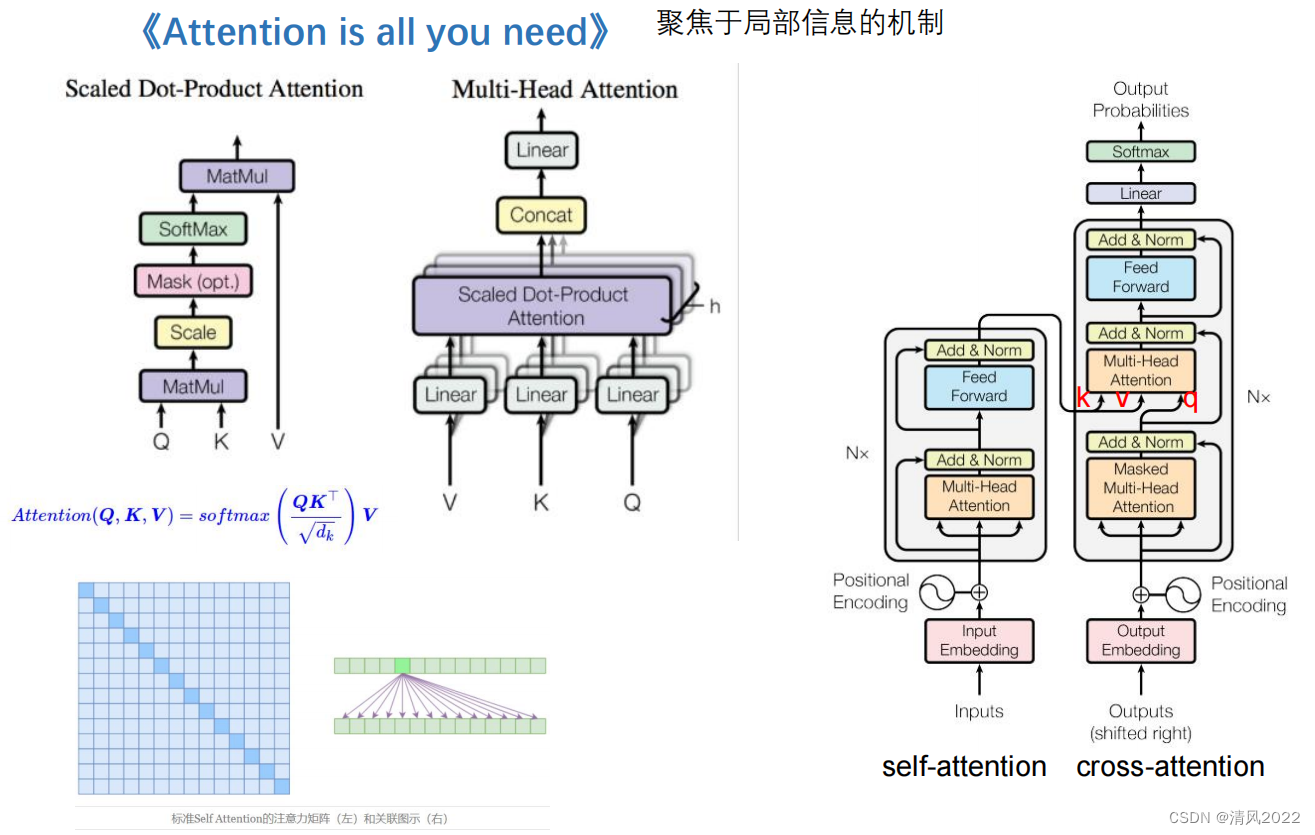
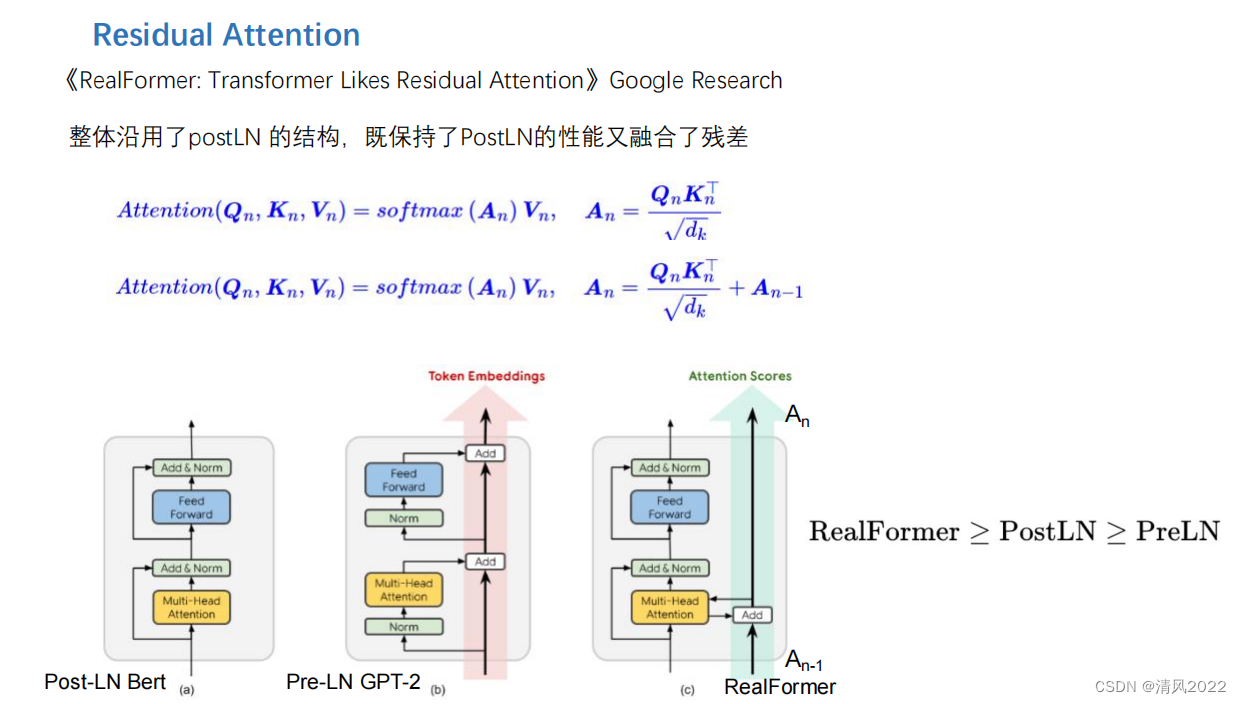
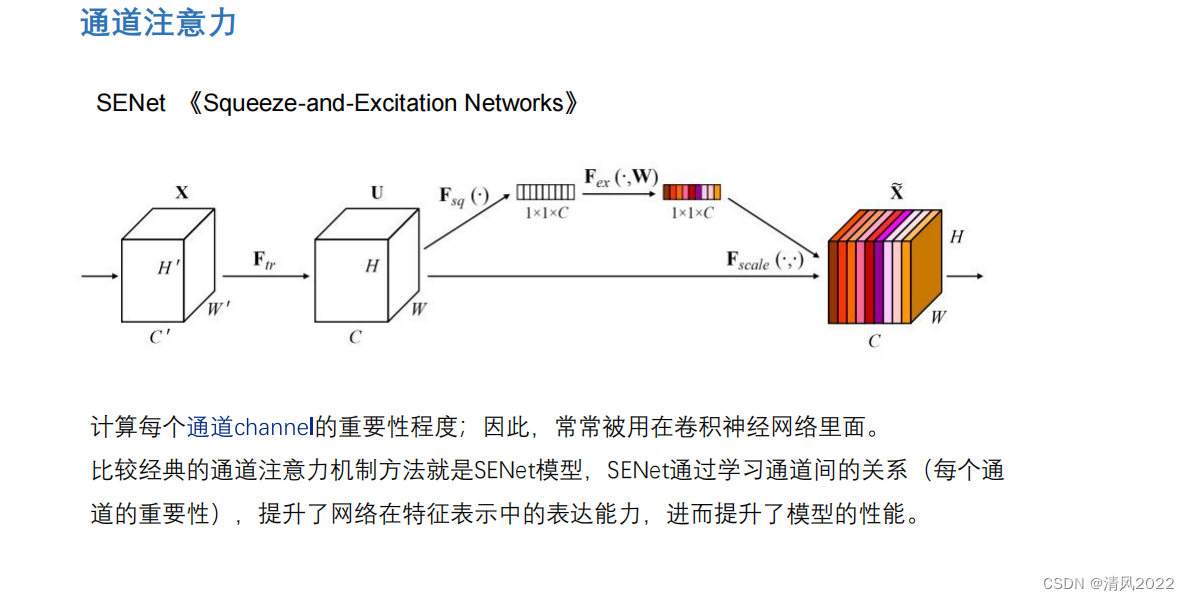
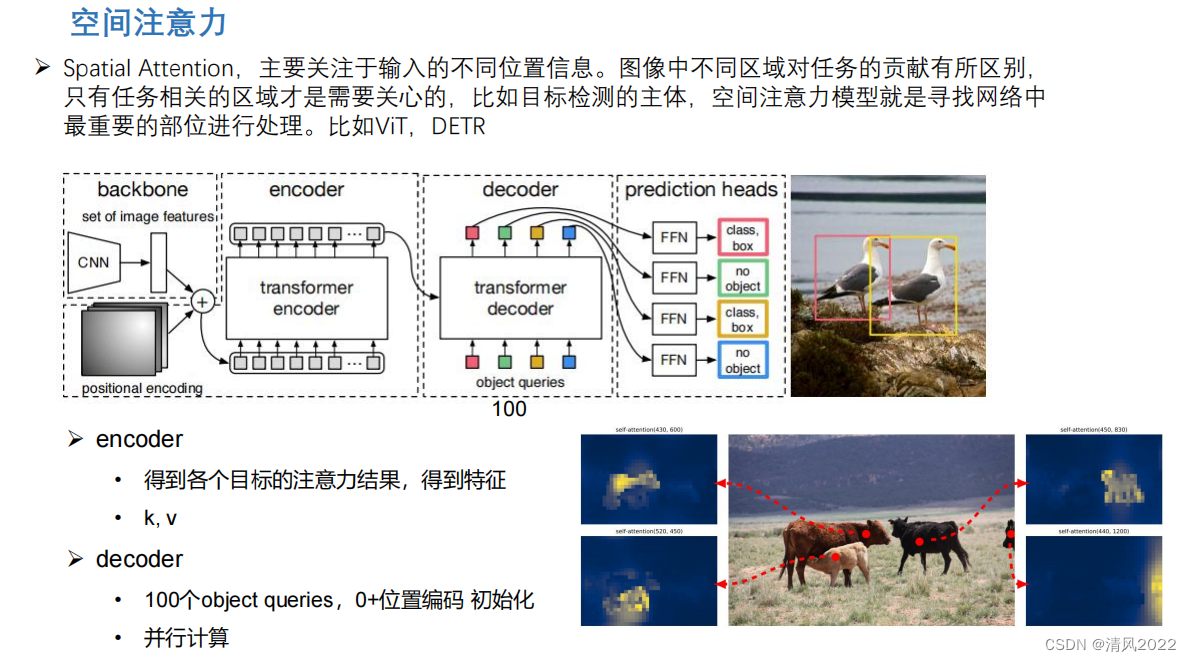
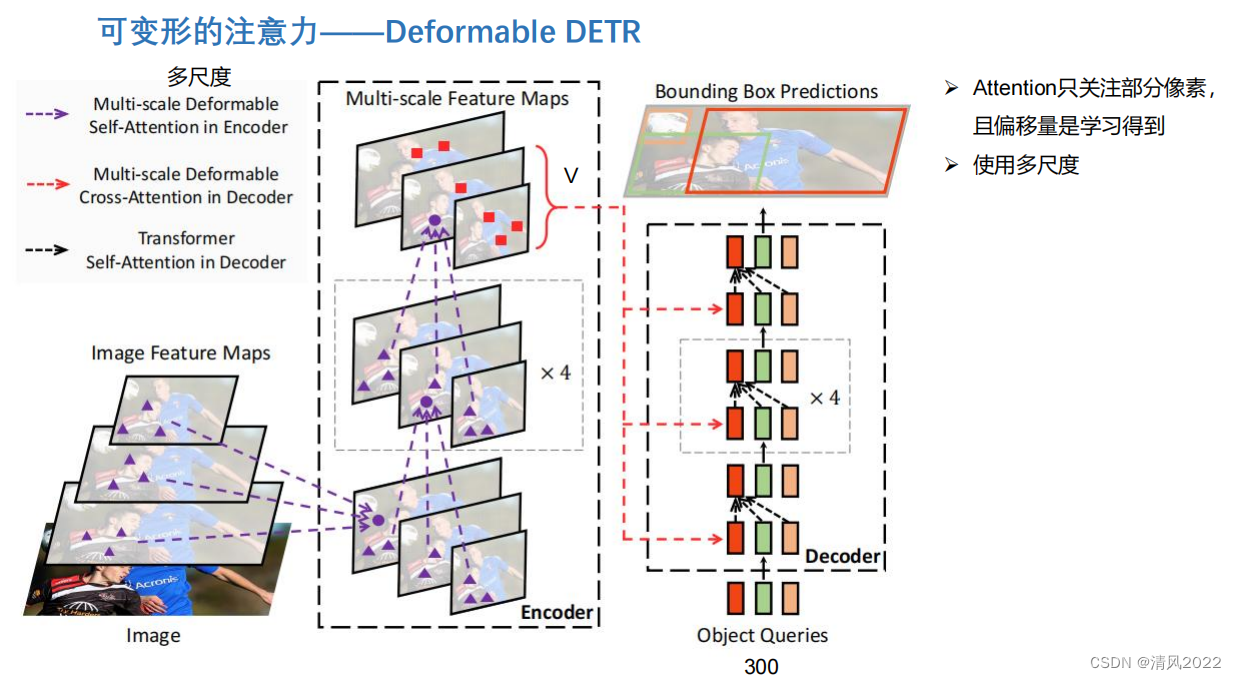
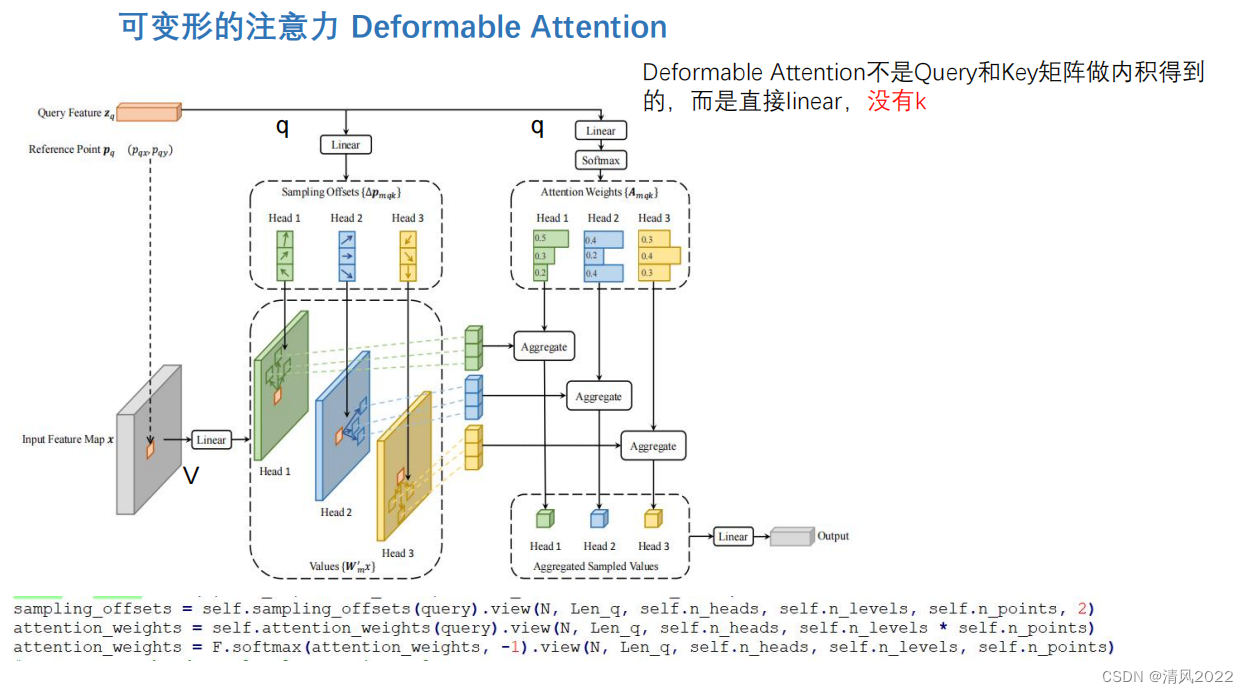
目录 《Attention is all you need 》稀疏Attention残差Attention通道注意力空间注意力时间注意力可变形注意力 《Attention is all you need 》 稀疏Attention 残差Attention 通道注意力 空间注意力 时间注意力 实际上序列类任务也属于时间注意力,比如transformer decoder逐个预测模型 可变形注意力







 本文深入探讨了Attention机制的各种形式,包括稀疏Attention、残差Attention、通道注意力、空间注意力和时间注意力,特别强调在序列类任务中时间注意力的应用,如Transformer解码器中的预测过程,以及可变形注意力的新发展。
本文深入探讨了Attention机制的各种形式,包括稀疏Attention、残差Attention、通道注意力、空间注意力和时间注意力,特别强调在序列类任务中时间注意力的应用,如Transformer解码器中的预测过程,以及可变形注意力的新发展。



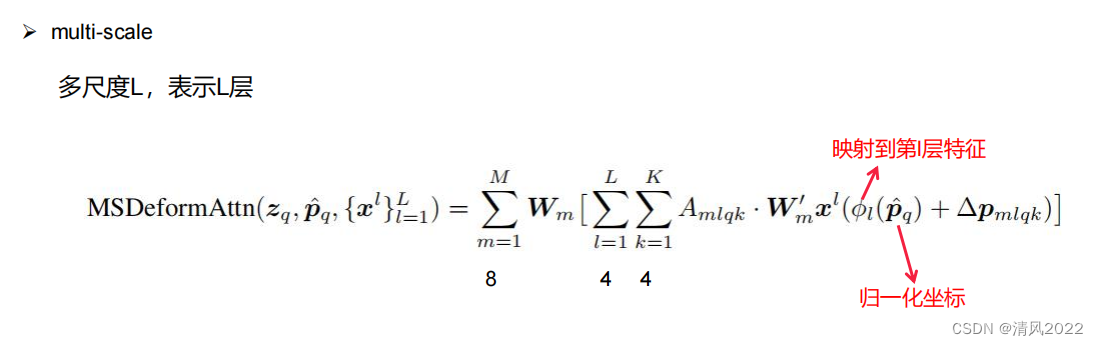


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 1975
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
1975
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






