






Introduction
我们知道在slam领域,传统视觉slam算法经过较长时间的理论积累和工程优化经验,是目前工程上主流的实现方案,而深度学习与在slam上的发展也慢慢显露出其优势,发展速度也越来越快。目前基于nerf的火热,nerf-base的slam相关工作也慢慢出现,nerf-base可以将nerf的惊人效果和slam结合在一起,与传统slam如orb-slam这种稀疏关键点地图相比,在稠密建图上可以实现惊人的重建效果。本文介绍的nerf-slam是一篇结合了多个优秀工作的成果,与nice-slam相比,它的输入值需要rgb数据就可以实现非常优秀的效果。
Tracking: Dense SLAM with Covariances
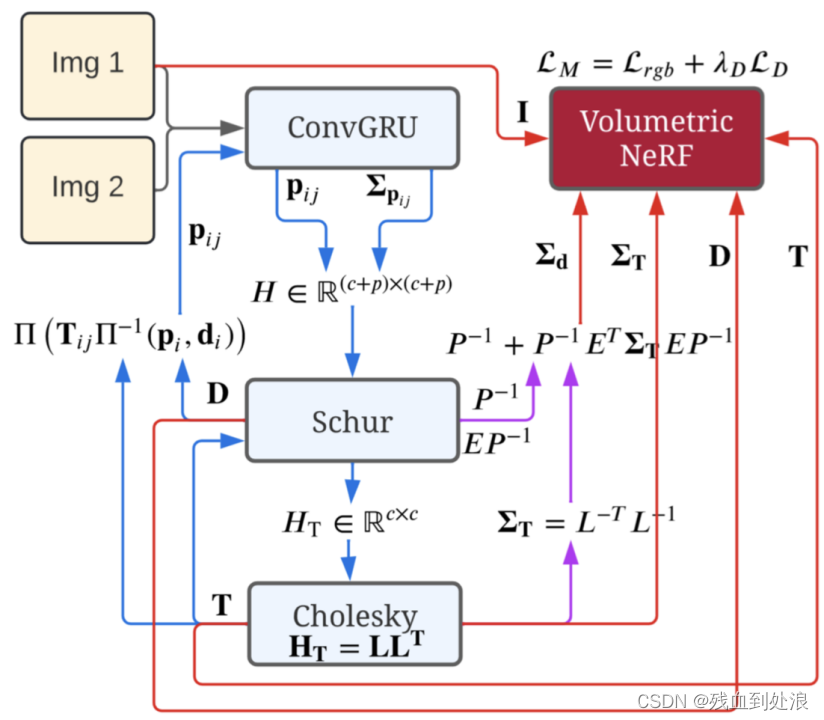
输入由连续的单目图像组成(这里表示为Img 1和Img 2)。从右上角开始,该架构使用instant-NGP的NeRF,其输入为RGB图像I,深度D来监督,其中深度由其边缘协方差∑D加权。我们从稠密单目SLAM(Droid SLAM)计算这些协方差。蓝色显示Droid SLAM的贡献和信息流,同样,粉色显示Rosinol的贡献,红色显示本文的贡献。
RAFT
Droid SLAM是基于RAFT的思路来做的,所以我们先来看看RAFT做了什么。RAFT是一个利用convGRU来做光流估计的模型,获得了很好的效果:

RAFT由3个主要组件组成:
(1)从两个输入图像中提取每像素特征的特征编码器,以及仅从I1中提取特征的上下文编码器。(2) 一个相关层,通过取所有对的内积来构建4D W×H×W×H correlation volume特征向量。4D correlation volume的最后二维在多个尺度上进行合并,以构建一组多尺度体积。
(3) 一种更新算子,通过使用当前估计值从一组相关体积中查找值来反复更新光流。
Droid-SLAM
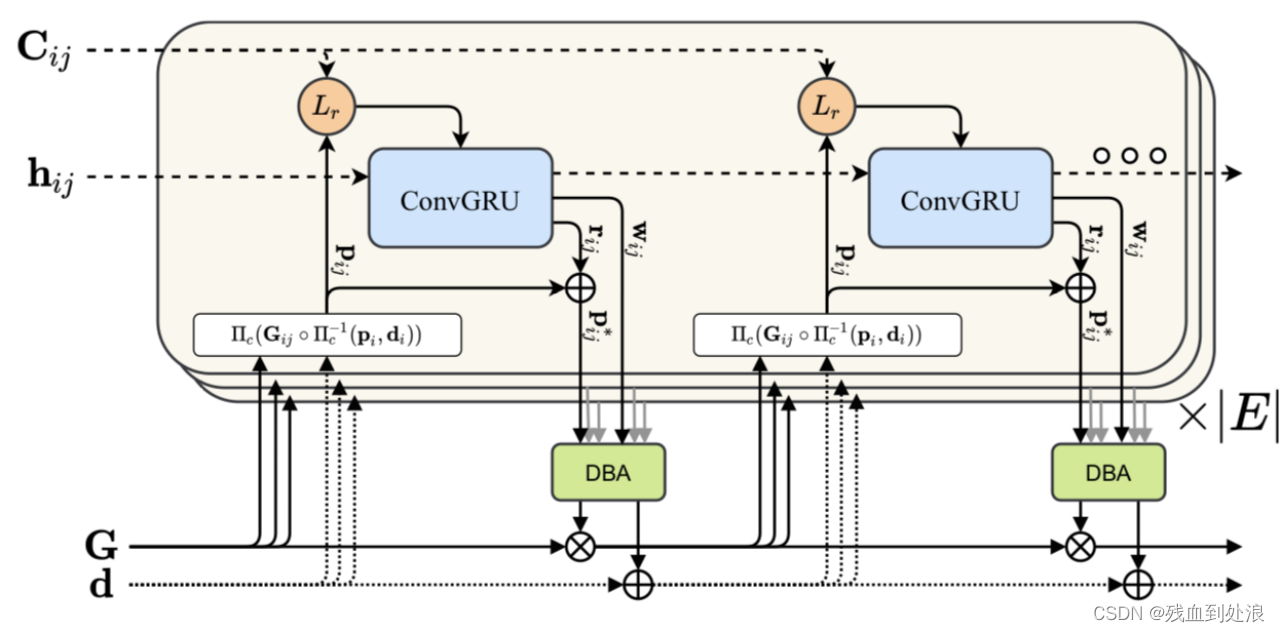
droid-slam在RAFT基础上修改了更新部分。看上图示,操作符作用于frame graph中的边,预测通过(DBA)层映射到深度和位姿更新修正。

注意这里的pi指的是frame i对应的像素点p,di为frame i的逆深度,通过相机投影和反投影,
pij表示frame i的像素点pi使用估计的pose和深度信息映射到frame j。
这里的Cij输入是使用pij通过查找表的方式从correlation volume获得的(图中表述为Lr)。

convGRU并不是直接输出G和D的残差,而是输出pij的残差量 :rij和信心矩阵 :wij
接下来看最重要的DBA部分
Dense Bundle Adjustment Layer (DBA)

其实这部分应用到了传统slam中BA的很多知识点,首先c和p分别表示BA过程中的相机和 路标点,我们知道p的数量一般远远大于c,所以一般在vslam中求解H矩阵我们会先算出c,在代入算出p。具体操作如下:
首先通过舒尔补Schur将原来的H编程和camera相关的矩阵Ht:
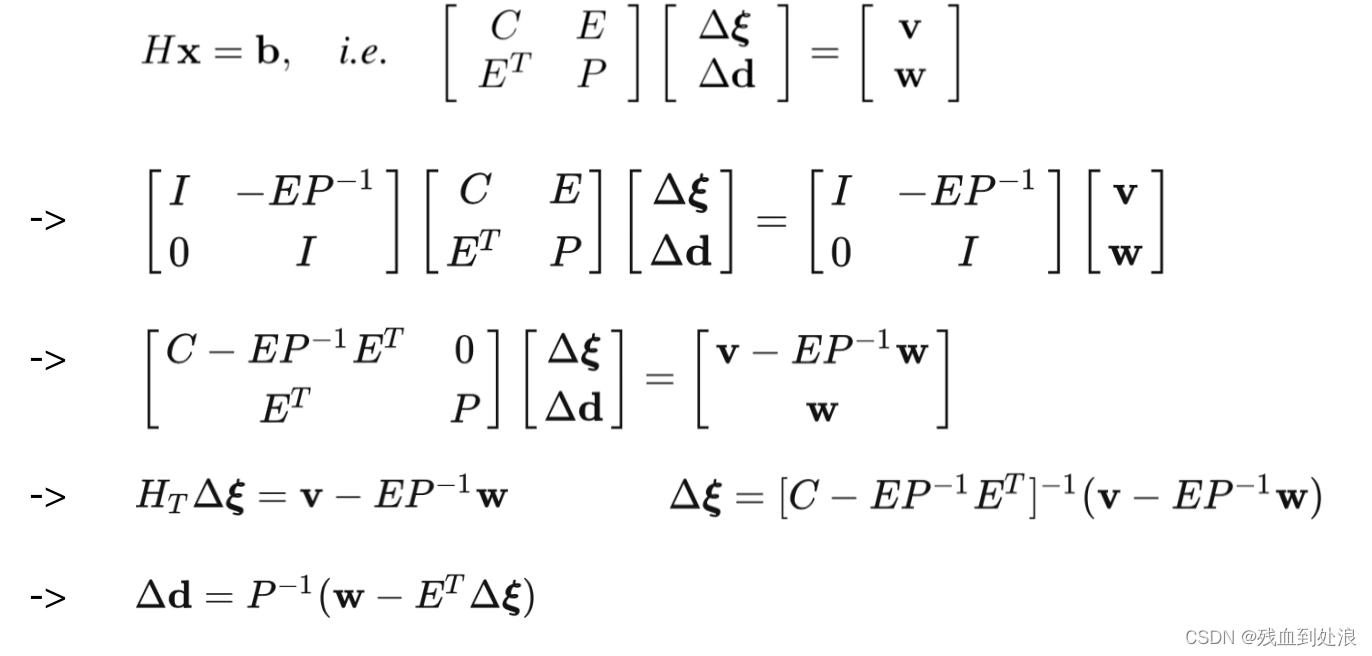
注意这里的delta d就是我们所要求的路标点逆深度,delta 柯西就是相机的位姿,我们先求出delta 柯西然后代入delta d

西格马T和西格马d就是对应的边际协方差的求解,注意我们可以利用Cholesky 分解获得:
H = LLT
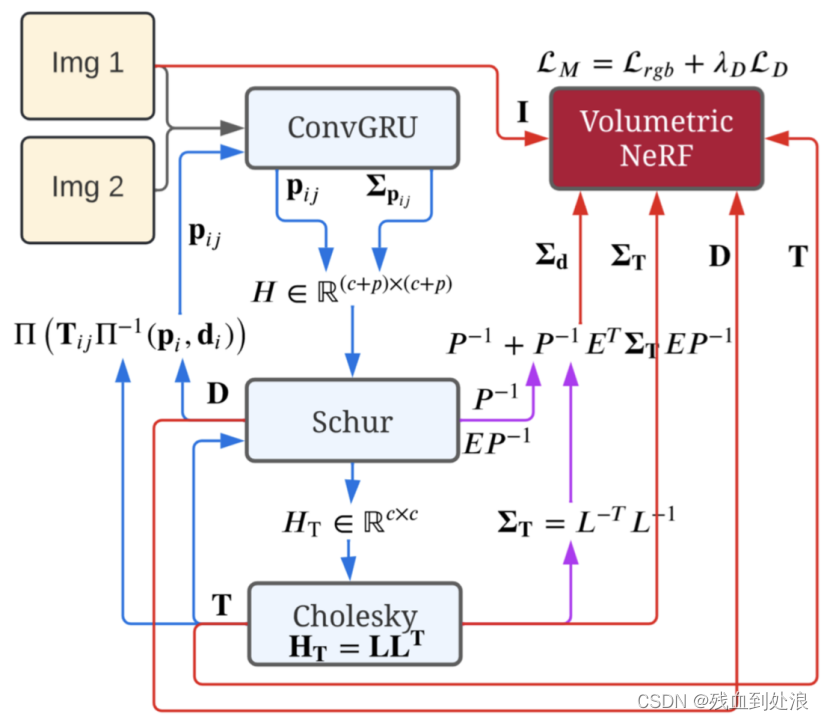
现在重新回顾这张图对比一下大家就会理解的比较清楚
Mapping: Probabilistic Volumetric NeRF
Instant-NGP
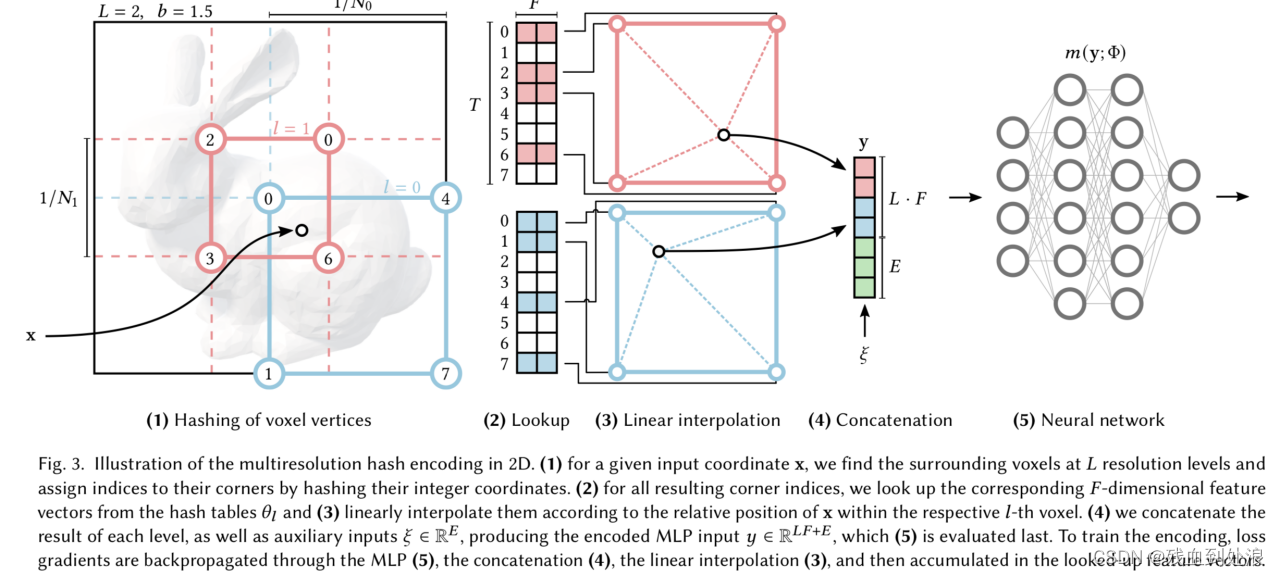
这个方法利用了hash编码让nerf在速度上获得了很大的提升,上图以L=2 两层的分辨率为例,对应点x,在粉色和蓝色分别有不同的hash编码值,将它们与输入编码拼接组合后,再输入到MLP,这里关于体渲染基础可以参考Volume Rendering
Mapping Loss
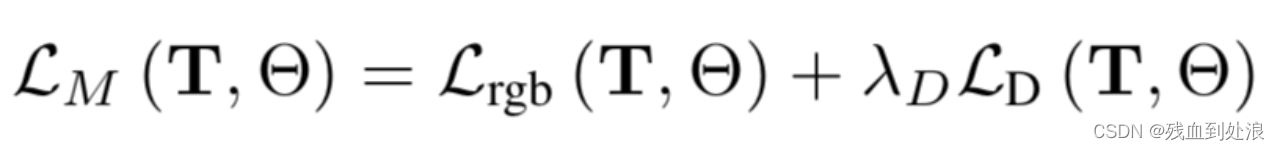
在给定超参数λD平衡深度和颜色监督(我们将λD设置为1.0)的情况下,我们将姿态T和神经参数θ最小化。特别是,我们的深度损失由下式给出:
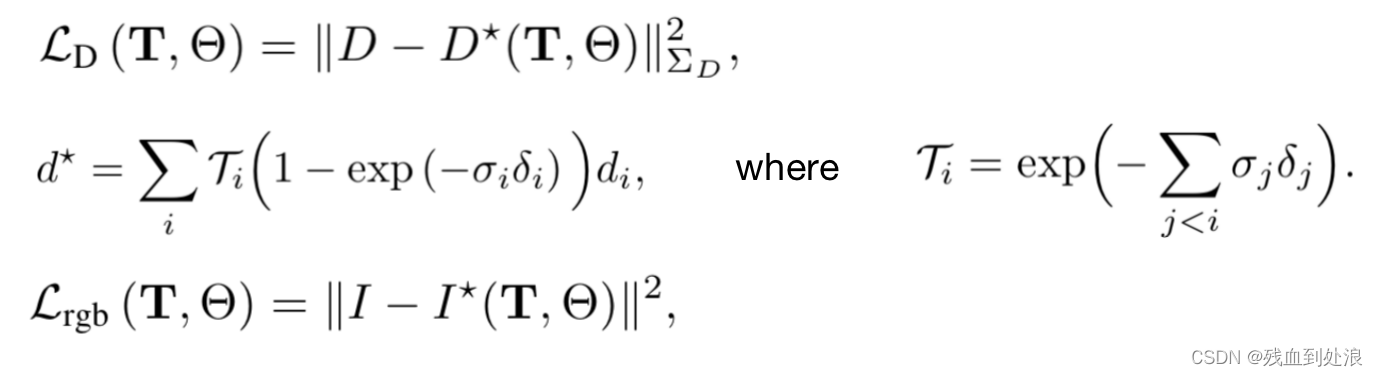
来自原始深度图的神经辐射场的深度监督,无论是从密集SLAM估计的还是来自RGB-D的,都容易出错,因为深度图通常是有噪声的,并且有异常值。对于密集的单目SLAM,这是特别有问题的,因为即使对于无纹理或锯齿区域,也会估计深度值。
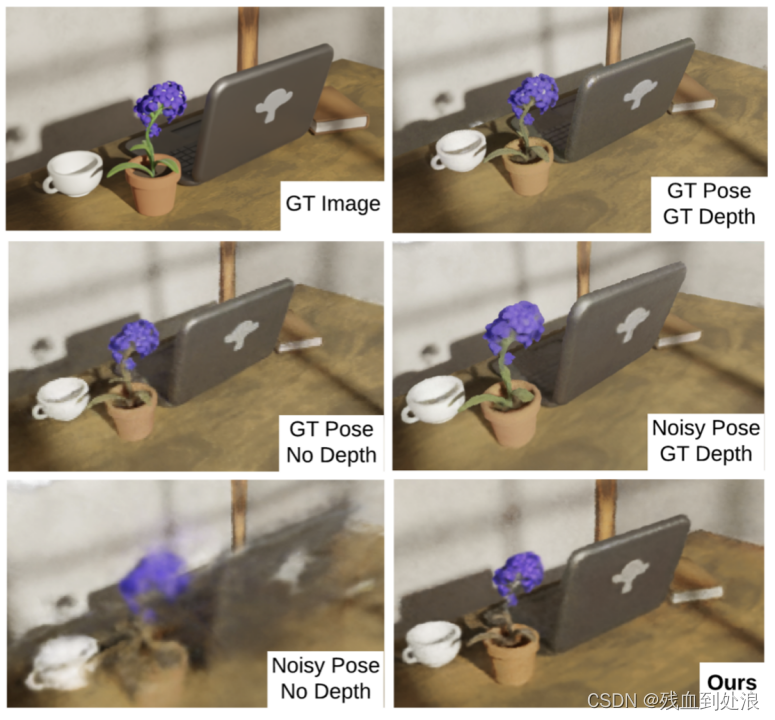
使用groud true姿态和深度进行快速准确的神经辐射场重建(右上角图像)。如果没有提供groud true深度,但groud true姿态可用,则辐射场也会收敛,尽管速度较慢(左中);这是NeRF(姿势图像)的经典输入。相反,如果我们提供有噪声的姿态和无深度图,辐射场不会在60秒内收敛(左下角),而使用groud true深度和有噪声的姿势仍然会产生很好的结果(右中角)。我们的方法旨在达到最后一个结果。右下角的图像显示,尽管使用了有噪声的姿势和深度,但只要根据它们的不确定性进行加权,我们的方法就可以取得很好的结果。
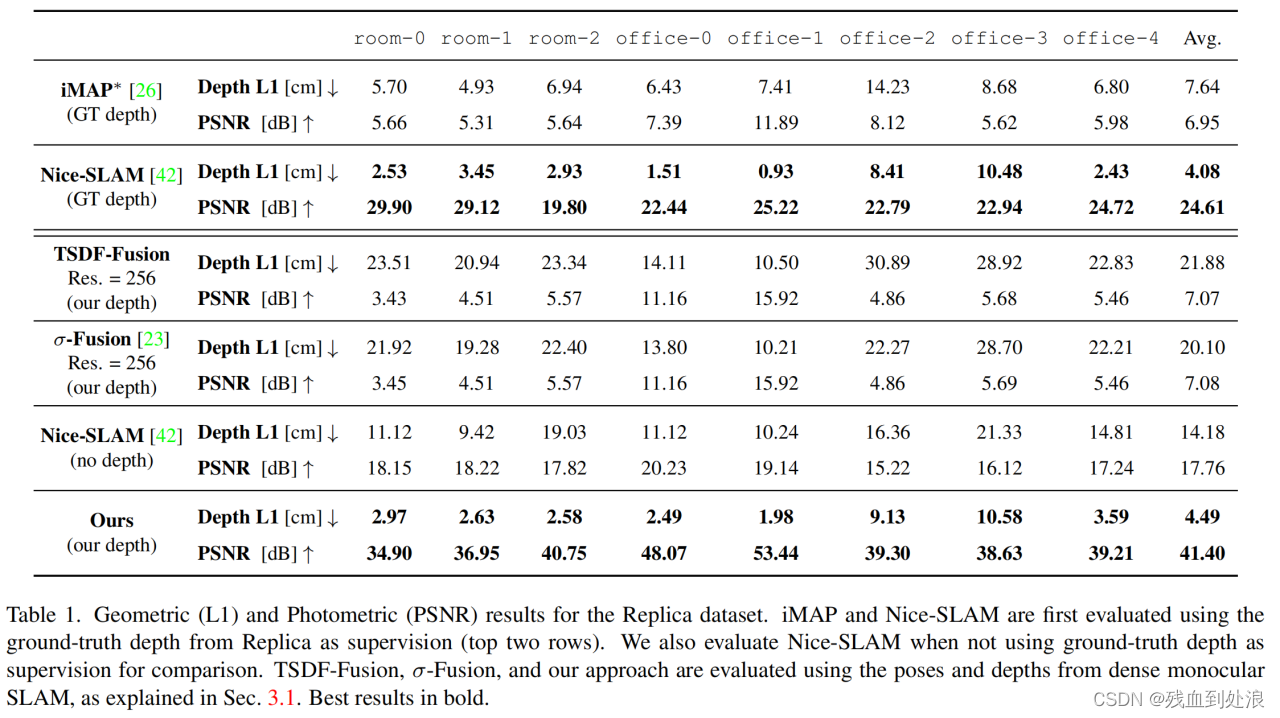
Results

















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









