







上一小节讲了拉格朗日函数,可以把原始问题转化为对偶问题,并且对偶问题是凸的。我们还得到了弱对偶性和强对偶性的概念,并且提到了 Slater Condition 保证凸问题的强对偶性成立,并且给出了一些几何的直观解释。那么在这一节,我们将引出著名的 KKT 条件,它给出了最优解需要满足的必要条件,是求解优化问题最优解的一个重要方式。
有需要的话可以参考前面两节内容
凸优化学习笔记 10:凸优化问题
凸优化学习笔记 11:对偶原理
1. KKT 条件
我们首先回顾一下拉格朗日函数,考虑下面的优化问题
minimize
f
0
(
x
)
subject to
f
i
(
x
)
≤
0
,
i
=
1
,
…
,
m
h
i
(
x
)
=
0
,
i
=
1
,
…
,
p
\begin{aligned} \text { minimize } \quad& f_{0}(x)\\ \text { subject to } \quad& f_{i}(x) \leq 0, \quad i=1, \ldots, m\\ &h_{i}(x)=0, \quad i=1, \ldots, p \end{aligned}
minimize subject to f0(x)fi(x)≤0,i=1,…,mhi(x)=0,i=1,…,p
那么他的拉格朗日函数就是
L
(
x
,
λ
,
ν
)
=
f
0
(
x
)
+
λ
T
f
(
x
)
+
ν
T
h
(
x
)
L(x,\lambda,\nu)=f_0(x)+\lambda^Tf(x)+\nu^Th(x)
L(x,λ,ν)=f0(x)+λTf(x)+νTh(x)
首先,我们看对偶函数
g
(
λ
,
ν
)
=
inf
x
∈
D
(
f
0
(
x
)
+
λ
T
f
(
x
)
+
ν
T
h
(
x
)
)
g(\lambda,\nu)=\inf_{x\in\mathcal{D}}\left(f_0(x)+\lambda^Tf(x)+\nu^Th(x)\right)
g(λ,ν)=x∈Dinf(f0(x)+λTf(x)+νTh(x))
对偶问题实际上就是
d
⋆
=
sup
λ
,
ν
g
(
λ
,
ν
)
=
sup
λ
,
ν
inf
x
L
(
x
,
λ
,
ν
)
d^\star = \sup_{\lambda,\nu}g(\lambda,\nu)=\sup_{\lambda,\nu}\inf_x L(x,\lambda,\nu)
d⋆=λ,νsupg(λ,ν)=λ,νsupxinfL(x,λ,ν)
然后我们再看原问题,由于
λ
⪰
0
,
f
(
x
)
⪯
0
\lambda\succeq0,f(x)\preceq0
λ⪰0,f(x)⪯0,我们有
f
0
(
x
)
=
sup
λ
,
ν
L
(
x
,
λ
,
ν
)
f_0(x)=\sup_{\lambda,\nu}L(x,\lambda,\nu)
f0(x)=λ,νsupL(x,λ,ν)
原问题的最优解实际上就是
p
⋆
=
inf
x
f
0
(
x
)
=
inf
x
sup
λ
,
ν
L
(
x
,
λ
,
ν
)
p^\star=\inf_x f_0(x)= \inf_x \sup_{\lambda,\nu}L(x,\lambda,\nu)
p⋆=xinff0(x)=xinfλ,νsupL(x,λ,ν)
弱对偶性
p
⋆
≥
d
⋆
p^\star \ge d^\star
p⋆≥d⋆ 实际上说的是什么呢?就是 max-min 不等式
inf
x
sup
λ
,
ν
L
(
x
,
λ
,
ν
)
≥
sup
λ
,
ν
inf
x
L
(
x
,
λ
,
ν
)
\inf_x \sup_{\lambda,\nu}L(x,\lambda,\nu) \ge \sup_{\lambda,\nu}\inf_x L(x,\lambda,\nu)
xinfλ,νsupL(x,λ,ν)≥λ,νsupxinfL(x,λ,ν)
强对偶性说的又是什么呢?就是上面能够取等号
inf
x
sup
λ
,
ν
L
(
x
,
λ
,
ν
)
=
sup
λ
,
ν
inf
x
L
(
x
,
λ
,
ν
)
=
L
(
x
⋆
,
λ
⋆
,
ν
⋆
)
\inf_x \sup_{\lambda,\nu}L(x,\lambda,\nu) = \sup_{\lambda,\nu}\inf_x L(x,\lambda,\nu) = L({x}^\star,{\lambda}^\star,{\nu}^\star)
xinfλ,νsupL(x,λ,ν)=λ,νsupxinfL(x,λ,ν)=L(x⋆,λ⋆,ν⋆)
实际上
x
⋆
,
λ
⋆
,
ν
⋆
{x}^\star,{\lambda}^\star,{\nu}^\star
x⋆,λ⋆,ν⋆ 就是拉格朗日函数的鞍点!!!(数学家们真实太聪明了!!!妙啊!!!)那么也就是说强对偶性成立等价于拉格朗日函数存在鞍点(在定义域内)。
好,如果存在鞍点的话,我们怎么求解呢?还是看上面取等的式子
f
0
(
x
⋆
)
=
g
(
λ
⋆
,
ν
⋆
)
=
inf
x
(
f
0
(
x
)
+
λ
⋆
T
f
(
x
)
+
ν
⋆
T
h
(
x
)
)
≤
f
0
(
x
⋆
)
+
λ
⋆
T
f
(
x
⋆
)
+
ν
⋆
T
h
(
x
⋆
)
≤
f
0
(
x
⋆
)
\begin{aligned} f_0({x}^\star) = g(\lambda^\star,\nu^\star) &= \inf_x \left( f_0(x)+\lambda^{\star T}f(x)+\nu^{\star T}h(x) \right) \\ & \le f_0(x^\star)+\lambda^{\star T}f(x^\star)+\nu^{\star T}h(x^\star) \\ & \le f_0(x^\star) \end{aligned}
f0(x⋆)=g(λ⋆,ν⋆)=xinf(f0(x)+λ⋆Tf(x)+ν⋆Th(x))≤f0(x⋆)+λ⋆Tf(x⋆)+ν⋆Th(x⋆)≤f0(x⋆)
这两个不等号必须要取到等号,而第一个不等号取等条件应为
∇
x
(
f
0
(
x
)
+
λ
⋆
T
f
(
x
)
+
ν
⋆
T
h
(
x
)
)
=
0
\nabla_x \left( f_0(x)+\lambda^{\star T}f(x)+\nu^{\star T}h(x) \right) =0
∇x(f0(x)+λ⋆Tf(x)+ν⋆Th(x))=0
第二个不等号取等条件为
λ
i
⋆
f
i
(
x
⋆
)
=
0
,
∀
i
\lambda^\star_i f_i(x^\star)=0,\forall i
λi⋆fi(x⋆)=0,∀i
同时,由于 x ⋆ , λ ⋆ , ν ⋆ {x}^\star,{\lambda}^\star,{\nu}^\star x⋆,λ⋆,ν⋆ 还必须位于定义域内,需要满足约束条件,因此上面的几个条件共同构成了 KKT 条件。
KKT 条件
- 原始约束 f i ( x ) ≤ 0 , i = 1 , . . . , m , h i ( x ) = 0 , i = 1 , . . . , p f_i(x)\le0,i=1,...,m, \quad h_i(x)=0,i=1,...,p fi(x)≤0,i=1,...,m,hi(x)=0,i=1,...,p
- 对偶约束 λ ⪰ 0 \lambda\succeq0 λ⪰0
- 互补性条件(complementary slackness) λ i f i ( x ) = 0 , i = 1 , . . . , m \lambda_i f_i(x)=0,i=1,...,m λifi(x)=0,i=1,...,m
- 梯度条件
∇ f 0 ( x ) + ∑ i = 1 m λ i ∇ f i ( x ) + ∑ i = 1 p ν i ∇ h i ( x ) = 0 \nabla f_{0}(x)+\sum_{i=1}^{m} \lambda_{i} \nabla f_{i}(x)+\sum_{i=1}^{p} \nu_{i} \nabla h_{i}(x)=0 ∇f0(x)+i=1∑mλi∇fi(x)+i=1∑pνi∇hi(x)=0
2. KKT 条件与凸问题
Remarks(重要结论)
- 前面推导没有任何凸函数的假设,因此不论是否为凸问题,如果满足强对偶性,那么最优解一定满足 KKT 条件。
- 但是反过来不一定成立,也即 KKT 条件的解不一定是最优解,因为如果 L ( x , λ ⋆ , ν ⋆ ) L(x,\lambda^\star,\nu^\star) L(x,λ⋆,ν⋆) 不是凸的,那么 ∇ x L = 0 \nabla_x L=0 ∇xL=0 并不能保证 g ( λ ⋆ , ν ⋆ ) = inf x L ( x , λ ⋆ , ν ⋆ ) ≠ L ( x ⋆ , λ ⋆ , ν ⋆ ) g(\lambda^\star,\nu^\star)=\inf_x L(x,\lambda^\star,\nu^\star)\ne L(x^\star,\lambda^\star,\nu^\star) g(λ⋆,ν⋆)=infxL(x,λ⋆,ν⋆)=L(x⋆,λ⋆,ν⋆),也即不能保证 x ⋆ , λ ⋆ , ν ⋆ {x}^\star,{\lambda}^\star,{\nu}^\star x⋆,λ⋆,ν⋆ 就是鞍点。
但是如果我们假设原问题为凸问题的话,那么 L ( x , λ ⋆ , ν ⋆ ) L(x,\lambda^\star,\nu^\star) L(x,λ⋆,ν⋆) 就是一个凸函数,由梯度条件 ∇ x L = 0 \nabla_x L=0 ∇xL=0 我们就能得到 g ( λ ⋆ , ν ⋆ ) = L ( x ⋆ , λ ⋆ , ν ⋆ ) = inf x L ( x , λ ⋆ , ν ⋆ ) g(\lambda^\star,\nu^\star)=L(x^\star,\lambda^\star,\nu^\star)=\inf_x L(x,\lambda^\star,\nu^\star) g(λ⋆,ν⋆)=L(x⋆,λ⋆,ν⋆)=infxL(x,λ⋆,ν⋆),另一方面根据互补性条件我们有此时 f 0 ( x ⋆ ) = L ( x ⋆ , λ ⋆ , ν ⋆ ) f_0(x^\star)=L(x^\star,\lambda^\star,\nu^\star) f0(x⋆)=L(x⋆,λ⋆,ν⋆),因此我们可以得到一个结论
Remarks(重要结论):
- 考虑原问题为凸的,那么若 KKT 条件有解 x ~ , λ ~ , ν ~ \tilde{x},\tilde{\lambda},\tilde{\nu} x~,λ~,ν~,则原问题一定满足强对偶性,且他们就对应原问题和对偶问题的最优解。
- 但是需要注意的是,KKT 条件可能无解!此时就意味着原问题不满足强对偶性!
假如我们考虑上一节提到的 SCQ 条件,如果凸优化问题满足 SCQ 条件,则意味着强对偶性成立,则此时有结论
Remarks(重要结论):
如果 SCQ 满足,那么 x x x 为最优解当且仅当存在 λ , ν \lambda,\nu λ,ν 满足 KKT 条件!
例子 1:等式约束的二次优化问题
P
∈
S
+
n
P\in S_+^n
P∈S+n
minimize
(
1
/
2
)
x
T
P
x
+
q
T
x
+
r
subject to
A
x
=
b
\begin{aligned} \text { minimize } \quad& (1/2)x^TPx+q^Tx+r \\ \text { subject to } \quad& Ax=b \end{aligned}
minimize subject to (1/2)xTPx+qTx+rAx=b
那么经过简单计算就可以得到 KKT 条件为
[
P
A
T
A
0
]
[
x
⋆
ν
⋆
]
=
[
−
q
b
]
\left[\begin{array}{cc} P & A^{T} \\ A & 0 \end{array}\right]\left[\begin{array}{l} x^{\star} \\ \nu^{\star} \end{array}\right]=\left[\begin{array}{c} -q \\ b \end{array}\right]
[PAAT0][x⋆ν⋆]=[−qb]
例子 2:注水问题
minimize
−
∑
i
=
1
n
log
(
α
i
+
x
i
)
subject to
x
⪰
0
,
1
T
x
=
1
\begin{aligned} &\text { minimize } \quad-\sum_{i=1}^{n} \log \left(\alpha_{i}+x_{i}\right)\\ &\text { subject to } \quad x \succeq 0, \quad \mathbf{1}^{T} x=1 \end{aligned}
minimize −i=1∑nlog(αi+xi) subject to x⪰0,1Tx=1
根据上面的结论,
x
x
x 是最优解当且仅当
x
⪰
0
,
1
T
x
=
1
x\succeq0,\mathbf{1}^{T} x=1
x⪰0,1Tx=1,且存在
λ
,
ν
\lambda,\nu
λ,ν 满足
λ
⪰
0
,
λ
i
x
i
=
0
,
1
x
i
+
α
i
+
λ
i
=
ν
\lambda \succeq 0, \quad \lambda_{i} x_{i}=0, \quad \frac{1}{x_{i}+\alpha_{i}}+\lambda_{i}=\nu
λ⪰0,λixi=0,xi+αi1+λi=ν
根据互补性条件 λ i x i = 0 \lambda_i x_i=0 λixi=0 分情况讨论可以得到
- 如果 ν < 1 / α i \nu<1/\alpha_i ν<1/αi: λ i = 0 , x i = 1 / ν − α i \lambda_i=0,x_i=1/\nu-\alpha_i λi=0,xi=1/ν−αi
- 如果 ν ≥ 1 / α i \nu\ge1/\alpha_i ν≥1/αi: λ i = ν − 1 / α i , x i = 0 \lambda_i=\nu-1/\alpha_i,x_i=0 λi=ν−1/αi,xi=0
整理就可以得到 1 T x = ∑ i max { 0 , 1 / ν − α i } \mathbf{1}^{T} x=\sum_i\max\{0,1/\nu-\alpha_i\} 1Tx=∑imax{0,1/ν−αi},这个式子怎么理解呢?就像向一个池子里注水一样
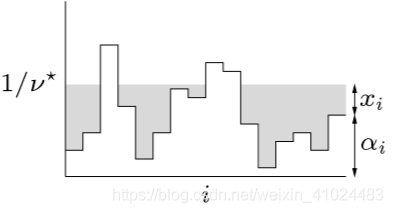
3. 扰动与敏感性分析
现在我们再回到原始问题
minimize
f
0
(
x
)
subject to
f
i
(
x
)
≤
0
,
i
=
1
,
…
,
m
h
i
(
x
)
=
0
,
i
=
1
,
…
,
p
\begin{aligned} \text { minimize } \quad& f_{0}(x)\\ \text { subject to } \quad& f_{i}(x) \leq 0, \quad i=1, \ldots, m\\ &h_{i}(x)=0, \quad i=1, \ldots, p \end{aligned}
minimize subject to f0(x)fi(x)≤0,i=1,…,mhi(x)=0,i=1,…,p
我们引入了对偶函数
g
(
λ
,
ν
)
g(\lambda,\nu)
g(λ,ν),那这两个参数
λ
,
ν
\lambda,\nu
λ,ν 有什么含义吗?假如我们把原问题放松一下
minimize
f
0
(
x
)
subject to
f
i
(
x
)
≤
u
i
,
i
=
1
,
…
,
m
h
i
(
x
)
=
v
i
,
i
=
1
,
…
,
p
\begin{aligned} \text { minimize } \quad& f_{0}(x)\\ \text { subject to } \quad& f_{i}(x) \leq u_i, \quad i=1, \ldots, m\\ &h_{i}(x)=v_i, \quad i=1, \ldots, p \end{aligned}
minimize subject to f0(x)fi(x)≤ui,i=1,…,mhi(x)=vi,i=1,…,p
记最优解为
p
⋆
(
u
,
v
)
=
min
f
0
(
x
)
p^\star(u,v)=\min f_0(x)
p⋆(u,v)=minf0(x),现在对偶问题变成了
max
g
(
λ
,
ν
)
−
u
T
λ
−
v
T
ν
s.t.
λ
⪰
0
\begin{aligned} \max \quad& g(\lambda,\nu)-u^T\lambda -v^T\nu\\ \text{s.t.} \quad& \lambda\succeq0 \end{aligned}
maxs.t.g(λ,ν)−uTλ−vTνλ⪰0
假如说原始对偶问题的最优解为
λ
⋆
,
ν
⋆
\lambda^\star,\nu^\star
λ⋆,ν⋆,松弛后的对偶问题最优解为
λ
~
,
ν
~
\tilde{\lambda},\tilde{\nu}
λ~,ν~,那么根据弱对偶性原理,有
p
⋆
(
u
,
v
)
≥
g
(
λ
~
,
ν
~
)
−
u
T
λ
~
−
v
T
ν
~
≥
g
(
λ
⋆
,
ν
⋆
)
−
u
T
λ
⋆
−
v
T
ν
⋆
=
p
⋆
(
0
,
0
)
−
u
T
λ
⋆
−
v
T
ν
⋆
\begin{aligned} p^\star(u,v) &\ge g(\tilde\lambda,\tilde\nu)-u^T\tilde\lambda -v^T\tilde\nu \\ &\ge g(\lambda^\star,\nu^\star)-u^{T}\lambda^\star -v^{T}\nu^\star \\ &= p^\star(0,0) - u^{T}\lambda^\star -v^{T}\nu^\star \end{aligned}
p⋆(u,v)≥g(λ~,ν~)−uTλ~−vTν~≥g(λ⋆,ν⋆)−uTλ⋆−vTν⋆=p⋆(0,0)−uTλ⋆−vTν⋆
这像不像关于
u
,
v
u,v
u,v 的一阶近似?太像了!实际上,我们有
λ
i
⋆
=
−
∂
p
⋆
(
0
,
0
)
∂
u
i
,
ν
i
⋆
=
−
∂
p
⋆
(
0
,
0
)
∂
v
i
\lambda_{i}^{\star}=-\frac{\partial p^{\star}(0,0)}{\partial u_{i}}, \quad \nu_{i}^{\star}=-\frac{\partial p^{\star}(0,0)}{\partial v_{i}}
λi⋆=−∂ui∂p⋆(0,0),νi⋆=−∂vi∂p⋆(0,0)
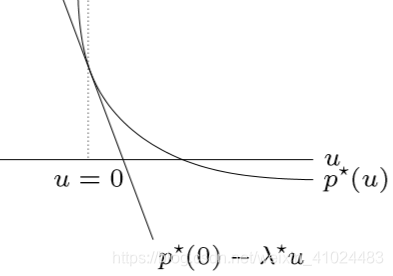
4. Reformulation
前面将凸优化问题的时候,我们提到了Reformulation的几个方法来简化原始问题(参考凸优化学习笔记 10:凸优化问题),比如消去等式约束,添加等式约束,添加松弛变量,epigraph等等。现在当我们学习了对偶问题,再来重新看一下这些方法。
4.1 引入等式约束
例子 1:考虑无约束优化问题
min
f
(
A
x
+
b
)
\min f(Ax+b)
minf(Ax+b),他的对偶问题跟原问题是一样的。如果我们引入等式约束,原问题和对偶问题变为
minimize
f
0
(
y
)
subject to
A
x
+
b
−
y
=
0
minimize
b
T
ν
−
f
0
∗
(
ν
)
subject to
A
T
ν
=
0
\begin{aligned} \text{minimize} \quad& f_{0}(y) \quad \\ \text{subject to} \quad& A x+b-y=0 \end{aligned} \quad\qquad \begin{aligned} \text{minimize} \quad& b^{T} \nu-f_{0}^{*}(\nu) \\ \text{subject to} \quad& A^{T} \nu=0 \end{aligned}
minimizesubject tof0(y)Ax+b−y=0minimizesubject tobTν−f0∗(ν)ATν=0
例子 2:考虑无约束优化
min
∥
A
x
−
b
∥
\min \Vert Ax-b\Vert
min∥Ax−b∥,类似的引入等式约束后,对偶问题变为
minimize
b
T
ν
subject to
A
T
ν
=
0
,
∥
ν
∥
∗
≤
1
\begin{aligned} \text{minimize} \quad& b^{T} \nu \\ \text{subject to} \quad& A^{T} \nu=0,\quad \Vert\nu\Vert_*\le1 \end{aligned}
minimizesubject tobTνATν=0,∥ν∥∗≤1
4.2 显示约束与隐式约束的相互转化
例子 3:考虑原问题如下,可以看出来对偶问题非常复杂
minimize c T x subject to A x = b − 1 ⪯ x ⪯ 1 maximize − b T ν − 1 T λ 1 − 1 T λ 2 subject to c + A T ν + λ 1 − λ 2 = 0 λ 1 ⪰ 0 , λ 2 ⪰ 0 \begin{aligned} \text{minimize} \quad& c^{T} x \\ \text{subject to} \quad& A x=b \\ \quad& -1 \preceq x \preceq 1 \end{aligned} \qquad \begin{aligned} \text{maximize} \quad& -b^{T} \nu-\mathbf{1}^{T} \lambda_{1}-\mathbf{1}^{T} \lambda_{2} \\ \text{subject to} \quad& c+A^{T} \nu+\lambda_{1}-\lambda_{2}=0 \\ \quad& \lambda_{1} \succeq 0, \quad \lambda_{2} \succeq 0 \end{aligned} minimizesubject tocTxAx=b−1⪯x⪯1maximizesubject to−bTν−1Tλ1−1Tλ2c+ATν+λ1−λ2=0λ1⪰0,λ2⪰0
如果我们原问题的不等式约束条件转化为隐式约束,则有
minimize
f
0
(
x
)
=
{
c
T
x
∥
x
∥
∞
⪯
1
∞
otherwise
subject to
A
x
=
b
\begin{aligned} \text{minimize} \quad& f_{0}(x)=\left\{\begin{array}{ll}c^{T} x & \Vert x\Vert_\infty \preceq 1 \\ \infty & \text { otherwise }\end{array}\right. \\ \text{subject to} \quad& A x=b \end{aligned}
minimizesubject tof0(x)={cTx∞∥x∥∞⪯1 otherwise Ax=b
然后对偶问题就可以转化为无约束优化问题
maximize
−
b
T
ν
−
∥
A
T
ν
+
c
∥
1
\text{maximize} -b^T\nu-\Vert A^T\nu +c\Vert_1
maximize−bTν−∥ATν+c∥1
4.3 转化目标函数与约束函数
例子 4:还考虑上面提到的无约束优化问题
min
∥
A
x
−
b
∥
\min \Vert Ax-b\Vert
min∥Ax−b∥,我们可以把目标函数平方一下,得到
minimize
(
1
/
2
)
∥
y
∥
2
subject to
A
x
−
b
=
y
\begin{aligned} \text{minimize} \quad& (1/2)\Vert y\Vert^2 \\ \text{subject to} \quad& Ax-b=y \end{aligned}
minimizesubject to(1/2)∥y∥2Ax−b=y
然后对偶问题就可以转化为
minimize
(
1
/
2
)
∥
ν
∥
∗
2
+
b
T
ν
subject to
A
T
ν
=
0
\begin{aligned} \text{minimize} \quad& (1/2)\Vert \nu\Vert_*^2+ b^T\nu \\ \text{subject to} \quad& A^T\nu=0 \end{aligned}
minimizesubject to(1/2)∥ν∥∗2+bTνATν=0
最后给我的博客打个广告,欢迎光临
https://glooow1024.github.io/
https://glooow.gitee.io/
前面的一些博客链接如下
凸优化专栏
凸优化学习笔记 1:Convex Sets
凸优化学习笔记 2:超平面分离定理
凸优化学习笔记 3:广义不等式
凸优化学习笔记 4:Convex Function
凸优化学习笔记 5:保凸变换
凸优化学习笔记 6:共轭函数
凸优化学习笔记 7:拟凸函数 Quasiconvex Function
凸优化学习笔记 8:对数凸函数
凸优化学习笔记 9:广义凸函数
凸优化学习笔记 10:凸优化问题
凸优化学习笔记 11:对偶原理


















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









