰富但语义弱;深层特征语义强但分辨率低)。
-
颈部的作用:通过FPN(Feature Pyramid Network)或PANet(Path Aggregation Network)等结构,将不同层级的特征图进行融合,使模型同时具备:
-
细节信息(利于检测小物体)。
-
语义信息(利于检测大物体)。
-
-
YOLOv8的改进:可能采用更高效的跨层级连接(如双向融合),增强特征传递。
在目标检测任务中,多尺度特征融合是提升模型性能(尤其是对小物体检测)的关键技术。FPN(Feature Pyramid Network) 和 PANet(Path Aggregation Network) 是两种经典的颈部(Neck)网络结构,广泛应用于YOLO系列(如YOLOv3/v4/v5/v8)、Faster R-CNN等模型中。下面详细解析它们的原理、结构及差异:
一、FPN(Feature Pyramid Network)
1. 核心思想
FPN 通过自上而下(Top-Down)的路径将深层语义信息传递到浅层,与高分辨率的浅层特征融合,构建一个兼具高语义和高分辨率的特征金字塔。
2. 结构详解
FPN 包含以下三个关键部分:
Bottom-Up Pathway(自下而上路径)
即Backbone(如ResNet)的前向传播过程,生成不同层级的特征图(如C1, C2, C3, C4, C5),分辨率逐渐降低,语义逐渐增强。Top-Down Pathway(自上而下路径)
从最深层(如C5)开始,通过**上采样(Upsample)**逐步放大特征图尺寸,与对应的Bottom-Up层(如C4、C3)融合。Lateral Connections(横向连接)
通过1×1卷积将Bottom-Up的特征图通道数调整一致,再与上采样后的特征图逐元素相加(Element-wise Addition),生成融合后的特征图(P3, P4, P5等)。3. 输出特征金字塔
P3, P4, P5:融合后的多尺度特征图,分别用于检测小、中、大物体。
可选扩展:在P5基础上通过最大池化生成P6(用于更大目标检测,如Mask R-CNN)。
4. 优点
显著提升小物体检测性能(浅层保留细节,深层提供语义)。
计算高效,仅增加少量参数。
5. 局限性
单向信息流:仅从深层到浅层传递语义信息,忽略了浅层到深层的细节补充。
特征融合简单:仅通过加法融合,可能丢失部分信息。
二、PANet(Path Aggregation Network)
1. 核心思想
PANet 在FPN基础上增加自下而上(Bottom-Up)的增强路径,形成双向特征融合,进一步优化信息流动和梯度传递。
2. 结构改进
PANet 在FPN的基础上引入以下关键模块:
Bottom-Up Path Augmentation
在FPN的Top-Down路径后,新增一个从浅层到深层的路径(类似FPN的逆过程),通过3×3卷积+下采样逐步融合低层特征到高层(生成N3, N4, N5等)。Adaptive Feature Pooling
在RoI Align(用于两阶段检测器)中聚合多尺度特征,提升区域提议的质量(YOLO等单阶段检测器不涉及此部分)。全连接融合(Fully-Connected Fusion)
可选模块,通过短连接增强特征重用。3. 输出特征金字塔
双向融合特征:P3→N3, P4→N4, P5→N5,兼具高层语义和低层细节。
4. 优点
双向信息流:同时传递语义和细节信息,特征表达更丰富。
更深的融合路径:提升小目标检测精度(如COAP数据集中APsmall提升约2%)。
5. 局限性
计算量略高于FPN(增加了一个Bottom-Up路径)。
三、FPN 与 PANet 的对比
特性 FPN PANet 信息流方向 单向(Top-Down) 双向(Top-Down + Bottom-Up) 特征融合方式 横向连接 + 加法融合 双向路径 + 卷积融合 计算复杂度 较低 较高 小目标检测效果 较好 更优(尤其密集小物体场景) 典型应用 YOLOv3, Faster R-CNN YOLOv4/v5, Mask R-CNN
四、在YOLO系列中的应用
YOLOv3:首次引入FPN,生成3个尺度的特征图(13×13, 26×26, 52×52)。
YOLOv4/v5:采用PANet的变体(如PANet-Lite),平衡速度和精度。
YOLOv8:可能进一步优化双向路径(如跨阶段连接)或引入注意力机制。
五、总结
FPN 是基础的多尺度融合框架,适合计算资源受限的场景。
PANet 通过双向路径实现更全面的特征融合,适合高精度需求的任务。
现代改进:后续的BiFPN(EfficientDet)、NAS-FPN等通过加权融合或神经网络搜索进一步优化了这两种结构。
2. 特征增强与上下文提取
-
引入注意力机制:部分版本可能嵌入CBAM(Convolutional Block Attention Module)或SE(Squeeze-and-Excitation)模块,增强关键特征通道或空间的权重。
1. SE 模块(Squeeze-and-Excitation)
提出者:2017 年,来自论文《Squeeze-and-Excitation Networks(CVPR 2018)》
作用:自适应调整特征图中不同通道的重要性,即通过通道注意力(Channel Attention)增强重要通道的特征,抑制无关通道。SE 模块的结构
SE 模块主要分为 3 个步骤:
Squeeze(特征压缩):
先对输入特征图做 Global Average Pooling(GAP),将 H×W×C 的特征图压缩成 1×1×C,获取全局通道信息。
Excitation(特征重标定):
通过 两层全连接(FC)+ ReLU + Sigmoid 生成每个通道的权重,学习哪些通道更重要。
Reweight(通道重标定):
计算出的权重与原特征通道逐通道相乘(乘性注意力机制),增强关键通道的信息,抑制不重要的通道。
SE 计算流程
假设输入特征为 X ∈ ℝ^(H×W×C),则:
Squeeze:
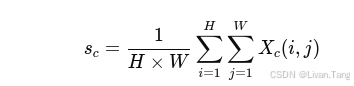
结果是一个 1×1×C 的通道向量。
Excitation:
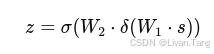
这里 W1(降维 FC) 降维到 C/r(r=16 一般),ReLU 激活
W2(升维 FC) 恢复到 C 维,Sigmoid 激活(0-1 归一化权重)
Reweight:
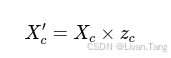
通过逐通道加权,增强重要通道的特征。
2. CBAM 模块(Convolutional Block Attention Module)
提出者:2018 年,来自论文《CBAM: Convolutional Block Attention Module(ECCV 2018)》
作用:结合 通道注意力(Channel Attention) + 空间注意力(Spatial Attention),对重要特征通道和空间位置进行增强,提升目标的可见性。CBAM 模块的结构
CBAM 由 通道注意力 + 空间注意力 两部分组成:
通道注意力(Channel Attention)
作用:学习哪些通道更重要(类似 SE)。
计算方式:
对输入特征做 全局平均池化(GAP) 和 全局最大池化(GMP)(比 SE 更丰富)。
经过 MLP + Sigmoid,得到通道权重,与输入特征逐通道相乘。
空间注意力(Spatial Attention)
作用:学习特征图中哪些空间区域更重要(即目标所在位置)。
计算方式:
对输入特征在通道维度做 最大池化和平均池化,然后拼接(Concat)。
通过一个 7×7 卷积 提取空间注意力信息。
用 Sigmoid 归一化后,与输入特征逐像素相乘。
3. SE vs CBAM:哪个更强?
模块 作用 特点 适用场景 SE 通道注意力 仅关注通道间的特征关系 轻量级,适合通用任务 CBAM 通道 + 空间注意力 同时考虑通道和空间信息 更强但计算量稍高,适合检测/分割
SE 模块适用于一般 CNN 模型(ResNet、EfficientNet),能增强通道级别的特征表达。
CBAM 更适用于目标检测任务(如 YOLO),它能增强目标的空间信息,提高检测鲁棒性,适合小目标检测或复杂背景下的场景。
4. YOLOv8 里的应用
在 YOLOv8 的一些变体(如 YOLOv8-CBAM 或 YOLOv8-SE)中:
Backbone(主干网络):可能会嵌入 SE 或 CBAM,提升特征提取能力。
Neck(PAN-FPN 结构):在融合多尺度特征时,CBAM 可以让模型更关注关键目标区域,减少背景干扰,提高小目标的检测能力。
5. 总结
🔹 SE 模块:增强通道间的注意力,主要在分类网络中使用,但也可以用于 YOLO 提高特征表达能力。
🔹 CBAM 模块:结合 通道+空间注意力,适合目标检测任务,能更好地定位目标并减少背景干扰。
🔹 在 YOLOv8 的变体 中,SE/CBAM 可以用于 Backbone 和 Neck,提升检测精度,特别是在小目标检测、复杂背景、遮挡等场景下效果更明显。如果你在做 YOLOv8 的优化,可以尝试加入 CBAM,看是否能提升检测效果!

上下文信息聚合:通过空洞卷积(Dilated Convolution)或更大感受野的模块,捕捉目标周围的上下文信息,提升遮挡或复杂场景下的检测鲁棒性。
**空洞卷积(Dilated Convolution)**的理解
空洞卷积(Dilated Convolution),也称为扩张卷积(Atrous Convolution),是在标准卷积的基础上引入了间隔(dilation rate),使得卷积核的感受野扩大,而不会增加额外的计算量。
1. 空洞卷积的基本概念
在标准卷积中,卷积核是连续采样输入特征图的,比如:
普通 3×3 卷积 计算时,每次滑动窗口都会覆盖连续的像素。
空洞卷积的特点是:
在卷积核的元素之间插入空洞(dilated gaps),从而跳跃式地采样特征图。
这样可以在不增加计算量的前提下,扩大感受野,捕获更大范围的上下文信息。
计算方式
对于一个 3×3 的卷积核:
标准卷积(dilation=1):每个像素紧密相连,感受野是 3×3。
空洞卷积(dilation=2):每两个相邻像素之间跳过 1 个像素,感受野变成 5×5。
空洞卷积(dilation=3):每两个相邻像素之间跳过 2 个像素,感受野变成 7×7。
Dilation Rate 3×3 卷积核 实际覆盖区域 1(标准卷积) 3×3 2 5×5 3 7×7 4 9×9
2. 为什么使用空洞卷积?
扩大感受野:
例如,dilation=2 的 3×3 空洞卷积,感受野相当于 5×5 卷积,但只需要 3×3 计算量。
这样模型能看到更远的像素,增强对全局信息的理解,特别适用于目标检测、语义分割等任务。
避免下采样丢失信息:
传统 CNN 通过 池化(Pooling) 或 步长(Stride)>1 来扩大感受野,但这会导致分辨率下降、细节丢失。
空洞卷积可以在不降低分辨率的情况下,获取更大范围的特征信息。
适用于多尺度特征提取:
通过不同的空洞率(Dilation Rate),可以让不同层感受不同尺度的信息。
例如,DeepLabV3+ 就利用了多尺度空洞卷积来提升语义分割精度。
3. 空洞卷积 vs 标准卷积 vs 池化
方法 是否影响分辨率 计算量 感受野扩展能力 适用场景 标准卷积 不影响 计算量较大 低 常规特征提取 池化(Pooling) 影响,降低分辨率 低 高 下采样、特征压缩 空洞卷积 不影响 适中 高 语义分割、目标检测、时序数据
4. 在 YOLOv8 里的作用
在 目标检测任务 中,空洞卷积主要用于 增强上下文信息的获取,特别是解决目标遮挡或小目标检测问题。可能的应用方式包括:
Backbone 部分:用于提取更大范围的特征。
Neck 部分(PAN-FPN):可结合 FPN 多尺度特征,进一步增强高层语义信息。
SPPF 模块(类似 Dilated Conv):在不同感受野下聚合信息,提高检测精度。
3. 计算效率优化
-
轻量化设计:YOLOv8的颈部可能采用深度可分离卷积(Depthwise Separable Convolution)或减少冗余层数,平衡性能与速度。
-
梯度流优化:通过残差连接(Residual Connections)或密集连接(Dense Blocks),缓解深层网络梯度消失问题。
4. 与Head的协同
-
颈部输出的多尺度特征会直接输入检测头(Head),用于生成最终的边界框和类别预测。颈部的质量直接影响Head的精度和速度。
对比YOLOv5的改进(可能包含):
-
更复杂的融合路径:如增加自上而下/自下而上的双向特征融合次数。
-
自适应模块:动态调整特征融合权重(如ASFF)。
-
减少计算量:通过剪枝或重构颈部结构,提升推理速度。
总结:
YOLOv8的颈部网络是Backbone和Head之间的桥梁,核心目标是生成多尺度、高语义、高分辨率的特征金字塔,使模型能同时高效检测不同大小的目标,同时兼顾速度与精度需求。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









